Adatok átalakítása a Delta Lake-ben a leképezési adatfolyamok használatával
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ha még csak ismerkedik az Azure Data Factory használatával, olvassa el az Azure Data Factory használatának első lépéseit ismertető cikket.
Ebben az oktatóanyagban az adatfolyam-vásznon olyan adatfolyamokat hozhat létre, amelyek lehetővé teszik az adatok elemzését és átalakítását az Azure Data Lake Storage (ADLS) Gen2-ben, és tárolhatja azokat a Delta Lake-ben.
Előfeltételek
- Azure-előfizetés. Ha nem rendelkezik Azure-előfizetéssel, mindössze néhány perc alatt létrehozhat egy ingyenes Azure-fiókot a virtuális gép létrehozásának megkezdése előtt.
- Egy Azure Storage-fiók. Az ADLS-tárolót forrás- és fogadóadattárként használja. Ha még nem rendelkezik tárfiókkal, tekintse meg az Azure Storage-fiók létrehozásának lépéseit ismertető cikket.
Az oktatóanyagban átalakítandó fájl MoviesDB.csv, amely itt található. Ha le szeretné kérni a fájlt a GitHubról, másolja a tartalmat egy tetszőleges szövegszerkesztőbe, és mentse helyileg .csv fájlként. Ha fel szeretné tölteni a fájlt a tárfiókba, olvassa el a Blobok feltöltése az Azure Portallal című témakört. A példák egy "sample-data" nevű tárolóra hivatkoznak.
Adat-előállító létrehozása
Ebben a lépésben létrehoz egy adat-előállítót, és megnyitja a Data Factory UX-t egy folyamat létrehozásához az adat-előállítóban.
Nyissa meg a Microsoft Edge-et vagy a Google Chrome-ot. A Data Factory felhasználói felülete jelenleg csak a Microsoft Edge és a Google Chrome böngészőkben támogatott.
A bal oldali menüben válassza az Erőforrás-integrációs>>adat-előállító létrehozása lehetőséget
Az Új adat-előállító lap Név területén adja meg az ADFTutorialDataFactory nevet
Válassza ki azt az Azure-előfizetést, amelyben az adat-előállítót létre szeretné hozni.
Erőforráscsoport: hajtsa végre a következő lépések egyikét:
a. Kattintson a Meglévő használata elemre, majd a legördülő listából válasszon egy meglévő erőforráscsoportot.
b. Kattintson az Új létrehozása elemre, és adja meg az erőforráscsoport nevét.
Az erőforráscsoportokkal kapcsolatos információkért tekintse meg az Erőforráscsoportok használata az Azure-erőforrások kezeléséhez ismertető cikket.
A Verzió résznél válassza a V2 értéket.
A Hely területen válassza ki az adat-előállító helyét. A legördülő listán csak a támogatott helyek jelennek meg. Az adat-előállító által használt adattárak (például az Azure Storage és az SQL Database) és a számítások (például az Azure HDInsight) más régiókban is lehetnek.
Válassza a Létrehozás lehetőséget.
A létrehozás befejezése után megjelenik az értesítés az Értesítések központban. Válassza az Ugrás az erőforrásra lehetőséget a Data Factory lapra való navigáláshoz.
A Data Factory felhasználói felületének külön lapon történő elindításához válassza a Létrehozás és figyelés csempét.
Folyamat létrehozása adatfolyam-tevékenységgel
Ebben a lépésben egy adatfolyam-tevékenységet tartalmazó folyamatot hoz létre.
A kezdőlapon válassza az Orchestrate (Vezénylés) lehetőséget.
A folyamat Általános lapján adja meg a DeltaLake nevet a folyamat nevéhez.
A Tevékenységek panelen bontsa ki az Áthelyezés és átalakítás harmonika elemet. Húzza a Adatfolyam tevékenységet a panelről a folyamatvászonra.
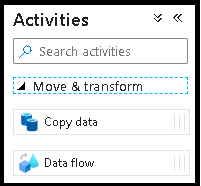
A Hozzáadás Adatfolyam előugró ablakban válassza az Új Adatfolyam létrehozása lehetőséget, majd adja meg az adatfolyam DeltaLake nevét. Ha elkészült, válassza a Befejezés lehetőséget.
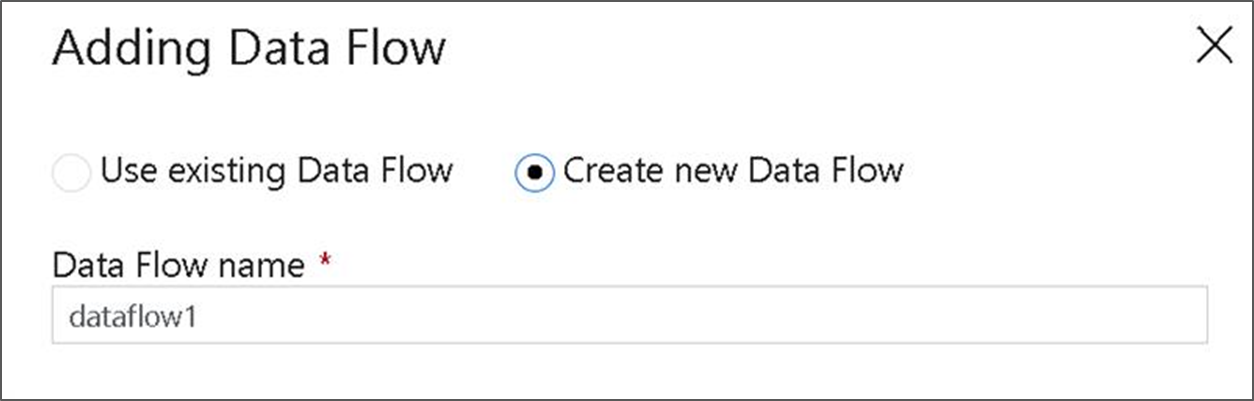
A folyamatvászon felső sávján húzza a Adatfolyam hibakeresési csúszkát. A hibakeresési mód lehetővé teszi az átalakítási logika interaktív tesztelését egy élő Spark-fürtön. Adatfolyam fürtök bemelegedése 5-7 percet vesz igénybe, és a felhasználóknak ajánlott először bekapcsolniuk a hibakeresést, ha Adatfolyam fejlesztést terveznek. További információ: Hibakeresési mód.

Átalakítási logika létrehozása az adatfolyam-vásznon
Ebben az oktatóanyagban két adatfolyamot hoz létre. Az első adatfolyam egy egyszerű forrás, amely egy új Delta Lake-t hoz létre a filmek CSV-fájljából. Végül létre kell hoznia az alábbi folyamattervet a Delta Lake adatainak frissítéséhez.

Oktatóanyag célkitűzései
- Használja a MoviesCSV adatkészlet forrását az előfeltételekből, és alakítsa ki belőle az új Delta Lake-t.
- Hozza létre a logikát, hogy az 1988-hoz készült filmek minősítéseit "1" értékre frissítse.
- Törölje az összes filmet 1950-ből.
- Új filmek beszúrása 2021-ben a filmek 1960-ból való duplikálásával.
Kezdés egy üres adatfolyam-vászonról
Válassza ki a forrásátalakítást az adatfolyam-szerkesztő ablakának tetején, majd válassza az + Új lehetőséget az Adathalmaz tulajdonság mellett a Forrásbeállítások ablakban:
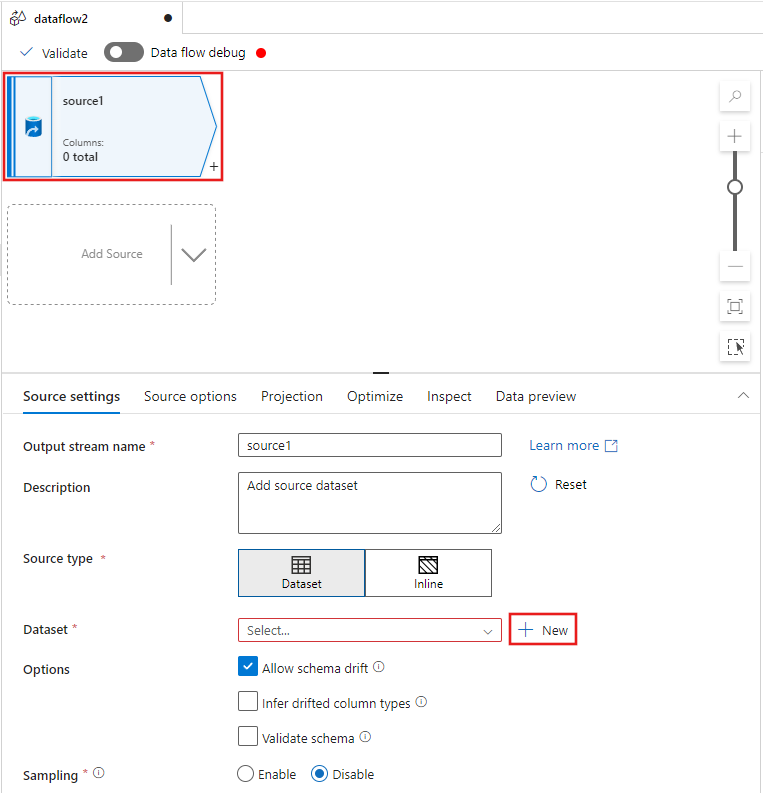
Válassza az Azure Data Lake Storage Gen2-t a megjelenő Új adathalmaz ablakban, majd válassza a Folytatás lehetőséget.
