Vue d’ensemble de la sécurité dans la recherche Azure AI
Cet article décrit les fonctionnalités de sécurité de recherche Azure AI qui protègent les données et les opérations.
Flux de données (modèles de trafic réseau)
Un service de recherche Azure AI est hébergé sur Azure et généralement accessible par les applications clientes par le biais de connexions de réseau public. Bien que ce modèle soit prédominant, il ne s’agit pas du seul modèle de trafic auquel vous devez faire attention. Vous devez bien comprendre tous les points d’entrée ainsi que le trafic sortant pour sécuriser vos environnements de développement et de production.
La recherche Azure AI a trois modèles de trafic réseau de base :
- Demandes entrantes effectuées par un client au service de recherche (modèle prédominant)
- Demandes sortantes émises par le service de recherche pour d’autres services sur Azure et ailleurs
- Demandes de service à service internes sur le réseau principal Microsoft sécurisé
Trafic entrant
Les demandes entrantes ciblant un point de terminaison de service de recherche sont les suivantes :
- Créer, lire, mettre à jour ou supprimer des objets sur le service de recherche
- Charger un index avec des documents de recherche
- Interroger un index
- Déclencher l’exécution d’un indexeur ou d’un ensemble de compétences
Les API REST décrivent la plage complète de requêtes entrantes gérées par un service de recherche.
Au minimum, toutes les demandes entrantes doivent être authentifiées à l’aide de l’une des options suivantes :
- Authentification basée sur la clé (par défaut). Les demandes entrantes fournissent une clé API valide.
- Contrôle d’accès en fonction du rôle. L’autorisation est effectuée via les identités Microsoft Entra et les attributions de rôles sur votre service de recherche.
En outre, vous pouvez ajouter des fonctionnalités de sécurité réseau pour restreindre davantage l’accès au point de terminaison. Vous pouvez créer des règles de trafic entrant dans un pare-feu IP ou des points de terminaison privés qui protègent entièrement votre service de recherche de l’Internet public.
Trafic interne
Les demandes internes sont sécurisées et gérées par Microsoft. Vous ne pouvez pas configurer ou contrôler ces connexions. Si vous verrouillez l’accès réseau, aucune action n’est nécessaire, car le trafic interne n’est pas configurable par le client.
Le trafic interne est constitué :
- Les appels de service à service pour des tâches comme l’authentification et l’autorisation à travers Microsoft Entra ID, la journalisation des diagnostics envoyée à Azure Monitor et les connexions de point de terminaison privé qui utilisent Azure Private Link.
- Les requêtes adressées aux API Azure AI services pour les compétences intégrées.
- Les requêtes adressées aux modèles Machine Learning qui prennent en charge le classement sémantique.
Trafic sortant
Les requêtes sortantes peuvent être sécurisées et gérées par vous. Les requêtes sortantes proviennent d’un service de recherche vers d’autres applications. Ces requêtes sont généralement effectuées par des indexeurs pour l’indexation basée sur le texte, l’enrichissement par IA basé sur les compétences et les vectorisations au moment de la requête. Les demandes sortantes incluent des opérations de lecture et d’écriture.
La liste suivante est une énumération complète des demandes sortantes pour lesquelles vous pouvez configurer des connexions sécurisées. Un service de recherche effectue des requêtes en son propre nom et au nom d’un indexeur ou d’une compétence personnalisée.
| Opération | Scénario |
|---|---|
| Indexeurs | Connectez-vous à des sources de données externes pour récupérer des données. Pour plus d’informations, reportez-vous à Accès de l’indexeur au contenu protégé par les fonctionnalités de sécurité réseau Azure. |
| Indexeurs | Connectez-vous au Stockage Azure pour conserver les magasins de connaissances, les enrichissements mis en cache, les sessions de débogage. |
| Compétences personnalisées | Connectez-vous aux fonctions Azure, aux applications web Azure ou à d’autres applications exécutant du code externe hébergé hors service. La demande de traitement externe est envoyée pendant l’exécution de l’ensemble de compétences. |
| Indexeurs et vectorisation intégrée | Connectez-vous à Azure OpenAI et à un modèle d’incorporation déployé, ou passez par une compétence personnalisée pour vous connecter à un modèle d’incorporation que vous fournissez. Le service de recherche envoie du texte à des modèles d’incorporation pour la vectorisation pendant l’indexation. |
| Vectoriseurs | Connectez-vous à Azure OpenAI ou à d’autres modèles incorporés au moment de la requête pour convertir des chaînes de texte utilisateur en vecteurs pour la recherche vectorielle. |
| Service de recherche | Connectez-vous à Azure Key Vault pour les clés de chiffrement gérées par le client, utilisées pour chiffrer et déchiffrer des données sensibles. |
Les connexions sortantes peuvent être établies avec la chaîne de connexion d’accès complet d’une ressource qui comprend une clé, une connexion de base de données ou une connexion Microsoft Entra ou avec une identité managée si vous utilisez Microsoft Entra ID et l’accès basé sur les rôles.
Pour atteindre les ressources Azure derrière un pare-feu, créez des règles de trafic entrant sur d’autres ressources Azure qui acceptent les demandes de service de recherche.
Pour accéder aux ressources protégées par Azure Private Link, créez une liaison privée partagée qu’un indexeur utilise pour établir sa connexion.
Exception pour les services de recherche et de stockage dans la même région
Si Stockage Azure et Recherche Azure AI se trouvent dans la même région, le trafic réseau est routé via une adresse IP privée sur le réseau principal de Microsoft. Étant donné que des adresses IP privées sont utilisées, vous ne pouvez pas configurer de pare-feu IP ou de point de terminaison privé pour la sécurité réseau.
Configurez les connexions de même région à l’aide de l’une des approches suivantes :
Sécurité du réseau
La sécurité réseau protège les ressources contre l’accès non autorisé ou les attaques en appliquant des contrôles au trafic réseau. La recherche Azure AI prend en charge des fonctionnalités réseau qui peuvent constituer votre première ligne de défense contre l’accès non autorisé.
Connexion entrante via des pare-feu IP
Un service de recherche est provisionné avec un point de terminaison public qui autorise l’accès en utilisant une adresse IP publique. Pour limiter le trafic qui transite par le point de terminaison public, créez une règle de pare-feu entrante qui accepte les demandes d’une adresse IP spécifique ou d’une plage d’adresses IP. Toutes les connexions clientes doivent être effectuées via une adresse IP autorisée, sans quoi la connexion est refusée.
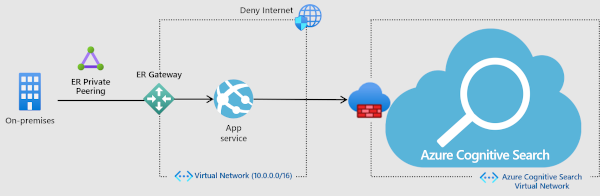
Vous pouvez utiliser le portail pour configurer l’accès du pare-feu.
Vous pouvez aussi utiliser les API REST de gestion. À compter de la version 13-03-2020 de l’API avec le paramètre IpRule, vous pouvez limiter l’accès à votre service en identifiant les adresses IP, individuellement ou dans une plage, qui doivent pouvoir accéder à votre service de recherche.
Connexion entrante à un point de terminaison privé (isolement réseau, aucun trafic Internet)
Pour une sécurité plus rigoureuse, vous pouvez établir un point de terminaison privé pour que la recherche Azure AI autorise un client sur un réseau virtuel à accéder de façon sécurisée aux données d’un index de recherche sur une liaison privée.
Le points de terminaison privé utilise une adresse IP de l’espace d’adressage du réseau virtuel pour les connexions à votre service de recherche. Le trafic entre le client et le service Search traverse le réseau virtuel et une liaison privée sur le réseau principal de Microsoft, ce qui élimine l’exposition sur l’Internet public. Un réseau virtuel permet une communication sécurisée entre ressources, avec votre réseau local, ainsi qu’avec Internet.
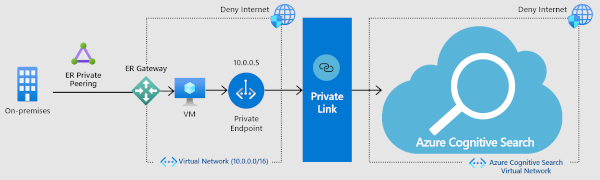
Bien que cette solution soit la plus sécurisée, l’utilisation de services supplémentaires représente un coût supplémentaire : veillez donc à avoir une compréhension claire des avantages avant de la mettre en place. Pour plus d’informations sur les coûts, consultez la page Tarification. Pour plus d’informations sur la façon dont ces composants fonctionnent ensemble, regardez cette vidéo. L’option du point de terminaison privé est présentée à partir de 5:48 dans la vidéo. Pour obtenir des instructions sur la configuration du point de terminaison, consultez Créer un point de terminaison privé pour la recherche Azure AI.
Authentification
Une fois qu’une requête est acceptée dans le service de recherche, elle doit toujours se soumettre à l’authentification et à une autorisation qui détermine si la requête est autorisée. La recherche Azure AI prend en charge deux approches :
L’authentification Microsoft Entra établit l’appelant (et non la requête) en tant qu’identité authentifiée. Une attribution de rôle Azure détermine l’autorisation.
L’authentification basée sur une clé s’effectue sur la demande (et non sur l’utilisateur ou l’application qui appelle) par le biais d’une clé API, où la clé est une chaîne composée de chiffres et de lettres générés de manière aléatoire qui prouvent que la demande émane d’une source digne de confiance. Ces clés sont nécessaires pour chaque requête. La soumission d’une clé valide est considérée comme la preuve que la requête provient d’une entité approuvée.
Vous pouvez utiliser les deux méthodes d’authentification ou désactiver une approche que vous ne souhaitez pas disponible sur votre service de recherche.
Autorisation
La recherche Azure AI fournit des modèles d’autorisation pour le management des services et du contenu.
Autoriser le management des services Azure
La gestion des ressources est autorisée via le contrôle d’accès en fonction du rôle dans votre locataire Microsoft Entra.
Dans la recherche Azure AI, Resource Manager est utilisé pour créer ou supprimer le service, gérer les clés API, mettre à l’échelle le service et configurer la sécurité. Ainsi, les attributions de rôles Azure déterminent qui peut effectuer ces tâches, qu’elles utilisent le portail, PowerShell ou les API REST de gestion.
Trois rôles de base (Propriétaire, Contributeur, Lecteur) s’appliquent à l’administration du service de recherche. Les attributions de rôles peuvent être effectuées à l’aide de toute méthodologie prise en charge (portail, PowerShell, etc.) et sont honorées dans l’ensemble du service.
Remarque
En utilisant des mécanismes à l’échelle d’Azure, vous pouvez verrouiller un abonnement ou une ressource pour empêcher la suppression accidentelle ou non autorisée de votre service de recherche par les utilisateurs disposant de droits d’administration. Pour plus d’informations, consultez Verrouiller les ressources pour en empêcher la suppression.
Autoriser l’accès au contenu
La gestion du contenu fait référence aux objets créés et hébergés sur un service de recherche.
Pour l’autorisation basée sur les rôles, utilisez les attributions de rôles Azure pour établir un accès en lecture-écriture aux opérations.
Pour l’autorisation basée sur des clés, une clé API et un point de terminaison qualifié déterminent l’accès. Un point de terminaison peut être le service proprement dit, la collection d’index, un index spécifique, une collection de documents ou un document spécifique. En cas de chaînage, le point de terminaison, l’opération (par exemple, une requête de création ou de mise à jour) et le type de clé (administrateur ou requête) autorisent l’accès au contenu et aux opérations.
Restriction de l’accès aux index
Si vous utilisez des rôles Azure, vous pouvez définir des autorisations sur des index individuels, à condition de le faire par programmation.
Toute personne disposant d’une clé d’administration pour votre service peut lire, modifier ou supprimer un index de ce service. En ce qui concerne la protection contre la suppression accidentelle ou malveillante des index, votre contrôle de code source en interne pour les ressources de code est la solution appropriée pour annuler des suppressions ou des modifications d’index indésirables. La recherche Azure AI dispose d’un système de basculement dans le cluster pour garantir sa disponibilité, mais il ne stocke pas et n’exécute pas le code propriétaire que vous avez utilisé pour créer ou charger des index.
Pour les solutions d’architecture mutualisée qui nécessitent des limites de sécurité au niveau des index, il est courant de gérer l’isolation de l'index au niveau intermédiaire dans le code de votre application. Pour plus d’informations sur les cas d’usage d’architecture mutualisée, consultez Modèles de conception pour les applications SaaS mutualisées et la recherche Azure AI.
Restriction de l’accès aux documents
Les autorisations utilisateur au niveau du document, également appelées sécurité au niveau des lignes ne sont pas prises en charge en mode natif dans la recherche Azure AI. Si vous importez des données à partir d’un système externe qui fournit une sécurité au niveau des lignes, comme Azure Cosmos DB, ces autorisations ne seront pas transférées avec les données comme étant indexées par la recherche Azure AI.
Si vous avez besoin d’un accès autorisé sur le contenu dans les résultats de recherche, il existe une technique permettant d’appliquer des filtres qui incluent ou excluent des documents en fonction de l’identité de l’utilisateur. Cette solution de contournement ajoute un champ de chaîne dans la source de données qui représente un groupe ou une identité d’utilisateur, que vous pouvez rendre filtrable dans votre index. Le tableau suivant décrit les deux approches permettant de filtrer les résultats de recherche de contenu non autorisé.
| Approche | Description |
|---|---|
| Filtrage de sécurité basé sur les filtres d’identité | Cet article décrit le workflow de base pour l’implémentation du contrôle d’accès basé sur l’identité de l’utilisateur. Il décrit l’ajout d’identificateurs de sécurité à un index, puis le filtrage relatif à ce champ qui permet d’omettre les résultats de contenu non autorisé. |
| Découpage de sécurité en fonction des identités Microsoft Entra | Cet article développe l’article précédent, en indiquant les étapes à suivre pour récupérer des identités de Microsoft Entra ID, l’un des services gratuits de la plateforme cloud Azure. |
Résidence des données
Lorsque vous installez un service de recherche, vous choisissez un emplacement ou une région qui détermine où les données client sont stockées et traitées. La recherche Azure AI ne stocke pas de données client en dehors de votre région spécifiée, sauf si vous configurez une fonctionnalité qui a une dépendance sur une autre ressource Azure et que cette ressource est provisionnée dans une autre région.
Actuellement, la seule ressource externe dans laquelle un service de recherche écrit est Stockage Azure. Le compte de stockage est celui que vous fournissez. Il peut se trouver dans n’importe quelle région. Un service de recherche écrit dans Stockage Azure si vous utilisez l’une des fonctionnalités suivantes : cache d’enrichissement, session de débogage, base de connaissances.
Exceptions aux engagements de résidence des données
Les noms d’objet sont stockés et traités en dehors de la région ou de l’emplacement sélectionné(e). Les clients ne doivent pas saisir de données sensibles dans les champs de nom ni créer d’applications conçues pour stocker des données sensibles dans ces champs. Ces données apparaissent dans les journaux de télémétrie utilisés par Microsoft pour assurer la prise en charge du service. Les noms d’objet incluent les noms des index, des indexeurs, des sources de données, des ensembles de compétences, des ressources, des conteneurs et du magasin de coffre de clés.
