A TDSP egy agilis és iteratív adatelemzési módszertan, amellyel hatékonyan végezhet prediktív elemzési megoldásokat és AI-alkalmazásokat. A TDSP javítja a csapatmunkát és a tanulást azáltal, hogy optimális módszereket javasol a csapatszerepkörök együttműködéséhez. A TDSP a Microsoft és más iparági vezetők ajánlott eljárásait és keretrendszereit tartalmazza, amelyek segítenek a csapatnak hatékonyan megvalósítani az adatelemzési kezdeményezéseket. A TDSP lehetővé teszi az elemzési program előnyeinek teljes körű kihasználását.
Ez a cikk áttekintést nyújt a TDSP-ről és fő összetevőiről. Útmutatást nyújt a TDSP Microsoft-eszközök és -infrastruktúra használatával történő implementálásához. A cikkben részletesebb forrásanyagokat talál.
A TDSP fő összetevői
A TDSP a következő fő összetevőkkel rendelkezik:
- Adatelemzési életciklus-definíció
- Szabványosított projektstruktúra
- Adatelemzési projektekhez ideális infrastruktúra és erőforrások
- Felelős AI: és az AI fejlődése iránti elkötelezettség, etikai alapelvek vezérelve
Adatelemzési életciklus
A TDSP egy életciklust biztosít, amellyel strukturálhatja az adatelemzési projektek fejlesztését. Az életciklus a sikeres projektek által követett teljes lépéseket ismerteti.
A feladatalapú TDSP-t kombinálhatja más adatelemzési életciklusokkal, például az adatbányászat iparágközi szabványos folyamatával (CRISP-DM), az adatbázisokban való tudásfelderítéssel (KDD) vagy egy másik egyéni folyamattal. Magas szinten ezek a különböző módszerek sok közös.
Ezt az életciklust akkor használja, ha egy intelligens alkalmazás részét képező adatelemzési projektje van. Az intelligens alkalmazások gépi tanulási vagy AI-modelleket helyeznek üzembe a prediktív elemzéshez. Ezt a folyamatot feltáró adatelemzési projektekhez és improvizált elemzési projektekhez is használhatja.
A TDSP életciklusa öt fő szakaszból áll, amelyeket a csapat iteratív módon hajt végre. Ezek a szakaszok a következők:
Íme a TDSP életciklusának vizuális ábrázolása:
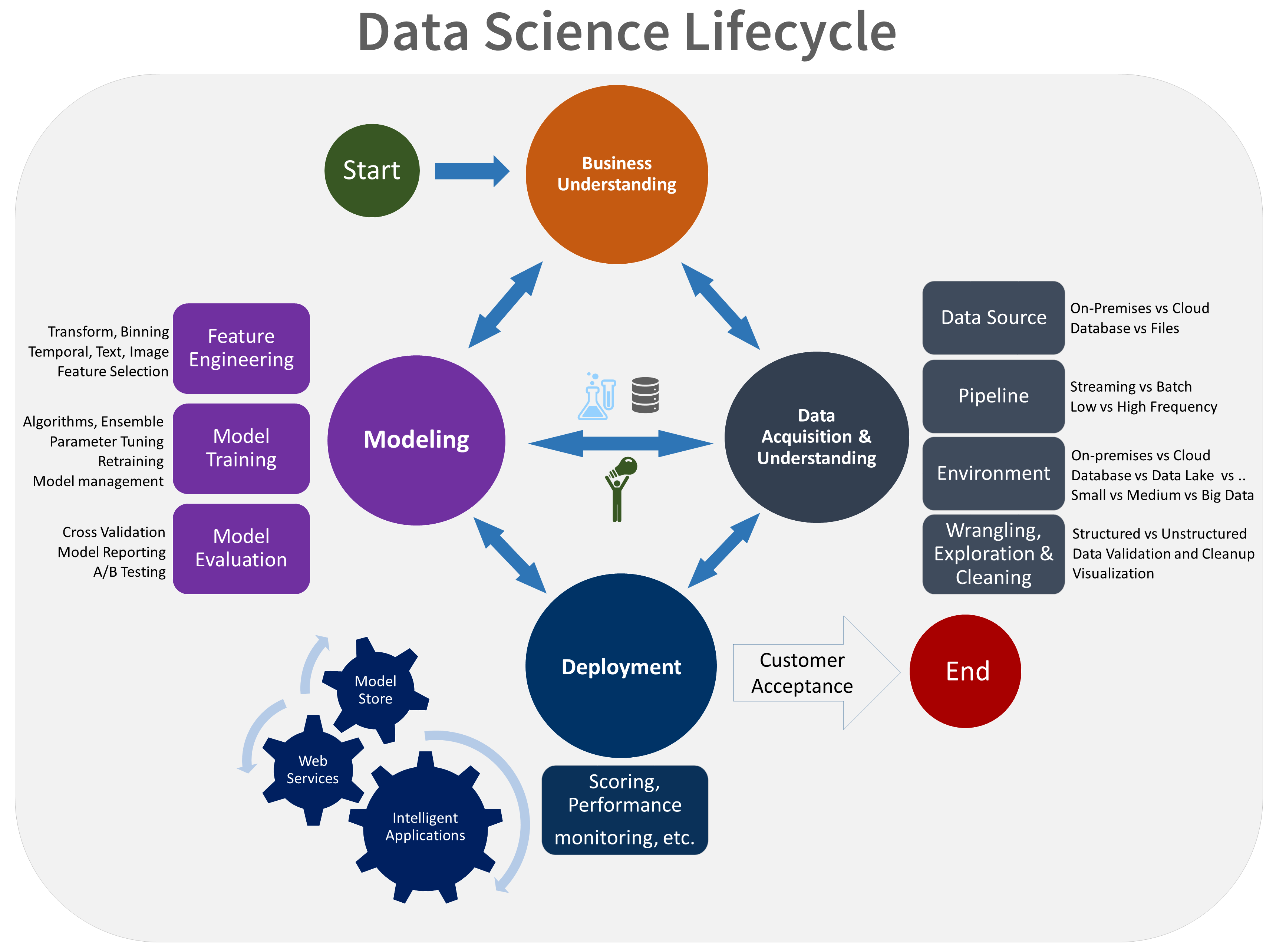
Az egyes szakaszok céljairól, feladatairól és dokumentációs összetevőiről további információt a TDSP életciklusában talál.
Ezek a tevékenységek és összetevők a projektszerepkörökhöz igazodnak, például:
- Megoldástervező
- Projektvezető
- Adatszakértő
- Adattudós
- Alkalmazásfejlesztő
- Projektvezető
