Adatok átalakítása Jar-tevékenység futtatásával az Azure Databricksben
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Az Azure Databricks Jar-tevékenység egy folyamatban spark jart futtat az Azure Databricks-fürtön. Ez a cikk az adatátalakítási tevékenységekről szóló cikkre épül, amely általános áttekintést nyújt az adatátalakításról és a támogatott átalakítási tevékenységekről. Az Azure Databricks egy felügyelt platform az Apache Spark futtatásához.
Az alábbi videóban a funkció bemutatását és ismertetését tekintheti meg tizenegy percben:
Jar-tevékenység hozzáadása az Azure Databrickshez felhasználói felülettel rendelkező folyamathoz
Ha Jar-tevékenységet szeretne használni az Azure Databrickshez egy folyamatban, hajtsa végre a következő lépéseket:
Keresse meg a Jart a folyamattevékenységek panelen, és húzzon egy Jar-tevékenységet a folyamatvászonra.
Jelölje ki az új Jar-tevékenységet a vásznon, ha még nincs kijelölve.
Válassza az Azure Databricks lapot egy új Azure Databricks társított szolgáltatás kiválasztásához vagy létrehozásához, amely végrehajtja a Jar-tevékenységet.
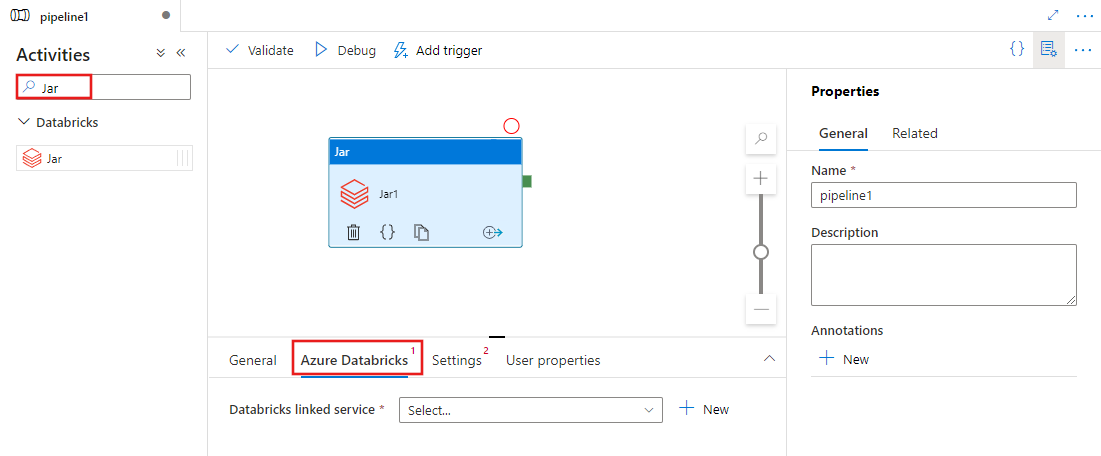
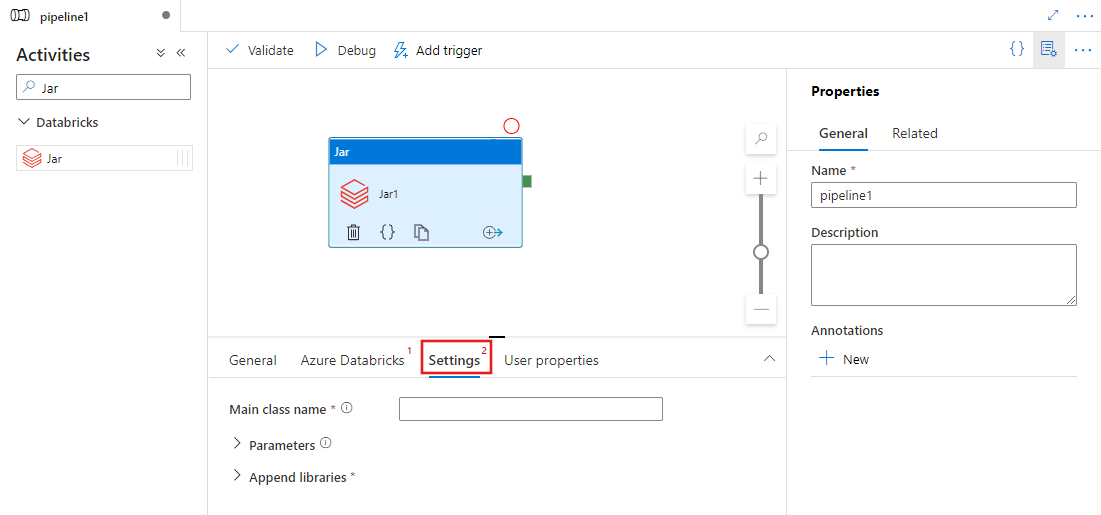
Válassza a Beállítások lapot, és adja meg az Azure Databricksen végrehajtandó osztálynevet, a Jarnak átadandó opcionális paramétereket, valamint a fürtre telepíteni kívánt kódtárakat a feladat végrehajtásához.
Databricks Jar-tevékenységdefiníció
A Databricks Jar-tevékenység JSON-mintadefiníciója a következő:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Databricks Jar-tevékenység tulajdonságai
Az alábbi táblázat a JSON-definícióban használt JSON-tulajdonságokat ismerteti:
| Tulajdonság | Leírás | Szükséges |
|---|---|---|
| név | A folyamat tevékenységének neve. | Igen |
| leírás | A tevékenység tevékenységeit leíró szöveg. | Nem |
| típus | A Databricks Jar-tevékenység esetében a tevékenység típusa a DatabricksSparkJar. | Igen |
| linkedServiceName | Annak a Databricks társított szolgáltatásnak a neve, amelyen a Jar-tevékenység fut. A társított szolgáltatással kapcsolatos további információkért tekintse meg a társított számítási szolgáltatásokról szóló cikket. | Igen |
| mainClassName | A végrehajtandó fő metódust tartalmazó osztály teljes neve. Ezt az osztályt egy kódtárként megadott JAR-ben kell tárolni. A JAR-fájlok több osztályt is tartalmazhatnak. Mindegyik osztály tartalmazhat fő metódust. | Igen |
| parameters | A fő metódusnak átadott paraméterek. Ez a tulajdonság sztringek tömbje. | Nem |
| kódtárak | A feladatot végrehajtó fürtre telepíteni kívánt kódtárak listája. Ez lehet sztringek, objektumok tömbje <> | Igen (legalább egy a mainClassName metódust tartalmazza) |
Feljegyzés
Ismert probléma – Ha ugyanazt az interaktív fürtöt használja egyidejű Databricks Jar-tevékenységek futtatásához (fürt újraindítása nélkül), a Databricksben ismert probléma áll fenn, ahol az 1. tevékenység paramétereiben a következő tevékenységek is használhatók. Emiatt a program helytelen paramétereket ad át a következő feladatoknak. Ennek mérsékléséhez használjon inkább feladatfürtöt.
A databricks-tevékenységekhez támogatott kódtárak
Az előző Databricks-tevékenységdefinícióban a következő kódtártípusokat adta meg: jar, , , maven, pypicran. egg
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
További információkért tekintse meg a Databricks könyvtártípusokkal kapcsolatos dokumentációját .
Tár feltöltése a Databricksben
A munkaterület felhasználói felületét használhatja:
A Databricks-munkaterület felhasználói felületének használata
A felhasználói felületen hozzáadott kódtár adatbázis-elérési útjának lekéréséhez használhatja a Databricks parancssori felületét.
A Jar-kódtárak általában a dbfs:/FileStore/jars alatt vannak tárolva a felhasználói felület használata során. A parancssori felület összes elemét listázhatja: databricks fs ls dbfs:/FileStore/job-jars
Vagy használhatja a Databricks parancssori felületét:
A Databricks parancssori felületének használata (telepítési lépések)
Például egy JAR másolása a dbfs-be:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Kapcsolódó tartalom
A funkció 11 perces bemutatásához és bemutatásához tekintse meg a videót.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: