Présentation de ML.NET et de son fonctionnement
ML.NET vous donne la possibilité d’ajouter le Machine Learning aux applications .NET, dans des scénarios en ligne ou hors connexion. Avec cette fonctionnalité, vous pouvez ensuite effectuer des prédictions automatiques à partir des données disponibles dans votre application. Les applications Machine Learning utilisent des modèles dans les données pour effectuer des prédictions plutôt que d’avoir besoin d’être explicitement programmées.
Le modèle Machine Learning est central dans ML.NET. Le modèle spécifie les étapes nécessaires pour transformer vos données d’entrée en prédiction. Avec ML.NET, vous pouvez entraîner un modèle personnalisé en spécifiant un algorithme, ou vous pouvez importer des modèles TensorFlow et ONNX préentraînés.
Une fois que vous avez un modèle, vous pouvez l’ajouter à votre application pour effectuer les prédictions.
ML.NET s’exécute sur Windows, Linux et macOS en tirant parti de .NET ou sur Windows en utilisant .NET Framework. Le mode 64 bits est pris en charge sur toutes les plateformes. Le mode 32 bits est pris en charge sur Windows, à l’exception des fonctionnalités TensorFlow, LightGBM et ONNX.
La tableau suivant illustre des exemples des types de prédiction possibles avec ML.NET.
| Type de prédiction | Exemple |
|---|---|
| Classification/catégorisation | Classez automatiquement des commentaires de clients dans les catégories Positif et Négatif. |
| Régression/prédiction de valeurs continues | Prévoyez le prix des maisons en fonction de la superficie et de l’emplacement. |
| Détection des anomalies | Détectez des transactions bancaires frauduleuses. |
| Recommandations | Suggérez des produits aux acheteurs en ligne en fonction de leurs achats précédents. |
| Série chronologique/de données séquentielles | Prévoyez la météo ou les ventes de produits. |
| Classification d’images | Catégorisez des pathologies dans des images médicales. |
| Classification de texte | Catégoriser des documents en fonction de leur contenu. |
| Similitudes de phrases | Mesurer la similarité de deux phrases. |
Hello ML.NET World
Le code dans l’extrait suivant illustre l’application ML.NET la plus simple. Cet exemple crée un modèle de régression linéaire pour prédire les prix de maisons à partir des données de superficie et des prix immobiliers.
using System;
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public class HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new MLContext();
// 1. Import or create training data
HouseData[] houseData = {
new HouseData() { Size = 1.1F, Price = 1.2F },
new HouseData() { Size = 1.9F, Price = 2.3F },
new HouseData() { Size = 2.8F, Price = 3.0F },
new HouseData() { Size = 3.4F, Price = 3.7F } };
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model
var model = pipeline.Fit(trainingData);
// 4. Make a prediction
var size = new HouseData() { Size = 2.5F };
var price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size*1000} sq ft= {price.Price*100:C}k");
// Predicted price for size: 2500 sq ft= $261.98k
}
}
Workflow du code
Le diagramme suivant représente la structure du code de l’application ainsi que le processus itératif de développement du modèle :
- Collecter et charger des données d’entraînement dans un objet IDataView
- Spécifier un pipeline d’opérations pour extraire des caractéristiques et appliquer un algorithme de machine learning
- Entraîner un modèle en appelant Fit() sur le pipeline
- Évaluer le modèle et effectuer des itérations pour l’améliorer
- Enregistrer le modèle au format binaire pour l’utiliser dans une application
- Recharger le modèle dans un objet ITransformer
- Effectuer des prédictions en appelant CreatePredictionEngine.Predict()
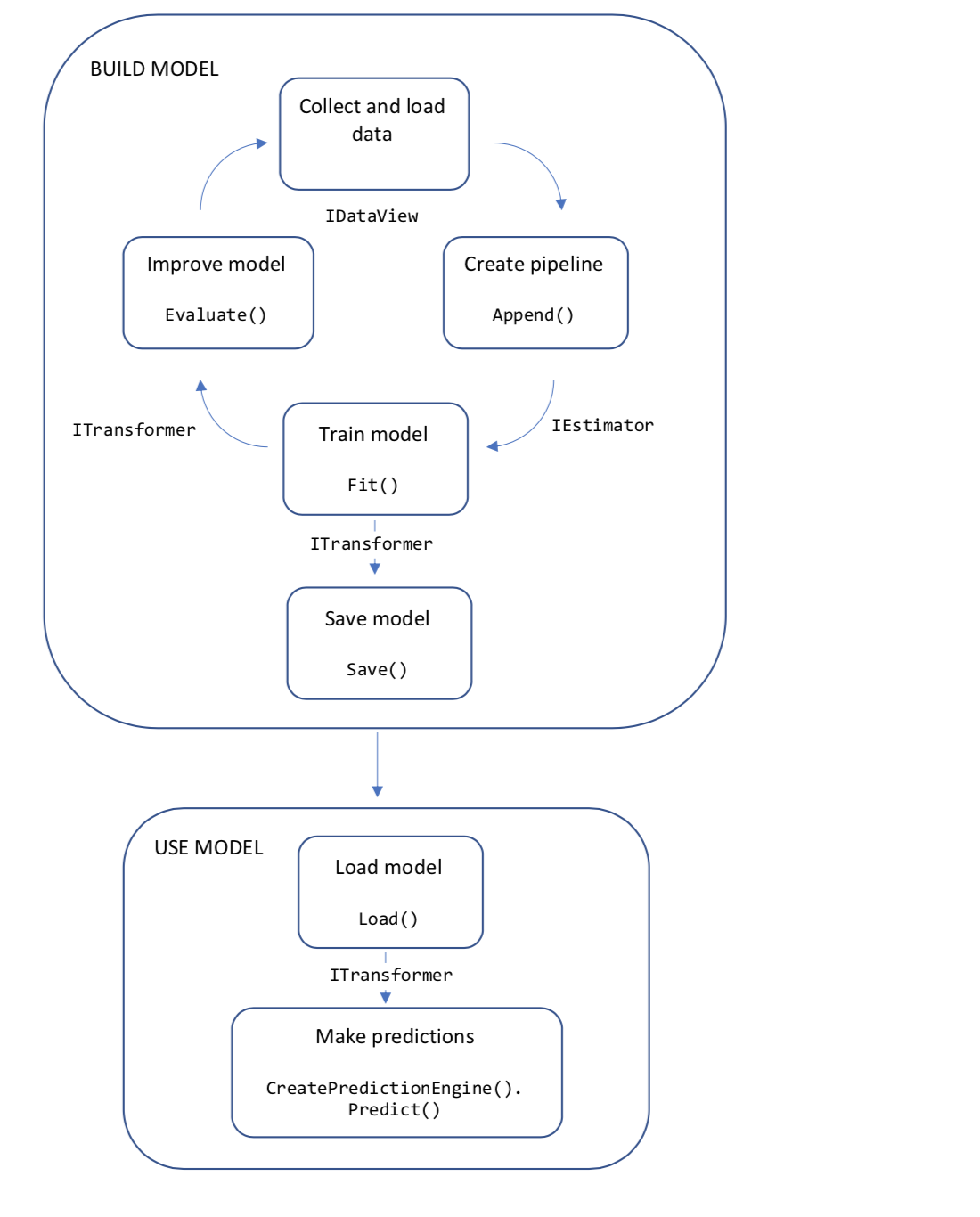
Revoyons maintenant tous ces concepts un peu plus en détail.
Modèle Machine Learning
Un modèle ML.NET est un objet qui contient des transformations à effectuer sur vos données d’entrée pour produire la sortie prédite.
Basic
Le modèle de base, le plus simple, est la régression linéaire à deux dimensions, où une quantité continue est proportionnelle à une autre, comme dans l’exemple des prix de maisons ci-dessus.

Le modèle est simple : $Price = b + Size * w$. Les paramètres $b$ et $w$ sont estimés en ajustant une ligne sur un ensemble de paires de valeurs (size, price). Les données utilisées pour rechercher les paramètres du modèle sont appelées données d’entraînement. Les entrées d’un modèle Machine Learning sont des caractéristiques. Dans cet exemple, $Size$ est la seule caractéristique. Les valeurs certifiées vraies utilisées pour entraîner un modèle Machine Learning sont appelées des étiquettes. Ici, les étiquettes sont les valeurs $Price$ contenues dans le jeu de données d’entraînement.
Plus complexe
Un modèle plus complexe classe les transactions financières dans différentes catégories en fonction du texte de description de la transaction.
Chaque description de transaction est décomposée en un ensemble de caractéristiques, après suppression des mots et caractères redondants, et comptage des combinaisons de mots et caractères. L’ensemble des caractéristiques est ensuite utilisé pour entraîner un modèle linéaire basé sur l’ensemble des catégories trouvées dans les données d’entraînement. Plus une nouvelle description se rapproche d’une des descriptions figurant dans le jeu de données d’entraînement, plus elle a de chance d’être attribuée à la même catégorie.

Le modèle de prix des maisons et le modèle de classification de texte sont tous les deux des modèles de type linéaire. Selon la nature de vos données et le problème à résoudre, vous pouvez également utiliser des modèles d’arbre de décision, des modèles additifs généralisés et d’autres modèles. Pour plus d’informations sur les modèles, consultez Tâches.
Préparation des données
Dans la plupart des cas, les données dont vous disposez ne peuvent pas être utilisées directement pour entraîner un modèle Machine Learning. Les données brutes doivent être préparées ou prétraitées afin de pouvoir ensuite être utilisées pour rechercher les paramètres de votre modèle. Par exemple, vous devrez peut-être convertir vos données de valeurs de chaîne en une représentation numérique, supprimer des informations redondantes dans vos données d’entrée, réduire ou développer les dimensions de vos données d’entrée, ou encore normaliser ou redimensionner vos données.
Les tutoriels ML.NET vous montrent différents pipelines de traitement des données (pour les données texte, d’image, numériques et de série chronologique) qui sont utilisés dans le cadre de tâches de machine learning spécifiques.
La rubrique Préparer vos données explique comment préparer des données de manière plus générale.
Vous trouverez toutes les transformations disponibles en annexe, dans la section des ressources.
Évaluation du modèle
Une fois que vous avez entraîné votre modèle, comment savoir si ses prédictions futures seront correctes ? Avec ML.NET, vous pouvez évaluer votre modèle par rapport à de nouvelles données de test.
Chaque type de tâche de machine learning présente des métriques qui permettent d’évaluer l’exactitude et la précision du modèle par rapport au jeu de données de test.
Dans notre exemple de prix des maisons, nous avons utilisé la tâche de régression. Pour évaluer le modèle, ajoutez le code suivant à l’exemple de code initial.
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
Les métriques d’évaluation indiquent une erreur relativement faible, et une forte corrélation entre la sortie prédite et la sortie du test. Facile, n’est-ce pas ? En réalité, vous aurez davantage de réglages à faire pour parvenir à des métriques de modèle satisfaisantes.
Architecture de ML.NET
Cette section décrit les modèles architecturaux de ML.NET. Si vous êtes un développeur .NET qualifié, certains de ces modèles vous sont déjà familiers, et d’autres moins.
Au démarrage de toute application ML.NET, il y a un objet MLContext. Cet objet singleton contient des catalogues. Un catalogue est une fabrique pour les composants de chargement et d’enregistrement des données, des transformations, des entraîneurs et de l’utilisation du modèle. Chaque objet du catalogue a des méthodes permettant de créer les différents types de composants.
| Tâche | Catalogue |
|---|---|
| Enregistrement et chargement des données | DataOperationsCatalog |
| Préparation des données | TransformsCatalog |
| Classification binaire | BinaryClassificationCatalog |
| Classification multiclasse | MulticlassClassificationCatalog |
| Détection des anomalies | AnomalyDetectionCatalog |
| Clustering | ClusteringCatalog |
| Prévisions | ForecastingCatalog |
| Classement | RankingCatalog |
| régression ; | RegressionCatalog |
| Recommandation | RecommendationCatalog |
| série chronologique | TimeSeriesCatalog |
| Utilisation du modèle | ModelOperationsCatalog |
Vous pouvez accéder aux méthodes de création dans chacune des catégories ci-dessus. Dans Visual Studio, les catalogues s’affichent via IntelliSense.
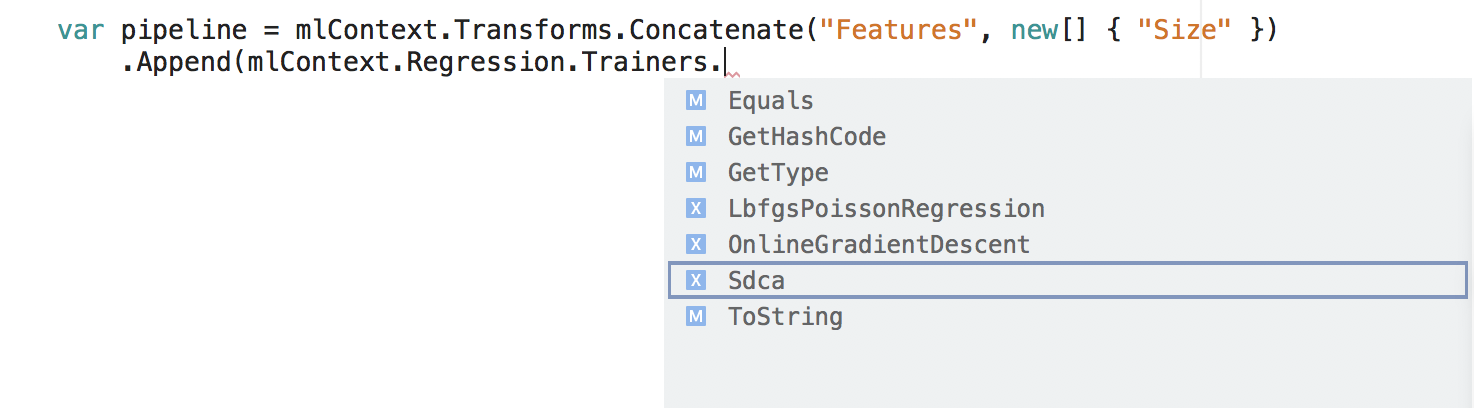
Générer le pipeline
Au sein de chaque catalogue, il existe un jeu de méthodes d’extension que vous pouvez utiliser pour créer un pipeline d’entraînement.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
Dans l’extrait de code, Concatenate et Sdca sont deux méthodes figurant dans le catalogue. Chaque méthode crée un objet IEstimator qui est ajouté au pipeline.
À ce stade, les objets ont été créés, mais aucune exécution ne s’est produite.
Entraîner le modèle
Une fois que les objets dans le pipeline ont été créés, les données peuvent être utilisées pour entraîner le modèle.
var model = pipeline.Fit(trainingData);
L’appel de Fit() déclenche l’utilisation des données d’entraînement d’entrée pour estimer les paramètres du modèle. Ce processus est l’entraînement du modèle. Souvenez-vous que le modèle de régression linéaire affiché plus haut avait deux paramètres de modèle : le biais et le poids. Après l’appel de Fit(), les valeurs des paramètres sont connues. (La plupart des modèles ont beaucoup plus de paramètres que cela.)
Pour plus d’informations sur l’entraînement du modèle, consultez Entraîner votre modèle.
L’objet modèle obtenu implémente l’interface ITransformer. Autrement dit, le modèle transforme les données d’entrée en prédictions.
IDataView predictions = model.Transform(inputData);
Utiliser le modèle
Vous pouvez transformer les données d’entrée en prédictions soit en bloc, soit entrée par entrée. Dans l’exemple des prix de maisons, nous avons fait les deux : en bloc pour l’évaluation du modèle et un par un pour effectuer une nouvelle prédiction. Examinons le cas des prédictions uniques.
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
La méthode CreatePredictionEngine() a une classe d’entrée et une classe de sortie. Les noms de champs ou les attributs de code déterminent les noms des colonnes de données utilisées durant l’entraînement du modèle et la prédiction de données. Pour plus d’informations, consultez Effectuer des prédictions avec un modèle entraîné.
Schéma et modèles de données
Les objets DataView sont au cœur du pipeline de machine learning de ML.NET.
Chaque transformation dans le pipeline a deux schémas : un schéma d’entrée (noms de données, types et tailles que la transformation s’attend à voir dans son entrée) et un schéma de sortie (noms de données, types et tailles générés suite à l’exécution de la transformation).
Si le schéma de sortie d’une transformation dans le pipeline ne correspond pas au schéma d’entrée de la transformation suivante, ML.NET lève une exception.
Un objet vue de données contient des colonnes et des lignes. Chaque colonne a un nom, un type et une longueur. Par exemple, les colonnes d’entrée dans l’exemple des prix de maisons sont Size et Price. Elles ont toutes deux un type et représentent des quantités scalaires plutôt que des quantités de vecteur.
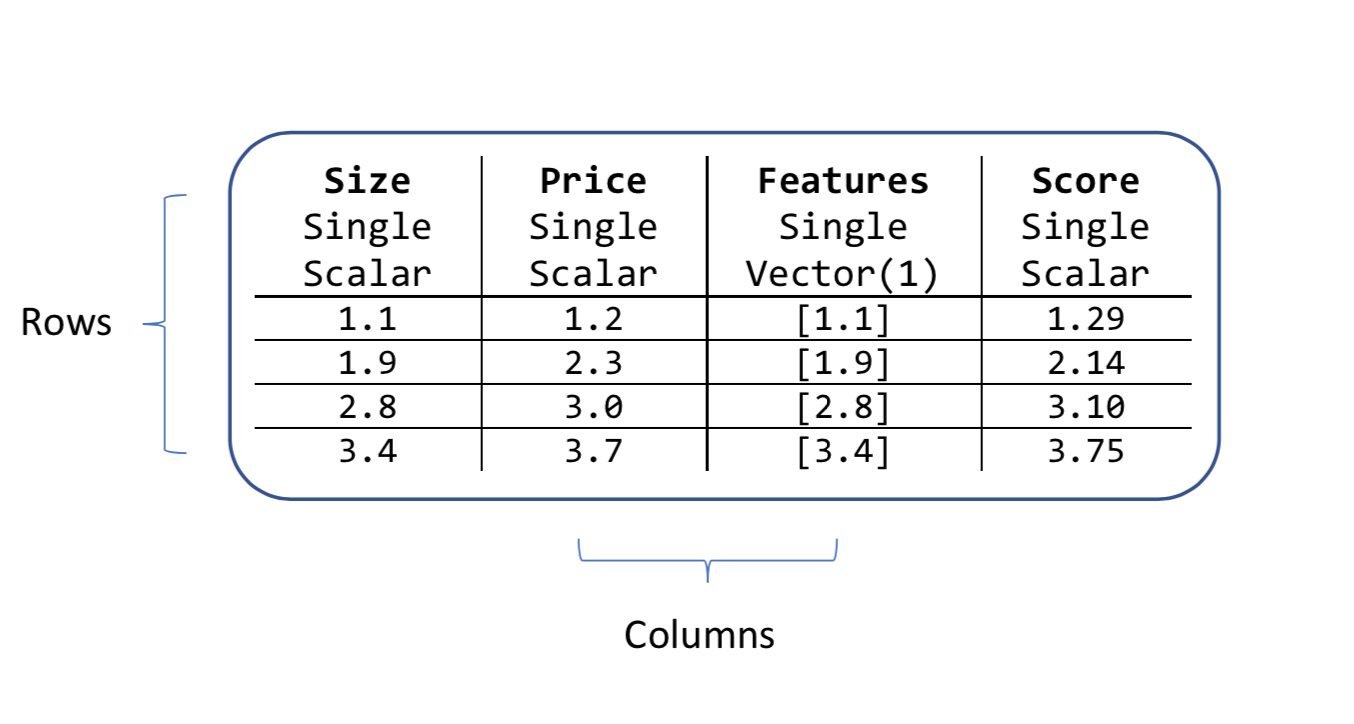
Tous les algorithmes ML.NET recherchent une colonne d’entrée de type vectorielle. Par défaut, cette colonne vectorielle est appelée Fonctionnalités. C’est pourquoi nous avons concaténé la colonne Taille en une nouvelle colonne appelée Fonctionnalités dans l’exemple de prix de maison.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
Tous les algorithmes créent également des colonnes après avoir effectué une prédiction. Les noms fixes de ces nouvelles colonnes dépendent du type d’algorithme de machine learning. Pour la tâche de régression, l’une des nouvelles colonnes s’appelle Score comme illustré dans l’attribut des données de prix.
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
Pour plus d’informations sur les colonnes de sortie des différentes tâches de machine learning, consultez le guide Tâches de machine learning.
Une propriété importante des objets DataView est leur évaluation tardive. Les objets vue de données sont uniquement chargés et traités pendant l’entraînement et l’évaluation du modèle, et durant la prédiction de données. Lors des phases d’écriture et de test de votre application ML.NET, vous pouvez utiliser le débogueur Visual Studio pour avoir un aperçu d’un objet vue de données en appelant la méthode Preview.
var debug = testPriceDataView.Preview();
Vous pouvez voir la variable debug dans le débogueur et examiner son contenu. N’utilisez pas la méthode Preview dans le code de production, car elle dégrade considérablement les performances.
Déploiement de modèle
Dans les applications réelles, votre code d’entraînement et d’évaluation du modèle sera séparé de votre code de prédiction. En fait, ces deux activités sont souvent effectuées par des équipes distinctes. L’équipe de développement du modèle peut enregistrer le modèle pour une utilisation dans l’application de prédiction.
mlContext.Model.Save(model, trainingData.Schema,"model.zip");
Étapes suivantes
Suivez plusieurs tutoriels pour apprendre à créer des applications avec différentes tâches de machine learning en utilisant des jeux de données plus réalistes.
Vous pouvez approfondir vos connaissances en consultant les guides pratiques.
Si vous en avez envie, vous pouvez directement vous plonger dans la documentation de référence des API.