Az alábbi ábrán a vízszintes tengelyen és a függőleges tengelyen ábrázolt szerepkörökhöz tartozó tevékenységek (kék színnel) és az életciklus egyes szakaszainak megfelelő összetevők (zöld színnel) láthatók.

Szabványosított projektstruktúra
Csapata az Azure-infrastruktúrával rendszerezheti adatelemzési eszközeit.
Az Azure Machine Learning támogatja a nyílt forráskódú MLflow-t. Javasoljuk, hogy az MLflow-t használja az adatelemzéshez és az AI-projektek kezeléséhez. Az MLflow a teljes gépi tanulási életciklus kezelésére lett tervezve. Különböző platformokon képez ki és szolgál ki modelleket, így konzisztens eszközkészletet használhat, függetlenül attól, hogy hol futnak a kísérletek. Az MLflow helyileg használható a számítógépen, távoli számítási célon, virtuális gépen vagy gépi tanulási számítási példányon.
Az MLflow számos fő funkcióból áll:
Kísérletek nyomon követése: Az MLflow használatával nyomon követheti a kísérleteket, beleértve a paramétereket, a kódverziókat, a metrikákat és a kimeneti fájlokat. Ez a funkció segít a különböző futtatások összehasonlításában és a kísérletezési folyamat hatékony kezelésében.
Csomagkód: Szabványos formátumot biztosít a gépi tanulási kód csomagolásához, amely függőségeket és konfigurációkat is tartalmaz. Ezzel a csomagolással egyszerűbbé válik a futtatások reprodukálása és a kód megosztása másokkal.
Modellek kezelése: Az MLflow funkciókkal kezeli és verziószámozza a modelleket. Támogatja a különböző gépi tanulási keretrendszereket, így modelleket tárolhat, futtathat és kiszolgálhat.
Modellek kiszolgálása és üzembe helyezése: Az MLflow integrálja a modellek kiszolgálási és üzembe helyezési képességeit, hogy a modelleket egyszerűen üzembe helyezhesse különböző környezetekben.
Modellek regisztrálása: Kezelheti egy modell életciklusát, amely magában foglalja a verziószámozást, a fázisáttűnéseket és a széljegyzeteket. Az MLflow használatával egy központosított modelltárolót tarthat fenn együttműködésen alapuló környezetben.
API és felhasználói felület használata: Az Azure-ban az MLflow a Machine Learning API 2-es verziójában van csomagolva, így programozott módon kezelheti a rendszert. Az Azure Portal használatával kezelheti a felhasználói felületeket.
Az MLflow leegyszerűsíti és egységesíti a gépi tanulás fejlesztését a kísérletezéstől az üzembe helyezésig.
A Machine Learning integrálható a Git-adattárakkal, így Git-kompatibilis szolgáltatásokat használhat, például a GitHubot, a GitLabet, a Bitbucketet, az Azure DevOpsot vagy egy másik Git-kompatibilis szolgáltatást. A Machine Learningben már nyomon követett eszközök mellett a csapata saját osztályozást is fejleszthet a Git-kompatibilis szolgáltatásban más projektadatok tárolására, például:
- Dokumentáció
- Projektadatok: például a végső projektjelentés
- Adatjelentés: például az adatszótár vagy az adatminőségi jelentések
- Modell: például modelljelentések
- Kód
- Adatok előkészítése
- Modellfejlesztés
- Üzemeltetés, amely magában foglalja a biztonságot és a megfelelőséget
Infrastruktúra és erőforrások
A TDSP javaslatokat nyújt a megosztott elemzési és tárolási infrastruktúra kezelésére a következő kategóriákban:
- Adathalmazok tárolására használható felhőalapú fájlrendszerek
- Felhőbeli adatbázisok
- SQL-t vagy Sparkot használó big data-fürtök
- AI- és gépi tanulási szolgáltatások
Adathalmazok tárolására használható felhőalapú fájlrendszerek
A felhőalapú fájlrendszerek számos okból kulcsfontosságúak a TDSP számára:
Központosított adattárolás: A felhőalapú fájlrendszerek központi helyet biztosítanak az adathalmazok tárolásához, ami elengedhetetlen az adatelemzési csapattagok közötti együttműködéshez. A központosítás biztosítja, hogy a csapat minden tagja hozzáférhessen a legfrissebb adatokhoz, és csökkentse az elavult vagy inkonzisztens adathalmazok használatának kockázatát.
Méretezhetőség: A felhőalapú fájlrendszerek nagy mennyiségű adatot képesek kezelni, ami az adatelemzési projektekben gyakori. A fájlrendszerek skálázható tárolási megoldásokat biztosítanak, amelyek a projekt igényeinek megfelelően növekednek. Lehetővé teszik a csapatok számára a nagy méretű adathalmazok tárolását és feldolgozását anélkül, hogy a hardverkorlátozások miatt kellene aggódniuk.
Akadálymentesség: A felhőbeli fájlrendszerek segítségével bárhonnan elérheti az adatokat internetkapcsolattal. Ez a hozzáférés fontos az elosztott csapatok számára, vagy ha a csapattagoknak távolról kell dolgozniuk. A felhőalapú fájlrendszerek megkönnyítik a zökkenőmentes együttműködést, és gondoskodnak arról, hogy az adatok mindig elérhetők legyenek.
Biztonság és megfelelőség: A felhőszolgáltatók gyakran alkalmaznak robusztus biztonsági intézkedéseket, amelyek közé tartozik a titkosítás, a hozzáférés-vezérlés, valamint az iparági szabványoknak és előírásoknak való megfelelés. Az erős biztonsági intézkedések védhetik a bizalmas adatokat, és segíthetnek a csapatnak megfelelni a jogi és szabályozási követelményeknek.
Verziókövetés: A felhőalapú fájlrendszerek gyakran tartalmaznak verziókövetési funkciókat, amelyekkel a csapatok nyomon követhetik az adathalmazok időbeli változásait. A verziókövetés elengedhetetlen az adatok integritásának fenntartásához és az eredmények adatelemzési projektekben való reprodukálásához. Emellett segít a felmerülő problémák naplózásában és hibaelhárításában is.
Integráció eszközökkel: A felhőalapú fájlrendszerek zökkenőmentesen integrálhatók különböző adatelemzési eszközökkel és platformokkal. Az eszközintegráció támogatja a könnyebb adatbetöltést, adatfeldolgozást és adatelemzést. Az Azure Storage például jól integrálható a Machine Learning, az Azure Databricks és más adatelemzési eszközökkel.
Együttműködés és megosztás: A felhőalapú fájlrendszerek megkönnyítik az adathalmazok más csapattagokkal vagy érdekelt felekkel való megosztását. Ezek a rendszerek olyan együttműködési funkciókat támogatnak, mint a megosztott mappák és az engedélyek kezelése. Az együttműködési funkciók megkönnyítik a csapatmunkát, és biztosítják, hogy a megfelelő személyek hozzáférjenek a szükséges adatokhoz.
Költséghatékonyság: A felhőalapú fájlrendszerek költséghatékonyabbak lehetnek, mint a helyszíni tárolási megoldások fenntartása. A felhőszolgáltatók rugalmas díjszabási modellekkel rendelkeznek, amelyek használatalapú fizetéses lehetőségeket tartalmaznak, amelyek segítenek a költségek kezelésében az adatelemzési projekt tényleges használati és tárolási követelményei alapján.
Vészhelyreállítás: A felhőalapú fájlrendszerek általában tartalmazzák az adatmentés és a vészhelyreállítás funkcióit. Ezek a funkciók segítenek megvédeni az adatokat a hardverhibáktól, a véletlen törléstől és más katasztrófáktól. Nyugalmat biztosít, és támogatja az adatelemzési műveletek folytonosságát.
Automatizálás és munkafolyamat-integráció: A felhőalapú tárolórendszerek integrálhatók automatizált munkafolyamatokba, amelyek zökkenőmentes adatátvitelt tesznek lehetővé az adatelemzési folyamat különböző szakaszai között. Az automatizálás segíthet a hatékonyság növelésében és az adatok kezeléséhez szükséges manuális erőfeszítések csökkentésében.
Ajánlott Azure-erőforrások felhőbeli fájlrendszerekhez
- Azure Blob Storage – Az Azure Blob Storage átfogó dokumentációja, amely strukturálatlan adatok skálázható objektumtárolási szolgáltatása.
- Azure Data Lake Storage – Információk az Azure Data Lake Storage Gen2-ről, amely big data elemzésre lett tervezve, és támogatja a nagy méretű adathalmazokat.
- Azure Files – Részletek az Azure Filesról, amely teljes mértékben felügyelt fájlmegosztásokat biztosít a felhőben.
Összefoglalva, a felhőalapú fájlrendszerek kulcsfontosságúak a TDSP szempontjából, mivel skálázható, biztonságos és akadálymentes tárolási megoldásokat biztosítanak, amelyek támogatják a teljes adatéletciklust. A felhőalapú fájlrendszerek zökkenőmentes adatintegrációt tesznek lehetővé különböző forrásokból, ami támogatja az átfogó adatgyűjtést és -megértést. Az adattudósok felhőalapú fájlrendszerekkel hatékonyan tárolhatják, kezelhetik és érhetik el a nagy adathalmazokat. Ez a funkció elengedhetetlen a gépi tanulási modellek betanításához és üzembe helyezéséhez. Ezek a rendszerek az együttműködést is növelik azáltal, hogy lehetővé teszik a csapattagok számára az adatok egységes környezetben való megosztását és egyidejű használatát. A felhőalapú fájlrendszerek robusztus biztonsági funkciókat biztosítanak, amelyek segítenek az adatok védelmében és a jogszabályi követelményeknek való megfelelésben, ami elengedhetetlen az adatintegritás és a megbízhatóság fenntartásához.
Felhőbeli adatbázisok
A felhőalapú adatbázisok több okból is kritikus szerepet játszanak a TDSP-ben:
Méretezhetőség: A felhőalapú adatbázisok méretezhető megoldásokat biztosítanak, amelyek egyszerűen növekedhetnek a projekt növekvő adatigényének megfelelően. A méretezhetőség kulcsfontosságú a nagy és bonyolult adathalmazokat gyakran kezelő adatelemzési projektek esetében. A felhőadatbázisok manuális beavatkozás vagy hardverfrissítés nélkül kezelhetik a különböző számítási feladatokat.
Teljesítményoptimalizálás: A fejlesztők a felhőadatbázisokat teljesítményre optimalizálják olyan képességek használatával, mint az automatikus indexelés, a lekérdezésoptimalizálás és a terheléselosztás. Ezek a funkciók biztosítják, hogy az adatok lekérése és feldolgozása gyors és hatékony legyen, ami elengedhetetlen a valós idejű vagy közel valós idejű adathozzáférést igénylő adatelemzési feladatokhoz.
Akadálymentesség és együttműködés: A Teams bármilyen helyről hozzáférhet a felhőalapú adatbázisokban tárolt adatokhoz. Ez az akadálymentesség elősegíti a földrajzilag szétszórt csapattagok közötti együttműködést. Az akadálymentesség és az együttműködés fontos az elosztott csapatok vagy a távolról dolgozó személyek számára. A felhőalapú adatbázisok támogatják az egyidejű hozzáférést és együttműködést lehetővé tevő többfelhasználós környezeteket.
Integráció adatelemzési eszközökkel: A felhőalapú adatbázisok zökkenőmentesen integrálhatók különböző adatelemzési eszközökkel és platformokkal. Az Azure-felhőadatbázisok például jól integrálhatók a Machine Learning, a Power BI és más adatelemzési eszközökkel. Ez az integráció leegyszerűsíti az adatfolyamatot a betöltéstől a tároláson át az elemzésig és a vizualizációig.
Biztonság és megfelelőség: A felhőszolgáltatók robusztus biztonsági intézkedéseket vezetnek be, amelyek magukban foglalják az adattitkosítást, a hozzáférés-vezérlést, valamint az iparági szabványoknak és előírásoknak való megfelelést. A biztonsági intézkedések védik a bizalmas adatokat, és segítenek a csapatnak megfelelni a jogi és szabályozási követelményeknek. A biztonsági funkciók létfontosságúak az adatintegritás és az adatvédelem fenntartásához.
Költséghatékonyság: A felhőalapú adatbázisok gyakran használatalapú fizetéses modellen működnek, ami költséghatékonyabb lehet, mint a helyszíni adatbázisrendszerek fenntartása. Ez a díjszabási rugalmasság lehetővé teszi a szervezetek számára, hogy hatékonyan kezeljék költségvetésüket, és csak az általuk használt tárolási és számítási erőforrásokért fizessenek.
Automatikus biztonsági mentések és vészhelyreállítás: A felhőalapú adatbázisok automatikus biztonsági mentési és vészhelyreállítási megoldásokat biztosítanak. Ezek a megoldások segítenek megelőzni az adatvesztést hardverhibák, véletlen törlések vagy egyéb katasztrófák esetén. A megbízhatóság kulcsfontosságú az adatelemzési projektek adat-folytonosságának és integritásának fenntartásához.
Valós idejű adatfeldolgozás: Számos felhőalapú adatbázis támogatja a valós idejű adatfeldolgozást és -elemzést, ami elengedhetetlen a legfrissebb információkat igénylő adatelemzési feladatokhoz. Ez a funkció segít az adattudósok számára, hogy a legfrissebb elérhető adatok alapján időben döntéseket hozzanak.
Adatintegráció: A felhőalapú adatbázisok könnyen integrálhatók más adatforrásokkal, adatbázisokkal, adattókkal és külső adatcsatornákkal. Az integráció segítségével az adattudósok több forrásból származó adatokat kombinálnak, és átfogó képet és kifinomultabb elemzést biztosítanak.
Rugalmasság és változatosság: A felhőbeli adatbázisok különböző formában, például relációs adatbázisokban, NoSQL-adatbázisokban és adattárházakban érhetők el. Ez a változatosság lehetővé teszi, hogy az adatelemzési csapatok az adott igényeiknek leginkább megfelelő adatbázistípust válasszák, legyen szó strukturált adattárolásról, strukturálatlan adatkezelésről vagy nagy léptékű adatelemzésről.
Speciális elemzések támogatása: A felhőalapú adatbázisok gyakran beépített támogatást nyújtanak a fejlett elemzésekhez és a gépi tanuláshoz. Az Azure SQL Database például beépített gépi tanulási szolgáltatásokat biztosít. Ezek a szolgáltatások segítenek az adattudósoknak a speciális elemzések elvégzésében közvetlenül az adatbázis-környezetben.
Ajánlott Azure-erőforrások felhőalapú adatbázisokhoz
- Azure SQL Database – Dokumentáció az Azure SQL Database-ről, egy teljes mértékben felügyelt relációsadatbázis-szolgáltatásról.
- Azure Cosmos DB – Információk az Azure Cosmos DB-ről, amely egy globálisan elosztott, többmodelles adatbázis-szolgáltatás.
- Azure Database for PostgreSQL – Útmutató az Azure Database for PostgreSQL-hez, amely egy felügyelt adatbázis-szolgáltatás alkalmazásfejlesztéshez és üzembe helyezéshez.
- Azure Database for MySQL – Részletek az Azure Database for MySQL-ről, a MySQL-adatbázisok felügyelt szolgáltatásáról.
Összefoglalva, a felhőalapú adatbázisok kulcsfontosságúak a TDSP szempontjából, mivel skálázható, megbízható és hatékony adattárolási és felügyeleti megoldásokat biztosítanak, amelyek támogatják az adatvezérelt projekteket. Megkönnyítik a zökkenőmentes adatintegrációt, ami segít az adattudósoknak a különböző forrásokból származó nagy adathalmazok betöltésében, előfeldolgozásában és elemzésében. A felhőalapú adatbázisok gyors lekérdezést és adatfeldolgozást tesznek lehetővé, ami elengedhetetlen a gépi tanulási modellek fejlesztéséhez, teszteléséhez és üzembe helyezéséhez. A felhőalapú adatbázisok az együttműködést úgy is javítják, hogy központosított platformot biztosítanak a csapattagok számára az adatok egyidejű eléréséhez és kezeléséhez. Végül a felhőadatbázisok fejlett biztonsági funkciókat és megfelelőségi támogatást biztosítanak az adatok védelmének és a jogszabályi előírásoknak való megfeleléshez, ami elengedhetetlen az adatintegritás és a megbízhatóság fenntartásához.
SQL-t vagy Sparkot használó big data-fürtök
A big data-fürtök, például az SQL-t vagy a Sparkot használó fürtök több okból is alapvető fontosságúak a TDSP szempontjából:
Nagy mennyiségű adat kezelése: A big data fürtök nagy mennyiségű adat hatékony kezelésére lettek kialakítva. Az adatelemzési projektek gyakran olyan nagy adathalmazokat foglalnak magukban, amelyek túllépik a hagyományos adatbázisok kapacitását. Az SQL-alapú big data-fürtök és a Spark nagy méretekben kezelheti és feldolgozhatja ezeket az adatokat.
Elosztott számítástechnika: A big data-fürtök elosztott számítástechnikát használnak az adatok és számítási feladatok több csomóponton való elosztásához. A párhuzamos feldolgozási képesség jelentősen felgyorsítja az adatfeldolgozási és elemzési feladatokat, ami elengedhetetlen az adatelemzési projektek időben történő elemzéséhez.
Méretezhetőség: A big data-fürtök horizontálisan is magas méretezhetőséget biztosítanak több csomópont hozzáadásával és függőlegesen a meglévő csomópontok teljesítményének növelésével. A méretezhetőség lehetővé teszi, hogy az adatinfrastruktúra a projekt igényeihez igazodva növekedjön az adatméretek és az összetettség növelésével.
Integráció adatelemzési eszközökkel: A big data fürtök jól integrálhatók a különböző adatelemzési eszközökkel és platformokkal. A Spark például zökkenőmentesen integrálható a Hadooptal, és az SQL-fürtök különböző adatelemzési eszközökkel működnek együtt. Az integráció zökkenőmentes munkafolyamatot tesz lehetővé az adatbetöltéstől az elemzésig és a vizualizációig.
Speciális elemzés: A Big data-fürtök támogatják a fejlett elemzéseket és a gépi tanulást. A Spark például a következő beépített kódtárakat biztosítja:
- Gépi tanulás, MLlib
- Gráffeldolgozás, GraphX
- Streamfeldolgozás, Spark Streaming
Ezek a képességek segítenek az adattudósoknak összetett elemzéseket végezni közvetlenül a fürtön belül.
Valós idejű adatfeldolgozás: A Big data-fürtök, különösen a Sparkot használó fürtök támogatják a valós idejű adatfeldolgozást. Ez a képesség kulcsfontosságú az olyan projektek esetében, amelyekhez naprakész adatelemzésre és döntéshozatalra van szükség. A valós idejű feldolgozás olyan helyzetekben segít, mint a csalások észlelése, a valós idejű javaslatok és a dinamikus díjszabás.
Adatátalakítás és kinyerés, átalakítás, betöltés (ETL): A big data fürtök ideálisak adatátalakításhoz és ETL-folyamatokhoz. Hatékonyan kezelhetik az összetett adatátalakításokat, tisztítási és összesítési feladatokat, amelyek gyakran szükségesek az adatok elemzése előtt.
Költséghatékonyság: A big data-fürtök költséghatékonyak lehetnek, különösen akkor, ha olyan felhőalapú megoldásokat használ, mint az Azure Databricks és más felhőszolgáltatások. Ezek a szolgáltatások rugalmas díjszabási modelleket biztosítanak, amelyek használatalapú fizetést is tartalmaznak, ami gazdaságosabb lehet, mint a helyszíni big data-infrastruktúra fenntartása.
Hibatűrés: A Big Data-fürtök hibatűrést szem előtt tartva lettek kialakítva. A csomópontok között replikálják az adatokat, így biztosítják, hogy a rendszer működőképes maradjon, még akkor is, ha egyes csomópontok meghibásodnak. Ez a megbízhatóság kritikus fontosságú az adatintegritás és a rendelkezésre állás fenntartásához adatelemzési projektekben.
Data lake-integráció: A Big Data-fürtök gyakran zökkenőmentesen integrálhatók a data lake-ekkel, így az adattudósok egységes módon férhetnek hozzá és elemezhetők a különböző adatforrások. Az integráció a strukturált és strukturálatlan adatok kombinációjának támogatásával segíti elő az átfogóbb elemzéseket.
SQL-alapú feldolgozás: Az SQL-t ismerő adattudósok számára az SQL-lekérdezéseket használó big data-fürtök, például a Spark SQL vagy a Hadoopon futó SQL, ismerős felületet biztosítanak a big data lekérdezéséhez és elemzéséhez. Ez a könnyű használat felgyorsíthatja az elemzési folyamatot, és elérhetővé teheti a felhasználók szélesebb köre számára.
Együttműködés és megosztás: A big data-fürtök olyan együttműködési környezeteket támogatnak, ahol több adatelemző és elemző is dolgozhat ugyanazon az adathalmazon. Olyan funkciókat biztosítanak, amelyekkel megosztható a kód, a jegyzetfüzetek és az eredmények, amelyek elősegítik a csapatmunkát és a tudásmegosztást.
Biztonság és megfelelőség: A big data fürtök robusztus biztonsági funkciókat biztosítanak, például adattitkosítást, hozzáférés-vezérlést és az iparági szabványoknak való megfelelést. A biztonsági funkciók védik a bizalmas adatokat, és segítenek a csapatnak megfelelni a jogszabályi követelményeknek.
Ajánlott Azure-erőforrások big data-fürtökhöz
- Apache Spark a Machine Learningben: Az Azure Synapse Analytics machine learning-integrációja egyszerű hozzáférést biztosít az elosztott számítási erőforrásokhoz az Apache Spark-keretrendszeren keresztül.
- Synapse Analytics: A Synapse Analytics átfogó dokumentációja, amely integrálja a big data-t és az adatraktározást.
Összefoglalva, a big data fürtök, akár az SQL, akár a Spark kulcsfontosságúak a TDSP számára, mivel a nagy mennyiségű adat hatékony kezeléséhez szükséges számítási teljesítményt és méretezhetőséget biztosítják. A big data-fürtök lehetővé teszik az adattudósok számára, hogy összetett lekérdezéseket és fejlett elemzéseket végezzenek nagy adathalmazokon, amelyek megkönnyítik a mély elemzéseket és a pontos modellfejlesztést. Elosztott számítástechnika használata esetén ezek a fürtök gyors adatfeldolgozást és elemzést tesznek lehetővé, ami felgyorsítja az általános adatelemzési munkafolyamatot. A big data-fürtök emellett támogatják a különböző adatforrásokkal és eszközökkel való zökkenőmentes integrációt is, ami javítja a több környezetből származó adatok betöltésének, feldolgozásának és elemzésének képességét. A big data-fürtök az együttműködést és a reprodukálhatóságot is elősegítik egy egységes platform biztosításával, ahol a csapatok hatékonyan oszthatnak meg erőforrásokat, munkafolyamatokat és eredményeket.
AI- és gépi tanulási szolgáltatások
Az AI- és gépi tanulási (ML) szolgáltatások több okból is nélkülözhetetlenek a TDSP-hez:
Speciális elemzés: Az AI- és ML-szolgáltatások speciális elemzést tesznek lehetővé. Az adattudósok speciális elemzésekkel összetett mintákat fedhetnek fel, előrejelzéseket készíthetnek, és olyan elemzéseket hozhatnak létre, amelyek nem lehetségesek a hagyományos elemzési módszerekkel. Ezek a fejlett képességek kulcsfontosságúak a nagy hatású adatelemzési megoldások létrehozásához.
Ismétlődő feladatok automatizálása: Az AI- és ML-szolgáltatások automatizálhatják az ismétlődő feladatokat, például az adattisztítást, a funkciófejlesztést és a modell betanítását. Az Automatizálás időt takarít meg, és segít az adattudósoknak a projekt stratégiai szempontjaira összpontosítani, ami javítja az általános termelékenységet.
Jobb pontosság és teljesítmény: Az ML-modellek az adatokból tanulva javíthatják az előrejelzések és elemzések pontosságát és teljesítményét. Ezek a modellek folyamatosan fejlődhetnek, mivel egyre több adatnak lesznek kitéve, ami jobb döntéshozatalhoz és megbízhatóbb eredményekhez vezet.
Méretezhetőség: A felhőplatformok, például a Machine Learning által nyújtott AI- és ML-szolgáltatások nagy mértékben méretezhetők. Nagy mennyiségű adatot és összetett számítást képesek kezelni, amelyek segítségével az adatelemzési csapatok úgy méretezhetik megoldásaikat, hogy megfeleljenek a növekvő igényeknek anélkül, hogy a mögöttes infrastruktúra korlátai miatt kellene aggódniuk.
Integráció más eszközökkel: Az AI- és ML-szolgáltatások zökkenőmentesen integrálhatók a Microsoft ökoszisztémájának más eszközeivel és szolgáltatásaival, például az Azure Data Lake-zel, az Azure Databrickskel és a Power BI-val. Az integráció leegyszerűsített munkafolyamatot támogat az adatbetöltéstől és feldolgozástól a modell üzembe helyezéséig és vizualizációig.
Modell üzembe helyezése és felügyelete: Az AI- és ML-szolgáltatások robusztus eszközöket biztosítanak a gépi tanulási modellek éles környezetben való üzembe helyezéséhez és kezeléséhez. Az olyan funkciók, mint a verziókövetés, a monitorozás és az automatikus újratanítás segítenek biztosítani, hogy a modellek pontosak és hatékonyak maradjanak az idő múlásával. Ez a megközelítés leegyszerűsíti az ML-megoldások karbantartását.
Valós idejű feldolgozás: Az AI és az ML-szolgáltatások támogatják a valós idejű adatfeldolgozást és döntéshozatalt. A valós idejű feldolgozás elengedhetetlen az olyan alkalmazásokhoz, amelyek azonnali elemzéseket és műveleteket igényelnek, mint például a csalások észlelése, a dinamikus díjszabás és a javaslati rendszerek.
Testreszabhatóság és rugalmasság: Az AI- és ML-szolgáltatások számos testre szabható lehetőséget kínálnak, az előre összeállított modellektől és API-któl kezdve az egyéni modellek alapoktól való létrehozásához szükséges keretrendszerekig. Ez a rugalmasság segít az adatelemzési csapatoknak a konkrét üzleti igényekhez és használati esetekhez igazítani a megoldásokat.
Élvonalbeli algoritmusokhoz való hozzáférés: A mesterséges intelligencia és az ML-szolgáltatások hozzáférést biztosítanak az adattudósoknak a vezető kutatók által kifejlesztett élvonalbeli algoritmusokhoz és technológiákhoz. Az Access biztosítja, hogy a csapat a mi-ben és az ML-ben a legújabb fejlesztési lehetőségeket használja a projektjeikhez.
Együttműködés és megosztás: Az AI- és ML-platformok támogatják az együttműködésen alapuló fejlesztési környezeteket, ahol több csapattag is együttműködhet ugyanazon a projekten, megoszthatja a kódot és reprodukálhatja a kísérleteket. Az együttműködés javítja a csapatmunkát, és biztosítja a modellfejlesztés konzisztenciáját.
Költséghatékonyság: A felhőbeli AI- és ML-szolgáltatások költséghatékonyabbak lehetnek, mint a helyszíni megoldások létrehozása és karbantartása. A felhőszolgáltatók rugalmas díjszabási modellekkel rendelkeznek, amelyek használatalapú fizetéses lehetőségeket tartalmaznak, amelyek csökkenthetik a költségeket és optimalizálhatják az erőforrás-használatot.
Fokozott biztonság és megfelelőség: Az AI- és ML-szolgáltatások robusztus biztonsági funkciókkal rendelkeznek, amelyek magukban foglalják az adattitkosítást, a biztonságos hozzáférés-vezérlést, valamint az iparági szabványoknak és előírásoknak való megfelelést. Ezek a funkciók segítenek az adatok és modellek védelmében, valamint a jogi és szabályozási követelményeknek való megfelelésben.
Előre elkészített modellek és API-k: Számos AI- és ML-szolgáltatás előre összeállított modelleket és API-kat biztosít olyan gyakori feladatokhoz, mint a természetes nyelvi feldolgozás, a képfelismerés és az anomáliadetektálás. Az előre összeállított megoldások felgyorsíthatják a fejlesztést és az üzembe helyezést, és segítenek a csapatoknak gyorsan integrálni az AI-képességeket az alkalmazásaikba.
Kísérletezés és prototípus-kezelés: Az AI- és ML-platformok környezeteket biztosítanak a gyors kísérletezéshez és prototípus-készítéshez. Az adattudósok gyorsan tesztelhetik a különböző algoritmusokat, paramétereket és adathalmazokat, hogy megtalálják a legjobb megoldást. A kísérletezés és a prototípus-fejlesztés támogatja a modellfejlesztés iteratív megközelítését.
Ajánlott Azure-erőforrások AI- és ML-szolgáltatásokhoz
A Machine Learning az adatelemzési alkalmazáshoz és a TDSP-hez ajánlott fő erőforrás. Az Azure emellett olyan AI-szolgáltatásokat is biztosít, amelyek kész AI-modellekkel rendelkeznek adott alkalmazásokhoz.
- Machine Learning: A Machine Learning fő dokumentációs oldala, amely a beállítással, a modell betanításával, az üzembe helyezéssel stb. foglalkozik.
- Azure AI-szolgáltatások: Információk olyan AI-szolgáltatásokról, amelyek előre összeállított AI-modelleket biztosítanak a látáshoz, beszédhez, nyelvhez és döntéshozatali feladatokhoz.
Összefoglalva, az AI- és ML-szolgáltatások kulcsfontosságúak a TDSP szempontjából, mivel hatékony eszközöket és keretrendszereket biztosítanak, amelyek leegyszerűsítik a gépi tanulási modellek fejlesztését, betanítását és üzembe helyezését. Ezek a szolgáltatások olyan összetett feladatokat automatizálnak, mint az algoritmusok kiválasztása és a hiperparaméterek finomhangolása, ami jelentősen felgyorsítja a modellfejlesztési folyamatot. Ezek a szolgáltatások skálázható infrastruktúrát is biztosítanak, amely segít az adattudósoknak a nagy adathalmazok hatékony kezelésében és a számításigényes feladatok kezelésében. Az AI- és ML-eszközök zökkenőmentesen integrálhatók más Azure-szolgáltatásokkal, és javítják az adatbetöltést, az előfeldolgozást és a modell üzembe helyezését. Az integráció biztosítja a zökkenőmentes, végpontok közötti munkafolyamatot. Emellett ezek a szolgáltatások elősegítik az együttműködést és a reprodukálhatóságot. A Teams megoszthatja az elemzéseket, és hatékonyan kísérletezhet az eredményekkel és a modellekkel, miközben magas szintű biztonságot és megfelelőséget tart fenn.
Felelős AI
A Microsoft mi- vagy ML-megoldásokkal támogatja a felelős AI-eszközöket a mesterséges intelligenciával és az ML-megoldásokkal. Ezek az eszközök támogatják a Microsoft Responsible AI Standardot. A számítási feladatnak továbbra is egyénileg kell kezelnie az AI-hez kapcsolódó károkat.
Lektorált idézetek
A TDSP egy jól bevált módszertan, amelyet a csapatok a Microsoft-együttműködések során használnak. A TDSP dokumentálva és tanulmányozva van a lektorált szakirodalomban. Az idézetek lehetőséget nyújtanak a TDSP-funkciók és -alkalmazások vizsgálatára. További információkért és az idézetek listájáért tekintse meg a TDSP életciklusát.