Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben az oktatóanyagban megtudhatja, hogyan hozhat létre Apache Spark gépi tanulási alkalmazást az Azure HDInsighthoz a Jupyter Notebook használatával.
Az MLlib a Spark adaptálható gépi tanulási kódtára, amely általános tanulási algoritmusokból és segédprogramokból áll. (Besorolás, regresszió, fürtözés, együttműködésen alapuló szűrés és dimenziócsökkentés. Emellett a mögöttes optimalizálási primitívek.)
Ebben az oktatóanyagban az alábbiakkal fog megismerkedni:
- Apache Spark gépi tanulási alkalmazás fejlesztése
Előfeltételek
Apache Spark-fürt megléte a HDInsightban. Lásd: Apache Spark-fürt létrehozása.
A Jupyter-notebookok és a HDInsighton futó Spark használatának ismerete. További információ: Adatok betöltése és lekérdezések futtatása az Apache Spark on HDInsight használatával.
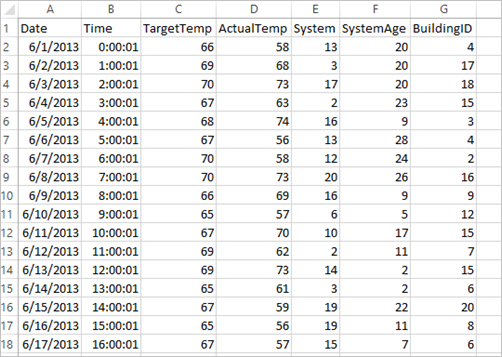
Az adatkészlet értelmezése
Az alkalmazás a HVAC.csv mintaadatokat használja, amelyek alapértelmezésben elérhetők minden klaszteren. A fájl a következő helyen található: \HdiSamples\HdiSamples\SensorSampleData\hvac. Az adatok néhány HVAC-rendszerrel felszerelt épület célhőmérsékletét és jelenlegi hőmérsékletét mutatják. A System (Rendszer) oszlop tartalmazza a rendszer-azonosítót, míg a SystemAge (Rendszer kora) oszlop azt mutatja, hogy az épületben hány éve működik a HVAC-rendszer. Előre jelezheti, hogy egy épület melegebb vagy hidegebb lesz-e a célhőmérséklet, a megadott rendszerazonosító és a rendszer életkora alapján.
Egy Spark Machine Learning-alkalmazás fejlesztése a Spark MLlib segítségével
Ez az alkalmazás Spark ML-folyamatot használ a dokumentumbesorolás elvégzéséhez. Az ML-folyamatok a DataFrame-ekre épülő, magas szintű API-k egységes készletét biztosítják. A DataFrame-ek segítségével a felhasználók gyakorlati gépi tanulási folyamatokat hozhatnak létre és hangolnak. A folyamat során a dokumentumokat szavakra osztja fel, a szavakat átalakítja egy numerikus vektorrá, majd végül a vektorok és címkék alapján létrehoz egy előrejelzési modellt. Az alkalmazás létrehozásához hajtsa végre az alábbi lépéseket.
Jupyter-jegyzetfüzet létrehozása a PySpark kernel használatával. Az utasításokért lásd : Jupyter Notebook-fájl létrehozása.
Importálja a forgatókönyvhöz szükséges típusokat. Illessze be a következő kódrészletet egy üres cellába, majd nyomja le a SHIFT + ENTER billentyűkombinációt.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayTöltse be az adatokat (a hvac.csv fájlból), elemezze őket, és használja fel őket a modellje betanításához.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()A kódrészletben adjon meg egy függvényt, amely összehasonlítja a jelenlegi hőmérsékletet a célhőmérséklettel. Ha a jelenlegi hőmérséklet a magasabb, akkor az épület meleg, ezt az 1.0 érték jelzi. Ellenkező esetben az épület hideg, amit a 0.0 érték jelez.
Konfigurálja a Spark gépi tanulási folyamatot, amely három fázisból áll:
tokenizer,hashingTFéslr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])A folyamatról és annak működéséről további információt az Apache Spark gépi tanulási folyamatában talál.
Igazítsa a folyamatot a betanítási dokumentumhoz.
model = pipeline.fit(training)Ellenőrizze a betanítási dokumentumban az alkalmazás előrehaladási állapotát.
training.show()Az eredmény az alábbihoz hasonlóan fog kinézni:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Hasonlítsa össze a kimenetet a nyers CSV-fájllal. Például a CSV-fájl első sora a következő adatokat tartalmazza:

Figyelje meg, hogy a tényleges hőmérséklet alacsonyabb, mint a célhőmérséklet, ami arra utal, hogy az épület hideg. Az első sorban a címke értéke 0,0, ami azt jelenti, hogy az épület nem meleg.
Készítsen elő egy adathalmazt, amelyen lefuttatja a betanított modellt. Ehhez a rendszerazonosítót és a rendszer életkorát adja át (a betanítási kimenetben SystemInfo-ként jelölve). A modell azt jelzi előre, hogy a rendszerazonosítóval és a rendszer életkorával rendelkező épület melegebb (1,0-val jelölve) vagy hidegebb lesz (0,0-val jelölve).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Végül végezze el az előrejelzést a tesztadatok alapján.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Az eredmény az alábbihoz hasonlóan fog kinézni:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Figyelje meg az előrejelzés első sorát. A 20-as azonosítójú és 25 éves HVAC rendszer esetében az épület forró (előrejelzés=1,0). A DenseVector első értéke (0.49999) a 0.0 előrejelzésnek, a második értéke (0.5001) az 1.0 előrejelzésnek felel meg. A kimenetben – annak ellenére, hogy a második érték csak kicsivel nagyobb – a modell által mutatott előrejelzés: prediction = 1.0.
Állítsa le a laptopot az erőforrások felszabadításához. Ehhez a notebook File (Fájl) menüjében kattintson a Close and Halt (Bezárás és leállítás) elemre. Ez a művelet leállítja és bezárja a notebookot.
Anaconda scikit-learn kódtár használata a Spark Machine Learninghez
A HDInsight-alapú Apache Spark-fürtök Anaconda-kódtárakat tartalmaznak. Ezek közé tartozik a scikit-learn gépi tanulási kódtár. A kódtár különböző adatkészleteket is tartalmaz, amelyekkel közvetlenül a Jupyter Notebookból hozhat létre mintaalkalmazásokat. Példák a scikit-learn kódtár használatára: https://scikit-learn.org/stable/auto_examples/index.html.
Az erőforrások rendbetétele
Ha nem folytatja az alkalmazás használatát, törölje a létrehozott fürtöt az alábbi lépésekkel:
Jelentkezzen be az Azure Portalra.
A felül található Keresőmezőbe írja be a HDInsight parancsot.
Válassza ki a Szolgáltatások között található HDInsight-fürtöket.
A megjelenő HDInsight-fürtök listájában válassza ki az oktatóanyaghoz létrehozott fürt melletti "..." opciót.
Válassza a Törlés lehetőséget. Válassza az Igen lehetőséget.
Következő lépések
Ebben az oktatóanyagban megtanulta, hogyan hozhat létre Apache Spark gépi tanulási alkalmazást az Azure HDInsighthoz a Jupyter Notebook használatával. A következő oktatóanyag azt mutatja be, hogyan használhatja az IntelliJ IDEA-t Spark-feladatokhoz.