Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous allez apprendre à activer le connecteur Synapse Studio intégré à Log Analytics. Vous pourrez ensuite collecter et envoyer les métriques et journaux d’une application Apache Spark à votre espace de travail Log Analytics. Enfin, vous aurez la possibilité d’utiliser un classeur Azure Monitor pour visualiser les métriques et journaux.
Configuration des informations de l’espace de travail
Pour configurer les informations nécessaires dans Synapse Studio, procédez comme suit.
Étape 1 : Créer un espace de travail Log Analytics
Pour créer cet espace de travail, consultez l’une des ressources suivantes :
- Créer un espace de travail dans le portail Azure.
- Créer un espace de travail avec Azure CLI.
- Créer et configurer un espace de travail dans Azure Monitor avec PowerShell.
Étape 2 : Collecter les informations de configuration
Utilisez l’une des options suivantes pour préparer la configuration.
Option 1 : Configuration avec l’ID et la clé de l’espace de travail Log Analytics
Collectez les valeurs suivantes pour la configuration Spark :
-
<LOG_ANALYTICS_WORKSPACE_ID>: ID de l’espace de travail Log Analytics -
<LOG_ANALYTICS_WORKSPACE_KEY>: clé Log Analytics. Pour la trouvez, accédez au portail Azure, puis à Espace de travail Azure Log Analytics>Agents>Clé primaire.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.secret <LOG_ANALYTICS_WORKSPACE_KEY>
Vous pouvez également utiliser les propriétés suivantes :
spark.synapse.diagnostic.emitters: LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret: <LOG_ANALYTICS_WORKSPACE_KEY>
Option 2 : Configuration avec Azure Key Vault
Remarque
Vous devez accorder l’autorisation de lecture secrète aux utilisateurs qui envoient des applications Apache Spark. Pour plus d’informations, consultez Attribution de l’accès aux clés, certificats et secrets Key Vault avec un contrôle d’accès en fonction du rôle Azure. Quand vous activez cette fonctionnalité dans un pipeline Synapse, vous devez utiliser l’option 3. Cela est nécessaire pour obtenir le secret d’Azure Key Vault avec l’identité gérée par l’espace de travail.
Pour configurer Azure Key Vault de façon à stocker la clé de l’espace de travail, procédez comme suit :
Créez votre coffre de clés et accédez-y sur le Portail Azure.
Accordez les autorisations appropriées aux utilisateurs ou aux identités gérées de l’espace de travail.
Sur les pages de paramètres du coffre de clés, sélectionnez Secrets.
Sélectionnez Générer/Importer.
Sur l’écran Créer un secret, choisissez les valeurs suivantes :
-
Nom : donnez un nom au secret. Pour sélectionner la valeur par défaut, entrez
SparkLogAnalyticsSecret. -
Valeur : entrez
<LOG_ANALYTICS_WORKSPACE_KEY>comme secret. - Conservez les valeurs par défaut des autres options. Sélectionnez ensuite Créer.
-
Nom : donnez un nom au secret. Pour sélectionner la valeur par défaut, entrez
Collectez les valeurs suivantes pour la configuration Spark :
-
<LOG_ANALYTICS_WORKSPACE_ID>: ID de l’espace de travail Log Analytics -
<AZURE_KEY_VAULT_NAME>: Le nom du coffre-fort de clés que vous avez configuré. -
<AZURE_KEY_VAULT_SECRET_KEY_NAME>(facultatif) : nom secret dans le coffre de clés pour la clé de l’espace de travail. Par défaut, il s’agit deSparkLogAnalyticsSecret.
-
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Vous pouvez également utiliser les propriétés suivantes :
spark.synapse.diagnostic.emitters LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret.keyVault: <AZURE_KEY_VAULT_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.secretName: <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Remarque
Vous pouvez également stocker l’ID de l’espace de travail dans Key Vault. Pour stocker l’ID d’espace de travail avec le nom du secret SparkLogAnalyticsWorkspaceId, reportez-vous à la procédure précédente. Vous pouvez également utiliser la configuration spark.synapse.logAnalytics.keyVault.key.workspaceId pour spécifier le nom du secret de l’ID de l’espace de travail dans Key Vault.
