Intelligens alkalmazások az Azure SQL Database-lel
A következőre vonatkozik:![]() Azure SQL Database
Azure SQL Database
Ez a cikk áttekintést nyújt a mesterséges intelligencia (AI) lehetőségeinek, például az OpenAI és a vektorok használatával intelligens alkalmazások azure SQL Database-beli létrehozásához.
Áttekintés
A nagyméretű nyelvi modellek (LLM-ek) lehetővé teszik a fejlesztők számára, hogy jól ismert felhasználói felülettel hozzanak létre mesterséges intelligenciával rendelkező alkalmazásokat.
Az LLM-ek alkalmazásokban való használata nagyobb értéket és jobb felhasználói élményt eredményez, ha a modellek a megfelelő időben férhetnek hozzá a megfelelő adatokhoz az alkalmazás adatbázisából. Ez a folyamat a retrieveal augmented Generation (RAG) néven ismert, és az Azure SQL Database számos olyan funkcióval rendelkezik, amelyek támogatják ezt az új mintát, így nagyszerű adatbázissá teszik az intelligens alkalmazások létrehozását.
Az alábbi hivatkozások különböző Azure SQL Database-lehetőségek mintakódját biztosítják intelligens alkalmazások létrehozásához:
| AI-beállítás | Leírás |
|---|---|
| Azure OpenAI | Beágyazásokat hozhat létre a RAG-hoz, és integrálható az Azure OpenAI által támogatott modellekkel. |
| Vektorok | Megtudhatja, hogyan tárolhat és kérdezhet le vektorokat az Azure SQL Database-ben. |
| Azure AI Search | Az Azure SQL Database és az Azure AI Search együttes használatával betaníthatja az LLM-et az adatokon. |
| Intelligens alkalmazások | Megtudhatja, hogyan hozhat létre végpontok közötti megoldást egy olyan közös mintával, amely bármilyen forgatókönyvben replikálható. |
Fő fogalmak
Ez a szakasz olyan kulcsfontosságú fogalmakat tartalmaz, amelyek kritikus fontosságúak az Azure SQL Database és az Azure OpenAI ragjának implementálásához.
Bővített generáció (RAG) lekérése
A RAG egy olyan technika, amely javítja az LLM azon képességét, hogy releváns és informatív válaszokat állítsunk elő további adatok külső forrásokból való lekérésével. A RAG például lekérdezheti azokat a cikkeket vagy dokumentumokat, amelyek a felhasználó kérdésével vagy kérdésével kapcsolatos tartományspecifikus ismereteket tartalmaznak. Az LLM ezután hivatkozásként használhatja ezeket a beolvasott adatokat a válasz létrehozásakor. Az Azure SQL Database-t használó egyszerű RAG-minta például a következő lehet:
- Adatok beszúrása egy Azure SQL Database-táblába.
- Az Azure SQL Database és az Azure AI Search összekapcsolása.
- Hozzon létre egy Azure OpenAI GPT4-modellt, és csatlakoztassa az Azure AI Searchhöz.
- Az alkalmazásból és az Azure SQL Database-ből származó betanított Azure OpenAI-modellel cseveghet és tehet fel kérdéseket az adataival kapcsolatban.
A RAG-minta gyors tervezéssel a válaszminőség növelését szolgálja azáltal, hogy több környezeti információt kínál a modellnek. A RAG lehetővé teszi, hogy a modell szélesebb körű tudásbázist alkalmazzon a releváns külső forrásoknak a létrehozási folyamatba való beépítésével, így átfogóbb és tájékozottabb válaszokat eredményez. Az LLM-ekkel kapcsolatostovábbi információkért lásd: Földi LLM-ek – Microsoft Community Hub.
Kérik és kérik a tervezést
A parancssor olyan konkrét szövegre vagy információra hivatkozik, amely utasításként szolgál egy LLM-nek, vagy olyan környezetfüggő adatokra, amelyekre az LLM építhet. A kérdések különböző űrlapokat, például kérdéseket, állításokat vagy akár kódrészleteket is tartalmazhatnak.
Az alábbiakban felsoroljuk azokat a kéréseket, amelyek az LLM-ből érkező válasz létrehozásához használhatók:
- Utasítások: irányelvek megadása az LLM-nek
- Elsődleges tartalom: információt ad az LLM-nek feldolgozásra
- Példák: segítség a modell adott tevékenységhez vagy folyamathoz való kondicionálásához
- Cues: irányítsa az LLM kimenetét a megfelelő irányba
- Támogató tartalom: olyan kiegészítő információkat jelöl, amelyekkel az LLM kimenetet hozhat létre
A forgatókönyvre vonatkozó jó kérések létrehozásának folyamatát parancssori tervezésnek nevezzük. További információ a parancssori tervezésre vonatkozó kérésekről és ajánlott eljárásokról: Azure OpenAI Service.
Tokenek
A jogkivonatok a bemeneti szöveg kisebb szegmensekre való felosztásával létrehozott kis méretű szövegrészek. Ezek a szegmensek lehetnek szavak vagy karaktercsoportok, egy karaktertől a teljes szóig változó hosszúságúak. A szó hamburger például olyan jogkivonatokra oszlik, mint hama , burés ger míg egy rövid és gyakori szó, mint pear egy jogkivonat.
Az Azure OpenAI-ban az API-nak megadott bemeneti szöveg jogkivonatokká (jogkivonatossá) alakul. Az egyes API-kérésekben feldolgozott tokenek száma olyan tényezőktől függ, mint a bemenet, a kimenet és a kérelem paramétereinek hossza. A feldolgozott jogkivonatok mennyisége a modellek válaszidejének és átviteli sebességének is befolyásolja. Az egyes modellek által az Azure OpenAI-tól érkező egyetlen kérésben/válaszban megengedett jogkivonatok száma korlátozott. További információkért tekintse meg az Azure OpenAI szolgáltatás kvótáit és korlátait.
Vektorok
A vektorok számokat tartalmazó rendezett tömbök (általában lebegőpontosak), amelyek bizonyos adatokkal kapcsolatos információkat képviselnek. Egy kép például a képpontértékek vektoraként is megjeleníthető, vagy egy szöveges sztring vektorként vagy ASCII-értékként is megjeleníthető. Az adatok vektorossá alakításának folyamatát vektorizálásnak nevezzük.
Beágyazások
A beágyazások olyan vektorok, amelyek az adatok fontos jellemzőit képviselik. A beágyazásokat gyakran mélytanulási modell használatával tanulják meg, és a gépi tanulási és AI-modellek funkcióként használják őket. A beágyazások a hasonló fogalmak szemantikai hasonlóságát is rögzíthetik. Ha például beágyazást hozunk létre a szavakhoz person , és humanazt várjuk, hogy a beágyazásuk (vektorábrázolás) értéke hasonló lesz, mivel a szavak is szemantikailag hasonlóak.
Az Azure OpenAI olyan modelleket kínál, amelyekkel beágyazásokat hozhat létre szöveges adatokból. A szolgáltatás jogkivonatokra bontja a szöveget, és beágyazásokat hoz létre az OpenAI által előre betanított modellek használatával. További információ: Beágyazások létrehozása az Azure OpenAI-val.
Vektoros keresés
A vektorkeresés egy adathalmaz összes vektorának megkeresésére utal, amely szemantikailag hasonlít egy adott lekérdezésvektorhoz. Ezért a szó human egy lekérdezésvektora szemantikailag hasonló szavakat keres a teljes szótárban, és szoros egyezésként kell megtalálnia a szót person . Ezt a közelséget vagy távolságot egy hasonlósági metrika, például a koszinusz hasonlósága alapján mérik. A közelebbi vektorok hasonlóak, minél kisebb a távolság közöttük.
Fontolja meg azt a forgatókönyvet, amikor több millió dokumentumon futtat lekérdezést, hogy megtalálja az adatokban a leginkább hasonló dokumentumokat. Az Azure OpenAI használatával beágyazásokat hozhat létre az adatokhoz és lekérdezheti a dokumentumokat. Ezután vektorkereséssel megkeresheti az adathalmazból a leginkább hasonló dokumentumokat. A vektorkeresés végrehajtása azonban néhány példa alapján triviális. Ez a keresés több ezer vagy több millió adatponton is kihívást jelent. A teljes körű keresés és a legközelebbi szomszéd (ANN) keresési módszerek között is vannak kompromisszumok, beleértve a késést, az átviteli sebességet, a pontosságot és a költségeket, amelyek mindegyike az alkalmazás követelményeitől függ.
Mivel az Azure SQL Database-beágyazások hatékonyan tárolhatók és lekérdezhetők az oszlopcentrikus index támogatásával, így a legközelebbi szomszédkeresést nagy teljesítménnyel teszik lehetővé, nem kell a pontosság és a sebesség között döntenie: mindkettőt használhatja. A vektoros beágyazások és az adatok integrált megoldásban való tárolása minimálisra csökkenti az adatszinkronizálás szükségességét, és felgyorsítja az AI-alkalmazások fejlesztéséhez szükséges időt.
Azure OpenAI
A beágyazás a valós világ adatokként való ábrázolásának folyamata. A szöveg, a képek vagy a hangok beágyazásokká alakíthatók. Az Azure OpenAI-modellek a valós információkat beágyazásokká alakíthatják. A modellek REST-végpontokként érhetők el, így könnyen felhasználhatók az Azure SQL Database-ből a sp_invoke_external_rest_endpoint rendszer által tárolt eljárással:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Az SQL Database és az OpenAI használatakor a REST-szolgáltatás meghívása a beágyazások lekérésére csak az egyik integrációs lehetőség. Bármely elérhető modell hozzáférhet az Azure SQL Database-ben tárolt adatokhoz olyan megoldások létrehozásához, amelyekben a felhasználók kezelhetik az adatokat, például az alábbi példában.
Az SQL Database és az OpenAI használatával kapcsolatos további példákért tekintse meg az alábbi cikkeket:
- Képek létrehozása az Azure OpenAI Szolgáltatással (DALL-E) és az Azure SQL Database-vel
- OpenAI REST-végpontok használata az Azure SQL Database-lel
Vektorok
Bár az Azure SQL Database nem rendelkezik natív vektortípussal , a vektor nem más, mint egy rendezett rekord, és a relációs adatbázisok nagyszerűen kezelik a rekordokat. A táblázat sorainak formális kifejezéseként tekinthet a tuple kifejezésre.
Az Azure SQL Database támogatja az oszlopcentrikus indexeket és a kötegelt módú végrehajtást is. A kötegelt módú feldolgozáshoz vektoralapú megközelítést használunk, ami azt jelenti, hogy a köteg minden oszlopa saját memóriahelyet biztosít, ahol vektorként tárolják. Ez lehetővé teszi az adatok gyorsabb és hatékonyabb feldolgozását kötegekben.
Az alábbi példa egy vektor SQL Database-ben való tárolására mutat be példát:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Ha például a Wikipédiából származó cikkek gyakori részhalmazát használja az OpenAI használatával létrehozott beágyazásokkal, tekintse meg az Azure SQL Database és az OpenAI vektoros hasonlósági keresését.
Az Azure SQL Database-ben a Vector Search használatának másik lehetősége az Azure AI-vel való integráció az integrált vektorizációs képességek használatával: Vector Search az Azure SQL Database-lel és az Azure AI Search-lel
Azure AI Search
RAG-mintákat valósít meg az Azure SQL Database és az Azure AI Search használatával. Az Azure AI Search és az Azure OpenAI és az Azure SQL Database integrációjának köszönhetően az Azure SQL Database-ben tárolt adatokon támogatott csevegőmodelleket futtathat anélkül, hogy be kellene tanítania vagy finomhangolnia a modelleket. Az adatokon futó modellek lehetővé teszik, hogy nagyobb pontossággal és sebességgel csevegjen és elemezze az adatokat.
- Azure OpenAI az adatokon
- Kiterjesztett generáció (RAG) lekérése az Azure AI Searchben
- Vektorkeresés az Azure SQL Database és az Azure AI Search használatával
Intelligens alkalmazások
Az Azure SQL Database olyan intelligens alkalmazások készítésére használható, amelyek AI-szolgáltatásokat, például ajánlókat és lekéréses kiterjesztett generációt (RAG) tartalmaznak, ahogy az alábbi ábrán látható:
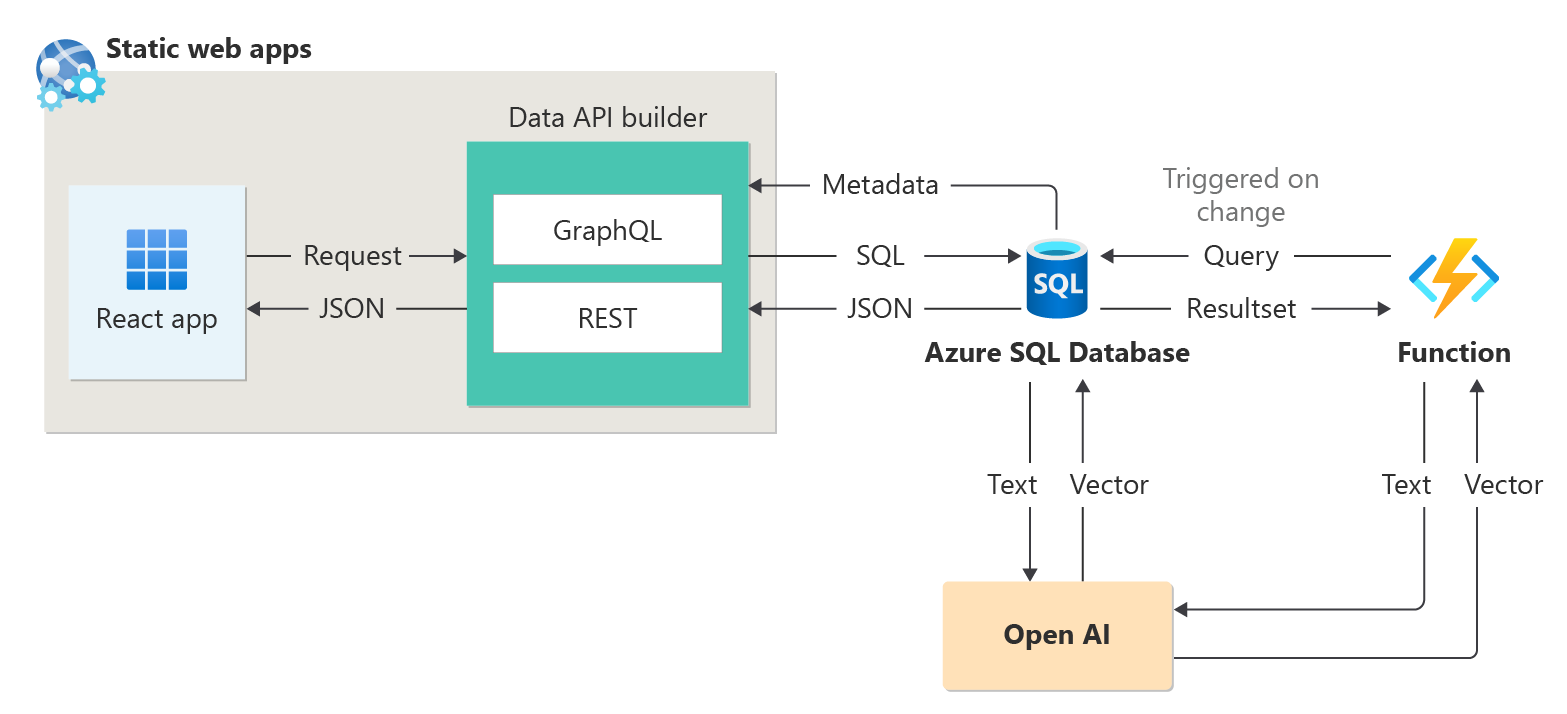
Ha egy végpontok közötti mintát szeretne létrehozni egy ajánló létrehozásához munkamenet-absztrakt mintaadatkészletként, tekintse meg a Munkamenet-ajánló 1 óra alatt az Open AI használatával történő összeállítását ismertető témakört.
LangChain-integráció
A LangChain egy jól ismert keretrendszer a nyelvi modelleken alapuló alkalmazások fejlesztéséhez.
Egy példa, amely bemutatja, hogy a LangChain hogyan használható csevegőrobot létrehozásához a saját adatain, lásd : Saját DB Copilot létrehozása az Azure SQL-hez az Azure OpenAI GPT-4 használatával.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: