Gérer les ressources du cluster Apache Spark dans Azure HDInsight
Découvrez comment accéder aux interfaces comme celles d’Apache Ambari et d’Apache Hadoop YARN ainsi qu’au serveur d’historique Spark associé à votre cluster Apache Spark, et comment ajuster la configuration du cluster afin d’optimiser les performances.
Ouvrir le serveur d’historique Spark
Le serveur d’historique Spark est l’interface utilisateur web pour les applications Spark terminées et en cours d’exécution. Il s’agit d’une extension de l’interface utilisateur web de Spark. Pour obtenir des informations complètes, consultez Serveur d’historique Spark.
Ouvrir l’interface utilisateur YARN
Vous pouvez utiliser l’interface utilisateur YARN pour surveiller les applications en cours d’exécution sur le cluster Spark.
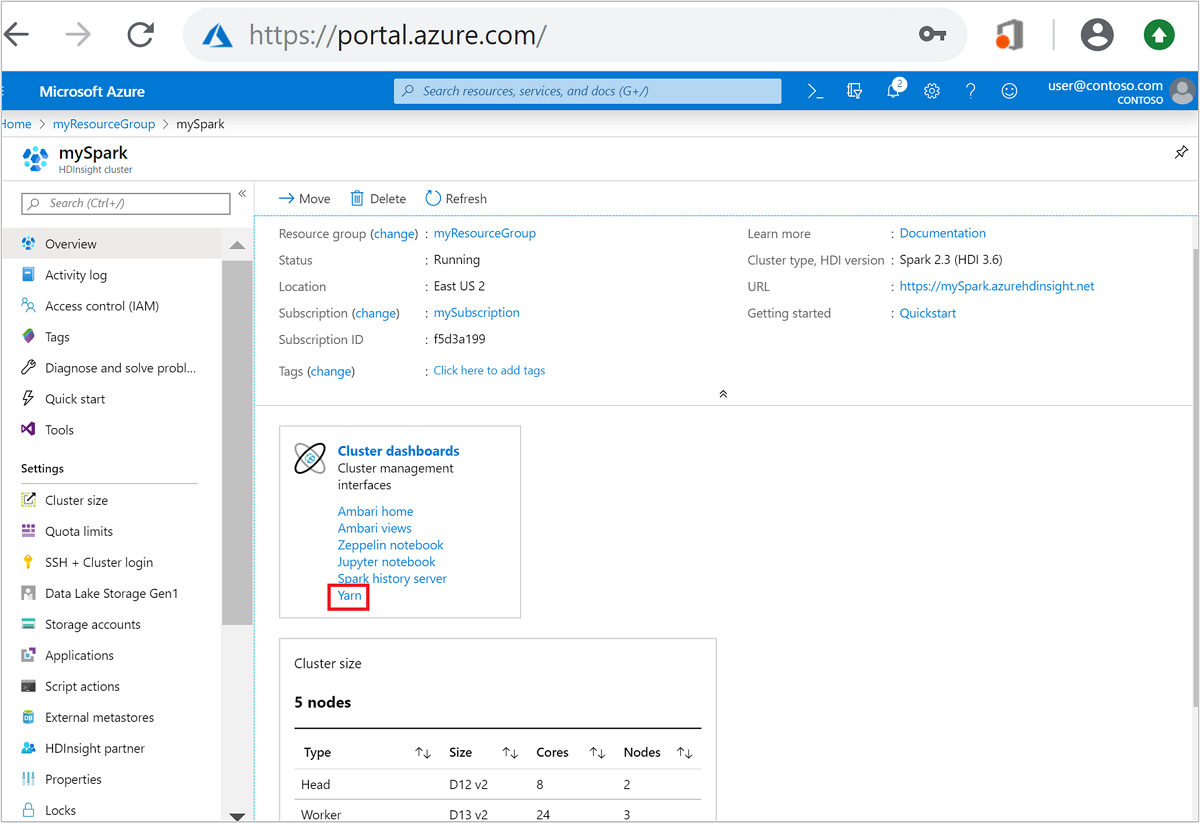
À partir du portail Azure, ouvrez le cluster Spark. Pour plus d’informations, voir Énumération et affichage des clusters.
Dans Tableaux de bord du cluster, sélectionnez Yarn. Lorsque vous y êtes invité, entrez les informations d’identification d’administrateur pour le cluster Spark.
Conseil
Vous pouvez également lancer l’interface utilisateur de YARN à partir de celle d’Ambari. À partir de l’interface utilisateur Ambari, accédez à YARN>Liens rapides>Actifs>Interface utilisateur Resource Manager.
Optimiser les clusters pour les applications Spark
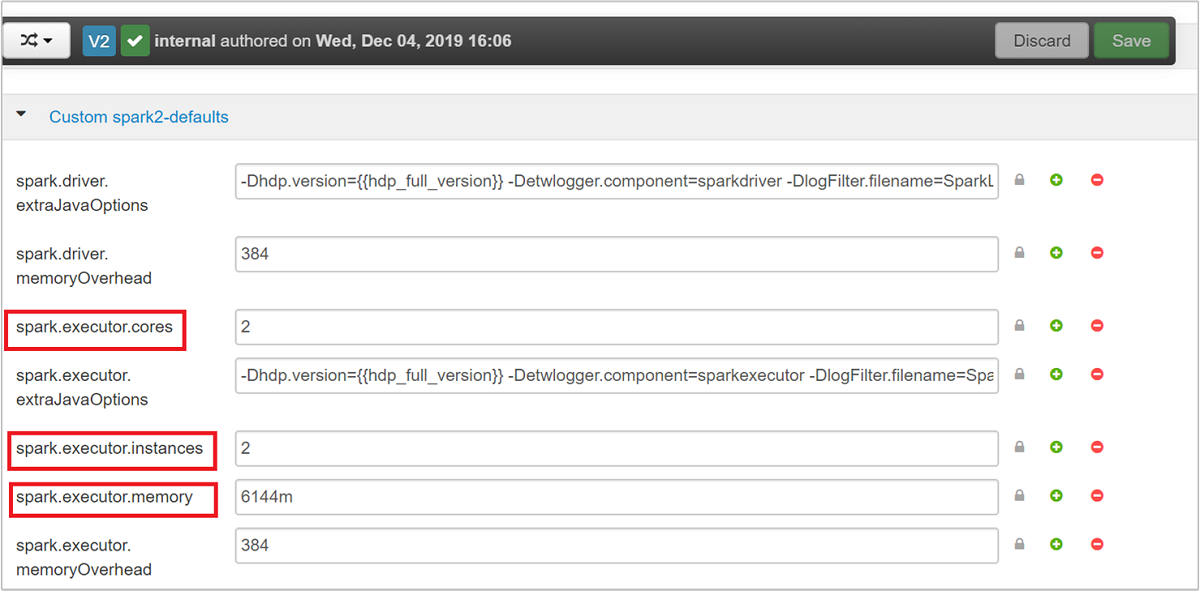
Les trois paramètres clés pouvant être utilisés pour la configuration de Spark selon la configuration requise pour l’application sont spark.executor.instances, spark.executor.cores et spark.executor.memory. Un exécuteur est un processus lancé pour une application Spark. Il s’exécute sur le nœud de travail et est chargé d’effectuer les tâches de l’application. Le nombre d’exécuteurs par défaut et les tailles d’exécuteur de chaque cluster sont calculés en fonction du nombre de nœuds de travail et de leur taille. Ces informations sont stockées dans spark-defaults.conf sur les nœuds principaux du cluster.
Les trois paramètres de configuration peuvent être configurés au niveau du cluster (pour toutes les applications qui s’exécutent sur le cluster) ou spécifiés pour chaque application.
