Ce guide de démarrage rapide contient les étapes relatives aux kits SDK suivants :
Choisissez un langage de programmation pour l’étape suivante. Les bibliothèques clientes Azure.Search.Documents sont disponibles dans les kits SDK Azure pour .NET, Python, Java et JavaScript.
Créez une application console à l’aide de la bibliothèque cliente Azure.Search.Documents pour créer, charger et interroger un index de recherche. Vous pouvez également télécharger le code source pour commencer avec un projet terminé ou suivre les étapes décrites dans cet article pour créer votre propre projet.
Configurer votre environnement
Démarrez Visual Studio et créez un projet d’application console.
Dans Outils>Gestionnaire de package NuGet, sélectionnez Gérer les packages NuGet pour la solution... .
Sélectionnez Parcourir.
Recherchez le package Azure.Search.Documents et sélectionnez la version 11.0 ou une version ultérieure.
Sélectionnez Installer à droite pour ajouter l’assembly à vos projet et solution.
Créer un client de recherche
Dans Program.cs, remplacez l’espace de noms par AzureSearch.SDK.Quickstart.v11, puis ajoutez les directives using suivantes.
using Azure;
using Azure.Search.Documents;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Azure.Search.Documents.Models;
Créez deux clients : SearchIndexClient crée l’index et SearchClient charge et interroge un index existant. Tous deux ont besoin du point de terminaison de service et d’une clé API d’administration pour l’authentification avec des droits de création/suppression.
Étant donné que le code génère l’URI pour vous, spécifiez uniquement le nom du service de recherche dans la propriété « serviceName ».
static void Main(string[] args)
{
string serviceName = "<your-search-service-name>";
string apiKey = "<your-search-service-admin-api-key>";
string indexName = "hotels-quickstart";
// Create a SearchIndexClient to send create/delete index commands
Uri serviceEndpoint = new Uri($"https://{serviceName}.search.windows.net/");
AzureKeyCredential credential = new AzureKeyCredential(apiKey);
SearchIndexClient adminClient = new SearchIndexClient(serviceEndpoint, credential);
// Create a SearchClient to load and query documents
SearchClient srchclient = new SearchClient(serviceEndpoint, indexName, credential);
. . .
}
Création d'un index
Ce guide de démarrage rapide crée un index Hotels que vous allez charger avec des données sur des hôtels et sur lequel vous allez effectuer des requêtes. Dans cette étape, définissez les champs de l’index. Chaque définition de champ comprend un nom, un type de données et des attributs qui déterminent la façon dont le champ est utilisé.
Dans cet exemple, des méthodes synchrones de la bibliothèque Azure.Search.Documents sont utilisées à des fins de simplicité et de lisibilité. En revanche, dans des scénarios de production, vous devez utiliser des méthodes asynchrones pour maintenir la scalabilité et la réactivité de votre application. Par exemple, vous pouvez utiliser CreateIndexAsync au lieu de CreateIndex.
Ajoutez une définition de classe vide à votre projet : Hotel.cs
Copiez le code suivant dans Hotel.cs pour définir la structure d’un document d’hôtel. Les attributs du champ déterminent la façon dont il est utilisé dans une application. Par exemple, l’attribut IsFilterable doit être assigné à chaque champ qui prend en charge une expression de filtre.
using System;
using System.Text.Json.Serialization;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
namespace AzureSearch.Quickstart
{
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.FrLucene)]
[JsonPropertyName("Description_fr")]
public string DescriptionFr { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[SearchableField(IsFilterable = true, IsFacetable = true)]
public string[] Tags { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public bool? ParkingIncluded { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public DateTimeOffset? LastRenovationDate { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public double? Rating { get; set; }
[SearchableField]
public Address Address { get; set; }
}
}
Dans la bibliothèque de client Azure.Search.Documents, vous pouvez utiliser SearchableField et SimpleField pour simplifier les définitions de champs. Les deux sont des dérivés d’un SearchField et peuvent potentiellement simplifier votre code :
SimpleField peut être n’importe quel type de données, ne peut jamais faire l’objet d’une recherche (il est ignoré pour les requêtes de recherche de texte intégral) et peut être récupéré (il n’est pas masqué). Les autres attributs sont désactivés par défaut, mais peuvent être activés. Vous pouvez utiliser un SimpleField pour les ID de document ou les champs utilisés seulement dans des filtres, des facettes ou des profils de scoring. Dans ce cas, veillez à appliquer tous les attributs nécessaires pour le scénario, comme IsKey = true pour un ID de document. Pour plus d’informations, consultez SimpleFieldAttribute.cs dans le code source.
SearchableField doit être une chaîne, et peut toujours faire l’objet d’une recherche et d’une récupération. Les autres attributs sont désactivés par défaut, mais peuvent être activés. Comme ce type de champ peut faire l’objet d’une recherche, il prend en charge les synonymes et l’ensemble complet des propriétés de l’analyseur. Pour plus d’informations, consultez SearchableFieldAttribute.cs dans le code source.
Que vous utilisiez l’API SearchField de base ou un des modèles d’assistance, vous devez activer explicitement les attributs de filtre, de facette et de tri. Par exemple, les attributs IsFilterable, IsSortable et IsFacetable doivent être explicitement attribués, comme illustré dans l’exemple ci-dessus.
Ajoutez une deuxième définition de classe vide à votre projet : Address.cs. Copiez le code suivant dans la classe.
using Azure.Search.Documents.Indexes;
namespace AzureSearch.Quickstart
{
public partial class Address
{
[SearchableField(IsFilterable = true)]
public string StreetAddress { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string City { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string StateProvince { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string PostalCode { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Country { get; set; }
}
}
Créez deux autres classes : Hotel.Methods.cs et Address.Methods.cs pour les substitutions ToString(). Ces classes servent à afficher les résultats de la recherche dans la sortie de la console. Le contenu de ces classes n’est pas fourni dans cet article, mais vous pouvez copier le code à partir de fichiers dans GitHub.
Dans Program.cs, créez un objet SearchIndex, puis appelez la méthode CreateIndex pour exprimer l’index dans votre service de recherche. L’index comprend également un SearchSuggester pour activer l’autocomplétion sur les champs spécifiés.
// Create hotels-quickstart index
private static void CreateIndex(string indexName, SearchIndexClient adminClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
adminClient.CreateOrUpdateIndex(definition);
}
Chargement de documents
La recherche Azure AI effectue des recherches parmi les contenus stockés dans le service. Au cours de cette étape, vous allez charger des documents JSON conformes à l’index de l’hôtel que vous venez de créer.
Dans la recherche Azure AI, les documents de recherche sont des structures de données qui sont à la fois des entrées pour l’indexation et des sorties de requêtes. Selon une source de données externe, les entrées de documents peuvent être des lignes dans une base de données, des objets blob dans le Stockage Blob ou des documents JSON sur le disque. Dans cet exemple, nous prenons un raccourci et incorporons des documents JSON pour quatre hôtels dans le code lui-même.
Lors du chargement de documents, vous devez utiliser un objet IndexDocumentsBatch. Un objet IndexDocumentsBatch contient une collection d’Actions, chacune contenant un document et une propriété qui indiquent à la recherche Azure AI l’action à effectuer (upload, merge, delete et mergeOrUpload).
Dans Program.cs, créez un tableau des documents et des actions d’index, puis passez le tableau à IndexDocumentsBatch. Les documents ci-dessous sont conformes à l’index hotels-quickstart, tel que défini par la classe hotel.
// Upload documents in a single Upload request.
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Secret Point Motel",
Description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
DescriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
Category = "Boutique",
Tags = new[] { "pool", "air conditioning", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1970, 1, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.6,
Address = new Address()
{
StreetAddress = "677 5th Ave",
City = "New York",
StateProvince = "NY",
PostalCode = "10022",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Twin Dome Motel",
Description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Boutique",
Tags = new[] { "pool", "free wifi", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1979, 2, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.60,
Address = new Address()
{
StreetAddress = "140 University Town Center Dr",
City = "Sarasota",
StateProvince = "FL",
PostalCode = "34243",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Triple Landscape Hotel",
Description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Resort and Spa",
Tags = new[] { "air conditioning", "bar", "continental breakfast" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(2015, 9, 20, 0, 0, 0, TimeSpan.Zero),
Rating = 4.80,
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
City = "Atlanta",
StateProvince = "GA",
PostalCode = "30326",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "4",
HotelName = "Sublime Cliff Hotel",
Description = "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.",
DescriptionFr = "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.",
Category = "Boutique",
Tags = new[] { "concierge", "view", "24-hour front desk service" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(1960, 2, 06, 0, 0, 0, TimeSpan.Zero),
Rating = 4.60,
Address = new Address()
{
StreetAddress = "7400 San Pedro Ave",
City = "San Antonio",
StateProvince = "TX",
PostalCode = "78216",
Country = "USA"
}
})
);
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs the failed document keys and continues.
Console.WriteLine("Failed to index some of the documents: {0}");
}
}
Une fois que vous avez initialisé l’objet IndexDocumentsBatch, vous pouvez l’envoyer à l’index en appelant IndexDocuments sur votre objet SearchClient.
Ajoutez les lignes suivantes à Main(). Le chargement de documents s’effectue à l’aide de SearchClient, mais l’opération nécessite également des droits d’administrateur sur le service, généralement associé à SearchIndexClient. L’une des manières de configurer cette opération consiste à récupérer SearchClient par le biais de SearchIndexClient (adminClient dans cet exemple).
SearchClient ingesterClient = adminClient.GetSearchClient(indexName);
// Load documents
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(ingesterClient);
Étant donné qu’il s’agit d’une application console qui exécute toutes les commandes de manière séquentielle, ajoutez un délai d’attente de 2 secondes entre l’indexation et les requêtes.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
Console.WriteLine("Waiting for indexing...\n");
System.Threading.Thread.Sleep(2000);
Le retard de 2 secondes compense l’indexation, qui est asynchrone, afin que tous les documents puissent être indexés avant l’exécution des requêtes. Le codage dans un retard n’est nécessaire que dans les démonstrations, les tests et les exemples d’applications.
Rechercher dans un index
Vous pouvez obtenir les résultats de la requête dès que le premier document est indexé, mais les tests réels de votre index doivent attendre que tous les documents soient indexés.
Cette section ajoute deux éléments de fonctionnalité : logique de requête et résultats. Pour les requêtes, utilisez la méthode Search. Cette méthode prend le texte de recherche (la chaîne de requête) ainsi que d’autres options.
La classe SearchResults représente les résultats.
Dans Program.cs, créez une méthode WriteDocuments qui affiche les résultats de la recherche sur la console.
// Write search results to console
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
private static void WriteDocuments(AutocompleteResults autoResults)
{
foreach (AutocompleteItem result in autoResults.Results)
{
Console.WriteLine(result.Text);
}
Console.WriteLine();
}
Créez une méthode RunQueries pour exécuter des requêtes et retourner des résultats. Les résultats sont des objets Hotel. Cet exemple montre la signature de la méthode et la première requête. Cette requête montre le paramètre Select qui vous permet de composer le résultat à l’aide de champs sélectionnés à partir du document.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient srchclient)
{
SearchOptions options;
SearchResults<Hotel> response;
// Query 1
Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
options = new SearchOptions()
{
IncludeTotalCount = true,
Filter = "",
OrderBy = { "" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Address/City");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
Dans la deuxième requête, recherchez un terme, ajoutez un filtre qui sélectionne les documents dont l’évaluation est supérieure à 4, puis triez par évaluation dans l’ordre décroissant. Un filtre est une expression booléenne évaluée sur des champs IsFilterable dans un index. Les requêtes de filtre incluent ou excluent des valeurs. Par conséquent, aucun score de pertinence n’est associé à une requête de filtre.
// Query 2
Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions()
{
Filter = "Rating gt 4",
OrderBy = { "Rating desc" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Rating");
response = srchclient.Search<Hotel>("hotels", options);
WriteDocuments(response);
La troisième requête illustre l’utilisation de searchFields, qui sert à limiter l’étendue d’une opération de recherche en texte intégral à des champs spécifiques.
// Query 3
Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions()
{
SearchFields = { "Tags" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Tags");
response = srchclient.Search<Hotel>("pool", options);
WriteDocuments(response);
La quatrième requête montre des facettes, qui peuvent être utilisées pour créer une structure de navigation à facettes.
// Query 4
Console.WriteLine("Query #4: Facet on 'Category'...\n");
options = new SearchOptions()
{
Filter = ""
};
options.Facets.Add("Category");
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Category");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
La cinquième requête retourne un document spécifique. Une recherche de document est une réponse classique à l’événement OnClick dans un jeu de résultats.
// Query 5
Console.WriteLine("Query #5: Look up a specific document...\n");
Response<Hotel> lookupResponse;
lookupResponse = srchclient.GetDocument<Hotel>("3");
Console.WriteLine(lookupResponse.Value.HotelId);
La dernière requête affiche la syntaxe pour l’autocomplétion ; elle simule une entrée utilisateur partielle « sa » qui est résolue en deux correspondances possibles dans les sourceFields associés au suggesteur que vous avez défini dans l’index.
// Query 6
Console.WriteLine("Query #6: Call Autocomplete on HotelName that starts with 'sa'...\n");
var autoresponse = srchclient.Autocomplete("sa", "sg");
WriteDocuments(autoresponse);
Ajoutez RunQueries à Main().
// Call the RunQueries method to invoke a series of queries
Console.WriteLine("Starting queries...\n");
RunQueries(srchclient);
// End the program
Console.WriteLine("{0}", "Complete. Press any key to end this program...\n");
Console.ReadKey();
Les requêtes précédentes illustrent plusieurs manières d’établir des correspondances entre des termes dans une requête : recherche en texte intégral, filtres et autocomplétion.
La recherche en texte intégral et les filtres sont exécutés à l’aide de la méthode SearchClient.Search. Une requête de recherche peut être transmise dans la chaîne searchText, tandis qu’une expression de filtre peut être transmise dans la propriété Filter de la classe SearchOptions. Pour filtrer sans effectuer de recherche, transmettez simplement "*" pour le paramètre searchText de la méthode Search. Pour effectuer une recherche sans filtrage, ne définissez pas la propriété Filter et ne transmettez aucune instance SearchOptions.
Exécuter le programme
Appuyez sur F5 pour regénérer l’application et exécuter le programme dans son intégralité.
La sortie comprend des messages de la méthode Console.WriteLine, avec en plus des informations et des résultats de requête.
Utilisez un notebook Jupyter et la bibliothèque azure-search-documents dans le Kit de développement logiciel (SDK) Azure pour Python pour créer, charger et interroger un index de recherche.
Vous pouvez également télécharger et exécuter un notebook terminé.
Paramétrer votre environnement
Utilisez Visual Studio Code avec l’extension Python, ou un IDE équivalent, avec Python 3.10 ou version ultérieure.
Nous vous recommandons un environnement virtuel pour ce démarrage rapide :
Démarrez Visual Studio Code.
Ouvrez la Palette de commandes (Ctrl+Maj+P).
Recherchez Python : Créer un environnement.
Sélectionnez Venv.
Sélectionnez un interpréteur Python. Choisissez la version 3.10 ou ultérieure.
La configuration peut prendre une minute. Si vous rencontrez des problèmes, consultez Environnements Python dans VS Code.
Installer des packages et définir des variables
Installez des packages, y compris azure-search-documents.
! pip install azure-search-documents==11.6.0b1 --quiet
! pip install azure-identity --quiet
! pip install python-dotenv --quiet
Fournissez des clés de point de terminaison et d’API :
search_endpoint: str = "PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE"
search_api_key: str = "PUT-YOUR-SEARCH-SERVICE-ADMIN-API-KEY-HERE"
index_name: str = "hotels-quickstart"
Création d'un index
from azure.core.credentials import AzureKeyCredential
credential = AzureKeyCredential(search_api_key)
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
ComplexField,
SimpleField,
SearchFieldDataType,
SearchableField,
SearchIndex
)
# Create a search schema
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
fields = [
SimpleField(name="HotelId", type=SearchFieldDataType.String, key=True),
SearchableField(name="HotelName", type=SearchFieldDataType.String, sortable=True),
SearchableField(name="Description", type=SearchFieldDataType.String, analyzer_name="en.lucene"),
SearchableField(name="Description_fr", type=SearchFieldDataType.String, analyzer_name="fr.lucene"),
SearchableField(name="Category", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Tags", collection=True, type=SearchFieldDataType.String, facetable=True, filterable=True),
SimpleField(name="ParkingIncluded", type=SearchFieldDataType.Boolean, facetable=True, filterable=True, sortable=True),
SimpleField(name="LastRenovationDate", type=SearchFieldDataType.DateTimeOffset, facetable=True, filterable=True, sortable=True),
SimpleField(name="Rating", type=SearchFieldDataType.Double, facetable=True, filterable=True, sortable=True),
ComplexField(name="Address", fields=[
SearchableField(name="StreetAddress", type=SearchFieldDataType.String),
SearchableField(name="City", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="StateProvince", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="PostalCode", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Country", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
])
]
scoring_profiles = []
suggester = [{'name': 'sg', 'source_fields': ['Tags', 'Address/City', 'Address/Country']}]
# Create the search index=
index = SearchIndex(name=index_name, fields=fields, suggesters=suggester, scoring_profiles=scoring_profiles)
result = index_client.create_or_update_index(index)
print(f' {result.name} created')
Créer une charge utile de documents
Utilisez une action d’index correspondant au type d’opération (charger, fusionner et charger, etc.). Les documents proviennent de HotelsData sur GitHub.
# Create a documents payload
documents = [
{
"@search.action": "upload",
"HotelId": "1",
"HotelName": "Secret Point Motel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": [ "pool", "air conditioning", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "2",
"HotelName": "Twin Dome Motel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": [ "pool", "free wifi", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "3",
"HotelName": "Triple Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": [ "air conditioning", "bar", "continental breakfast" ],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.80,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "4",
"HotelName": "Sublime Cliff Hotel",
"Description": "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.",
"Description_fr": "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": [ "concierge", "view", "24-hour front desk service" ],
"ParkingIncluded": "true",
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.60,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216",
"Country": "USA"
}
}
]
Chargement de documents
# Upload documents to the index
search_client = SearchClient(endpoint=search_endpoint,
index_name=index_name,
credential=credential)
try:
result = search_client.upload_documents(documents=documents)
print("Upload of new document succeeded: {}".format(result[0].succeeded))
except Exception as ex:
print (ex.message)
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
Exécuter votre première requête
Utilisez la méthode search de la classe search.client.
Cet exemple exécute une recherche vide (search=*), qui retourne une liste non classée (score de recherche = 1.0) de documents arbitraires. Étant donné qu’il n’y a aucun critère, tous les documents sont inclus dans les résultats.
# Run an empty query (returns selected fields, all documents)
results = search_client.search(query_type='simple',
search_text="*" ,
select='HotelName,Description',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Exécuter une requête de terme
La requête suivante ajoute des termes entiers à l’expression de recherche (« wifi »). Cette requête spécifie que les résultats contiennent uniquement les champs de l’instruction select. Le fait de limiter les champs de retour réduit la quantité de données renvoyées sur le réseau ainsi que la latence de recherche.
results = search_client.search(query_type='simple',
search_text="wifi" ,
select='HotelName,Description,Tags',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Ajouter un filtre
Ajoutez une expression de filtre afin de retourner uniquement les hôtels ayant une évaluation supérieure à quatre, triés par ordre décroissant.
# Add a filter
results = search_client.search(
search_text="hotels",
select='HotelId,HotelName,Rating',
filter='Rating gt 4',
order_by='Rating desc')
for result in results:
print("{}: {} - {} rating".format(result["HotelId"], result["HotelName"], result["Rating"]))
Ajouter une étendue de champ
Ajoutez search_fields pour étendre l’exécution de la requête sur des champs spécifiques.
# Add search_fields to scope query matching to the HotelName field
results = search_client.search(
search_text="sublime",
search_fields=['HotelName'],
select='HotelId,HotelName')
for result in results:
print("{}: {}".format(result["HotelId"], result["HotelName"]))
Ajouter des facettes
Les facettes sont générées pour les correspondances positives trouvées dans les résultats de recherche. Il n’y a pas de correspondance nulle. Si les résultats de la recherche n’incluent pas le terme "wifi", alors "wifi" n’apparaît pas dans la structure de navigation par facettes.
# Return facets
results = search_client.search(search_text="*", facets=["Category"])
facets = results.get_facets()
for facet in facets["Category"]:
print(" {}".format(facet))
Rechercher un document
Retourne un document en fonction de sa clé. Cette opération est utile si vous souhaitez fournir une extraction quand un utilisateur sélectionne un élément dans un résultat de recherche.
# Look up a specific document by ID
result = search_client.get_document(key="3")
print("Details for hotel '3' are:")
print("Name: {}".format(result["HotelName"]))
print("Rating: {}".format(result["Rating"]))
print("Category: {}".format(result["Category"]))
Ajouter l’autocomplétion
L’autocomplétion peut fournir des correspondances potentielles au fur et à mesure que l’utilisateur tape dans la zone de recherche.
L’autocomplétion utilise un suggesteur (sg) pour savoir quels champs contiennent des correspondances potentielles aux demandes du suggesteur. Dans ce guide de démarrage rapide, ces champs sont Tags, Address/City et Address/Country.
Pour simuler l’autocomplétion, passez les lettres « sa » en tant que chaîne partielle. La méthode d’autocomplétion de SearchClient renvoie les correspondances de termes potentielles.
# Autocomplete a query
search_suggestion = 'sa'
results = search_client.autocomplete(
search_text=search_suggestion,
suggester_name="sg",
mode='twoTerms')
print("Autocomplete for:", search_suggestion)
for result in results:
print (result['text'])
Créez une application console Java à l’aide de la bibliothèque Azure.Search.Documents pour créer, charger et interroger un index de recherche. Vous pouvez également télécharger le code source pour commencer avec un projet terminé ou suivre les étapes décrites dans cet article pour créer votre propre projet.
Configurer votre environnement
Nous avons utilisé les outils suivants pour créer ce guide de démarrage rapide.
Créer le projet
Démarrez Visual Studio Code.
Ouvrez la Palette de commandes (Ctrl+Maj+P). Recherchez Créer un projet Java.

Sélectionnez Maven.
Sélectionnez maven-archetype-quickstart.
Sélectionnez le numéro de version le plus récent, actuellement 1.4.

Entrez azure.search.sample comme ID de groupe.
Entrez azuresearchquickstart comme ID d’artefact.

Sélectionnez le dossier dans lequel créer le projet.
Terminez la création du projet dans le terminal intégré. Appuyez sur Entrée pour accepter la valeur par défaut pour « 1.0-SNAPSHOT », puis tapez « y » pour confirmer les propriétés de votre projet.
Ouvrez le dossier dans lequel vous avez créé le projet.
Spécifier les dépendances Maven
Ouvrir le fichier pom.xml et ajouter les dépendances suivantes
<dependencies>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-search-documents</artifactId>
<version>11.5.2</version>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-core</artifactId>
<version>1.34.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
Remplacer la version Java du compilateur par 11
<maven.compiler.source>1.11</maven.compiler.source>
<maven.compiler.target>1.11</maven.compiler.target>
Créer un client de recherche
Ouvrez la classe App sous src, main, java, azure, search, sample. Ajouter les directives d’importation suivantes
import java.util.Arrays;
import java.util.ArrayList;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.LocalDateTime;
import java.time.LocalDate;
import java.time.LocalTime;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.Context;
import com.azure.search.documents.SearchClient;
import com.azure.search.documents.SearchClientBuilder;
import com.azure.search.documents.models.SearchOptions;
import com.azure.search.documents.indexes.SearchIndexClient;
import com.azure.search.documents.indexes.SearchIndexClientBuilder;
import com.azure.search.documents.indexes.models.IndexDocumentsBatch;
import com.azure.search.documents.indexes.models.SearchIndex;
import com.azure.search.documents.indexes.models.SearchSuggester;
import com.azure.search.documents.util.AutocompletePagedIterable;
import com.azure.search.documents.util.SearchPagedIterable;
L’exemple suivant comprend des espaces réservés pour un nom de service de recherche, une clé API d’administration qui accorde des autorisations de création et de suppression, et un nom d’index. Fournissez les valeurs valides pour les trois espaces réservés. Créez deux clients : SearchIndexClient crée l’index et SearchClient charge et interroge un index existant. Tous deux ont besoin du point de terminaison de service et d’une clé API d’administration pour l’authentification avec des droits de création et de suppression.
public static void main(String[] args) {
var searchServiceEndpoint = "<YOUR-SEARCH-SERVICE-URL>";
var adminKey = new AzureKeyCredential("<YOUR-SEARCH-SERVICE-ADMIN-KEY>");
String indexName = "<YOUR-SEARCH-INDEX-NAME>";
SearchIndexClient searchIndexClient = new SearchIndexClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.buildClient();
SearchClient searchClient = new SearchClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.indexName(indexName)
.buildClient();
}
Création d'un index
Ce guide de démarrage rapide crée un index Hotels que vous allez charger avec des données sur des hôtels et sur lequel vous allez effectuer des requêtes. Dans cette étape, définissez les champs de l’index. Chaque définition de champ comprend un nom, un type de données et des attributs qui déterminent la façon dont le champ est utilisé.
Dans cet exemple, des méthodes synchrones de la bibliothèque azure-search-documents sont utilisées pour que ce soit simple et lisible. En revanche, dans des scénarios de production, vous devez utiliser des méthodes asynchrones pour maintenir la scalabilité et la réactivité de votre application. Par exemple, vous utiliseriez SearchAsyncClient plutôt que SearchClient.
Ajoutez une définition de classe vide à votre projet : Hotel.java
Copiez le code suivant dans Hotel.java pour définir la structure d’un document d’hôtel. Les attributs du champ déterminent la façon dont il est utilisé dans une application. Par exemple, l’annotation IsFilterable doit être attribuée à chaque champ qui prend en charge une expression de filtre.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.azure.search.documents.indexes.SimpleField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import java.time.OffsetDateTime;
/**
* Model class representing a hotel.
*/
@JsonInclude(Include.NON_NULL)
public class Hotel {
/**
* Hotel ID
*/
@JsonProperty("HotelId")
@SimpleField(isKey = true)
public String hotelId;
/**
* Hotel name
*/
@JsonProperty("HotelName")
@SearchableField(isSortable = true)
public String hotelName;
/**
* Description
*/
@JsonProperty("Description")
@SearchableField(analyzerName = "en.microsoft")
public String description;
/**
* French description
*/
@JsonProperty("DescriptionFr")
@SearchableField(analyzerName = "fr.lucene")
public String descriptionFr;
/**
* Category
*/
@JsonProperty("Category")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String category;
/**
* Tags
*/
@JsonProperty("Tags")
@SearchableField(isFilterable = true, isFacetable = true)
public String[] tags;
/**
* Whether parking is included
*/
@JsonProperty("ParkingIncluded")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Boolean parkingIncluded;
/**
* Last renovation time
*/
@JsonProperty("LastRenovationDate")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public OffsetDateTime lastRenovationDate;
/**
* Rating
*/
@JsonProperty("Rating")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Double rating;
/**
* Address
*/
@JsonProperty("Address")
public Address address;
@Override
public String toString()
{
try
{
return new ObjectMapper().writeValueAsString(this);
}
catch (JsonProcessingException e)
{
e.printStackTrace();
return "";
}
}
}
Dans la bibliothèque de client Azure.Search.Documents, vous pouvez utiliser SearchableField et SimpleField pour simplifier les définitions de champs.
SimpleField peut être n’importe quel type de données, ne peut jamais faire l’objet d’une recherche (il est ignoré pour les requêtes de recherche de texte intégral) et peut être récupéré (il n’est pas masqué). Les autres attributs sont désactivés par défaut, mais peuvent être activés. Vous pouvez utiliser un SimpleField pour les ID de document ou les champs utilisés seulement dans des filtres, des facettes ou des profils de scoring. Si c’est le cas, veillez à appliquer tous les attributs nécessaires pour le scénario, comme IsKey = true pour un ID de document.SearchableField doit être une chaîne, et peut toujours faire l’objet d’une recherche et d’une récupération. Les autres attributs sont désactivés par défaut, mais peuvent être activés. Comme ce type de champ peut faire l’objet d’une recherche, il prend en charge les synonymes et l’ensemble complet des propriétés de l’analyseur.
Que vous utilisiez l’API SearchField de base ou un des modèles d’assistance, vous devez activer explicitement les attributs de filtre, de facette et de tri. Par exemple, les attributs isFilterable, isSortable et isFacetable doivent être explicitement attribués, comme illustré dans l’exemple ci-dessus.
Ajoutez une deuxième définition de classe vide à votre projet : Address.cs. Copiez le code suivant dans la classe.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
/**
* Model class representing an address.
*/
@JsonInclude(Include.NON_NULL)
public class Address {
/**
* Street address
*/
@JsonProperty("StreetAddress")
@SearchableField
public String streetAddress;
/**
* City
*/
@JsonProperty("City")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String city;
/**
* State or province
*/
@JsonProperty("StateProvince")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String stateProvince;
/**
* Postal code
*/
@JsonProperty("PostalCode")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String postalCode;
/**
* Country
*/
@JsonProperty("Country")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String country;
}
Dans App.java, créez un objet SearchIndex dans la méthode main, puis appelez la méthode createOrUpdateIndex pour créer l’index dans votre service de recherche. L’index comprend également un SearchSuggester pour activer l’autocomplétion sur les champs spécifiés.
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
Charger des documents
La recherche Azure AI effectue des recherches parmi les contenus stockés dans le service. Au cours de cette étape, vous allez charger des documents JSON conformes à l’index de l’hôtel que vous venez de créer.
Dans la recherche Azure AI, les documents de recherche sont des structures de données qui sont à la fois des entrées pour l’indexation et des sorties de requêtes. Selon une source de données externe, les entrées de documents peuvent être des lignes dans une base de données, des objets blob dans le Stockage Blob ou des documents JSON sur le disque. Dans cet exemple, nous prenons un raccourci et incorporons des documents JSON pour quatre hôtels dans le code lui-même.
Lors du chargement de documents, vous devez utiliser un objet IndexDocumentsBatch. Un objet IndexDocumentsBatch contient une collection d’IndexActions, chacune contenant un document et une propriété qui indiquent à la recherche Azure AI l’action à effectuer (upload, merge, delete et mergeOrUpload).
Dans App.java, créez des documents et des actions d’index, puis passez-les à IndexDocumentsBatch. Les documents ci-dessous sont conformes à l’index hotels-quickstart, tel que défini par la classe hotel.
// Upload documents in a single Upload request.
private static void uploadDocuments(SearchClient searchClient)
{
var hotelList = new ArrayList<Hotel>();
var hotel = new Hotel();
hotel.hotelId = "1";
hotel.hotelName = "Secret Point Motel";
hotel.description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.";
hotel.descriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "air conditioning", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1970, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.6;
hotel.address = new Address();
hotel.address.streetAddress = "677 5th Ave";
hotel.address.city = "New York";
hotel.address.stateProvince = "NY";
hotel.address.postalCode = "10022";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "2";
hotel.hotelName = "Twin Dome Motel";
hotel.description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "free wifi", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1979, 2, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.60;
hotel.address = new Address();
hotel.address.streetAddress = "140 University Town Center Dr";
hotel.address.city = "Sarasota";
hotel.address.stateProvince = "FL";
hotel.address.postalCode = "34243";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "3";
hotel.hotelName = "Triple Landscape Hotel";
hotel.description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Resort and Spa";
hotel.tags = new String[] { "air conditioning", "bar", "continental breakfast" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2015, 9, 20), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.80;
hotel.address = new Address();
hotel.address.streetAddress = "3393 Peachtree Rd";
hotel.address.city = "Atlanta";
hotel.address.stateProvince = "GA";
hotel.address.postalCode = "30326";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "4";
hotel.hotelName = "Sublime Cliff Hotel";
hotel.description = "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.";
hotel.descriptionFr = "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.";
hotel.category = "Boutique";
hotel.tags = new String[] { "concierge", "view", "24-hour front desk service" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1960, 2, 06), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.60;
hotel.address = new Address();
hotel.address.streetAddress = "7400 San Pedro Ave";
hotel.address.city = "San Antonio";
hotel.address.stateProvince = "TX";
hotel.address.postalCode = "78216";
hotel.address.country = "USA";
hotelList.add(hotel);
var batch = new IndexDocumentsBatch<Hotel>();
batch.addMergeOrUploadActions(hotelList);
try
{
searchClient.indexDocuments(batch);
}
catch (Exception e)
{
e.printStackTrace();
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs failure and continues
System.err.println("Failed to index some of the documents");
}
}
Une fois que vous avez initialisé l’objet IndexDocumentsBatch, vous pouvez l’envoyer à l’index en appelant indexDocuments sur votre objet SearchClient.
Ajoutez les lignes suivantes à Main(). Le chargement de documents s’effectue à l’aide de SearchClient.
// Upload sample hotel documents to the Search Index
uploadDocuments(searchClient);
Étant donné qu’il s’agit d’une application console qui exécute toutes les commandes de manière séquentielle, ajoutez un délai d’attente de 2 secondes entre l’indexation et les requêtes.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
System.out.println("Waiting for indexing...\n");
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
}
Le retard de 2 secondes compense l’indexation, qui est asynchrone, afin que tous les documents puissent être indexés avant l’exécution des requêtes. Le codage dans un retard n’est nécessaire que dans les démonstrations, les tests et les exemples d’applications.
Rechercher dans un index
Vous pouvez obtenir les résultats de la requête dès que le premier document est indexé, mais les tests réels de votre index doivent attendre que tous les documents soient indexés.
Cette section ajoute deux éléments de fonctionnalité : logique de requête et résultats. Pour les requêtes, utilisez la méthode Search. Cette méthode prend le texte de recherche (la chaîne de requête) ainsi que d’autres options.
Dans App.java, créez une méthode WriteDocuments qui affiche les résultats de la recherche sur la console.
// Write search results to console
private static void WriteSearchResults(SearchPagedIterable searchResults)
{
searchResults.iterator().forEachRemaining(result ->
{
Hotel hotel = result.getDocument(Hotel.class);
System.out.println(hotel);
});
System.out.println();
}
// Write autocomplete results to console
private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults)
{
autocompleteResults.iterator().forEachRemaining(result ->
{
String text = result.getText();
System.out.println(text);
});
System.out.println();
}
Créez une méthode RunQueries pour exécuter des requêtes et retourner des résultats. Les résultats sont des objets Hotel. Cet exemple montre la signature de la méthode et la première requête. Cette requête montre le paramètre Select qui vous permet de composer le résultat à l’aide de champs sélectionnés dans le document.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
// Query 1
System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
SearchOptions options = new SearchOptions();
options.setIncludeTotalCount(true);
options.setFilter("");
options.setOrderBy("");
options.setSelect("HotelId", "HotelName", "Address/City");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
}
Dans la deuxième requête, recherchez un terme, ajoutez un filtre qui sélectionne les documents dont l’évaluation est supérieure à 4, puis triez par évaluation dans l’ordre décroissant. Un filtre est une expression booléenne évaluée sur des champs isFilterable dans un index. Les requêtes de filtre incluent ou excluent des valeurs. Par conséquent, aucun score de pertinence n’est associé à une requête de filtre.
// Query 2
System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions();
options.setFilter("Rating gt 4");
options.setOrderBy("Rating desc");
options.setSelect("HotelId", "HotelName", "Rating");
WriteSearchResults(searchClient.search("hotels", options, Context.NONE));
La troisième requête illustre l’utilisation de searchFields, qui sert à limiter l’étendue d’une opération de recherche en texte intégral à des champs spécifiques.
// Query 3
System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions();
options.setSearchFields("Tags");
options.setSelect("HotelId", "HotelName", "Tags");
WriteSearchResults(searchClient.search("pool", options, Context.NONE));
La quatrième requête montre des facettes, qui peuvent être utilisées pour créer une structure de navigation à facettes.
// Query 4
System.out.println("Query #4: Facet on 'Category'...\n");
options = new SearchOptions();
options.setFilter("");
options.setFacets("Category");
options.setSelect("HotelId", "HotelName", "Category");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
La cinquième requête retourne un document spécifique.
// Query 5
System.out.println("Query #5: Look up a specific document...\n");
Hotel lookupResponse = searchClient.getDocument("3", Hotel.class);
System.out.println(lookupResponse.hotelId);
System.out.println();
La dernière requête montre la syntaxe pour l’autocomplétion, en simulant une entrée utilisateur partielle « s » qui est résolue en deux correspondances possibles dans les sourceFields associés au suggesteur que vous avez défini dans l’index.
// Query 6
System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n");
WriteAutocompleteResults(searchClient.autocomplete("s", "sg"));
Ajoutez RunQueries à Main().
// Call the RunQueries method to invoke a series of queries
System.out.println("Starting queries...\n");
RunQueries(searchClient);
// End the program
System.out.println("Complete.\n");
Les requêtes précédentes illustrent plusieurs manières d’établir des correspondances entre des termes dans une requête : recherche en texte intégral, filtres et autocomplétion.
La recherche en texte intégral et les filtres sont exécutés à l’aide de la méthode SearchClient.search. Une requête de recherche peut être transmise dans la chaîne searchText, tandis qu’une expression de filtre peut être transmise dans la propriété filter de la classe SearchOptions. Pour filtrer sans effectuer de recherche, transmettez simplement « * » pour le paramètre searchText de la méthode search. Pour effectuer une recherche sans filtrage, ne définissez pas la propriété filter et ne transmettez aucune instance SearchOptions.
Exécuter le programme
Appuyez sur F5 pour regénérer l’application et exécuter le programme dans son intégralité.
La sortie comprend des messages de System.out.println, avec en plus des informations et des résultats de requête.
Créez une application console Node.js à l’aide de la bibliothèque @azure/search-documents pour créer, charger et interroger un index de recherche. Vous pouvez également télécharger le code source pour commencer avec un projet terminé ou suivre les étapes décrites dans cet article pour créer votre propre projet.
Configurer votre environnement
Nous avons utilisé les outils suivants pour créer ce guide de démarrage rapide.
Créer le projet
Démarrez Visual Studio Code.
Ouvrez la palette de commandes Ctrl+Maj+P, puis ouvrez le terminal intégré.
Créez un répertoire de développement, que vous appellerez quickstart :
mkdir quickstart
cd quickstart
Initialisez un projet vide avec npm en exécutant la commande suivante. Pour initialiser entièrement le projet, appuyez plusieurs fois sur Entrée pour accepter les valeurs par défaut, sauf pour la licence, que vous devez définir sur « MIT ».
npm init
Installez @azure/search-documents, le Kit de développement logiciel (SDK) JavaScript/TypeScript pour la recherche Azure AI.
npm install @azure/search-documents
Installez dotenv, qui est utilisé pour importer les variables d’environnement, comme le nom de votre service de recherche et de votre clé d’API.
npm install dotenv
Vérifiez que vous avez configuré les projets et leurs dépendances en regardant si votre fichier package.json se présente comme le JSON suivant :
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^11.3.0",
"dotenv": "^16.0.2"
}
}
Créez un fichier .env pour stocker les paramètres de votre service de recherche :
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
Remplacez la valeur <search-service-name> par le nom de votre service de recherche. Remplacez <search-admin-key> par la valeurs de clé que vous avez enregistrée précédemment.
Créer un fichier index.js
Nous créons ensuite un fichier index.js, qui est le fichier principal qui va héberger notre code.
Dans le haut de ce fichier, nous importons la bibliothèque @azure/search-documents :
const { SearchIndexClient, SearchClient, AzureKeyCredential, odata } = require("@azure/search-documents");
Ensuite, nous devons indiquer au package dotenv de lire les paramètres du fichier .env comme suit :
// Load the .env file if it exists
require("dotenv").config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
Avec nos importations et nos variables d’environnement en place, nous sommes prêts à définir la fonction main.
La plupart des fonctionnalités du SDK sont asynchrones, c’est pourquoi notre fonction main sera async. Nous incluons également un main().catch() sous la fonction principale pour intercepter et journaliser les erreurs rencontrées :
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
Une fois cela en place, nous sommes prêts à créer un index.
Créer un index
Créez un fichier hotels_quickstart_index.json. Ce fichier définit le fonctionnement de la recherche Azure AI avec les documents que vous chargerez à l’étape suivante. Chaque champ est identifié par un name et a un type spécifié. Chaque champ comporte également une série d’attributs d’index qui spécifient si la recherche Azure AI peut effectuer des recherches, filtrer, trier et définir des propriétés de facettes sur le champ. La plupart des champs sont des types de données simples, mais certains, comme AddressType, sont des types complexes qui vous permettent de créer des structures de données riches dans votre index. Vous pouvez en savoir plus sur les types de données pris en charge et les attributs d’index décrits dans Créer un index (REST).
Ajoutez le contenu suivant à hotels_quickstart_index.json ou téléchargez le fichier.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
Une fois notre définition d’index en place, nous voulons importer hotels_quickstart_index.json en haut du fichier index.js pour que la fonction main puisse accéder à la définition de l’index.
const indexDefinition = require('./hotels_quickstart_index.json');
Dans la fonction principale, nous créons ensuite un SearchIndexClient, qui est utilisé pour créer et gérer des index pour la recherche Azure AI.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
Ensuite, nous voulons supprimer l’index s’il existe déjà. Il s’agit d’une opération courante pour le code de test/démonstration.
Pour ce faire, nous définissons une fonction simple qui tente de supprimer l’index.
async function deleteIndexIfExists(indexClient, indexName) {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
Pour exécuter la fonction, nous extrayons le nom de l’index de la définition de l’index et nous passons indexName avec indexClient à la fonction deleteIndexIfExists().
const indexName = indexDefinition["name"];
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
Après cela, nous sommes prêts à créer l’index avec la méthode createIndex().
console.log('Creating index...');
let index = await indexClient.createIndex(indexDefinition);
console.log(`Index named ${index.name} has been created.`);
Exécution de l'exemple
À ce stade, vous êtes prêt à exécuter l’exemple. Utilisez une fenêtre de terminal pour exécuter la commande suivante :
node index.js
Si vous avez téléchargé le code source et que vous n’avez pas encore installé les packages requis, exécutez d’abord npm install.
Vous devez voir une série de messages décrivant les actions effectuées par le programme.
Ouvrez la Vue d’ensemble de votre service de recherche dans le Portail Azure. Sélectionnez l’onglet Index. Un résultat comme l’exemple suivant doit s’afficher :
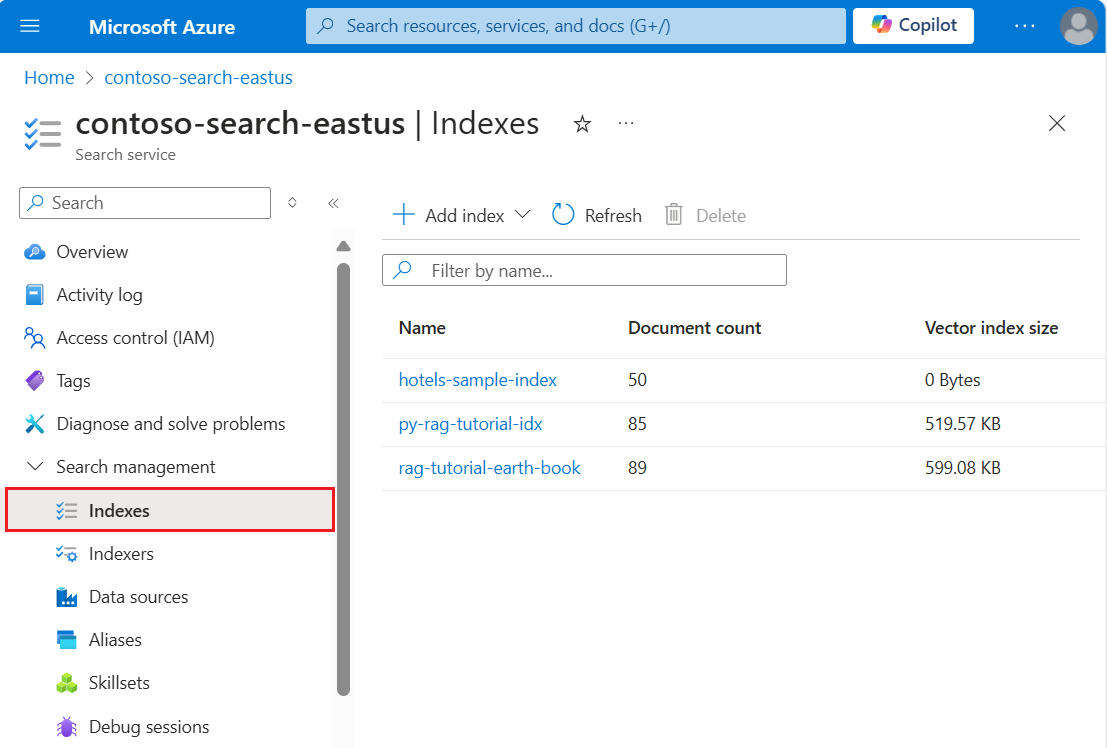
À l’étape suivante, vous ajouterez des données à l’index.
Chargement de documents
Dans la recherche Azure AI, les documents sont des structures de données qui sont à la fois des entrées pour l’indexation et des sorties de requêtes. Vous pouvez envoyer des données de ce type dans l’index ou utiliser un indexeur. Dans le cas présent, nous envoyons les documents à l’index programmatiquement.
Les entrées de documents peuvent être des lignes dans une base de données, des objets blob dans le Stockage Blob ou, comme dans cet exemple, des documents JSON sur le disque. Vous pouvez télécharger hotels.json ou créer votre propre fichier hotels.json avec le contenu suivant :
{
"value": [
{
"HotelId": "1",
"HotelName": "Secret Point Motel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Twin Dome Motel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Triple Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Cliff Hotel",
"Description": "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.",
"Description_fr": "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
À l’instar de ce que nous avons fait avec indexDefinition, nous devons aussi importer hotels.json dans le haut de index.js pour que les données soient accessibles dans notre fonction main.
const hotelData = require('./hotels.json');
Pour indexer les données dans l’index de recherche, nous devons maintenant créer un SearchClient. Alors que le SearchIndexClient est utilisé pour créer et gérer un index, le SearchClient est utilisé pour charger des documents et interroger l’index.
Il existe deux façons de créer un objet SearchClient. La première option consiste à créer un SearchClient à partir de zéro :
const searchClient = new SearchClient(endpoint, indexName, new AzureKeyCredential(apiKey));
Vous pouvez également utiliser la méthode getSearchClient() du SearchIndexClient pour créer le SearchClient :
const searchClient = indexClient.getSearchClient(indexName);
Maintenant que le client est défini, chargez les documents dans l’index de recherche. Dans le cas présent, nous utilisons la méthode mergeOrUploadDocuments(), qui charge les documents ou les fusionne avec un document existant si un document ayant la même clé existe déjà.
console.log('Uploading documents...');
let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
Exécutez à nouveau le programme avec node index.js. Vous devriez voir un ensemble de messages légèrement différents de ceux que vous avez vus à l’étape 1. Cette fois, l’index existe et vous voyez normalement un message à propos de sa suppression avant que l’application ne crée l’index et n’y envoie des données.
Avant d’exécuter les requêtes à l’étape suivante, définissez une fonction pour que le programme attende une seconde. Faites-le seulement à des fins de test ou de démonstration pour garantir que l’indexation se termine et que les documents sont disponibles dans l’index pour nos requêtes.
function sleep(ms) {
var d = new Date();
var d2 = null;
do {
d2 = new Date();
} while (d2 - d < ms);
}
Pour que le programme attende une seconde, appelez la fonction sleep comme ci-dessous :
sleep(1000);
Rechercher dans un index
Avec un index créé et des documents chargés, vous êtes prêt à envoyer des requêtes à l’index. Dans cette section, nous allons envoyer cinq requêtes différentes à l’index de recherche afin d’illustrer les différentes fonctionnalités de requête disponibles.
Les requêtes sont écrites dans une fonction sendQueries() que nous allons appeler dans la fonction main comme suit :
await sendQueries(searchClient);
Les requêtes sont envoyées en utilisant la méthode search() de searchClient. Le premier paramètre est le texte recherché et le deuxième paramètre spécifie les options de recherche.
La première requête recherche *, ce qui équivaut à effectuer une recherche dans tout, et sélectionne trois des champs de l’index. C’est une bonne pratique que d’appliquer un select seulement aux champs dont vous avez besoin, car l’extraction de données inutiles peut ajouter de la latence à vos requêtes.
Les searchOptions de cette requête ont également includeTotalCount défini sur true, ce qui retourne le nombre de résultats correspondants trouvés.
async function sendQueries(searchClient) {
console.log('Query #1 - search everything:');
let searchOptions = {
includeTotalCount: true,
select: ["HotelId", "HotelName", "Rating"]
};
let searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
Les requêtes restantes décrites ci-dessous doivent également être ajoutées à la fonction sendQueries(). Elles sont séparées ici seulement pour des raisons de lisibilité.
Dans la requête suivante, nous spécifions le terme de recherche "wifi" et nous incluons aussi un filtre pour retourner seulement les résultats où l’état est égal à 'FL'. Les résultats sont également classés selon la valeur du champ Rating de l’hôtel.
console.log('Query #2 - Search with filter, orderBy, and select:');
let state = 'FL';
searchOptions = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: ["HotelId", "HotelName", "Rating"]
};
searchResults = await searchClient.search("wifi", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Ensuite, la recherche est limitée à un seul champ pouvant faire l’objet d’une recherche en utilisant le paramètre searchFields. Cette approche constitue une option intéressante pour améliorer l’efficacité de votre requête si vous savez que vous êtes intéressé seulement par les correspondances dans certains champs.
console.log('Query #3 - Limit searchFields:');
searchOptions = {
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("sublime cliff", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log();
Une autre option courante à inclure dans une requête est facets. Les facettes vous permettent de créer des filtres sur votre interface utilisateur pour permettre aux utilisateurs de connaître facilement les valeurs sur lesquelles ils peuvent filtrer.
console.log('Query #4 - Use facets:');
searchOptions = {
facets: ["Category"],
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La dernière requête utilise la méthode getDocument() du searchClient. Ceci vous permet de récupérer efficacement un document en utilisant sa clé.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument(key='3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
Exécution de l'exemple
Exécutez le programme avec node index.js. À présent, en plus des étapes précédentes, les requêtes sont envoyées et les résultats sont écrits dans la console.
Créez une application console Node.js à l’aide de la bibliothèque @azure/search-documents pour créer, charger et interroger un index de recherche. Vous pouvez également télécharger le code source pour commencer avec un projet terminé ou suivre les étapes décrites dans cet article pour créer votre propre projet.
Configurer votre environnement
Nous avons utilisé les outils suivants pour créer ce guide de démarrage rapide.
Créer le projet
Démarrez Visual Studio Code.
Ouvrez la palette de commandes Ctrl+Maj+P, puis ouvrez le terminal intégré.
Créez un répertoire de développement, que vous appellerez quickstart :
mkdir quickstart
cd quickstart
Initialisez un projet vide avec npm en exécutant la commande suivante. Pour initialiser entièrement le projet, appuyez plusieurs fois sur Entrée pour accepter les valeurs par défaut, sauf pour la licence, que vous devez définir sur « MIT ».
npm init
Installez @azure/search-documents, le Kit de développement logiciel (SDK) JavaScript/TypeScript pour la recherche Azure AI.
npm install @azure/search-documents
Installez dotenv, qui est utilisé pour importer les variables d’environnement, comme le nom de votre service de recherche et de votre clé d’API.
npm install dotenv
Vérifiez que vous avez configuré les projets et leurs dépendances en regardant si votre fichier package.json se présente comme le JSON suivant :
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^12.1.0",
"dotenv": "^16.4.5"
}
}
Créez un fichier .env pour stocker les paramètres de votre service de recherche :
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
Remplacez la valeur <search-service-name> par le nom de votre service de recherche. Remplacez <search-admin-key> par la valeurs de clé que vous avez enregistrée précédemment.
Créer un fichier index.ts
Nous créons ensuite un fichier index.ts, qui est le fichier principal qui va héberger notre code.
Dans le haut de ce fichier, nous importons la bibliothèque @azure/search-documents :
import {
AzureKeyCredential,
ComplexField,
odata,
SearchClient,
SearchFieldArray,
SearchIndex,
SearchIndexClient,
SearchSuggester,
SimpleField
} from "@azure/search-documents";
Ensuite, nous devons indiquer au package dotenv de lire les paramètres du fichier .env comme suit :
// Load the .env file if it exists
import dotenv from 'dotenv';
dotenv.config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
Avec nos importations et nos variables d’environnement en place, nous sommes prêts à définir la fonction main.
La plupart des fonctionnalités du SDK sont asynchrones, c’est pourquoi notre fonction main sera async. Nous incluons également un main().catch() sous la fonction principale pour intercepter et journaliser les erreurs rencontrées :
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
Une fois cela en place, nous sommes prêts à créer un index.
Créer un index
Créez un fichier hotels_quickstart_index.json. Ce fichier définit le fonctionnement de la recherche Azure AI avec les documents que vous chargerez à l’étape suivante. Chaque champ est identifié par un name et a un type spécifié. Chaque champ comporte également une série d’attributs d’index qui spécifient si la recherche Azure AI peut effectuer des recherches, filtrer, trier et définir des propriétés de facettes sur le champ. La plupart des champs sont des types de données simples, mais certains, comme AddressType, sont des types complexes qui vous permettent de créer des structures de données riches dans votre index. Vous pouvez en savoir plus sur les types de données pris en charge et les attributs d’index décrits dans Créer un index (REST).
Ajoutez le contenu suivant à hotels_quickstart_index.json ou téléchargez le fichier.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
Une fois notre définition d’index en place, nous allons importer hotels_quickstart_index.json au-dessus de index.ts pour que la fonction main puisse accéder à la définition de l’index.
// Importing the index definition and sample data
import indexDefinition from './hotels_quickstart_index.json';
interface HotelIndexDefinition {
name: string;
fields: SimpleField[] | ComplexField[];
suggesters: SearchSuggester[];
};
const hotelIndexDefinition: HotelIndexDefinition = indexDefinition as HotelIndexDefinition;
Dans la fonction principale, nous créons ensuite un SearchIndexClient, qui est utilisé pour créer et gérer des index pour la recherche Azure AI.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
Ensuite, nous voulons supprimer l’index s’il existe déjà. Il s’agit d’une opération courante pour le code de test/démonstration.
Pour ce faire, nous définissons une fonction simple qui tente de supprimer l’index.
async function deleteIndexIfExists(indexClient: SearchIndexClient, indexName: string): Promise<void> {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
Pour exécuter la fonction, nous extrayons le nom de l’index de la définition de l’index et nous passons indexName avec indexClient à la fonction deleteIndexIfExists().
// Getting the name of the index from the index definition
const indexName: string = hotelIndexDefinition.name;
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
Après cela, nous sommes prêts à créer l’index avec la méthode createIndex().
console.log('Creating index...');
let index = await indexClient.createIndex(hotelIndexDefinition);
console.log(`Index named ${index.name} has been created.`);
Exécution de l'exemple
À ce stade, vous êtes prêt à générer et exécuter l’échantillon. Utilisez une fenêtre de terminal pour exécuter les commandes suivantes pour générer votre source avec tsc, puis exécutez votre source avec node :
tsc
node index.js
Si vous avez téléchargé le code source et que vous n’avez pas encore installé les packages requis, exécutez d’abord npm install.
Vous devez voir une série de messages décrivant les actions effectuées par le programme.
Ouvrez la Vue d’ensemble de votre service de recherche dans le Portail Azure. Sélectionnez l’onglet Index. Un résultat comme l’exemple suivant doit s’afficher :
À l’étape suivante, vous ajouterez des données à l’index.
Chargement de documents
Dans la recherche Azure AI, les documents sont des structures de données qui sont à la fois des entrées pour l’indexation et des sorties de requêtes. Vous pouvez envoyer des données de ce type dans l’index ou utiliser un indexeur. Dans le cas présent, nous envoyons les documents à l’index programmatiquement.
Les entrées de documents peuvent être des lignes dans une base de données, des objets blob dans le Stockage Blob ou, comme dans cet exemple, des documents JSON sur le disque. Vous pouvez télécharger hotels.json ou créer votre propre fichier hotels.json avec le contenu suivant :
{
"value": [
{
"HotelId": "1",
"HotelName": "Secret Point Motel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Twin Dome Motel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Triple Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Cliff Hotel",
"Description": "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.",
"Description_fr": "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
À l’instar de ce que nous avons fait avec indexDefinition, nous devons aussi importer hotels.json au-dessus de index.ts pour que les données soient accessibles dans notre fonction main.
import hotelData from './hotels.json';
interface Hotel {
HotelId: string;
HotelName: string;
Description: string;
Description_fr: string;
Category: string;
Tags: string[];
ParkingIncluded: string | boolean;
LastRenovationDate: string;
Rating: number;
Address: {
StreetAddress: string;
City: string;
StateProvince: string;
PostalCode: string;
};
};
const hotels: Hotel[] = hotelData["value"];
Pour indexer les données dans l’index de recherche, nous devons maintenant créer un SearchClient. Alors que le SearchIndexClient est utilisé pour créer et gérer un index, le SearchClient est utilisé pour charger des documents et interroger l’index.
Il existe deux façons de créer un objet SearchClient. La première option consiste à créer un SearchClient à partir de zéro :
const searchClient = new SearchClient<Hotel>(endpoint, indexName, new AzureKeyCredential(apiKey));
Vous pouvez également utiliser la méthode getSearchClient() du SearchIndexClient pour créer le SearchClient :
const searchClient = indexClient.getSearchClient<Hotel>(indexName);
Maintenant que le client est défini, chargez les documents dans l’index de recherche. Dans le cas présent, nous utilisons la méthode mergeOrUploadDocuments(), qui charge les documents ou les fusionne avec un document existant si un document ayant la même clé existe déjà. Vérifiez ensuite que l’opération a réussi, car au moins le premier document existe.
console.log("Uploading documents...");
const indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotels);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
Exécutez à nouveau le programme avec tsc && node index.js. Vous devriez voir un ensemble de messages légèrement différents de ceux que vous avez vus à l’étape 1. Cette fois, l’index existe et vous voyez normalement un message à propos de sa suppression avant que l’application ne crée l’index et n’y envoie des données.
Avant d’exécuter les requêtes à l’étape suivante, définissez une fonction pour que le programme attende une seconde. Faites-le seulement à des fins de test ou de démonstration pour garantir que l’indexation se termine et que les documents sont disponibles dans l’index pour nos requêtes.
function sleep(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
Pour que le programme attende une seconde, appelez la fonction sleep comme ci-dessous :
sleep(1000);
Rechercher dans un index
Avec un index créé et des documents chargés, vous êtes prêt à envoyer des requêtes à l’index. Dans cette section, nous allons envoyer cinq requêtes différentes à l’index de recherche afin d’illustrer les différentes fonctionnalités de requête disponibles.
Les requêtes sont écrites dans une fonction sendQueries() que nous allons appeler dans la fonction main comme suit :
await sendQueries(searchClient);
Les requêtes sont envoyées en utilisant la méthode search() de searchClient. Le premier paramètre est le texte recherché et le deuxième paramètre spécifie les options de recherche.
La première requête recherche *, ce qui équivaut à effectuer une recherche dans tout, et sélectionne trois des champs de l’index. C’est une bonne pratique que d’appliquer un select seulement aux champs dont vous avez besoin, car l’extraction de données inutiles peut ajouter de la latence à vos requêtes.
Les searchOptions de cette requête ont également includeTotalCount défini sur true, ce qui retourne le nombre de résultats correspondants trouvés.
async function sendQueries(
searchClient: SearchClient<Hotel>
): Promise<void> {
// Query 1
console.log('Query #1 - search everything:');
const selectFields: SearchFieldArray<Hotel> = [
"HotelId",
"HotelName",
"Rating",
];
const searchOptions1 = {
includeTotalCount: true,
select: selectFields
};
let searchResults = await searchClient.search("*", searchOptions1);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
Les requêtes restantes décrites ci-dessous doivent également être ajoutées à la fonction sendQueries(). Elles sont séparées ici seulement pour des raisons de lisibilité.
Dans la requête suivante, nous spécifions le terme de recherche "wifi" et nous incluons aussi un filtre pour retourner seulement les résultats où l’état est égal à 'FL'. Les résultats sont également classés selon la valeur du champ Rating de l’hôtel.
console.log('Query #2 - search with filter, orderBy, and select:');
let state = 'FL';
const searchOptions2 = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: selectFields
};
searchResults = await searchClient.search("wifi", searchOptions2);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Ensuite, la recherche est limitée à un seul champ pouvant faire l’objet d’une recherche en utilisant le paramètre searchFields. Cette approche constitue une option intéressante pour améliorer l’efficacité de votre requête si vous savez que vous êtes intéressé seulement par les correspondances dans certains champs.
console.log('Query #3 - limit searchFields:');
const searchOptions3 = {
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("sublime cliff", searchOptions3);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Une autre option courante à inclure dans une requête est facets. Les facettes vous permettent de fournir une exploration auto-dirigée à partir des résultats dans votre interface utilisateur. Les résultats des facettes peuvent être transformés en cases à cocher dans le volet de résultats.
console.log('Query #4 - limit searchFields and use facets:');
const searchOptions4 = {
facets: ["Category"],
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("*", searchOptions4);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La dernière requête utilise la méthode getDocument() du searchClient. Ceci vous permet de récupérer efficacement un document en utilisant sa clé.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument('3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
Réexécuter l’échantillon
Générez et exécutez le programme avec tsc && node index.ts. À présent, en plus des étapes précédentes, les requêtes sont envoyées et les résultats sont écrits dans la console.
Lorsque vous travaillez dans votre propre abonnement, il est recommandé, à la fin de chaque projet, de déterminer si vous avez toujours besoin des ressources que vous avez créées. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources une par une, ou choisir de supprimer le groupe de ressources afin de supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer les ressources dans le portail à l’aide des liens Toutes les ressources ou Groupes de ressources situés dans le volet de navigation de gauche.
Si vous utilisez un service gratuit, n'oubliez pas que vous êtes limité à trois index, indexeurs et sources de données. Vous pouvez supprimer des éléments un par un dans le portail pour ne pas dépasser la limite.
Dans ce guide de démarrage rapide, vous avez effectué un ensemble de tâches pour créer un index, le charger avec des documents et exécuter des requêtes. À différents stades, nous avons pris des raccourcis afin de simplifier le code pour une meilleure lisibilité et compréhension. Maintenant que vous avez assimilé les concepts de base, essayez de suivre un tutoriel qui appelle les API de recherche Azure AI dans une application web.