Option 3. Configuration avec un service lié
Remarque
Dans cette option, vous devez accorder l’autorisation de lecture de secret à l’identité managée de l’espace de travail. Pour plus d’informations, consultez Attribution de l’accès aux clés, certificats et secrets Key Vault avec un contrôle d’accès en fonction du rôle Azure.
Pour configurer un service lié Azure Key Vault dans Synapse Studio de façon à stocker la clé de l’espace de travail, procédez comme suit :
Suivez toutes les étapes de la section précédente, « Option 2 ».
Créez un service lié Key Vault dans Synapse Studio :
a) Accédez à Synapse Studio>Gérer>Services liés, puis sélectionnez Créer.
b. Dans la zone de recherche, recherchez Azure Key Vault.
v. Donnez un nom au service lié.
d. Choisissez votre coffre de clés, puis sélectionnez Créer.
Ajoutez un élément
spark.synapse.logAnalytics.keyVault.linkedServiceNameà la configuration Apache Spark.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.logAnalytics.keyVault.linkedServiceName <LINKED_SERVICE_NAME>
Vous pouvez également utiliser les propriétés suivantes :
spark.synapse.diagnostic.emitters LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret.keyVault: <AZURE_KEY_VAULT_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.secretName: <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.linkedService: <AZURE_KEY_VAULT_LINKED_SERVICE>
Pour obtenir la liste des configurations Apache Spark, consultez Configurations Apache Spark disponibles
Étape 3 : Créer une configuration Apache Spark
Vous pouvez créer une configuration Apache Spark pour votre espace de travail. Quand vous créez un Notebook ou une définition de tâche Apache Spark, vous pouvez sélectionner la configuration Apache Spark à utiliser avec votre pool Apache Spark. Lorsque vous la sélectionnez, les détails de la configuration s’affichent.
Sélectionnez Gérer>Configurations Apache Spark.
Sélectionnez le bouton Nouveau pour créer une configuration Apache Spark.
La page Nouvelle configuration Apache Spark s’ouvre une fois que vous avez sélectionné le bouton Nouveau.
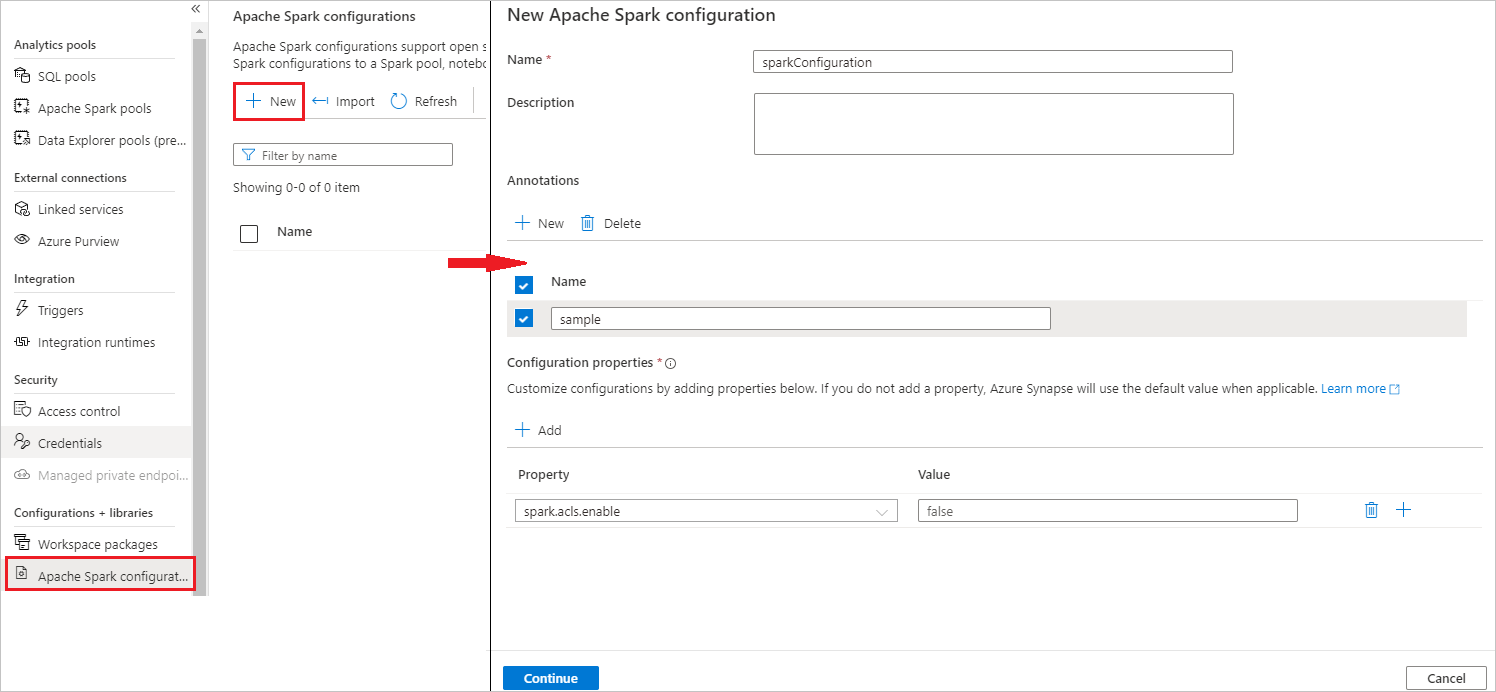
Pour Nom, vous pouvez entrer votre nom préféré valide.
Pour Description, vous pouvez entrer une description.
Pour Annotations, vous pouvez ajouter des annotations en cliquant sur le bouton Nouveau, et vous pouvez également supprimer des annotations existantes en sélectionnant et en cliquant sur le bouton Supprimer.
Pour Propriétés de configuration, ajoutez toutes les propriétés de l’option de configuration que vous avez choisie en sélectionnant le bouton Ajouter. Pour Propriété, ajoutez le nom de propriété tel qu’il est listé, et pour Valeur, utilisez la valeur que vous avez collectée à l’étape 2. Si vous n’ajoutez pas de propriété, Azure Synapse utilise la valeur par défaut, le cas échéant.

Envoyer une application Apache Spark et afficher les journaux et métriques
Voici comment procéder :
Envoyez une application Apache Spark au pool Apache Spark configuré à l’étape précédente. Pour cela, vous avez plusieurs possibilités :
- Exécutez un notebook dans Synapse Studio.
- Dans Synapse Studio, envoyez un programme de traitement par lots Apache Spark avec une définition de travail Apache Spark.
- Exécutez un pipeline contenant une activité Apache Spark.
Accédez à l’espace de travail Log Analytics spécifié, puis visualisez les métriques et les journaux de l’application Apache Spark quand celle-ci commence à s’exécuter.
Écrire des journaux d’application personnalisés
Vous pouvez utiliser la bibliothèque Apache Log4j pour écrire des journaux personnalisés.
Exemple pour Scala :
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Exemple pour PySpark :
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Visualisation des métriques et journaux avec l’exemple de classeur
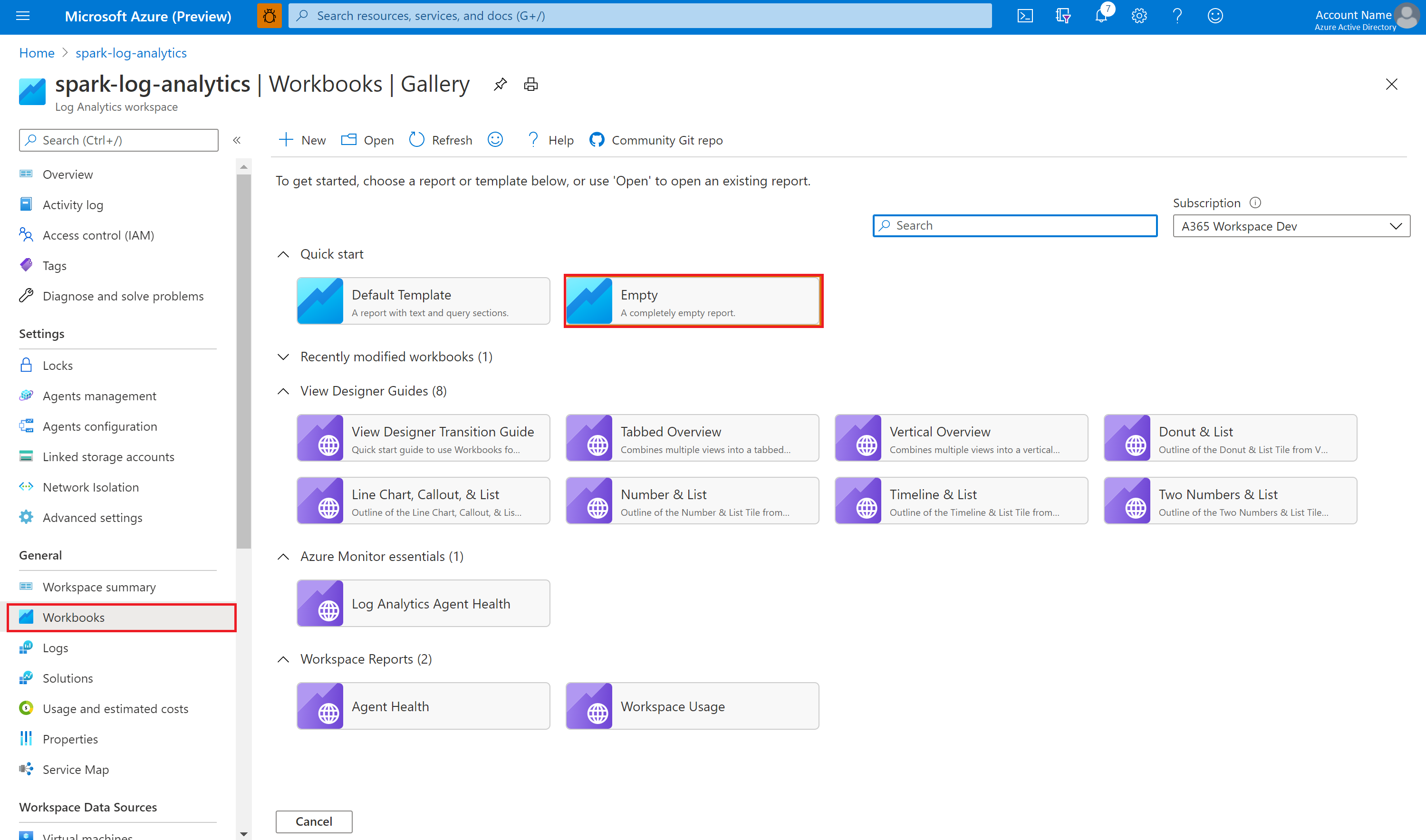
Ouvrez et copiez le contenu du fichier de classeur.
Sur le Portail Azure, sélectionnez Espace de travail Log Analytics>Classeurs.
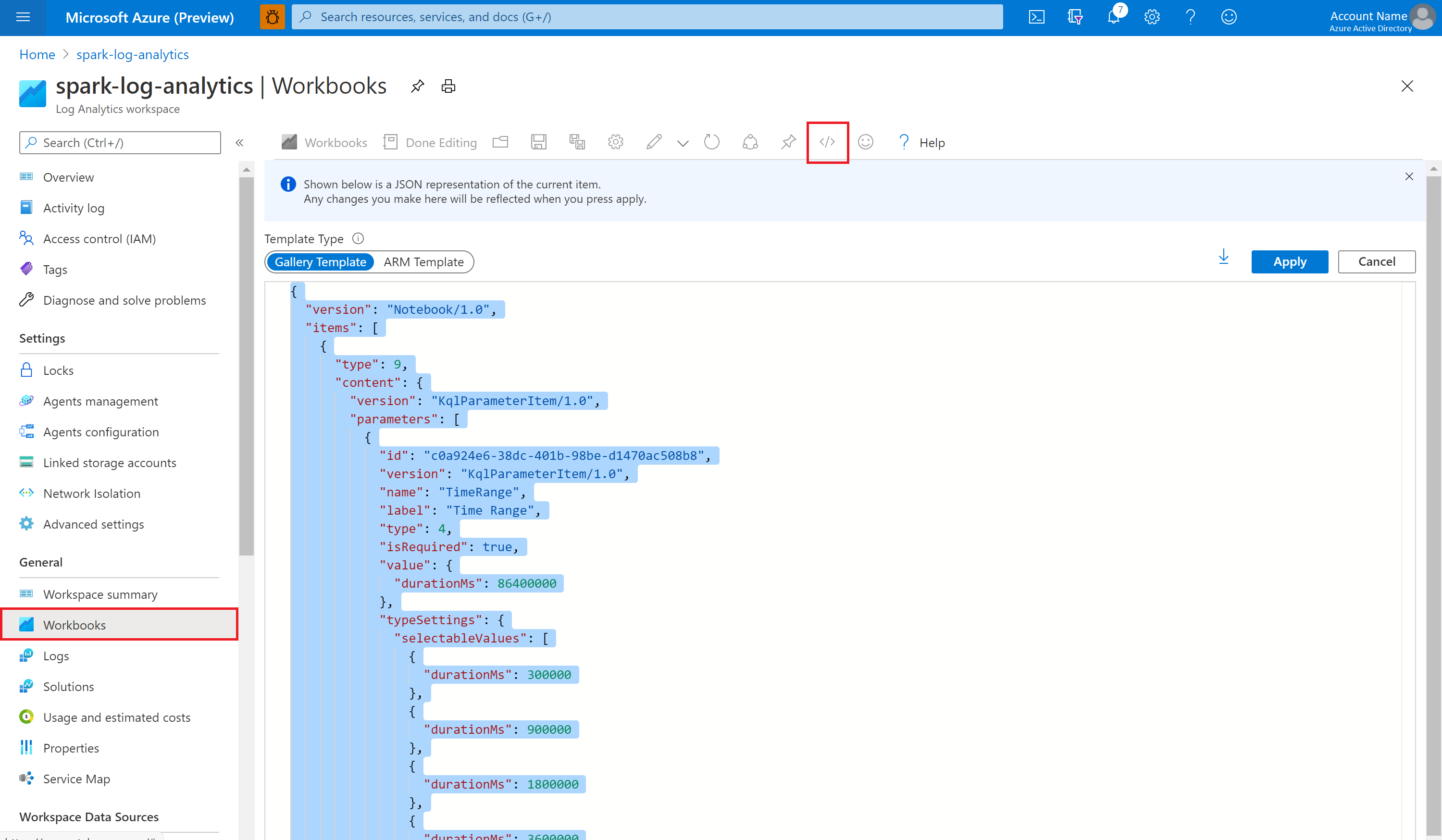
Ouvrez le classeur Vide. Utilisez le mode Éditeur avancé en sélectionnant l’icône </>.
Collez le contenu copié par-dessus le code JSON existant.
Sélectionnez Appliquer, puis Modification terminée.
Soumettez ensuite votre application Apache Spark au pool Apache Spark configuré. Une fois l’application passée dans un état en cours d’exécution, choisissez-la dans la liste déroulante des classeurs.
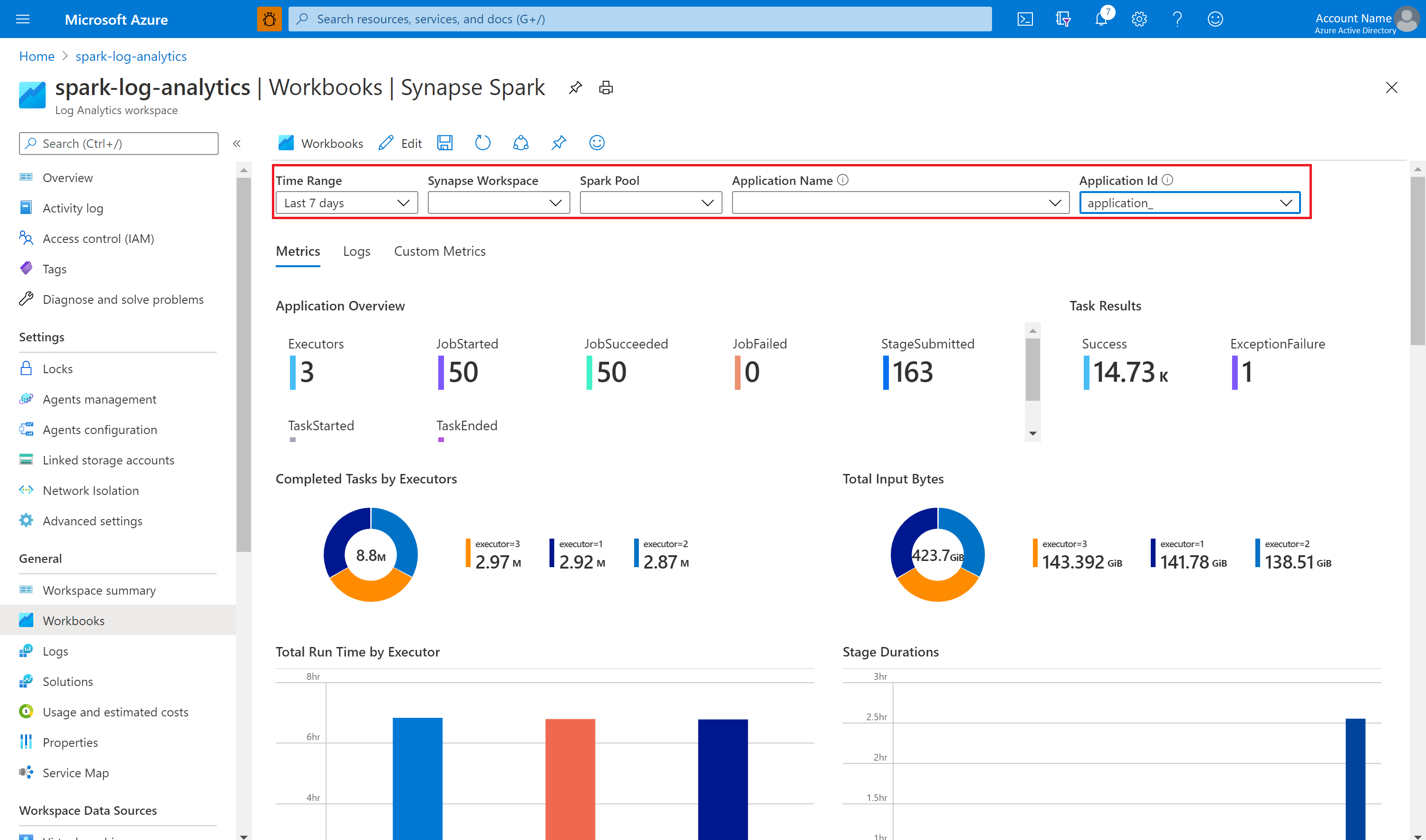
Il est possible de personnaliser le classeur. Par exemple, vous pouvez utiliser des requêtes Kusto et configurer des alertes.

Interroger des données avec Kusto
Voici un exemple d’interrogation d’événements Apache Spark :
SparkListenerEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Voici un exemple d’interrogation des journaux du pilote et des exécuteurs de l’application Apache Spark :
SparkLoggingEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Enfin, voici un exemple d’interrogation de métriques Apache Spark :
SparkMetrics_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
Création et gestion des alertes
Les utilisateurs peuvent lancer des requêtes pour évaluer les métriques et les journaux à une fréquence définie et déclencher une alerte en fonction des résultats. Pour plus d’informations, consultez Créer, afficher et gérer des alertes de journal à l’aide d’Azure Monitor.
Espace de travail Synapse où est activée la protection contre l’exfiltration de données
Après cela, l’espace de travail Synapse est créé avec la protection contre l’exfiltration de données activée.
Quand vous souhaitez activer cette fonctionnalité, vous devez créer des requêtes de connexion de point de terminaison privé managée à des étendues de liaison privée Azure Monitor (AMPLS) dans les locataires Microsoft Entra approuvés de l’espace de travail.
Vous pouvez suivre les étapes ci-dessous pour créer une connexion de point de terminaison privé géré aux étendues de liaison privée Azure Monitor (AMPLS) :
- S'il n'existe aucune instance AMPLS, consultez Configurer une connexion Azure Monitor via Private Link pour en créer un.
- Accédez à votre portail AMPLS dans Azure, sur la page Ressources Azure Monitor, sélectionnez Ajouter pour ajouter une connexion à votre espace de travail Azure Log Analytics.
- Accédez à Synapse Studio > Gérer > Points de terminaison privés gérés, sélectionnez le bouton Nouveau, sélectionnez Étendues de liaison privée Azure Monitor, puis Continuer.
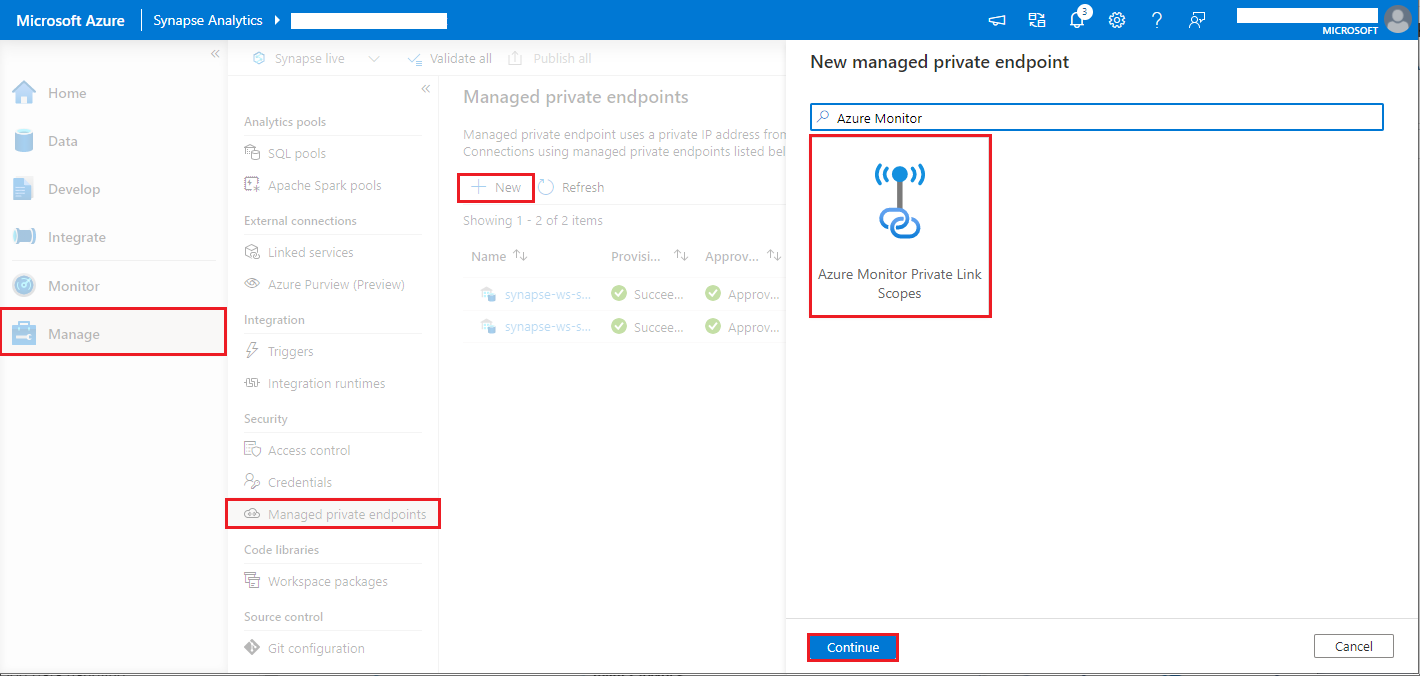
- Choisissez l’étendue de liaison privée Azure Monitor que vous avez créée, puis sélectionnez le bouton Créer.
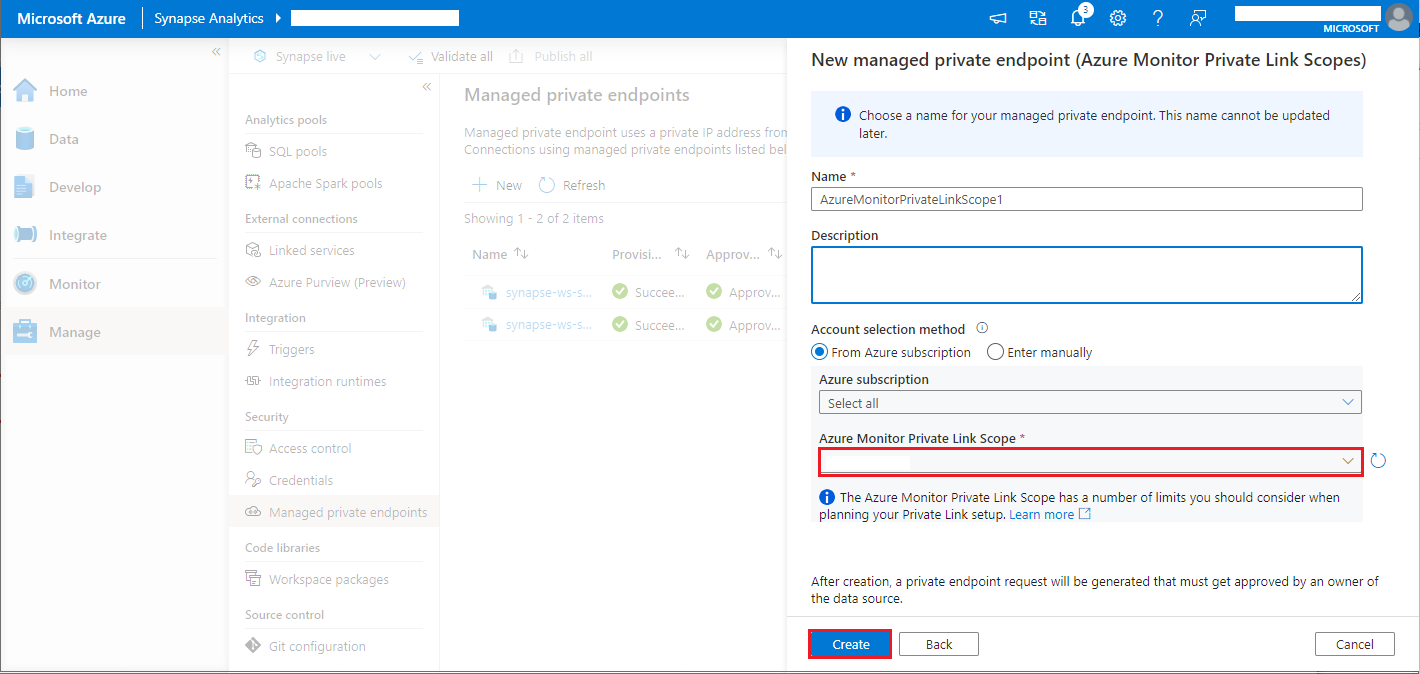
- Attendez quelques minutes que le provisionnement du point de terminaison privé soit terminé.
- Accédez à nouveau à votre AMPLS dans le portail Azure et, dans la page Connexions de point de terminaison privé, sélectionnez la connexion provisionnée, puis Approuver.
Remarque
- L’objet AMPLS a de nombreuses limites que vous devez prendre en compte lors de la planification de votre configuration private Link. Consultez Limites d’AMPLS pour une présentation plus approfondie de ces limites.
- Vérifiez si vous disposez de l’autorisation appropriée pour créer un point de terminaison privé managé.
Configurations disponibles
| Paramétrage | Descriptif |
|---|---|
spark.synapse.diagnostic.emitters |
Obligatoire. Noms des destinations des émetteurs de diagnostic, séparés par des virgules. Par exemple, MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Obligatoire. Type de destination intégrée. Pour activer la destination Azure Log Analytics, AzureLogAnalytics doit être inclus dans ce champ. |
spark.synapse.diagnostic.emitter.<destination>.categories |
facultatif. Catégories de journaux sélectionnées séparées par des virgules. Les valeurs disponibles sont les suivantes : DriverLog, ExecutorLog, EventLog, Metrics. Si aucune valeur n’est définie, la valeur par défaut sera all (toutes les catégories). |
spark.synapse.diagnostic.emitter.<destination>.workspaceId |
Obligatoire. Pour activer la destination Azure Log Analytics, workspaceId doit être inclus dans ce champ. |
spark.synapse.diagnostic.emitter.<destination>.secret |
facultatif. Contenu secret (clé Log Analytics). Pour ce faire, dans le portail Azure, accédez à l’espace de travail Azure Log Analytics > Agents > Clé primaire. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Requis si .secret n'est pas spécifié. Nom du coffre de clés Azure dans lequel est stocké le secret (clé d’accès ou SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Obligatoire si .secret.keyVault est spécifié. Nom du secret du coffre de clés Azure où le secret est stocké. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
facultatif. Nom du service lié au coffre de clés Azure. Lorsqu’il est activé dans le pipeline Synapse, il est nécessaire d’obtenir le secret auprès d’Azure Key Vault. (Assurez-vous que le MSI dispose d’un accès en lecture au coffre de clés Azure). |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
facultatif. Noms de bibliothèque de journalisation Log4j séparés par des virgules. Vous pouvez spécifier les journaux à collecter. Par exemple, SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
facultatif. Noms de bibliothèque de journalisation log4j séparés par des virgules. Vous pouvez spécifier les journaux à collecter. Par exemple : org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
facultatif. Suffixes des noms de métrique Spark séparés par des virgules. Vous pouvez spécifier les métriques à collecter. Par exemple :jvm.heap.used |