Always On rendelkezésre állási csoport azure-beli virtuális gépeken futó SQL Serveren
A következőre vonatkozik:![]() SQL Server azure-beli virtuális gépen
SQL Server azure-beli virtuális gépen
Ez a cikk bemutatja az Azure-beli virtuális gépeken (VM-eken) futó SQL Serverhez készült Always On rendelkezésre állási csoportokat (AG).
Első lépésként tekintse meg a rendelkezésre állási csoport oktatóanyagát.
Áttekintés
Az Azure Virtual Machines Always On rendelkezésre állási csoportjai hasonlóak a helyszíni Always On rendelkezésre állási csoportokhoz, és a mögöttes Windows Server feladatátvevő fürtre támaszkodnak. Mivel azonban a virtuális gépeket az Azure-ban üzemeltetik, további szempontokat is figyelembe kell venni, például a virtuális gépek redundanciáit és az Azure-hálózat útválasztási forgalmát.
Az alábbi ábra az Azure-beli virtuális gépeken futó SQL Server rendelkezésre állási csoportját mutatja be:
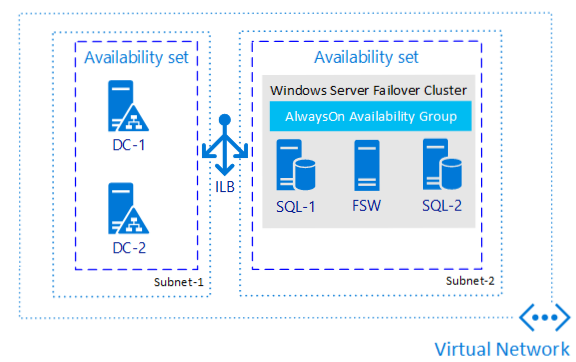
Megjegyzés:
Mostantól az Azure Migrate használatával át lehet emelni és áthelyezni a rendelkezésre állási csoport megoldását az Azure-beli virtuális gépeken futó SQL Serverre. További információ: Migrálási rendelkezésre állási csoport .
Virtuálisgép-redundancia
A redundancia és a magas rendelkezésre állás növelése érdekében az SQL Server virtuális gépeknek ugyanabban a rendelkezésre állási csoportban vagy különböző rendelkezésre állási zónákban kell lenniük.
Ha egy virtuális gépet ugyanabban a rendelkezésre állási csoportban helyez el, az védelmet nyújt az adatközpontban a berendezések meghibásodása (a rendelkezésre állási csoportban lévő virtuális gépek nem osztanak meg erőforrásokat) vagy a frissítésektől (a rendelkezésre állási csoportban lévő virtuális gépek nem frissülnek egyszerre).
A rendelkezésre állási zónák védelmet nyújtanak egy teljes adatközpont meghibásodása ellen, és minden zóna egy adott régióban lévő adatközpontokat jelöl. Ha biztosítja, hogy az erőforrások különböző rendelkezésre állási zónákba kerüljenek, egyetlen adatközpontszintű leállás sem képes az összes virtuális gép offline állapotba helyezésére.
Azure-beli virtuális gépek létrehozásakor választania kell a rendelkezésre állási csoportok és a rendelkezésre állási zónák konfigurálása között. Az Azure-beli virtuális gépek nem vehetnek részt mindkettőben.
Bár a rendelkezésre állási zónák jobb rendelkezésre állást biztosíthatnak, mint a rendelkezésre állási csoportok (99,99% és 99,95%), a teljesítményt is figyelembe kell venni. A rendelkezésre állási csoportban lévő virtuális gépek olyan közelségi elhelyezési csoportba helyezhetők, amely garantálja, hogy közel állnak egymáshoz, így minimalizálva a közöttük lévő hálózati késést. A különböző rendelkezésre állási zónákban található virtuális gépek nagyobb hálózati késéssel rendelkeznek közöttük, ami növelheti az elsődleges és a másodlagos replika(ok) közötti adatszinkronizálási időt. Ez késéseket okozhat az elsődleges replikán, valamint növelheti az adatvesztés esélyét nem tervezett feladatátvétel esetén. Fontos tesztelni a javasolt megoldást terhelés alatt, és gondoskodni arról, hogy megfeleljen az SLA-knak mind a teljesítmény, mind a rendelkezésre állás szempontjából.
Kapcsolatok
A rendelkezésre állási csoport figyelőjéhez való csatlakozás helyszíni élményének megfelelően helyezze üzembe az SQL Server virtuális gépeket ugyanazon a virtuális hálózaton belül több alhálózaton . Ha több alhálózattal rendelkezik, azzal nem szükséges az Azure Load Balancer extra függősége, vagy egy elosztott hálózati név (DNN) a forgalom figyelőhöz való átirányításához.
Ha az SQL Server virtuális gépeket egyetlen alhálózaton helyezi üzembe, konfigurálhat egy virtuális hálózatnevet (VNN) és egy Azure Load Balancert, vagy egy elosztott hálózati nevet (DNN) a forgalomnak a rendelkezésre állási csoport figyelőjéhez való átirányításához. Tekintse át a kettő közötti különbségeket, majd helyezzen üzembe egy elosztott hálózatnevet (DNN) vagy egy virtuális hálózatnevet (VNN) a rendelkezésre állási csoport számára.
A legtöbb SQL Server-funkció transzparens módon működik a rendelkezésre állási csoportokkal a DNN használatakor, de vannak bizonyos funkciók, amelyek különleges figyelmet igényelhetnek. További információért tekintse meg az AG és a DNN együttműködési lehetőségeit .
Emellett a VNN-figyelő és a DNN-figyelő funkciói között is vannak viselkedésbeli különbségek, amelyeket fontos megjegyezni:
- Feladatátvételi idő: A feladatátvételi idő gyorsabb, ha DNN-figyelőt használ, mivel nem kell megvárni, amíg a hálózati terheléselosztó észleli a hibaeseményt, és módosítja annak útválasztását.
- Meglévő kapcsolatok: A feladatátvételi rendelkezésre állási csoporton belül egy adott adatbázishoz létesített kapcsolatok bezárulnak, de az elsődleges replikához kapcsolódó egyéb kapcsolatok nyitva maradnak, mivel a DNN online marad a feladatátvételi folyamat során. Ez eltér a hagyományos VNN-környezetétől, ahol az elsődleges replikához tartozó összes kapcsolat általában bezárul, amikor a rendelkezésre állási csoport meghibásodik, a figyelő offline állapotba kerül, és az elsődleges replika átáll a másodlagos szerepkörre. DNN-figyelő használata esetén előfordulhat, hogy módosítania kell az alkalmazáskapcsolati sztringeket, hogy a rendszer a feladatátvételkor az új elsődleges replikára irányítsa a kapcsolatokat.
- Tranzakciók megnyitása: A feladatátvételi rendelkezésre állási csoport adatbázisán belüli tranzakciók megnyitása bezáródik és visszagördül, és manuálisan kell újracsatlakoznia. Az SQL Server Management Studióban például zárja be a lekérdezési ablakot, és nyisson meg egy újat.
A VNN-figyelő Azure-ban való beállításához terheléselosztóra van szükség. Az Azure-ban a terheléselosztók két fő lehetőség közül választhatnak: külső (nyilvános) vagy belső. A külső (nyilvános) terheléselosztó internetkapcsolattal rendelkezik, és az interneten keresztül elérhető nyilvános virtuális IP-címhez van társítva. A belső terheléselosztó csak az ugyanazon a virtuális hálózaton belüli ügyfeleket támogatja. Mindkét terheléselosztótípus esetében engedélyeznie kell a Direct Server Returnt.
Az egyes rendelkezésre állási replikákhoz továbbra is külön csatlakozhat, ha közvetlenül a szolgáltatáspéldányhoz csatlakozik. Mivel a rendelkezésre állási csoportok visszamenőlegesen kompatibilisek az adatbázis-tükrözési ügyfelekkel, csatlakozhat a rendelkezésre állási replikákhoz, például az adatbázis-tükrözési partnerekhez, amennyiben a replikák az adatbázis-tükrözéshez hasonlóan vannak konfigurálva:
- Van egy elsődleges és egy másodlagos replika.
- A másodlagos replika nem olvashatóként van konfigurálva (Az olvasható másodlagos beállítás értéke Nem).
Az alábbiakban egy példa ügyfélkapcsolati sztring található, amely megfelel ennek az adatbázistükrözés-szerű konfigurációnak ADO.NET vagy natív SQL Server-ügyfél használatával:
Data Source=ReplicaServer1;Failover Partner=ReplicaServer2;Initial Catalog=AvailabilityDatabase;
Az ügyfélkapcsolattal kapcsolatos további információkért lásd:
- Kapcsolati sztring kulcsszavak használata natív SQL Server-ügyféllel
- Ügyfelek csatlakoztatása adatbázis-tükrözési munkamenethez (SQL Server)
- Csatlakozás a rendelkezésre állási csoport figyelőjével a hibrid it-ben
- Rendelkezésre állási csoport figyelői, ügyfélkapcsolatai és alkalmazás feladatátvétele (SQL Server)
- Adatbázis-tükrözési kapcsolati sztringek használata rendelkezésre állási csoportokkal
Az egyetlen alhálózat terheléselosztót igényel
Amikor egy rendelkezésre állási csoport figyelőt hoz létre egy hagyományos helyszíni Windows Server feladatátvevő fürtön (WSFC), a rendszer létrehoz egy DNS-rekordot a figyelő számára a megadott IP-címmel, és ez az IP-cím a helyszíni hálózat kapcsolóinak és útválasztóinak ARP-tábláiban lévő aktuális elsődleges replika MAC-címére lesz leképezve. A fürt ezt a Gratuitous ARP (GARP) használatával teszi meg, ahol a legújabb IP-mac címleképezést közvetíti a hálózatra, amikor a feladatátvétel után új elsődlegest választ ki. Ebben az esetben az IP-cím a figyelőhöz tartozik, a MAC pedig az aktuális elsődleges replika. A GARP kényszeríti a kapcsolók és útválasztók ARP-táblabejegyzéseinek frissítését, valamint a figyelő IP-címéhez csatlakozó felhasználókat a rendszer zökkenőmentesen irányítja az aktuális elsődleges replikára.