Les journaux de télémétrie sont conservés pendant un an et demi. Pendant cette période, Microsoft peut accéder aux noms d’objet et les référencer dans les conditions suivantes :
Diagnostiquer un problème, améliorer une fonctionnalité ou corriger un bogue. Dans ce scénario, l’accès aux données est interne uniquement (pas d’accès tiers).
Pendant le support, ces informations peuvent être utilisées pour résoudre rapidement les problèmes et faire remonter les informations à l’équipe produit si nécessaire
Protection des données
Au niveau de la couche de stockage, le chiffrement des données est intégré pour l’ensemble du contenu géré par le service enregistré sur le disque, dont les index, les cartes de synonymes et les définitions d’indexeurs, de sources de données et d’ensembles de compétences. Le chiffrement géré par le service s’applique à la fois au stockage de données à long terme et au stockage de données temporaire.
Si vous le souhaitez, vous pouvez ajouter des clés gérées par le client (CMK) pour un chiffrement supplémentaire du contenu indexé, afin d’obtenir un double chiffrement des données au repos. Pour les services créés après le 1er août 2020, le chiffrement avec clé gérée par le client s’étend aux données à court terme sur les disques temporaires.
Données en transit
Dans la recherche Azure AI, le chiffrement commence aux connexions et aux transmissions. Pour les services de recherche sur l’Internet public, la recherche Azure AI écoute sur le port HTTPS 443. Toutes les connexions client-à-service utilisent le chiffrement TLS 1.2. Les versions antérieures (1.0 ou 1.1) ne sont pas prises en charge.
Données au repos
Pour les données gérées en interne par le service de recherche, le tableau suivant décrit les modèles de chiffrement de données. Certaines fonctionnalités, telles que la base de connaissances, l’enrichissement incrémentiel et l’indexation basée sur un indexeur, lisent ou écrivent dans des structures de données dans d’autres services Azure. Les services qui dépendent du Stockage Azure peuvent utiliser les fonctionnalités de chiffrement de cette technologie.
| Modèle | Clés | Exigences | Restrictions | S’applique à |
|---|---|---|---|---|
| chiffrement côté serveur | Clés managées par Microsoft | Aucune (intégré) | Aucune, disponible pour tous les niveaux de service, dans toutes les régions, pour le contenu créé après le 24 janvier 2018. | Contenu (index et cartes de synonymes) et définitions (indexeurs, sources de données, ensembles de compétences) sur les disques de données et les disques temporaires |
| chiffrement côté serveur | clés gérées par le client | Azure Key Vault | Disponible pour les niveaux de service facturables, dans des régions spécifiques, pour le contenu créé après le 1er août 2020. | Contenu (index et cartes de synonymes) sur les disques de données |
| chiffrement complet côté serveur | clés gérées par le client | Azure Key Vault | Disponible sur les niveaux de service facturables, dans toutes les régions, sur les services de recherche après le 13 mai 2021. | Contenu (index et cartes de synonymes) sur les disques de données et les disques temporaires |
Clés gérées par le service
Le chiffrement géré par le service est une opération Microsoft interne qui utilise le chiffrement AES 256 bits. Il se produit automatiquement sur toutes les indexations, y compris sur les mises à jour incrémentielles des index qui ne sont pas entièrement chiffrés (créés avant janvier 2018).
Le chiffrement géré par le service s’applique à tout le contenu sur le stockage à long et à court terme.
Clés gérées par le client (CMK)
Les clés gérées par le client nécessitent un service facturable supplémentaire, Azure Key Vault, qui peut se trouver dans une autre région que l’instance de recherche Azure AI, mais qui doit être sous le même abonnement.
La prise en charge des clés gérées par le client a été déployée en deux phases. Si vous avez créé votre service de recherche pendant la première phase, le chiffrement avec clé gérée par le client était limité au stockage à long terme et à des régions spécifiques. Les services créés dans la deuxième phase, après mai 2021, peuvent utiliser le chiffrement avec clé gérée par le client dans n’importe quelle région. Dans le cadre du deuxième déploiement, le contenu est chiffré par clé gérée par le client sur le stockage à long terme et à court terme. Pour plus d’informations sur la prise en charge des clés gérées par le client, consultez Chiffrement double complet.
L’activation du chiffrement CMK a pour effet d’augmenter la taille de l’index et dégrader les performances des requêtes. Sur la base des observations effectuées à ce jour, vous pouvez vous attendre à une augmentation de 30 à 60 % des temps de requête, même si les performances réelles varient en fonction de la définition d’index et des types de requêtes. En raison de l’incidence négative sur les performances, nous vous recommandons de n’activer cette fonctionnalité que sur les index qui en ont réellement besoin. Pour plus d’informations, consultez Configurer des clés de chiffrement gérées par le client dans la recherche Azure AI.
Sécurité et administration
Gérer les clés API
Le recours à une authentification basée sur des clés API signifie que vous devez disposer d’un plan pour la régénération de la clé d’administration à intervalles réguliers, conformément aux meilleures pratiques de sécurité Azure. Il y a, au maximum, deux clés d’administration par service de recherche. Pour plus d’informations sur la sécurisation et la gestion des clés API, consultez Créer et gérer des clés API.
Journal d’activité et journaux de ressource
La recherche Azure AI ne journalisant pas les identités des utilisateurs, vous ne pouvez pas consulter de journaux pour obtenir des informations sur un utilisateur spécifique. En revanche, le service journalise des opérations de création/lecture/mise à jour/suppression susceptibles de permettre d’établir une corrélation avec d’autres journaux pour comprendre des actions spécifiques.
À l’aide d’alertes et de l’infrastructure de journalisation dans Azure, vous pouvez revenir sur des pics de volume de requête ou d’autres actions qui s’écartent des charges de travail attendues. Pour plus d’informations sur la configuration des journaux, consultez Collecter et analyser des données de journal et Surveiller les demandes de requête.
Certifications et conformité
La recherche Azure AI intervient dans des audits réguliers, et a été certifié par rapport à de nombreux standards mondiaux, régionaux et sectoriels pour le cloud public et Azure Government. Pour obtenir la liste complète, téléchargez le livre blanc Microsoft Azure Compliance Offerings depuis la page des rapports d’audit officiels.
Pour la conformité, vous pouvez utiliser Azure Policy pour implémenter les bonnes pratiques de haute sécurité du benchmark de sécurité du cloud Microsoft. Le benchmark de sécurité du cloud Microsoft est un ensemble de recommandations de sécurité, codifiées en contrôles de sécurité qui sont associés à des actions clés que vous devez prendre pour atténuer les menaces sur les services et les données. Il existe actuellement 12 contrôles de sécurité, dont Sécurité réseau, Journalisation et surveillance et Protection des données.
Azure Policy est une fonctionnalité intégrée à Azure qui vous permet de gérer la conformité de plusieurs normes, y compris celles du benchmark de sécurité du cloud Microsoft. Pour les critères de référence bien connus, Azure Policy fournit des définitions intégrées qui fournissent à la fois des critères et une réponse actionnable en cas de non-conformité.
Pour la recherche Azure AI, il existe actuellement une seule définition intégrée. Il s’agit de la journalisation des ressources. Vous pouvez attribuer une stratégie qui identifie tout service de recherche auquel il manque la journalisation des ressources, puis l’active. Pour plus d’informations, consultez Contrôles de conformité réglementaire d’Azure Policy pour la recherche Azure AI.
Visionner la vidéo
Regardez cette vidéo rapide pour obtenir une vue d’ensemble de l’architecture de la sécurité et de chaque catégorie de fonctionnalités.