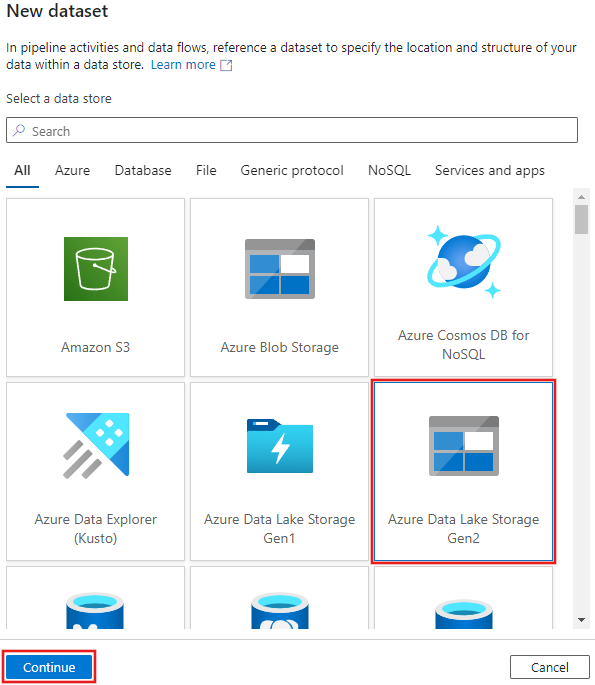
Válassza a DelimitedText (Elválasztó szöveg) lehetőséget az adathalmaz típusához, majd válassza ismét a Folytatás lehetőséget.

Nevezze el a "MoviesCSV" adathalmazt, és válassza az + Új a Csatolt szolgáltatás területen lehetőséget egy új társított szolgáltatás létrehozásához a fájlhoz.
Adja meg a korábban az Előfeltételek szakaszban létrehozott tárfiók adatait, és keresse meg és válassza ki az ott feltöltött MoviesCSV-fájlt.
A csatolt szolgáltatás hozzáadása után jelölje be az Első sort fejlécként jelölőnégyzet, majd a forrás hozzáadásához kattintson az OK gombra .
Lépjen az adatfolyam-beállítások ablakÁnak Vetítés lapjára, majd válassza az Adattípusok észlelése lehetőséget.
Most jelölje ki a + Forrás után az adatfolyam-szerkesztőablakban, és görgessen le a Cél szakaszban található Fogadó elemre, és adjon hozzá egy új fogadót az adatfolyamhoz.
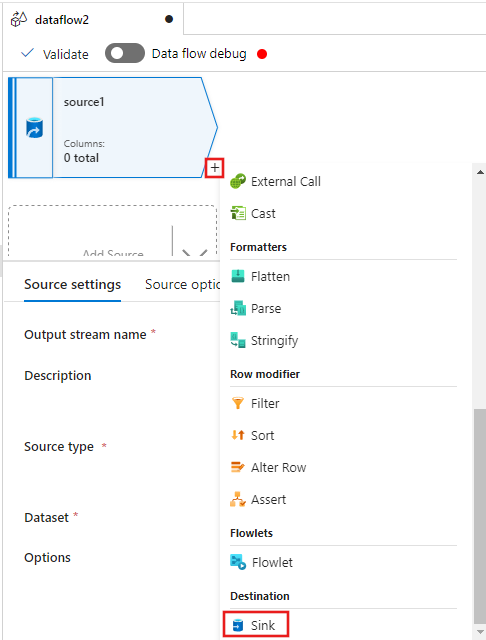
A Fogadó lapon a fogadó hozzáadása után megjelenő fogadóbeállításoknál válassza a Fogadó típus Beágyazott, majd a Delta lehetőséget a Beágyazott adathalmaz típushoz. Ezután válassza ki az Azure Data Lake Storage Gen2-t a társított szolgáltatáshoz.
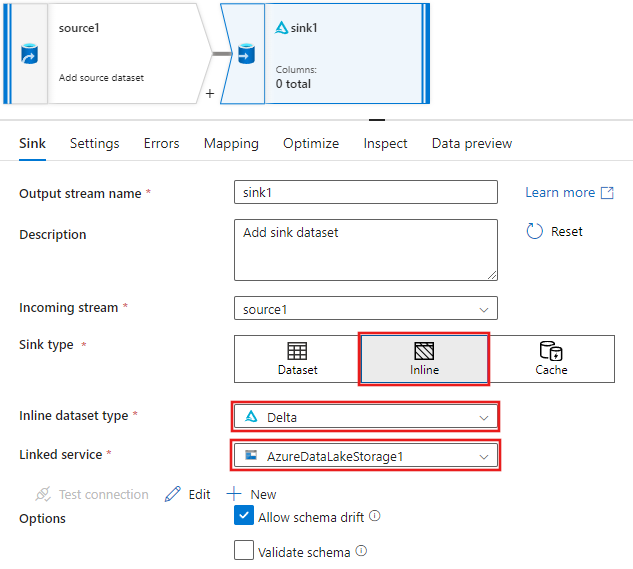
Válasszon egy mappanevet a tárolóban, ahol a szolgáltatás létre szeretné hozni a Delta Lake-t.
Végül lépjen vissza a folyamattervezőhöz, és válassza a Hibakeresés lehetőséget a folyamat hibakeresési módban való végrehajtásához, csak ezzel az adatfolyam-tevékenységgel a vásznon. Ez létrehozza az új Delta Lake-t az Azure Data Lake Storage Gen2-ben.
Most a képernyő bal oldalán található Gyári erőforrások menüben válassza az + új erőforrás hozzáadásához, majd az Adatfolyam lehetőséget.
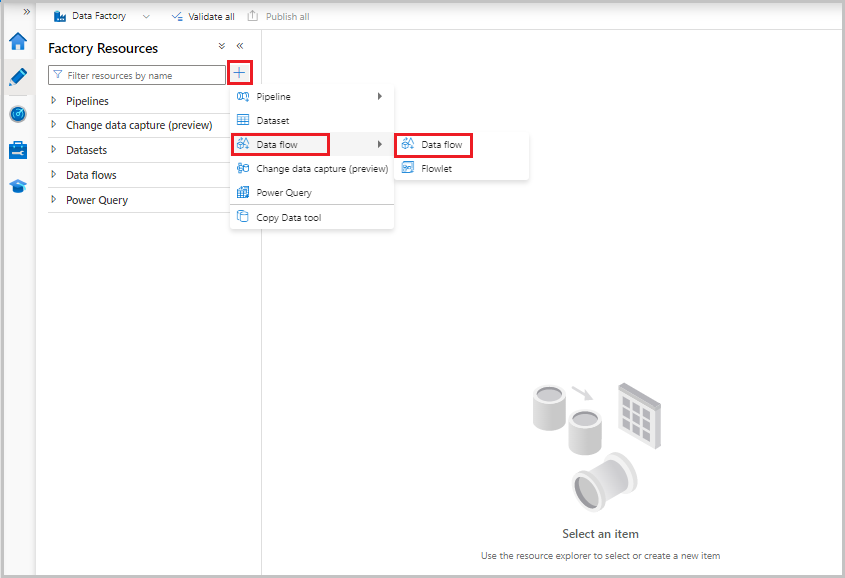
A korábbiakhoz hasonlóan válassza ki ismét a MoviesCSV fájlt forrásként, majd válassza ismét az Adattípusok észlelése lehetőséget a Vetítés lapon.
Ezúttal a forrás létrehozása után jelölje ki az + adatfolyam-szerkesztő ablakát, és adjon hozzá szűrőátalakítást a forráshoz.
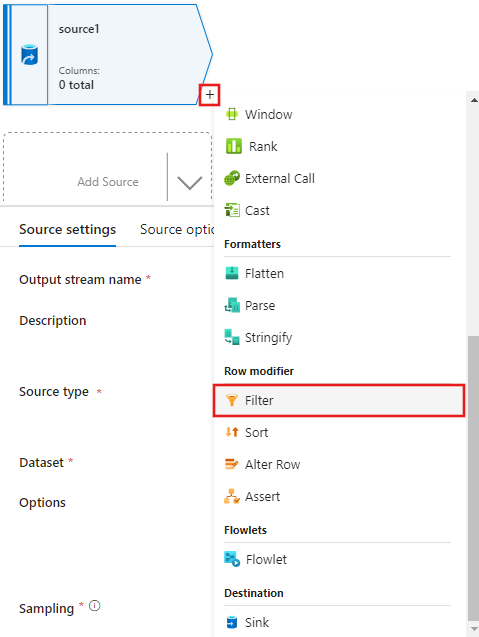
Adjon hozzá egy feltételt a Szűrőbeállítások ablakban, amely csak az 1950-nek, 1960-nak és 1988-nak megfelelő filmsorokat engedélyezi.
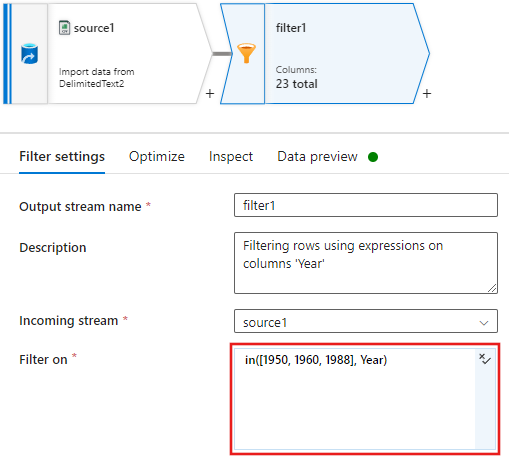
Most adjon hozzá egy származtatott oszlopátalakítást az egyes 1988-filmek minősítéseinek frissítéséhez az "1" értékre.
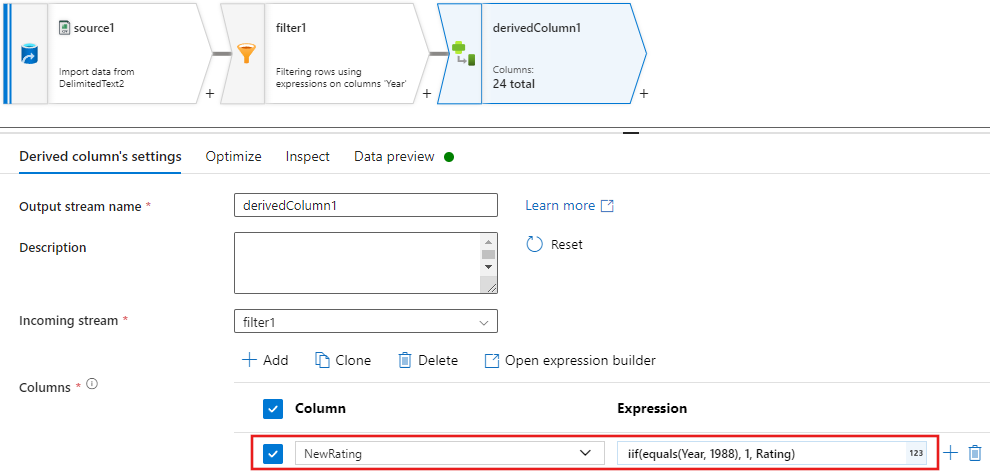
Update, insert, delete, and upserta szabályzatok az alter Row átalakításban jönnek létre. Adjon hozzá egy módosítósor-átalakítást a származtatott oszlop után.Az alter row policies-nek így kell kinéznie.

Most, hogy beállította a megfelelő szabályzatot az egyes váltakozósor-típusokhoz, ellenőrizze, hogy a megfelelő frissítési szabályok be lettek-e állítva a fogadó transzformációján
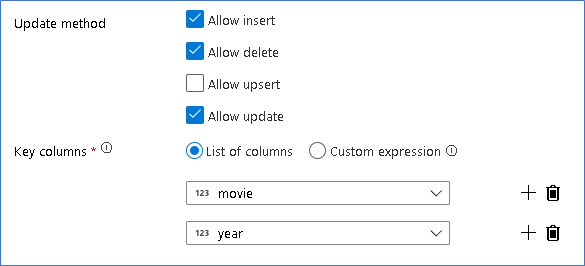
Itt a Delta Lake-fogadót használjuk az Azure Data Lake Storage Gen2 data lake-hez, és lehetővé tesszük a beszúrásokat, frissítéseket és törléseket.
Vegye figyelembe, hogy a kulcsoszlopok a Mozgókép elsődleges kulcs oszlopából és az Év oszlopból álló összetett kulcsok. Ennek az az oka, hogy hamis 2021-filmeket hoztunk létre az 1960-os sorok duplikálásával. Ez az egyediség biztosításával elkerüli az ütközéseket a meglévő sorok keresésekor.
Befejezett minta letöltése
Íme egy mintamegoldás a Delta-folyamathoz egy adatfolyammal a tóban lévő sorok frissítéséhez/törléséhez.
Kapcsolódó tartalom
További információ az adatfolyam-kifejezés nyelvéről.