Modifier les paramètres à l’aide de l’interface utilisateur d’Ambari
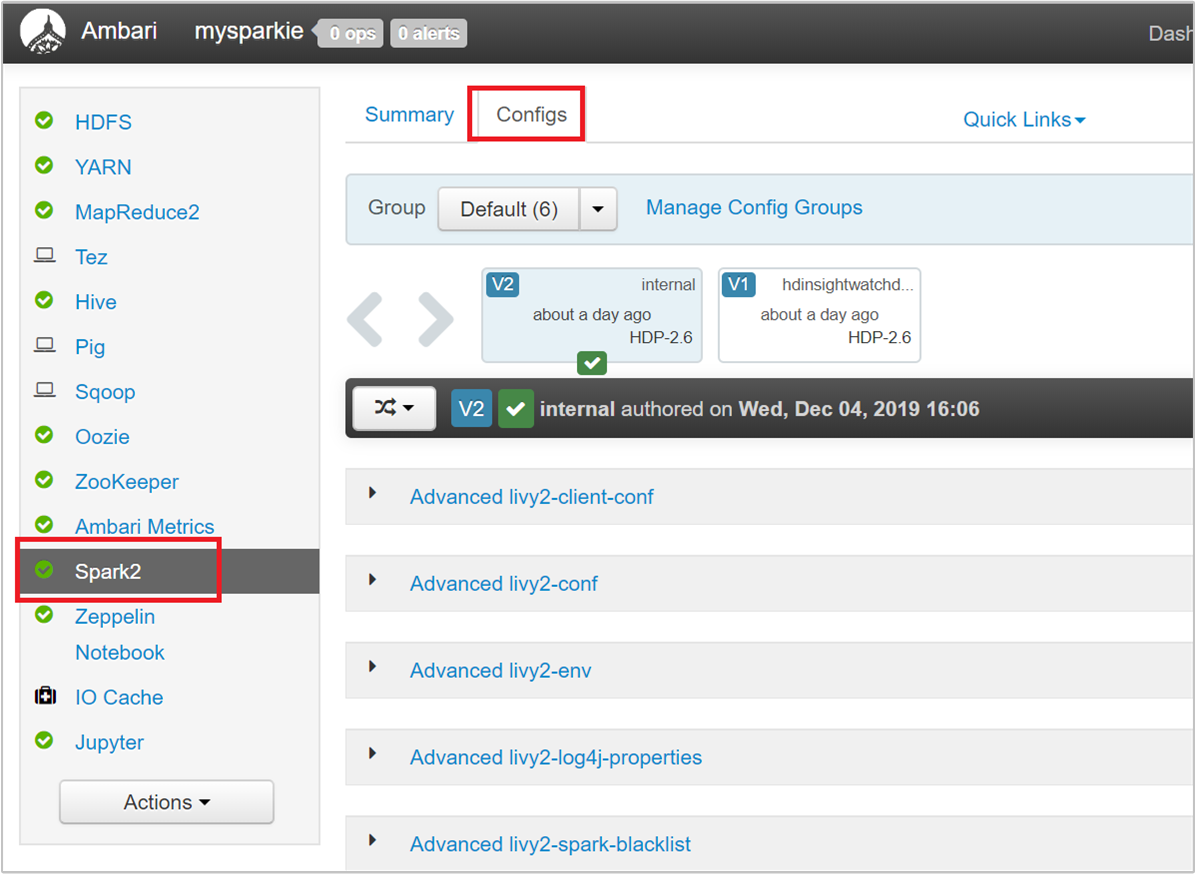
À partir de l’interface utilisateur Ambari, accédez à Spark 2>Paramètres>spark2-defaults personnalisé.
Les valeurs par défaut conviennent si vous souhaitez exécuter simultanément quatre applications Spark sur le cluster. Vous pouvez modifier ces valeurs dans l’interface utilisateur, comme indiqué dans la capture d’écran suivante :
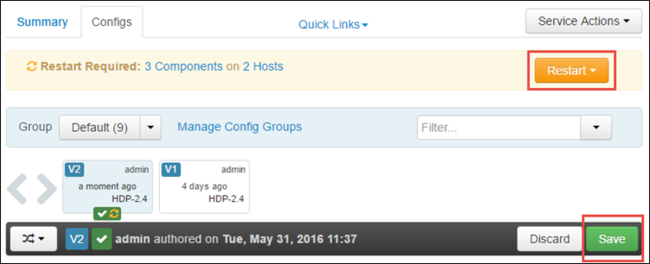
Sélectionnez Save pour enregistrer les modifications de la configuration. En haut de la page, vous êtes invité à redémarrer tous les services concernés. Sélectionnez Redémarrer.
Modifier les paramètres d’une application exécutée dans un bloc-notes Jupyter
Pour les applications exécutées dans le bloc-notes Jupyter, vous pouvez utiliser la commande magique %%configure pour procéder aux modifications de la configuration. Dans l’idéal, vous devez apporter ces modifications au début de l’application, avant d’exécuter la première cellule de code. Ainsi, la configuration est appliquée à la session Livy au moment de sa création. Si vous souhaitez modifier la configuration ultérieurement dans l’application, vous devez utiliser le paramètre -f . Néanmoins, en procédant ainsi, toute la progression de l’application est perdue.
L’extrait de code suivant montre comment modifier la configuration d’une application exécutée dans Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Les paramètres de configuration doivent être passés en tant que chaîne JSON et spécifiés sur la ligne suivant la commande magique, comme indiqué dans l’exemple de colonne.
Modifier les paramètres d’une application soumise à l’aide du script spark-submit
La commande suivante est un exemple de modification des paramètres de configuration d’une application de lot soumise à l’aide de spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Modifier les paramètres d’une application soumise à l’aide de cURL
La commande suivante est un exemple de modification des paramètres de configuration d’une application de lot soumise à l’aide de cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Notes
Copiez le fichier JAR dans votre compte de stockage de cluster. Ne copiez pas le fichier JAR directement dans le nœud principal.
Modifier ces paramètres sur un serveur Spark Thrift
Le serveur Thrift Spark fournit un accès JDBC/ODBC à un cluster Spark et est utilisé pour les requêtes SQL Spark. Des outils comme Power BI, Tableau, etc. utilisent le protocole ODBC pour communiquer avec Spark Thrift Server afin d’exécuter des requêtes SQL Spark en tant qu’application Spark. Lors de la création d’un cluster Spark, deux instances du serveur Thrift Spark sont démarrées, une par nœud principal. Chaque serveur Thrift Spark apparaît en tant qu’application Spark dans l’interface utilisateur de YARN.
Spark Thrift Server utilise l’allocation d’exécuteur dynamique de Spark. Le code spark.executor.instances n’est donc pas utilisé. En revanche, le serveur Thrift Spark utilise spark.dynamicAllocation.maxExecutors et spark.dynamicAllocation.minExecutors pour indiquer le nombre d’exécuteurs. Les paramètres de configuration spark.executor.cores et spark.executor.memory permettent de modifier la taille de l’exécuteur. Vous pouvez modifier ces paramètres comme indiqué dans les étapes suivantes :
Développez la catégorie Advanced spark2-thrift-sparkconf pour mettre à jour les paramètres
spark.dynamicAllocation.maxExecutorsetspark.dynamicAllocation.minExecutors.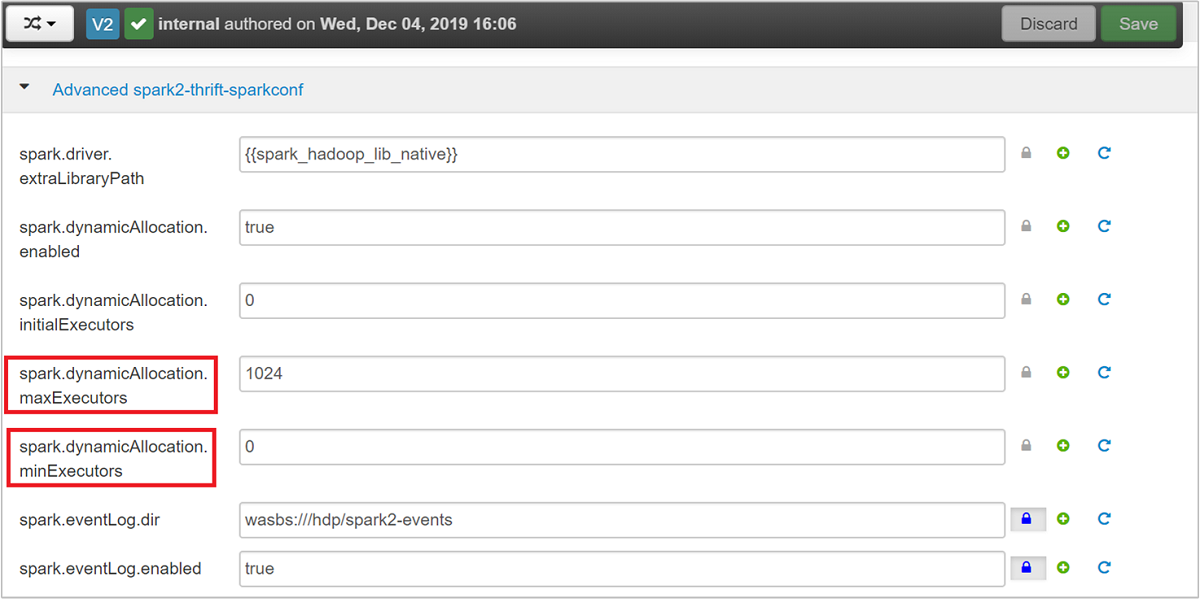
Développez la catégorie Custom spark2-thrift-sparkconf pour mettre à jour les paramètres
spark.executor.coresetspark.executor.memory.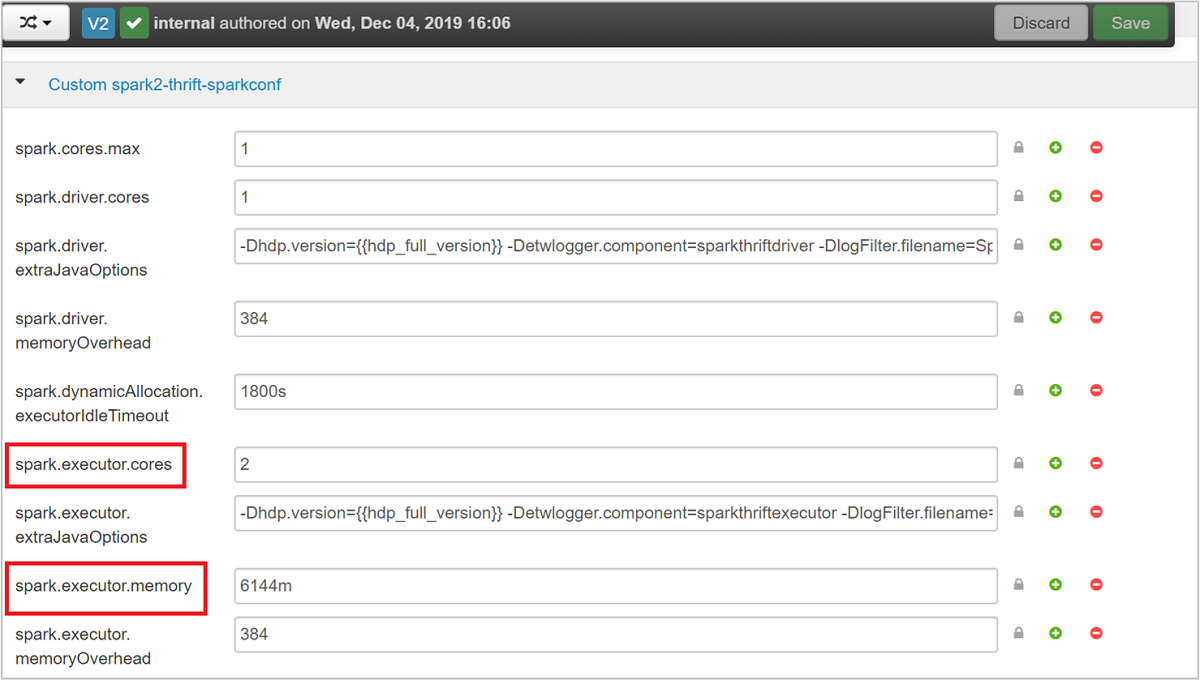
Modifier la mémoire du pilote du serveur Spark Thrift
La mémoire du pilote du serveur Spark Thrift est configurée sur 25 % de la taille de la mémoire RAM du nœud principal, sous réserve que la taille totale de la mémoire RAM du nœud principal soit supérieure à 14 Go. Vous pouvez utiliser l’interface utilisateur d’Ambari pour modifier la configuration de la mémoire du pilote, comme indiqué dans la capture d’écran suivante :
À partir de l’interface utilisateur Ambari, accédez à Spark2>Configurations>Advanced spark2-env. Indiquez ensuite la valeur pour spark_thrift_cmd_opts.
Récupérer des ressources de cluster Spark
En raison de l’allocation dynamique de Spark, les seules ressources consommées par le serveur Thrift sont celles des deux applications maîtres. Pour libérer ces ressources, vous devez arrêter l’exécution des services du serveur Thrift sur le cluster.
À partir de l’interface utilisateur Ambari, dans le volet gauche, cliquez sur Spark2.
Dans la page suivante, sélectionnez Serveur Spark2 Thrift.
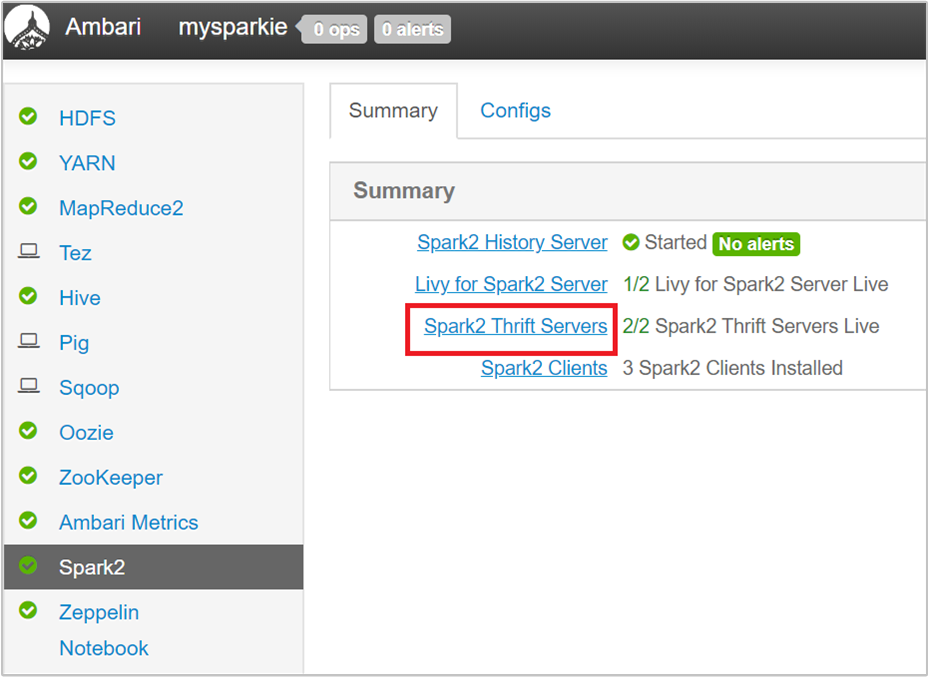
Vous devez voir les deux nœuds principaux sur lesquels le serveur Thrift Spark 2 s’exécute. Sélectionnez l’un des nœuds principaux.
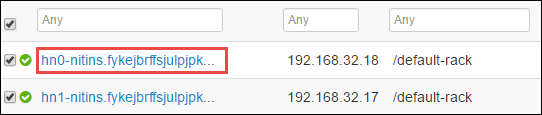
La page suivante répertorie tous les services exécutés sur ce nœud principal. Dans la liste, sélectionnez le bouton déroulant en regard de Spark 2 Thrift Server, puis sélectionnez Arrêter.
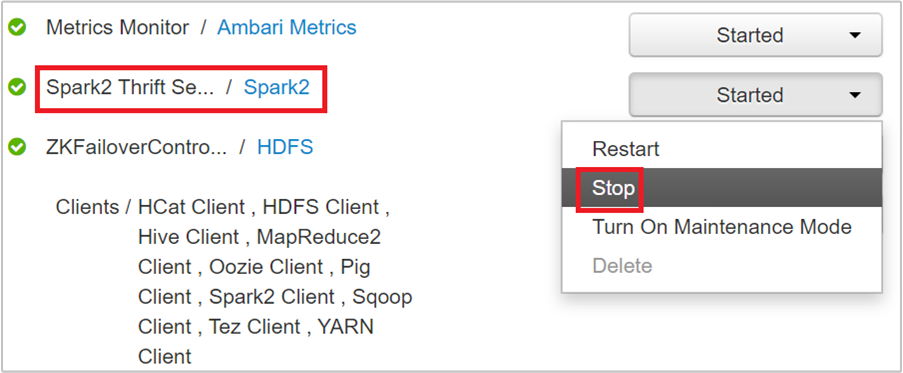
Répétez également ces étapes sur l’autre nœud principal.
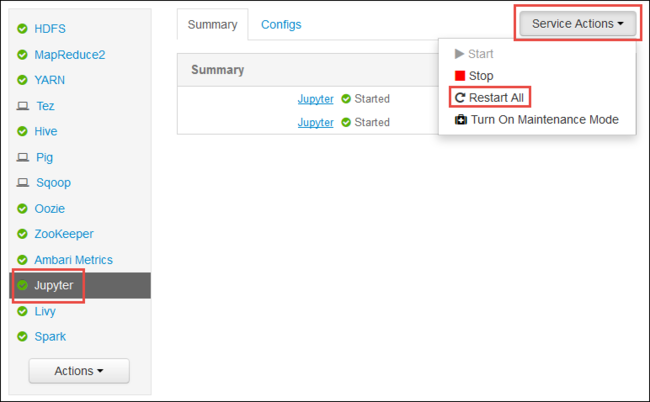
Redémarrer le service Jupyter
Lancez l’interface utilisateur web d’Ambari comme indiqué au début de l’article. Dans le volet de navigation gauche, sélectionnez Jupyter, sélectionnez Actions de service, puis Redémarrer tout. Cela démarre le service Jupyter sur tous les nœuds principaux.
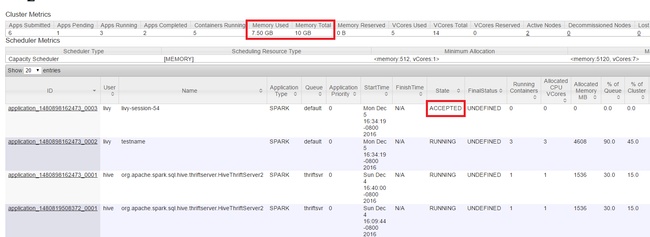
Surveiller les ressources
Lancez l’interface utilisateur Yarn comme indiqué au début de l’article. Dans la table des mesures de Cluster située en haut de l’écran, vérifiez les valeurs des colonnes Mémoire utilisée et Mémoire totale. Si les deux valeurs sont proches, le nombre de ressources ne sera peut-être pas suffisant pour démarrer l’application suivante. Cela s’applique également aux colonnes VCores utilisés et Total des VCores. En outre, dans la vue principale, si une application est restée dans l’état ACCEPTÉ et n’est pas passée à l’état EN COURS D’EXÉCUTION ou ÉCHEC, cela peut également indiquer que le nombre de ressources est insuffisant pour démarrer.
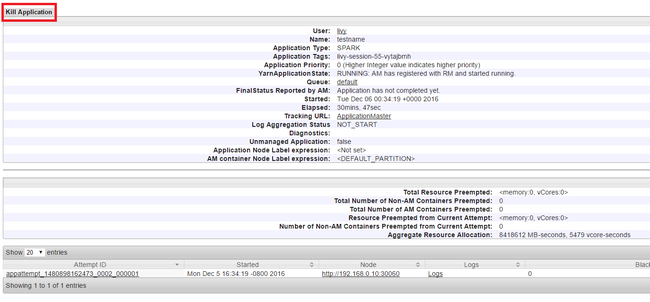
Arrêter les applications en cours d’exécution
Dans l’interface utilisateur Yarn, dans le volet gauche, sélectionnez En cours d’exécution. Dans la liste des applications en cours d’exécution, déterminez l’application à arrêter, puis sélectionnez l’ID.
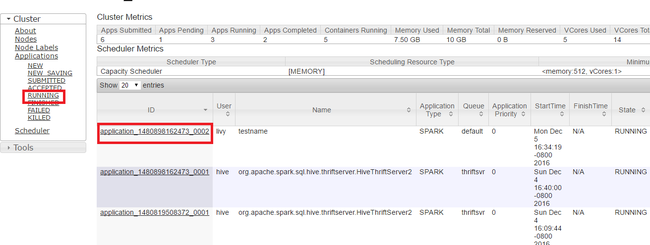
Sélectionnez Arrêter l’application dans le coin supérieur droit, puis OK.
Voir aussi
Pour les analystes de données
- Apache Spark avec Machine Learning : Utiliser Spark dans HDInsight pour analyser la température d’un bâtiment à l’aide de données issues des systèmes de chauffage, de ventilation et de climatisation
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour prédire les résultats de l’inspection d’aliments
- Analyse des journaux de site web à l’aide d’Apache Spark dans HDInsight
- Analyse de données de télémétrie Application Insight avec Spark dans HDInsight
Pour les développeurs Apache Spark
- Créer une application autonome avec Scala
- Exécuter des tâches à distance avec Apache Livy sur un cluster Apache Spark
- Utilisation du plugin d’outils HDInsight pour IntelliJ IDEA pour créer et soumettre des applications Spark Scala
- Utiliser le plug-in Azure HDInsight Tools pour IntelliJ IDEA afin de déboguer des applications Apache Spark à distance
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Noyaux disponibles pour bloc-notes Jupyter dans un cluster Apache Spark pour HDInsight
- Utiliser des packages externes avec des blocs-notes Jupyter
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)