Biztonsági okokból a nyilvános felhők (Azure, Google, AWS) közvetítése nem engedélyezett, így az Azure-beli ARP-k és GARP-k használata nem támogatott. A hálózati környezetek közötti különbség leküzdése érdekében az egyetlen alhálózati rendelkezésre állási csoportban lévő SQL Server virtuális gépek terheléselosztókra támaszkodnak a forgalom megfelelő IP-címekre való átirányításához. A terheléselosztók a figyelőnek megfelelő előtérbeli IP-címmel vannak konfigurálva, és egy mintavételi port van hozzárendelve, hogy az Azure Load Balancer rendszeresen lekérdezhesse a rendelkezésre állási csoportban lévő replikák állapotát. Mivel csak az elsődleges replika SQL Server virtuális gép válaszol a TCP-mintavételre, a bejövő forgalmat a rendszer átirányítja a mintavételre sikeresen válaszoló virtuális gépre. Emellett a megfelelő mintavételi port WSFC-fürt IP-címeként van konfigurálva, biztosítva, hogy az elsődleges replika válaszoljon a TCP-mintavételre.
Az egyetlen alhálózatban konfigurált rendelkezésre állási csoportoknak terheléselosztót vagy elosztott hálózati nevet (DNN) kell használniuk a forgalom megfelelő replikához való átirányításához. A függőségek elkerülése érdekében konfigurálja a rendelkezésre állási csoportot több alhálózatban, hogy a rendelkezésre állási csoport figyelője minden alhálózatban egy replika IP-címével legyen konfigurálva, és megfelelően irányíthassa a forgalmat.
Ha már létrehozta a rendelkezésre állási csoportot egyetlen alhálózatban, migrálhatja azt egy több alhálózatos környezetbe.
Bérlet mechanizmusa
AZ SQL Server esetében az AG-erőforrás DLL-je határozza meg az AG állapotát az AG-bérlet mechanizmusa és az Always On állapotészlelése alapján. Az AG-erőforrás DLL-je az IsAlive művelettel teszi elérhetővé az erőforrás állapotát. Az erőforrásmonitor a fürt szívverési időközében kérdezi le az IsAlive értéket, amelyet a CrossSubnetDelay és a SameSubnetDelay fürtszintű értékek határoznak meg. Egy elsődleges csomóponton a fürtszolgáltatás akkor kezdeményezi a feladatátvételt, amikor az erőforrás DLL-hez irányuló IsAlive-hívás azt adja vissza, hogy az AG nem kifogástalan állapotú.
Az AG-erőforrás DLL-je figyeli a belső SQL Server-összetevők állapotát. Sp_server_diagnostics az összetevők állapotát a HealthCheckTimeout által szabályozott időközönként jelenti az SQL Servernek.
A többi feladatátvételi mechanizmustól eltérően az SQL Server-példány aktív szerepet játszik a bérletmechanizmusban. A bérlet mechanizmus a fürterőforrás-gazdagép és az SQL Server-folyamat közötti LooksAlive-ellenőrzésként használatos. A mechanizmus annak biztosítására szolgál, hogy a két fél (a Fürtszolgáltatás és az SQL Server szolgáltatás) gyakran érintkezhessen egymással, ellenőrizze egymás állapotát, és végül megakadályozza a felosztási forgatókönyvet.
Ha azure-beli virtuális gépeken konfigurál egy AG-t, gyakran másképpen kell konfigurálni ezeket a küszöbértékeket, mint a helyszíni környezetben. Az Azure-beli virtuális gépekre vonatkozó ajánlott eljárásoknak megfelelő küszöbérték-beállítások konfigurálásához tekintse meg a fürt ajánlott eljárásait.
Hálózati konfiguráció
Ha lehetséges, helyezze üzembe az SQL Server virtuális gépeket több alhálózaton, hogy elkerülje az Azure Load Balancer vagy egy elosztott hálózati név (DNN) függőségét, hogy a forgalmat a rendelkezésre állási csoport figyelőjéhez irányíthassa.
Egy Azure-beli virtuálisgép-feladatátvevő fürtön kiszolgálónként (fürtcsomópontonként) egyetlen hálózati adaptert ajánlunk. Az Azure hálózatkezelés fizikai redundanciájú, ami további hálózati adaptereket szükségtelensé tesz egy Azure-beli virtuálisgép-feladatátvevő fürtön. Bár a fürtérvényesítési jelentés figyelmeztetést ad arról, hogy a csomópontok csak egyetlen hálózaton érhetők el, ezt a figyelmeztetést biztonságosan figyelmen kívül hagyhatja az Azure-beli virtuális gépek feladatátvevő fürtjeiben.
Alapszintű rendelkezésre állási csoport
Mivel az alapszintű rendelkezésre állási csoport nem engedélyez több másodlagos replikát, és nincs olvasási hozzáférése a másodlagos replikához, az adatbázis tükrözési kapcsolati sztringjét használhatja az alapszintű rendelkezésre állási csoportokhoz. A kapcsolati sztring használata szükségtelenné teszi a figyelők használatát. A figyelőfüggőség eltávolítása hasznos lehet az Azure-beli virtuális gépek rendelkezésre állási csoportjai számára, mivel szükségtelenné teszi a terheléselosztó használatát, vagy ha több figyelővel rendelkezik a további adatbázisokhoz, további IP-címeket kell hozzáadnia a terheléselosztóhoz.
Ha például tcp/IP használatával szeretne explicit módon csatlakozni az AdventureWorks AG-adatbázishoz egy alapszintű AG Replica_A vagy Replica_B (vagy bármely olyan AG-n, amely csak egy másodlagos replikával rendelkezik, és az olvasási hozzáférés nem engedélyezett a másodlagos replikában), az ügyfélalkalmazás a következő adatbázis-tükrözési kapcsolati sztringet szolgáltathatja az AG-hez való sikeres csatlakozáshoz
Server=Replica_A; Failover_Partner=Replica_B; Database=AdventureWorks; Network=dbmssocn
Telepítési beállítások
Tipp
Az Always On rendelkezésre állási csoporthoz tartozó Azure Load Balancer vagy elosztott hálózati név (DNN) szükségtelenné tételéhez hozzon létre SQL Server-virtuális gépeket több alhálózatban ugyanazon az Azure-beli virtuális hálózaton belül.
A rendelkezésre állási csoport azure-beli virtuális gépeken való üzembe helyezésére több lehetőség is van, amelyek némelyike több automatizálással rendelkezik, mint mások.
Az alábbi táblázat az elérhető lehetőségek összehasonlítását tartalmazza:
| Azure Portal | Azure CLI/PowerShell | Gyorsindítási sablonok | Manuális (egyetlen alhálózat) | Manuális (több alhálózat) | |
|---|---|---|---|---|---|
| SQL Server-verzió | 2016+ | 2016+ | 2016+ | 2012+ | 2012+ |
| SQL Server-kiadás | Enterprise | Enterprise | Enterprise | Enterprise, Standard | Enterprise, Standard |
| Windows Server verziója | 2016+ | 2016+ | 2016+ | Mind | Mind |
| Létrehozza a fürtöt | Igen | Igen | Igen | Nem | Nem |
| Létrehozza a rendelkezésreállási csoportot és a figyelőt | Igen | Nem | Nem | Nem | Nem |
| Külön létrehozza a figyelőt és a terheléselosztót | N/A | Nem | Nem | Igen | N/A |
| Létre lehet hozni DNN-figyelőt ezzel a módszerrel? | N/A | Nem | Nem | Igen | N/A |
| WSCF-kvórumkonfiguráció | Felhőbeli tanúsító | Felhőbeli tanúsító | Felhőbeli tanúsító | Mind | Mind |
| Vészhelyreállítás több régióval | Nem | Nem | Nem | Igen | Igen |
| Több alhálózat támogatása | Igen | Nem | Nem | N/A | Igen |
| Meglévő AD támogatása | Igen | Igen | Igen | Igen | Igen |
| Vészhelyreállítás ugyanazon régió több zónájával | Igen | Igen | Igen | Igen | Igen |
| Elosztott rendelkezésreállási csoportok AD nélkül | Nem | Nem | Nem | Igen | Igen |
| Elosztott rendelkezésreállási csoportok fürt nélkül | Nem | Nem | Nem | Igen | Igen |
| Terheléselosztó vagy DNN szükséges | Nem | Igen | Igen | Igen | Nem |
További lépések
Első lépésként tekintse át a HADR ajánlott eljárásait, majd helyezze üzembe manuálisan a rendelkezésre állási csoportot a rendelkezésre állási csoport oktatóanyagával.
További tudnivalókért lásd: