Entrainement
Parcours d’apprentissage
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
Ce navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
Une fois que vous disposez d’une application Microsoft Direct3D fonctionnelle et que vous souhaitez améliorer ses performances, vous utilisez généralement un outil de profilage prêt à l’emploi ou une technique de mesure personnalisée pour mesurer le temps nécessaire pour exécuter un ou plusieurs appels d’interface de programmation d’application (API). Si vous l’avez fait, mais que vous obtenez des résultats de minutage qui varient d’une séquence de rendu à l’autre, ou si vous formulez des hypothèses qui ne tiennent pas compte des résultats réels de l’expérience, les informations suivantes peuvent vous aider à comprendre pourquoi.
Les informations fournies ici sont basées sur l’hypothèse que vous avez connaissance et expérience des éléments suivants :
Un profileur indique le temps passé dans chaque appel d’API. Cela permet d’améliorer les performances en recherchant et en éliminant les points chauds. Il existe différents types de profileurs et de techniques de profilage.
Le type de profileur ou de technique de profilage utilisé ne fait qu’une partie du défi de la génération de mesures précises.
Le profilage vous donne des réponses qui vous aident à budgéter les performances. Par instance, supposons qu’un appel d’API s’exécute en moyenne mille cycles d’horloge. Vous pouvez affirmer certaines conclusions sur les performances telles que les suivantes :
En d’autres termes, si vous disposiez de suffisamment de temps par appel d’API, vous pouvez répondre à une question de budgétisation telle que le nombre de primitives pouvant être rendues de manière interactive. Mais les nombres bruts retournés par un profileur d’instrumentation ne répondront pas avec précision aux questions de budgétisation. Cela est dû au fait que le pipeline graphique présente des problèmes de conception complexes tels que le nombre de composants qui doivent effectuer un travail, le nombre de processeurs qui contrôlent le flux de travail entre les composants et les stratégies d’optimisation implémentées dans le runtime et dans un pilote qui sont conçues pour rendre le pipeline plus efficace.
Chaque appel est traité par plusieurs composants lors de son passage de l’application à la vidéo carte. Pour instance, considérez la séquence de rendu suivante contenant deux appels pour dessiner un triangle unique :
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
Le diagramme conceptuel suivant montre les différents composants par lesquels les appels doivent passer.

L’application appelle Direct3D qui contrôle la scène, gère les interactions utilisateur et détermine comment le rendu est effectué. Tout ce travail est spécifié dans la séquence de rendu, qui est envoyée au runtime à l’aide d’appels d’API Direct3D. La séquence de rendu est pratiquement indépendante du matériel (autrement dit, les appels d’API sont indépendants du matériel, mais une application a connaissance des fonctionnalités prises en charge par une vidéo carte).
Le runtime convertit ces appels dans un format indépendant de l’appareil. Le runtime gère toutes les communications entre l’application et le pilote, afin qu’une application s’exécute sur plusieurs composants matériels compatibles (en fonction des fonctionnalités requises). Lors de la mesure d’un appel de fonction, un profileur d’instrumentation mesure le temps passé dans une fonction, ainsi que le temps de retour de la fonction. L’une des limitations d’un profileur d’instrumentation est qu’il ne peut pas inclure le temps nécessaire à un pilote pour envoyer le travail obtenu à la vidéo carte ni le temps nécessaire à la vidéo carte pour traiter le travail. En d’autres termes, un profileur d’instrumentation prêt à l’emploi ne parvient pas à attribuer tout le travail associé à chaque appel de fonction.
Le pilote logiciel utilise des connaissances spécifiques au matériel sur la vidéo carte pour convertir les commandes indépendantes du périphérique en une séquence de commandes vidéo carte. Les pilotes peuvent également optimiser la séquence de commandes envoyées à la vidéo carte, afin que le rendu sur le carte vidéo soit effectué efficacement. Ces optimisations peuvent entraîner des problèmes de profilage, car la quantité de travail effectuée n’est pas ce qu’elle semble être (vous devrez peut-être comprendre les optimisations pour les prendre en compte). Le pilote retourne généralement le contrôle au runtime avant que le carte vidéo ait terminé de traiter toutes les commandes.
Le carte vidéo effectue la majeure partie du rendu en combinant les données des tampons de vertex et d’index, des textures, des informations d’état de rendu et des commandes graphiques. Une fois le rendu de la vidéo carte terminé, le travail créé à partir de la séquence de rendu est terminé.
Chaque appel d’API Direct3D doit être traité par chaque composant (le runtime, le pilote et la vidéo carte) pour afficher quoi que ce soit.
La relation entre ces composants est encore plus complexe, car l’application, le runtime et le pilote sont contrôlés par un seul processeur et la carte vidéo est contrôlée par un processeur distinct. Le diagramme suivant montre deux types de processeurs : une unité de traitement centrale (UC) et une unité de traitement graphique (GPU).
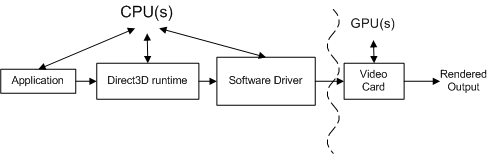
Les systèmes PC ont au moins un processeur et un GPU, mais peuvent en avoir plusieurs ou les deux. Les processeurs se trouvent sur la carte mère et les GPU se trouvent sur la carte mère ou sur la vidéo carte. La vitesse de l’UC est déterminée par une puce d’horloge sur la carte mère, et la vitesse du GPU est déterminée par une puce d’horloge distincte. L’horloge du processeur contrôle la vitesse du travail effectué par l’application, le runtime et le pilote. L’application envoie du travail au GPU via le runtime et le pilote.
Le processeur et le GPU s’exécutent généralement à des vitesses différentes, indépendamment les uns des autres. Le GPU peut répondre au travail dès que le travail est disponible (en supposant que le GPU a terminé de traiter le travail précédent). Le travail GPU est effectué en parallèle avec le travail du processeur, tel que mis en évidence par la ligne courbe dans la figure ci-dessus. Un profileur mesure généralement les performances du processeur, et non du GPU. Cela rend le profilage difficile, car les mesures effectuées par un profileur d’instrumentation incluent le temps processeur, mais peuvent ne pas inclure le temps GPU.
L’objectif du GPU est de décharger le traitement du processeur vers un processeur spécialement conçu pour le travail graphique. Sur les cartes vidéo modernes, le GPU remplace une grande partie du travail de transformation et d’éclairage dans le pipeline, de l’UC au GPU. Cela réduit considérablement la charge de travail du processeur, ce qui laisse davantage de cycles de processeur disponibles pour d’autres traitements. Pour optimiser les performances d’une application graphique, vous devez mesurer les performances de l’UC et du GPU, et équilibrer le travail entre les deux types de processeurs.
Ce document ne couvre pas les sujets liés à la mesure des performances du GPU ou à l’équilibrage du travail entre l’UC et le GPU. Si vous souhaitez mieux comprendre les performances d’un GPU (ou d’un carte vidéo particulier), visitez le site web du fournisseur pour obtenir plus d’informations sur les performances gpu. Au lieu de cela, ce document se concentre sur le travail effectué par le runtime et le pilote en réduisant le travail gpu à une quantité négligeable. Cela est, en partie, basé sur l’expérience que les applications qui rencontrent des problèmes de performances sont généralement limitées au processeur.
Le runtime intègre une optimisation des performances qui peut surcharger la mesure d’un appel individuel. Voici un exemple de scénario qui illustre ce problème. Considérez la séquence de rendu suivante :
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
Exemple 1 : Séquence de rendu simple
En examinant les résultats des deux appels dans la séquence de rendu, un profileur d’instrumentation peut retourner des résultats similaires à ceux-ci :
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
Le profileur retourne le nombre de cycles d’UC requis pour traiter le travail associé à chaque appel (n’oubliez pas que le GPU n’est pas inclus dans ces numéros, car le GPU n’a pas encore commencé à travailler sur ces commandes). Étant donné que IDirect3DDevice9::D rawPrimitive a nécessité près d’un million de cycles à traiter, vous pouvez conclure qu’il n’est pas très efficace. Toutefois, vous verrez bientôt pourquoi cette conclusion est incorrecte et comment vous pouvez générer des résultats qui peuvent être utilisés pour la budgétisation.
Tous les appels autres que IDirect3DDevice9::D rawPrimitive, DrawIndexedPrimitive ou Clear (par exemple, SetTexture, SetVertexDeclaration et SetRenderState) produisent un changement d’état. Chaque modification d’état définit l’état du pipeline qui contrôle la façon dont le rendu sera effectué.
Les optimisations dans le runtime et/ou le pilote sont conçues pour accélérer le rendu en réduisant la quantité de travail requise. Voici quelques optimisations des changements d’état qui peuvent polluer les moyennes de profil :
Il n’existe aucun moyen infaillible d’examiner une séquence de rendu et de conclure aux changements d’état qui définissent un bit sale et reportent le travail, ou sont simplement supprimés par optimisation. Même si vous pouvez identifier les changements d’état optimisés dans le runtime ou le pilote d’aujourd’hui, le runtime ou le pilote de demain est susceptible d’être mis à jour. Comme vous ne savez pas facilement quel était l’état précédent, il est difficile d’identifier les changements d’état redondants. La seule façon de vérifier le coût d’un changement d’état consiste à mesurer la séquence de rendu qui inclut les modifications d’état.
Comme vous pouvez le voir, les complications provoquées par le fait d’avoir plusieurs processeurs, les commandes traitées par plusieurs composants et les optimisations intégrées aux composants rendent le profilage difficile à prédire. Dans la section suivante, chacun de ces défis de profilage sera traité. Des exemples de séquences de rendu Direct3D seront affichés, avec les techniques de mesure associées. Avec ces connaissances, vous serez en mesure de générer des mesures précises et reproductibles sur des appels individuels.
Maintenant que certains des défis de profilage ont été mis en évidence, cette section vous présente les techniques qui vous aideront à générer des mesures de profil qui peuvent être utilisées pour la budgétisation. Des mesures de profilage précises et reproductibles sont possibles si vous comprenez la relation entre les composants contrôlés par le processeur et comment éviter les optimisations des performances implémentées par le runtime et le pilote.
Pour commencer, vous devez être en mesure de mesurer avec précision le temps d’exécution d’un seul appel d’API.
Le système d’exploitation Microsoft Windows comprend un minuteur haute résolution qui peut être utilisé pour mesurer les temps écoulés à haute résolution. La valeur actuelle de l’un de ces minuteurs peut être retournée à l’aide de QueryPerformanceCounter. Après avoir appelé QueryPerformanceCounter pour retourner des valeurs de début et d’arrêt, la différence entre les deux valeurs peut être convertie en temps écoulé réel (en secondes) à l’aide de QueryPerformanceCounter.
Les avantages de l’utilisation de QueryPerformanceCounter sont qu’il est disponible dans Windows et qu’il est facile à utiliser. Entourez simplement les appels d’un appel QueryPerformanceCounter et enregistrez les valeurs de début et d’arrêt. Par conséquent, cet article montre comment utiliser QueryPerformanceCounter pour profiler les temps d’exécution, de la même manière qu’un profileur d’instrumentation les mesure. Voici un exemple qui montre comment incorporer QueryPerformanceCounter dans votre code source :
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
Exemple 2 : Implémentation du profilage personnalisé avec QPC
start et stop sont deux grands entiers qui contiennent les valeurs de début et d’arrêt retournées par le minuteur hautes performances. Notez que QueryPerformanceCounter(&start) est appelé juste avant que SetTexture et QueryPerformanceCounter(&stop) soit appelé juste après DrawPrimitive. Après avoir obtenu la valeur d’arrêt, QueryPerformanceFrequency est appelé pour retourner freq, qui est la fréquence du minuteur haute résolution. Dans cet exemple hypothétique, supposons que vous obteniez les résultats suivants pour start, stop et freq :
| Variable locale | Nombre de ticks |
|---|---|
| start | 1792998845094 |
| stop | 1792998845102 |
| Freq | 3579545 |
Vous pouvez convertir ces valeurs en nombre de cycles qu’il faut pour exécuter les appels d’API comme suit :
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
En d’autres termes, il faut environ 4568 cycles d’horloge pour traiter SetTexture et DrawPrimitive sur cette machine de 2 GHz. Vous pouvez convertir ces valeurs en temps réel nécessaire pour exécuter tous les appels comme suit :
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
L’utilisation de QueryPerformanceCounter nécessite d’ajouter des mesures de début et d’arrêt à votre séquence de rendu et d’utiliser QueryPerformanceFrequency pour convertir la différence (nombre de graduations) en nombre de cycles d’UC ou en temps réel. L’identification de la technique de mesure est un bon début pour développer une implémentation de profilage personnalisé. Mais avant de commencer à prendre des mesures, vous devez savoir comment gérer les carte vidéo.
Comme indiqué précédemment, l’UC et le GPU fonctionnent en parallèle pour traiter le travail généré par les appels d’API. Une application réelle nécessite le profilage des deux types de processeurs pour déterminer si votre application est limitée au processeur ou au GPU. Étant donné que les performances gpu sont spécifiques au fournisseur, il serait très difficile de produire des résultats dans ce document qui couvre la variété des cartes vidéo disponibles.
Au lieu de cela, ce document se concentre uniquement sur le profilage du travail effectué par le processeur à l’aide d’une technique personnalisée pour mesurer le travail du runtime et du pilote. Le travail gpu sera réduit à une quantité insignifiante, de sorte que les résultats du processeur sont plus visibles. L’un des avantages de cette approche est que cette technique produit des résultats dans l’annexe que vous devriez être en mesure de corréler avec vos mesures. Pour réduire le travail requis par la vidéo carte à un niveau insignifiant, il suffit de réduire le travail de rendu au moins possible. Cela peut être effectué en limitant les appels de dessin pour afficher un triangle unique, et peut être davantage contraint de sorte que chaque triangle ne contienne qu’un seul pixel.
L’unité de mesure utilisée dans ce document pour mesurer le travail du processeur sera le nombre de cycles d’horloge du processeur plutôt que l’heure réelle. Les cycles d’horloge du processeur ont l’avantage d’être plus portables (pour les applications limitées au processeur) que le temps écoulé réel entre les machines avec des vitesses d’UC différentes. Cela peut facilement être converti en temps réel si vous le souhaitez.
Ce document ne couvre pas les sujets liés à l’équilibrage de la charge de travail entre le processeur et le GPU. N’oubliez pas que l’objectif de ce document n’est pas de mesurer les performances globales d’une application, mais de vous montrer comment mesurer avec précision le temps nécessaire au runtime et au pilote pour traiter les appels d’API. Avec ces mesures précises, vous pouvez effectuer la tâche de budgétisation du processeur pour comprendre certains scénarios de performances.
Avec une technique de mesure identifiée et une stratégie de réduction du travail gpu, l’étape suivante consiste à comprendre les optimisations du runtime et des pilotes qui se mettent en route lorsque vous effectuez le profilage.
Le travail du processeur peut être divisé en trois compartiments : le travail de l’application, le travail d’exécution et le travail du pilote. Ignorez le travail de l’application, car il est sous contrôle du programmeur. Du point de vue de l’application, le runtime et le pilote sont comme des boîtes noires, car l’application n’a aucun contrôle sur ce qui est implémenté dans ces zones. La clé est de comprendre les techniques d’optimisation qui peuvent être implémentées dans le runtime et le pilote. Si vous ne comprenez pas ces optimisations, il est très facile de tirer une conclusion erronée sur la quantité de travail effectuée par le processeur en fonction des mesures de profil. En particulier, il existe deux rubriques liées à ce qu’on appelle la mémoire tampon de commande et à ce qu’elle peut faire pour masquer le profilage. Ces rubriques sont les suivantes :
Lorsqu’une application effectue un appel d’API, le runtime convertit l’appel d’API en un format indépendant de l’appareil (que nous appellerons une commande) et le stocke dans la mémoire tampon de commande. La mémoire tampon de commande est ajoutée au diagramme suivant.
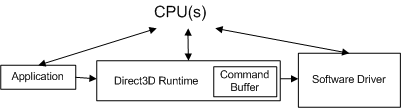
Chaque fois que l’application effectue un autre appel d’API, le runtime répète cette séquence et ajoute une autre commande à la mémoire tampon de commande. À un moment donné, le runtime vide la mémoire tampon (en envoyant les commandes au pilote). Dans Windows XP, le vidage de la mémoire tampon de commande entraîne une transition du mode lorsque le système d’exploitation passe du runtime (en mode utilisateur) au pilote (en mode noyau), comme illustré dans le diagramme suivant.
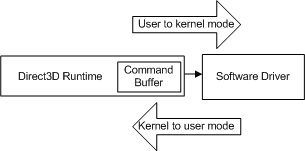
La transition se produit chaque fois que le processeur passe du mode utilisateur au mode noyau (et inversement) et que le nombre de cycles requis est élevé par rapport à un appel d’API individuel. Si le runtime a envoyé chaque appel d’API au pilote lorsqu’il a été appelé, chaque appel d’API entraînerait le coût d’une transition de mode.
Au lieu de cela, la mémoire tampon de commandes est une optimisation du runtime conçue pour réduire le coût effectif de la transition du mode. La mémoire tampon de commande met en file d’attente de nombreuses commandes de pilote en vue d’une transition en mode unique. Lorsque le runtime ajoute une commande à la mémoire tampon de commande, le contrôle est retourné à l’application. Un profileur n’a aucun moyen de savoir que les commandes du pilote n’ont probablement même pas encore été envoyées au conducteur. Par conséquent, les nombres retournés par un profileur d’instrumentation prêt à l’emploi sont trompeurs, car il mesure le travail d’exécution, mais pas le travail du pilote associé.
À l’aide de la séquence de rendu de l’exemple 2, voici quelques mesures de minutage typiques qui illustrent l’ampleur d’une transition de mode. En supposant que les appels SetTexture et DrawPrimitive ne provoquent pas de transition de mode, un profileur d’instrumentation prêt à l’emploi peut retourner des résultats similaires à ceux-ci :
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Chacun de ces numéros est le temps nécessaire au runtime pour ajouter ces appels à la mémoire tampon de commande. Comme il n’y a pas de transition de mode, le pilote n’a pas encore effectué de travail. Les résultats du profileur sont précis, mais ils ne mesurent pas tout le travail que la séquence de rendu va éventuellement entraîner l’exécution du processeur.
À présent, examinez ce qui se passe pour le même exemple lorsqu’une transition de mode se produit. Cette fois, supposons que SetTexture et DrawPrimitive provoquent une transition de mode. Encore une fois, un profileur d’instrumentation prêt à l’emploi peut retourner des résultats similaires à ceux-ci :
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
Le temps mesuré pour SetTexture est à peu près le même, mais l’augmentation spectaculaire du temps passé dans DrawPrimitive est due à la transition du mode. Voici ce qui se passe :
En résumant les résultats, vous voyez :
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
Tout comme la mesure de DrawPrimitive sans transition de mode (900 cycles), la mesure de DrawPrimitive avec la transition de mode (947 950 cycles) est précise mais inutile en termes de budget du travail processeur. Le résultat contient le travail d’exécution correct, le travail du pilote pour SetTexture, le travail du pilote pour toutes les commandes qui ont précédé SetTexture et deux transitions de mode. Toutefois, le travail du pilote DrawPrimitive est manquant pour la mesure.
Une transition de mode peut se produire en réponse à n’importe quel appel. Cela dépend de ce qui se trouvait précédemment dans la mémoire tampon de commandes. Vous devez contrôler la transition du mode pour comprendre la quantité de travail du processeur (runtime et pilote) associée à chaque appel. Pour ce faire, vous avez besoin d’un mécanisme pour contrôler la mémoire tampon de commandes et le minutage de la transition du mode.
Le mécanisme de requête dans Microsoft Direct3D 9 a été conçu pour permettre au runtime d’interroger le GPU sur la progression et de retourner certaines données à partir du GPU. Lors du profilage, si le travail gpu est réduit afin d’avoir un impact négligeable sur les performances, vous pouvez retourner status à partir du GPU pour vous aider à mesurer le travail du pilote. Après tout, le travail du pilote est terminé lorsque le GPU a vu les commandes du pilote. En outre, le mécanisme de requête peut être intégré dans le contrôle de deux caractéristiques de mémoire tampon de commande qui sont importantes pour le profilage : quand la mémoire tampon de commande se vide et la quantité de travail dans la mémoire tampon.
Voici la même séquence de rendu à l’aide du mécanisme de requête :
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
Exemple 3 : Utilisation d’une requête pour contrôler la mémoire tampon de commandes
Voici une explication plus détaillée de chacune de ces lignes de code :
Voici les résultats mesurés avec QueryPerformanceCounter et QueryPerformanceFrequency :
| Variable locale | Nombre de cycles |
|---|---|
| start | 1792998845060 |
| stop | 1792998845090 |
| Freq | 3579545 |
Conversion de cycles en cycles une fois de plus (sur un ordinateur de 2 GHz) :
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
Voici la répartition du nombre de cycles par appel :
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
Le mécanisme de requête nous a permis de contrôler le runtime et le travail du pilote mesuré. Pour comprendre chacun de ces numéros, voici ce qui se passe en réponse à chacun des appels d’API, ainsi que les minutages estimés :
Le premier appel vide la mémoire tampon de commande en appelant GetData avec D3DGETDATA_FLUSH. Lorsque le GPU a terminé de traiter tout le travail de la mémoire tampon de commandes, GetData retourne S_OK et la boucle est terminée, car le GPU est inactif.
La séquence de rendu commence par convertir SetTexture dans un format indépendant du périphérique et l’ajouter à la mémoire tampon de commandes. Supposons que cela prend environ 100 cycles.
DrawPrimitive est converti et ajouté à la mémoire tampon de commandes. Supposons que cela prend environ 900 cycles.
Le problème ajoute un marqueur de requête à la mémoire tampon de commande. Supposons que cela prend environ 200 cycles.
GetData entraîne le vidage de la mémoire tampon de commandes, ce qui force la transition en mode noyau. Supposons que cela prend environ 5 000 cycles.
Le pilote traite ensuite le travail associé aux quatre appels. Supposons que le temps du pilote pour traiter SetTexture est d’environ 2964 cycles, que DrawPrimitive est d’environ 3 600 cycles, que Issue est d’environ 200 cycles. Ainsi, la durée totale du pilote pour les quatre commandes est d’environ 6450 cycles.
Notes
Le pilote prend également un peu de temps pour voir quel est le status du GPU. Étant donné que le travail gpu est trivial, le GPU doit déjà être effectué. GetData retourne S_OK en fonction de la probabilité que le GPU soit terminé.
Lorsque le pilote termine son travail, la transition en mode utilisateur retourne le contrôle au runtime. La mémoire tampon de commandes est maintenant vide. Supposons que cela prend environ 5 000 cycles.
Les nombres de GetData sont les suivants :
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
Le mécanisme de requête utilisé en combinaison avec QueryPerformanceCounter mesure tout le travail du processeur. Pour ce faire, vous pouvez combiner des marqueurs de requête et des comparaisons de status de requête. Les marqueurs de requête de démarrage et d’arrêt ajoutés à la mémoire tampon de commande sont utilisés pour contrôler la quantité de travail dans la mémoire tampon. En attendant que le code de retour approprié soit retourné, la mesure de début est effectuée juste avant le début d’une séquence de rendu propre et la mesure d’arrêt est effectuée juste après que le pilote a terminé le travail associé au contenu de la mémoire tampon de commande. Cela capture efficacement le travail du processeur effectué par le runtime, ainsi que par le pilote.
Maintenant que vous connaissez la mémoire tampon de commandes et l’effet qu’elle peut avoir sur le profilage, vous devez savoir qu’il existe quelques autres conditions qui peuvent entraîner le vide de la mémoire tampon de commandes par le runtime. Vous devez les watch dans vos séquences de rendu. Certaines de ces conditions sont en réponse aux appels d’API, d’autres en réponse à des modifications de ressources dans le runtime. L’une des conditions suivantes entraîne une transition de mode :
Veillez à watch pour ces conditions dans vos séquences de rendu. Chaque fois qu’une transition de mode est ajoutée, 10 000 cycles de travail de pilote sont ajoutés à vos mesures de profilage. En outre, la mémoire tampon de commandes n’est pas dimensionnée de manière statique. Le runtime peut modifier la taille de la mémoire tampon en fonction de la quantité de travail générée par l’application. Il s’agit d’une autre optimisation qui dépend d’une séquence de rendu.
Veillez donc à contrôler les transitions de mode pendant le profilage. Le mécanisme de requête offre une méthode robuste pour vider la mémoire tampon de commande, ce qui vous permet de contrôler le moment de la transition du mode ainsi que la quantité de travail que contient la mémoire tampon. Toutefois, même cette technique peut être améliorée en réduisant le temps de transition du mode pour le rendre insignifiant par rapport au résultat mesuré.
Dans l’exemple précédent, le commutateur en mode noyau et le commutateur en mode utilisateur consomment environ 10 000 cycles qui n’ont rien à voir avec le travail du runtime et du pilote. Étant donné que la transition en mode est intégrée au système d’exploitation, elle ne peut pas être réduite à zéro. Pour rendre la transition de mode insignifiante, la séquence de rendu doit être ajustée de sorte que le travail du pilote et du runtime soit un ordre de grandeur supérieur à celui des commutateurs de mode. Vous pouvez essayer d’effectuer une soustraction pour supprimer les transitions, mais l’amortissement du coût sur un coût de séquence de rendu beaucoup plus élevé est plus fiable.
La stratégie de réduction de la transition de mode jusqu’à ce qu’elle devienne insignifiante consiste à ajouter une boucle à la séquence de rendu. Par exemple, examinons les résultats du profilage si une boucle est ajoutée qui répète la séquence de rendu 1500 fois :
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
Exemple 4 : Ajouter une boucle à la séquence de rendu
Voici les résultats mesurés avec QueryPerformanceCounter et QueryPerformanceFrequency :
| Variable locale | Nombre de tics |
|---|---|
| start | 1792998845000 |
| stop | 1792998847084 |
| Freq | 3579545 |
L’utilisation de QueryPerformanceCounter mesure maintenant 2 840 graduations. La conversion des graduations en cycles est la même que celle que nous avons déjà montrée :
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
En d’autres termes, il faut environ 6,9 millions de cycles sur cette machine à 2 GHz pour traiter les 1500 appels dans la boucle de rendu. Sur les 6,9 millions de cycles, la durée des transitions en mode est d’environ 10 000. Les résultats du profil mesurent donc presque entièrement le travail associé à SetTexture et DrawPrimitive.
Notez que l’exemple de code nécessite un tableau de deux textures. Pour éviter une optimisation du runtime qui supprimerait SetTexture s’il définit le même pointeur de texture chaque fois qu’il est appelé, utilisez simplement un tableau de deux textures. De cette façon, chaque fois que la boucle passe, le pointeur de texture change et le travail complet associé à SetTexture est effectué. Assurez-vous que les deux textures ont la même taille et le même format, afin qu’aucun autre état ne change lorsque la texture le fait.
Vous disposez maintenant d’une technique pour profiler Direct3D. Il s’appuie sur le compteur hautes performances (QueryPerformanceCounter) pour enregistrer le nombre de graduations qu’il faut au processeur pour traiter le travail. Le travail est soigneusement contrôlé pour être le travail d’exécution et de pilote associé aux appels d’API à l’aide du mécanisme de requête. Une requête fournit deux moyens de contrôle : d’abord pour vider la mémoire tampon de commande avant le début de la séquence de rendu, puis pour retourner une fois le travail GPU terminé.
Jusqu’à présent, cet article a montré comment profiler une séquence de rendu. Chaque séquence de rendu a été assez simple, contenant un seul appel DrawPrimitive et un appel SetTexture . Cela a été fait pour se concentrer sur la mémoire tampon de commande et l’utilisation du mécanisme de requête pour la contrôler. Voici un bref résumé de la façon de profiler une séquence de rendu arbitraire :
Toutes ces techniques sont utilisées pour profiler les changements d’état. En supposant que vous avez lu et compris comment contrôler la mémoire tampon de commande et que vous avez effectué avec succès les mesures de base sur DrawPrimitive, vous êtes prêt à ajouter des changements d’état à vos séquences de rendu. Il existe quelques défis supplémentaires de profilage lors de l’ajout de changements d’état à une séquence de rendu. Si vous envisagez d’ajouter des modifications d’état à vos séquences de rendu, veillez à passer à la section suivante.
Direct3D utilise de nombreux états de rendu pour contrôler presque tous les aspects du pipeline. Les API qui provoquent des changements d’état incluent toute fonction ou méthode autre que les appels Draw*Primitive.
Les changements d’état sont difficiles, car il se peut que vous ne puissiez pas voir le coût d’un changement d’état sans rendu. Il s’agit d’un résultat de l’algorithme paresseux que le pilote et le GPU utilisent pour différer le travail jusqu’à ce qu’il soit absolument nécessaire de le faire. En général, vous devez suivre ces étapes pour mesurer un seul changement d’état :
Naturellement, tout ce que vous avez appris sur l’utilisation du mécanisme de requête et la mise en boucle de la séquence de rendu pour nier le coût de la transition du mode s’applique toujours.
À partir d’une séquence de rendu qui contient DrawPrimitive, voici la séquence de code pour mesurer le coût d’ajout de SetTexture :
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
Exemple 5 : Mesure d’un appel d’API de changement d’état
Notez que la boucle contient deux appels, SetTexture et DrawPrimitive. La séquence de rendu boucle 1500 fois et génère des résultats similaires à ceux-ci :
| Variable locale | Nombre de tics |
|---|---|
| start | 1792998860000 |
| stop | 1792998870260 |
| Freq | 3579545 |
La conversion des graduations en cycles donne à nouveau les résultats suivants :
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
La division par le nombre d’itérations dans la boucle donne :
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
Chaque itération de la boucle contient un changement d’état et un appel de dessin. La soustraction du résultat de la séquence de rendu DrawPrimitive laisse :
3850 - 1100 = 2750 cycles for SetTexture
Il s’agit du nombre moyen de cycles pour ajouter SetTexture à cette séquence de rendu. Cette même technique peut être appliquée à d’autres changements d’état.
Pourquoi SetTexture est-il appelé un simple changement d’état ? Étant donné que l’état en cours de définition est limité afin que le pipeline effectue la même quantité de travail chaque fois que l’état est modifié. La contrainte des deux textures à la même taille et au même format garantit la même quantité de travail pour chaque appel SetTexture .
D’autres changements d’état entraînent la modification de la quantité de travail effectuée par le pipeline graphique pour chaque itération de la boucle de rendu. Par exemple, si z-testing est activé, chaque couleur de pixel met à jour une cible de rendu uniquement une fois que la valeur z du nouveau pixel a été testée par rapport à la valeur z pour le pixel existant. Si z-testing est désactivé, ce test par pixel n’est pas effectué et la sortie est écrite beaucoup plus rapidement. L’activation ou la désactivation de l’état z-test change considérablement la quantité de travail effectuée (par le processeur ainsi que par le GPU) pendant le rendu.
SetRenderState nécessite un état de rendu particulier et une valeur d’état pour activer ou désactiver z-testing. La valeur d’état particulière est évaluée au moment de l’exécution pour déterminer la quantité de travail nécessaire. Il est difficile de mesurer ce changement d’état dans une boucle de rendu et de conditionner l’état du pipeline pour qu’il bascule. La seule solution consiste à activer le changement d’état pendant la séquence de rendu.
Par exemple, la technique de profilage doit être répétée deux fois comme suit :
Avec la technique de bouclage utilisée dans la séquence de rendu, le coût de la modification de l’état du pipeline doit être mesuré en basculant l’état d’une condition « true » à une condition « false » et vice versa, pour chaque itération dans la séquence de rendu. La signification de « vrai » et de « faux » ici n’est pas littérale, cela signifie simplement que l’état doit être défini dans des conditions opposées. Cela entraîne la mesure des deux changements d’état pendant le profilage. Bien sûr, tout ce que vous avez appris sur l’utilisation du mécanisme de requête et la mise en boucle de la séquence de rendu pour annuler le coût de la transition du mode s’applique toujours.
Par exemple, voici la séquence de code permettant de mesurer le coût de l’activation ou de la désactivation des tests z :
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
Exemple 5 : mesure d’un changement d’état bascule
La boucle bascule l’état en exécutant deux appels SetRenderState . Le premier appel SetRenderState désactive z-testing et le second SetRenderState active z-testing. Chaque SetRenderState est suivi de DrawPrimitive afin que le travail associé au changement d’état soit traité par le pilote au lieu de définir uniquement un bit sale dans le pilote.
Ces nombres sont raisonnables pour cette séquence de rendu :
| Variable locale | Nombre de cycles |
|---|---|
| start | 1792998845000 |
| stop | 1792998861740 |
| Freq | 3579545 |
La conversion de cycles en cycles génère à nouveau :
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
La division par le nombre d’itérations dans la boucle génère :
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
Chaque itération de la boucle contient deux changements d’état et deux appels de dessin. La soustraction des appels de dessin (en supposant 1 100 cycles) laisse :
6200 - 1100 - 1100 = 4000 cycles for both state changes
Il s’agit du nombre moyen de cycles pour les deux changements d’état, de sorte que le temps moyen pour chaque changement d’état est :
4000 / 2 = 2000 cycles for each state change
Par conséquent, le nombre moyen de cycles pour activer ou désactiver les tests z est de 2 000 cycles. Il est important de noter que QueryPerformanceCounter mesure z-enable la moitié du temps et z-disable moitié du temps. Cette technique mesure en fait la moyenne des deux changements d’état. En d’autres termes, vous mesurez le temps nécessaire pour basculer un état. À l’aide de cette technique, vous n’avez aucun moyen de savoir si les temps d’activation et de désactivation sont équivalents, car vous avez mesuré la moyenne des deux. Néanmoins, il s’agit d’un nombre raisonnable à utiliser lors de la budgétisation d’un état bascule, car une application qui provoque ce changement d’état ne peut le faire qu’en basculant cet état.
Vous pouvez maintenant appliquer ces techniques et profiler tous les changements d’état que vous souhaitez, n’est-ce pas ? Pas tout à fait. Vous devez tout de même faire attention aux optimisations conçues pour réduire la quantité de travail à effectuer. Il existe deux types d’optimisations que vous devez connaître lors de la conception de vos séquences de rendu.
La section précédente montre comment profiler les deux types de changements d’état : un changement d’état simple qui est contraint de générer la même quantité de travail pour chaque itération, et un changement d’état bascule qui change considérablement la quantité de travail effectuée. Que se passe-t-il si vous prenez la séquence de rendu précédente et que vous y ajoutez un autre changement d’état ? Par instance, cet exemple prend la séquence de rendu z-enable> et y ajoute une comparaison z-func :
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
L’état z-func définit le niveau de comparaison lors de l’écriture dans la mémoire tampon z (entre la valeur z d’un pixel actuel et la valeur z d’un pixel dans la mémoire tampon de profondeur). D3DCMP_NEVER désactive la comparaison de z-testing tandis que D3DCMP_ALWAYS définit la comparaison pour qu’elle se produise chaque fois que z-testing est effectué.
Le profilage de l’une de ces modifications d’état dans une séquence de rendu avec DrawPrimitive génère des résultats similaires à ceux-ci :
| Changement d’état unique | Nombre moyen de cycles |
|---|---|
| D3DRS_ZENABLE uniquement | 2000 |
or
| Changement d’état unique | Nombre moyen de cycles |
|---|---|
| D3DRS_ZFUNC uniquement | 600 |
Toutefois, si vous profilez à la fois D3DRS_ZENABLE et D3DRS_ZFUNC dans la même séquence de rendu, vous pouvez voir des résultats comme suit :
| Les deux changements d’état | Nombre moyen de cycles |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
Vous pouvez vous attendre à ce que le résultat soit la somme de 2 000 et 600 (ou 2600) cycles, car le pilote effectue tout le travail associé à la définition des deux états de rendu. Au lieu de cela, la moyenne est de 2 000 cycles.
Ce résultat reflète une optimisation des changements d’état implémentée dans le runtime, le pilote ou le GPU. Dans ce cas, le pilote peut voir le premier SetRenderState et définir un état sale qui reporterait le travail à plus tard. Lorsque le pilote voit le deuxième SetRenderState, le même état sale peut être défini de manière redondante et le même travail est à nouveau reporté. Lorsque DrawPrimitive est appelé, le travail associé à l’état sale est finalement traité. Le pilote exécute le travail une seule fois, ce qui signifie que les deux premières modifications d’état sont effectivement consolidées par le pilote. De même, les troisième et quatrième changements d’état sont effectivement consolidés par le pilote en un seul changement d’état lorsque le deuxième DrawPrimitive est appelé. Le résultat net est que le pilote et le GPU traitent un seul changement d’état pour chaque appel de dessin.
Il s’agit d’un bon exemple d’optimisation de pilote dépendant de la séquence. Le pilote a reporté le travail deux fois en définissant un état sale, puis a effectué le travail une fois pour effacer l’état sale. Il s’agit d’un bon exemple du genre d’amélioration de l’efficacité qui peut se produire lorsque le travail est reporté jusqu’à ce qu’il soit absolument nécessaire.
Comment savoir quels changements d’état définissent un état sale en interne et, par conséquent, reportent le travail à plus tard ? Uniquement en testant les séquences de rendu (ou en parlant aux enregistreurs de pilotes). Les pilotes sont mis à jour et améliorés régulièrement afin que la liste des optimisations ne soit pas statique. Il n’existe qu’une seule façon de savoir ce que coûte un changement d’état dans une séquence de rendu donnée, sur un ensemble particulier de matériel ; et c’est pour le mesurer.
En plus des optimisations des changements d’état, le runtime tente d’optimiser le nombre d’appels de dessin que le pilote doit traiter. Par exemple, considérez ces appels de dessin dos à dos :
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
Exemple 5a : deux appels de dessin
Cette séquence contient deux appels de dessin, que le runtime consolidera en un seul appel équivalent à :
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
Exemple 5b : Un seul appel de dessin concaténé
Le runtime concatène ces deux appels de dessin particuliers en un seul appel, ce qui réduit le travail du pilote de 50 %, car le pilote n’a plus besoin de traiter qu’un seul appel de dessin.
En général, le runtime concatène deux ou plusieurs appels DrawPrimitive dos à dos dans les cas suivants :
De même, les conditions appropriées pour concaténer au moins deux appels DrawIndexedPrimitive dos à dos sont les suivantes :
Pour empêcher la concaténation pendant le profilage, modifiez la séquence de rendu afin que le type primitif ne soit pas une liste de triangles, ou modifiez la séquence de rendu afin qu’il n’y ait pas d’appels de dessin dos à dos qui utilisent des sommets (ou des index) consécutifs. Plus précisément, le runtime concatène également les appels de dessin qui répondent aux deux conditions suivantes :
Voici un exemple plus subtil de concaténation d’appel de dessin qui est facile à négliger lorsque vous effectuez le profilage. Supposons que la séquence de rendu ressemble à ceci :
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Exemple 5c : Un changement d’état et un appel de dessin
La boucle itère au sein de 1 500 triangles, en définissant une texture et en dessinant chaque triangle. Cette boucle de rendu prend environ 2750 cycles pour SetTexture et 1 100 cycles pour DrawPrimitive , comme indiqué dans les sections précédentes. Vous pouvez intuitivement vous attendre à ce que le déplacement de SetTexture en dehors de la boucle de rendu réduise la quantité de travail effectuée par le pilote de 1500 * 2750 cycles, soit la quantité de travail associée à l’appel de SetTexture 1500 fois. L’extrait de code se présente comme suit :
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Exemple 5d : Exemple 5c avec le changement d’état en dehors de la boucle
Le déplacement de SetTexture en dehors de la boucle de rendu réduit la quantité de travail associée à SetTexture , car il est appelé une fois au lieu de 1500 fois. Un effet secondaire moins évident est que le travail de DrawPrimitive est également réduit de 1500 appels à 1 appel, car toutes les conditions de concaténation des appels de dessin sont remplies. Lorsque la séquence de rendu est traitée, le runtime traite 1 500 appels en un seul appel de pilote. En déplaçant cette seule ligne de code, la quantité de travail du conducteur a été considérablement réduite :
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
Ces résultats sont tout à fait corrects, mais sont très trompeurs dans le contexte de la question initiale. L’optimisation des appels de tirage a considérablement réduit la quantité de travail du pilote. Il s’agit d’un problème courant lors du profilage personnalisé. Lors de l’élimination des appels d’une séquence de rendu, veillez à éviter la concaténation d’appel de dessin. En fait, ce scénario est un exemple puissant de la quantité d’amélioration des performances des pilotes possible par cette optimisation du runtime.
Vous savez maintenant comment mesurer les changements d’état. Commencez par profiler DrawPrimitive. Ajoutez ensuite chaque changement d’état supplémentaire à la séquence (dans certains cas en ajoutant un appel et dans d’autres cas en ajoutant deux appels) et mesurez la différence entre les deux séquences. Vous pouvez convertir les résultats en cycles, cycles ou temps. Tout comme la mesure des séquences de rendu avec QueryPerformanceCounter, la mesure des changements d’état individuels s’appuie sur le mécanisme de requête pour contrôler la mémoire tampon de commandes et place les modifications d’état dans une boucle pour réduire l’impact des transitions de mode. Cette technique mesure le coût du basculement d’un état, car le profileur retourne la moyenne de l’activation et de la désactivation de l’état.
Avec cette fonctionnalité, vous pouvez commencer à générer des séquences de rendu arbitraires et à mesurer avec précision le travail du runtime et du pilote associés. Les nombres peuvent ensuite être utilisés pour répondre à des questions de budgétisation telles que « combien de ces appels supplémentaires » peuvent être effectués dans la séquence de rendu tout en conservant une fréquence d’images raisonnable, en supposant des scénarios limités au processeur.
Ce document montre comment contrôler la mémoire tampon de commandes afin que les appels individuels puissent être profilés avec précision. Les numéros de profilage peuvent être générés en cycles, cycles ou temps absolu. Ils représentent la quantité de travail du runtime et du pilote associée à chaque appel d’API.
Commencez par profiler un appel Draw*Primitive dans une séquence de rendu. Veillez à effectuer les opérations suivantes :
Cela vous donne des performances de base pour DrawPrimitive qui peuvent être utilisées pour générer. Pour profiler un changement d’état, suivez ces conseils supplémentaires :
Mais faites attention aux optimisations qui provoquent des résultats inattendus lors du profilage. Les optimisations de changement d’état peuvent définir sale états qui entraînent le report du travail. Cela peut entraîner des résultats de profil qui ne sont pas aussi intuitifs que prévu. Dessiner des appels concaténés réduira considérablement le travail des conducteurs, ce qui peut conduire à des conclusions trompeuses. Des séquences de rendu soigneusement planifiées sont utilisées pour empêcher les changements d’état et dessiner des concaténations d’appels. L’astuce consiste à empêcher les optimisations de se produire pendant le profilage afin que les nombres que vous générez soient des nombres de budget raisonnables.
Notes
Il est plus difficile de dupliquer cette stratégie de profilage dans une application sans le mécanisme de requête. Avant Direct3D 9, la seule façon prévisible de vider la mémoire tampon de commandes consiste à verrouiller une surface active (telle qu’une cible de rendu) pour attendre que le GPU soit inactif. En effet, le verrouillage d’une surface force le runtime à vider la mémoire tampon de commandes au cas où des commandes de rendu dans la mémoire tampon devraient mettre à jour la surface avant qu’elle ne soit verrouillée, en plus d’attendre la fin du GPU. Cette technique est fonctionnelle, bien qu’elle soit plus gênante que l’utilisation du mécanisme de requête introduit dans Direct3D 9.
Les nombres de cette table sont une plage d’approximations pour la quantité de travail du runtime et du pilote associée à chacune de ces modifications d’état. Les approximations sont basées sur des mesures réelles effectuées sur les pilotes à l’aide des techniques présentées dans le document. Ces nombres ont été générés à l’aide du runtime Direct3D 9 et dépendent du pilote.
Les techniques décrites dans ce document sont conçues pour mesurer le travail du runtime et du pilote. En général, il est peu pratique de fournir des résultats qui correspondent aux performances du processeur et du GPU dans chaque application, car cela nécessiterait un tableau exhaustif de séquences de rendu. En outre, il est particulièrement difficile d’évaluer les performances du GPU, car il dépend fortement de la configuration de l’état dans le pipeline avant la séquence de rendu. Par instance, l’activation de la fusion alpha n’affecte pas la quantité de travail nécessaire au processeur, mais peut avoir un impact important sur la quantité de travail effectuée par le GPU. Par conséquent, les techniques décrites dans ce document limitent le travail gpu à la quantité minimale possible en limitant la quantité de données qui doit être rendue. Cela signifie que les nombres de la table correspondent le plus étroitement aux résultats obtenus à partir d’applications dont le processeur est limité (par opposition à une application limitée par le GPU).
Nous vous encourageons à utiliser les techniques présentées pour couvrir les scénarios et les configurations les plus importants pour vous. Les valeurs de la table peuvent être utilisées pour comparer les nombres que vous générez. Étant donné que chaque pilote varie, la seule façon de générer les nombres réels que vous verrez consiste à générer des résultats de profilage à l’aide de vos scénarios.
| Appel d’API | Nombre moyen de cycles |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| SPECULARENABLE | 1900 - 11200 |
| SetRenderTarget | 6000 - 6250 |
| SetPixelShaderConstant (1 constante) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| ÉCLAIRAGE | 1700 - 7500 |
| DIFFUSEMATERIALSOURCE | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| SetLight | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| SetIndices | 900 - 5600 |
| AMBIANTE | 1150 - 4800 |
| SetTexture | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVEMATERIALSOURCE | 900 - 4500 |
| SetMaterial | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| FILTRE MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 constante) | 1000 - 2700 |
| COLOROP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| ÉCRÊTAGE | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| ADDRESSU | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| STENCILMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| STENCILFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| STENCILFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| STENCILPASS | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Two_Sided_StencilMODE | 450 - 590 |
| ALPHATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| COLORWRITEENABLE | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
Entrainement
Parcours d’apprentissage
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization