Rövid útmutató: Interaktív adatcsongás az Apache Sparkkal az Azure Machine Tanulás
Az interaktív Azure Machine-Tanulás notebookadatok mozgatásának kezeléséhez az Azure Machine Tanulás Integráció az Azure Synapse Analyticsszel egyszerű hozzáférést biztosít az Apache Spark-keretrendszerhez. Ez a hozzáférés lehetővé teszi az Azure Machine Tanulás Notebook interaktív adatmegrendezését.
Ebben a rövid útmutatóban megtudhatja, hogyan végezhet interaktív adatcsongást az Azure Machine Tanulás kiszolgáló nélküli Spark-számítással, az Azure Data Lake Storage (ADLS) Gen 2-es tárfiókjával és a felhasználói identitás átengedésével.
Előfeltételek
- Azure-előfizetés; ha nem rendelkezik Azure-előfizetéssel, hozzon létre egy ingyenes fiókot a kezdés előtt.
- Egy Azure Machine Learning-munkaterület. Látogasson el a Munkaterület erőforrásainak létrehozása webhelyre.
- Egy Azure Data Lake Storage (ADLS) Gen 2-tárfiók. Látogasson el az Azure Data Lake Storage (ADLS) Gen 2-tárfiók létrehozásához.
Az Azure Storage-fiók hitelesítő adatainak tárolása titkos kulcsként az Azure Key Vaultban
Az Azure Storage-fiók hitelesítő adatainak titkos kulcsként való tárolása az Azure Key Vaultban az Azure Portal felhasználói felületével:
Navigáljon az Azure Key Vaulthoz az Azure Portalon
Titkos kulcsok kiválasztása a bal oldali panelen
Válassza a +Létrehozás/Importálás lehetőséget
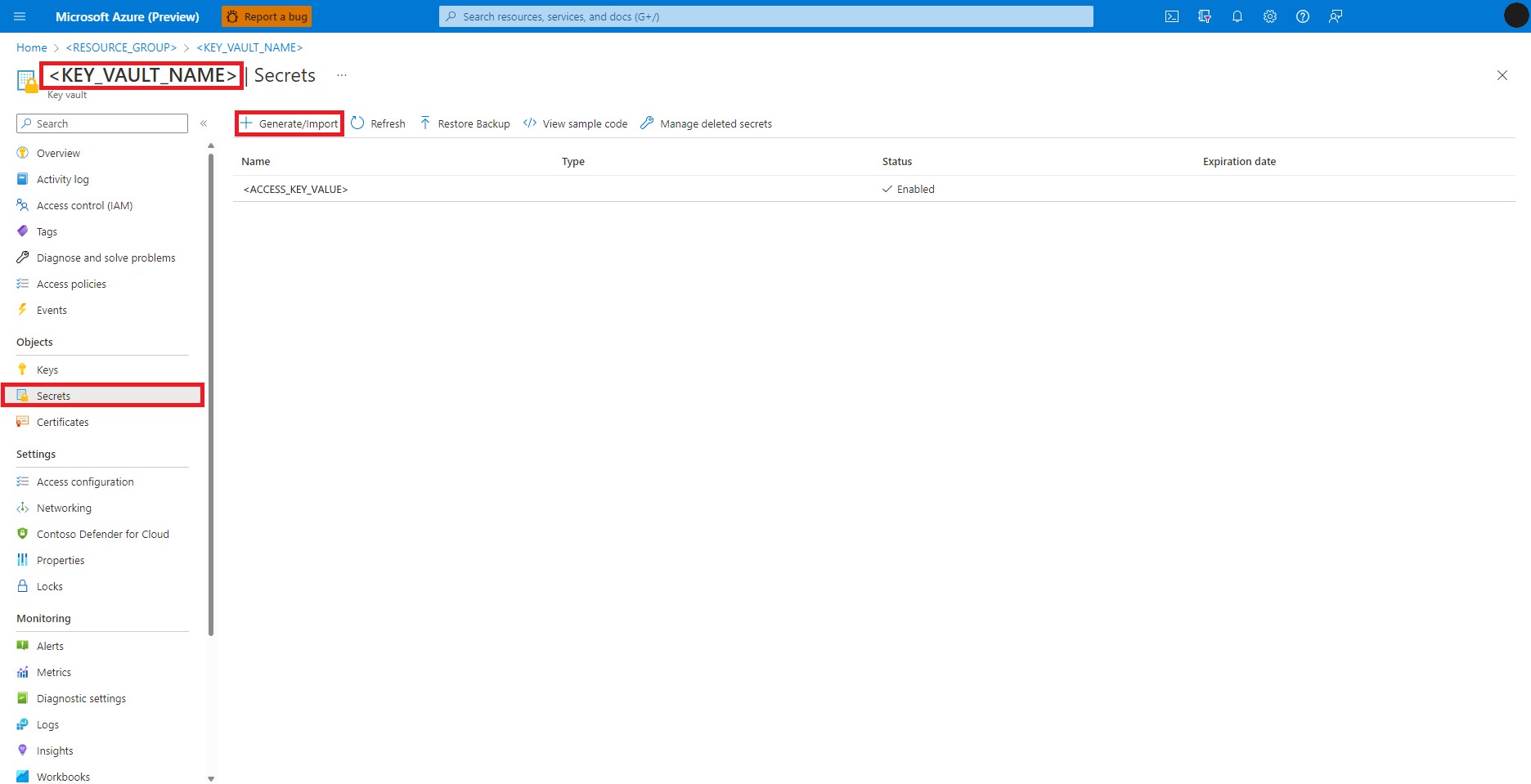
A Titkos kód létrehozása képernyőn adja meg a létrehozni kívánt titkos kód nevét
Navigáljon az Azure Blob Storage-fiókhoz az Azure Portalon az alábbi képen látható módon:
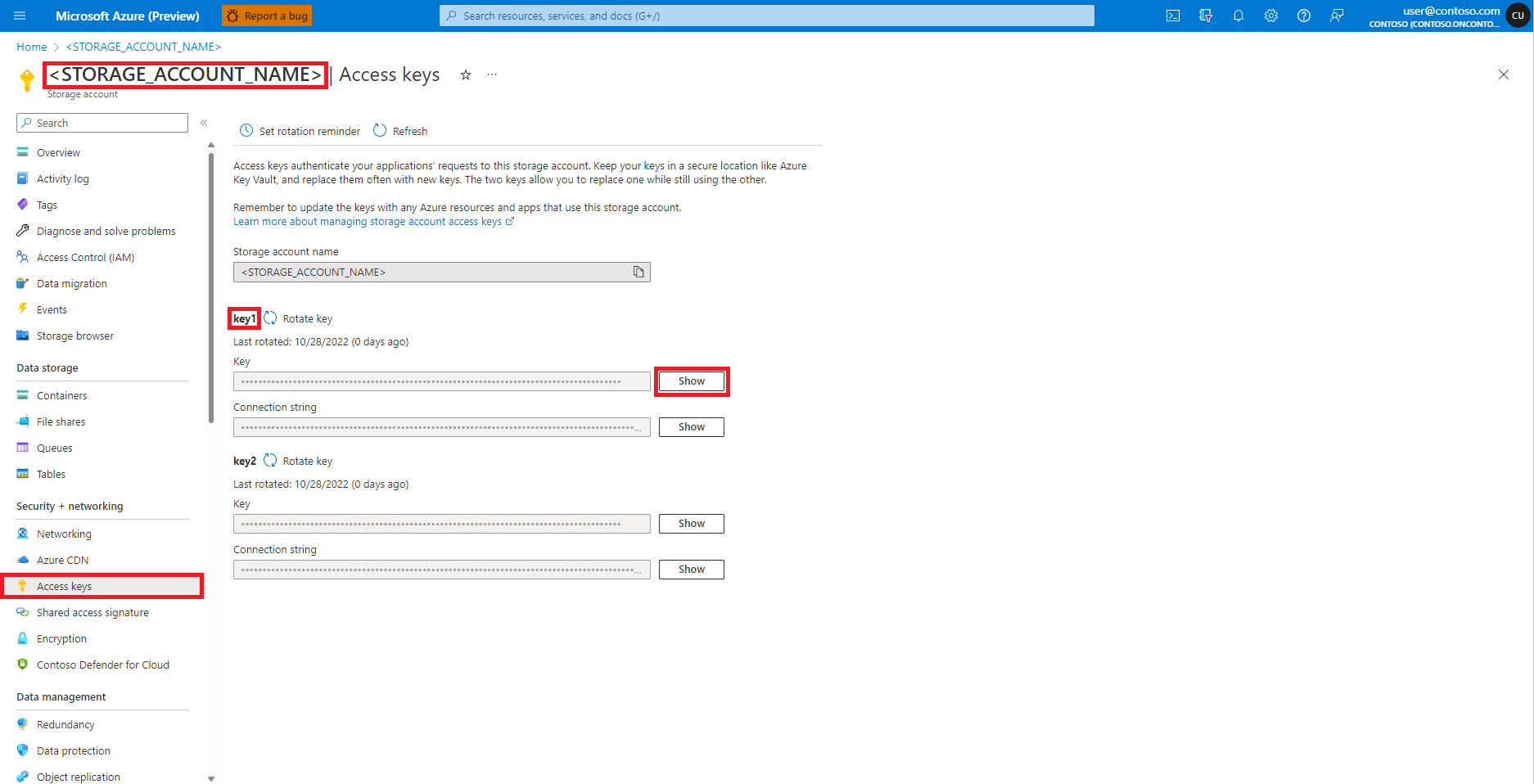
Hozzáférési kulcsok kiválasztása az Azure Blob Storage-fiók bal oldali paneljén
Válassza az 1. kulcs melletti Megjelenítés lehetőséget, majd a Vágólapra másolás lehetőséget a tárfiók hozzáférési kulcsának lekéréséhez
Feljegyzés
Válassza ki a másoláshoz szükséges beállításokat
- Az Azure Blob Storage-tároló megosztott hozzáférésű jogosultságkódjai (SAS) jogkivonatai
- Azure Data Lake Storage (ADLS) 2. generációs tárfiók szolgáltatásnév hitelesítő adatai
- bérlőazonosító
- ügyfélazonosító és
- titkos kód
a megfelelő felhasználói felületeken, miközben létrehozza az Azure Key Vault titkos kulcsait
Lépjen vissza a Titkos kód létrehozása képernyőre
A Titkos érték szövegmezőbe írja be az Azure Storage-fiók hozzáférési kulcsának hitelesítő adatait, amelyet a rendszer a korábbi lépésben a vágólapra másolt
Válassza a Létrehozás elemet
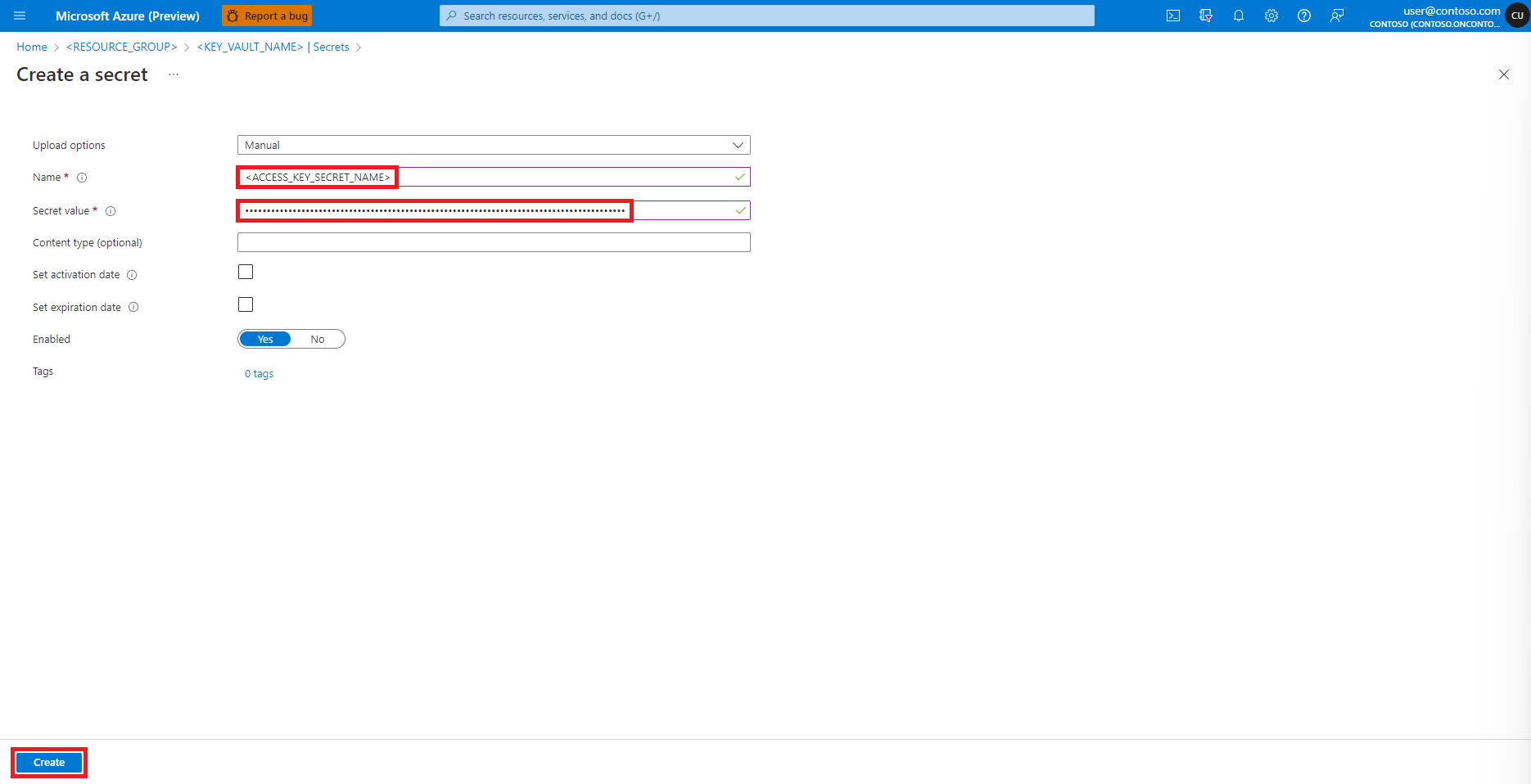
Tipp.
Az Azure CLI és az Azure Key Vault titkos ügyfélkódtára Pythonhoz is létrehozhat Azure Key Vault-titkos kulcsokat.
Szerepkör-hozzárendelések hozzáadása Azure Storage-fiókokban
Meg kell győződnünk arról, hogy a bemeneti és kimeneti adatelérési útvonalak elérhetők, mielőtt interaktív adatmegrendezést kezdünk. Először is:
a jegyzetfüzetek munkamenet bejelentkezett felhasználójának felhasználói identitása
vagy
szolgáltatásnév
Olvasói és tárolási blobadat-olvasó szerepkörök hozzárendelése a bejelentkezett felhasználó felhasználói identitásához. Bizonyos helyzetekben azonban érdemes lehet a wrangled adatokat visszaírni az Azure Storage-fiókba. Az Olvasó és tároló blobadat-olvasó szerepkörök írásvédett hozzáférést biztosítanak a felhasználói identitáshoz vagy szolgáltatásnévhez. Az olvasási és írási hozzáférés engedélyezéséhez rendeljen közreműködői és tárolási blobadat-közreműködői szerepköröket a felhasználói identitáshoz vagy szolgáltatásnévhez. A megfelelő szerepkörök hozzárendelése a felhasználói identitáshoz:
A Tárfiókok szolgáltatás keresése és kiválasztása

A Tárfiókok lapon válassza ki az Azure Data Lake Storage (ADLS) Gen 2. generációs tárfiókot a listából. Megnyílik egy lap, amelyen a tárfiók áttekintése látható
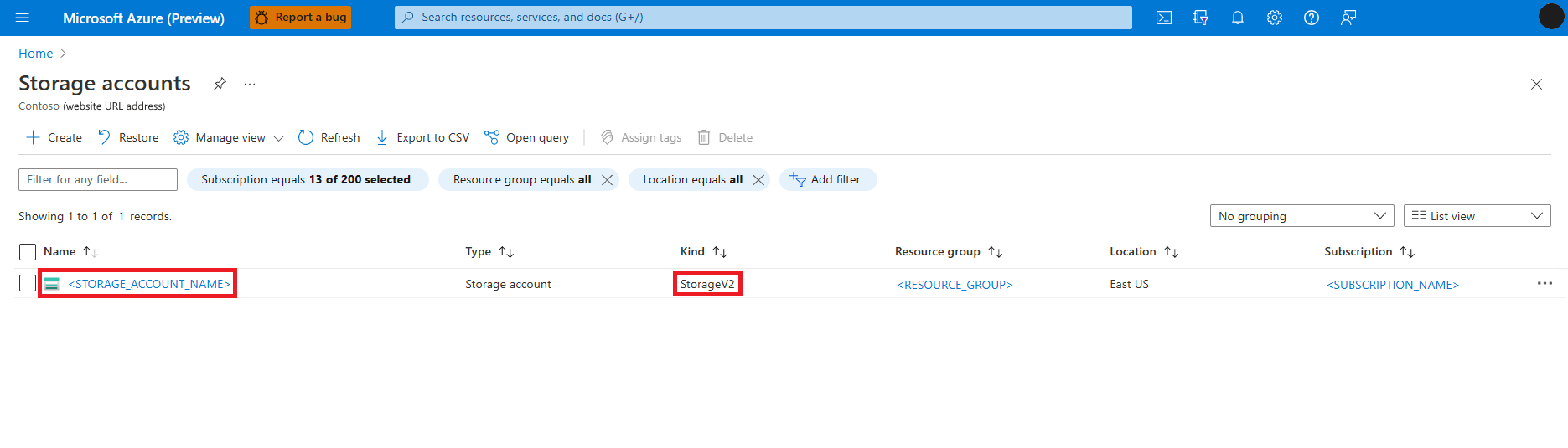
A bal oldali panelen válassza a Hozzáférés-vezérlés (IAM) lehetőséget
Válassza a Szerepkör-hozzárendelés hozzáadása lehetőséget
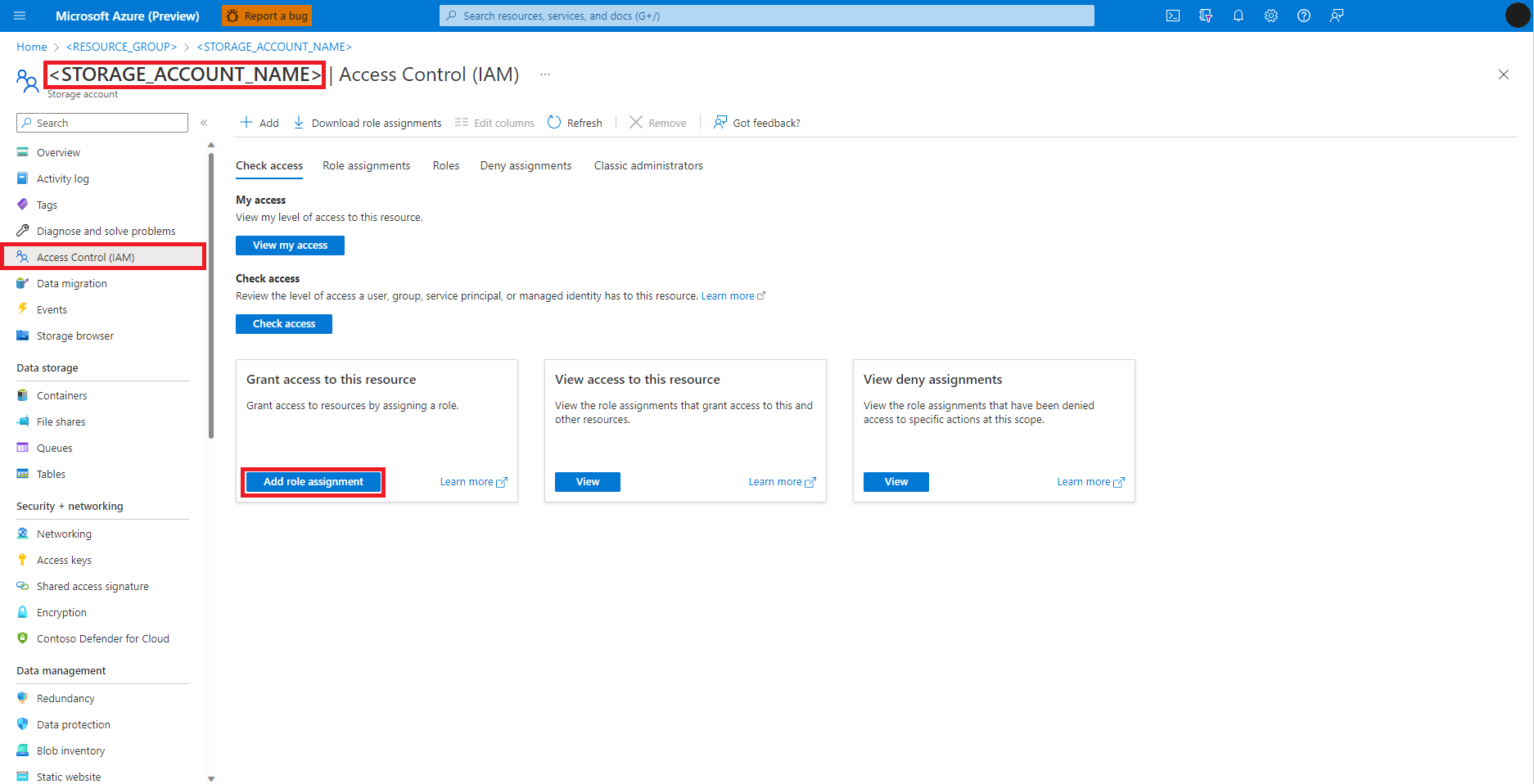
A Storage Blob Data Contributor szerepkör megkeresése és kiválasztása
Válassza a Tovább lehetőséget
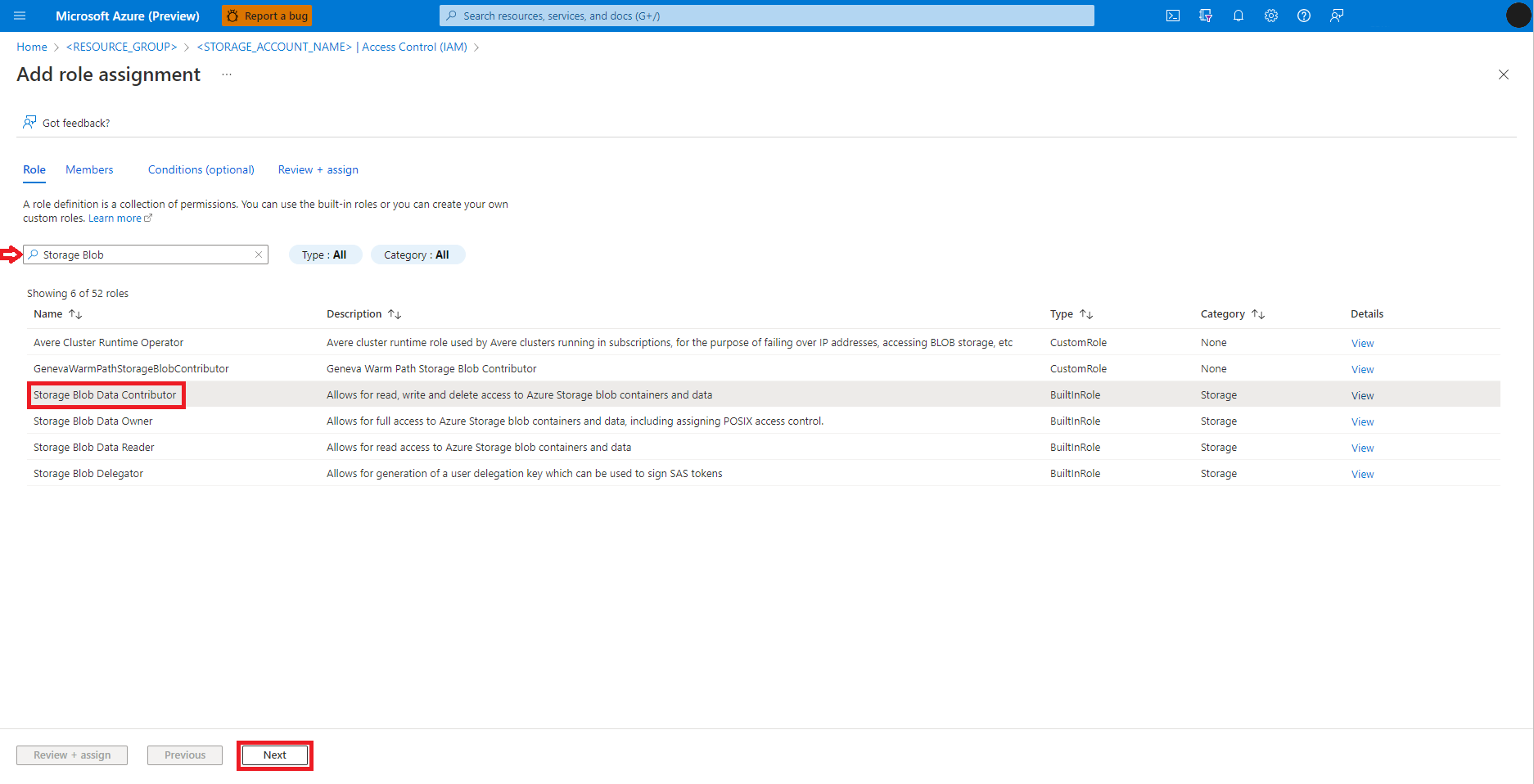
Felhasználó, csoport vagy szolgáltatásnév kiválasztása
Select + Select members
Keresse meg a felhasználói identitást a Select (Kiválasztás) lehetőség alatt
Válassza ki a felhasználói identitást a listából, hogy az a Kijelölt tagok területen jelenik meg
Válassza ki a megfelelő felhasználói identitást
Válassza a Tovább lehetőséget
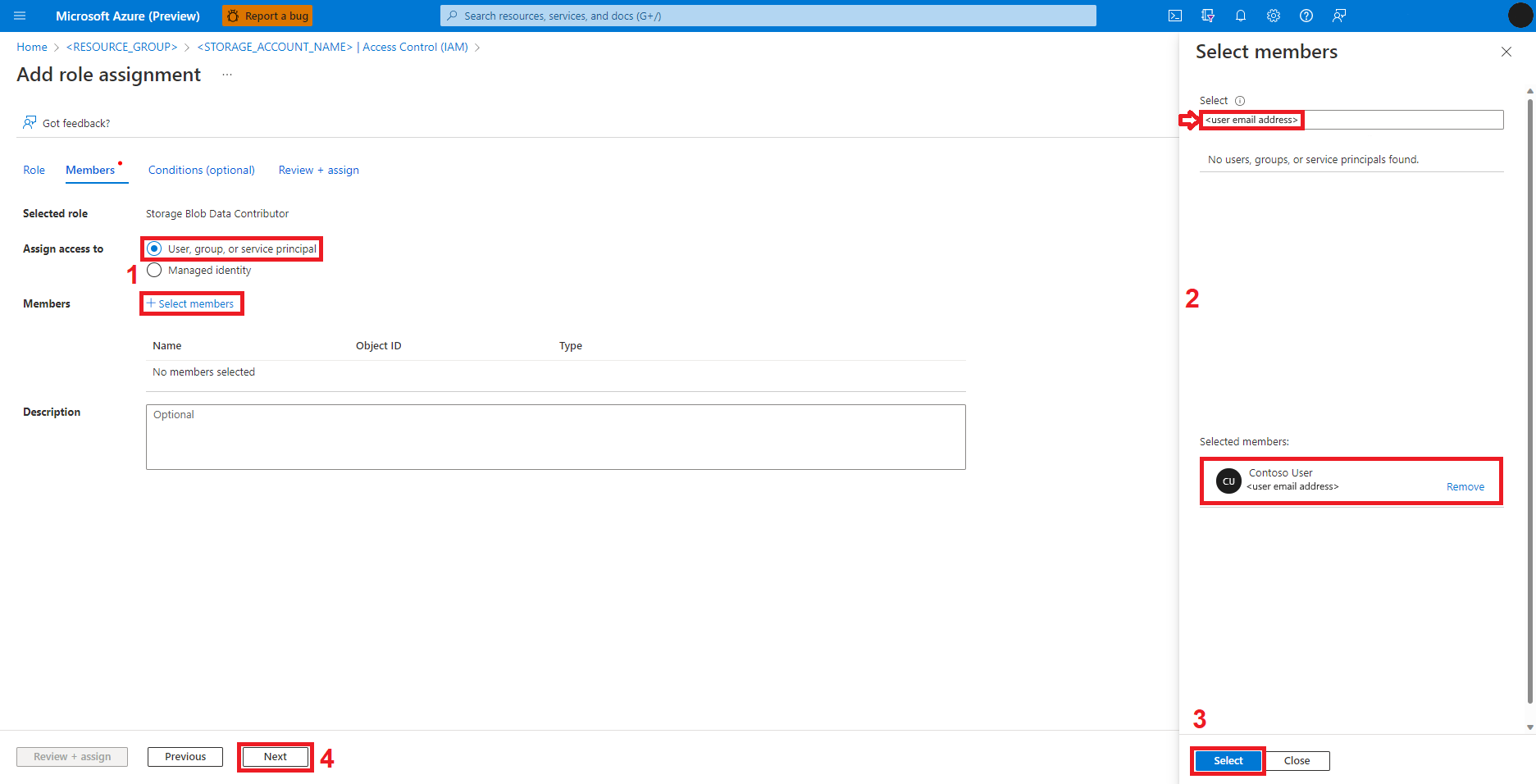
Válassza a Véleményezés + Hozzárendelés lehetőséget
A közreműködői szerepkör-hozzárendelés 2–13. lépésének ismétlése






Miután a felhasználói identitáshoz hozzárendelték a megfelelő szerepköröket, az Azure Storage-fiókban lévő adatoknak elérhetővé kell válniuk.
Feljegyzés
Ha egy csatolt Synapse Spark-készlet egy Synapse Spark-készletre mutat egy Azure Synapse-munkaterületen, amelyhez egy felügyelt virtuális hálózat van társítva, konfigurálnia kell egy felügyelt privát végpontot egy tárfiókra az adathozzáférés biztosítása érdekében.
Erőforrás-hozzáférés biztosítása Spark-feladatokhoz
Az adatok és egyéb erőforrások eléréséhez a Spark-feladatok használhatnak felügyelt identitást vagy felhasználói identitás átengedést. Az alábbi táblázat összefoglalja az erőforrás-hozzáférés különböző mechanizmusait az Azure Machine Tanulás kiszolgáló nélküli Spark-számítás és a csatolt Synapse Spark-készlet használata során.
| Spark-készlet | Támogatott identitások | Alapértelmezett identitás |
|---|---|---|
| Kiszolgáló nélküli Spark-számítás | Felhasználói identitás, a munkaterülethez csatolt, felhasználó által hozzárendelt felügyelt identitás | Felhasználói azonosító |
| Csatolt Synapse Spark-készlet | Felhasználói identitás, a csatolt Synapse Spark-készlethez csatolt felhasználó által hozzárendelt felügyelt identitás, a csatolt Synapse Spark-készlet rendszer által hozzárendelt felügyelt identitása | A csatolt Synapse Spark-készlet rendszer által hozzárendelt felügyelt identitása |
Ha a parancssori felület vagy az SDK-kód definiál egy lehetőséget a felügyelt identitás használatára, az Azure Machine Tanulás kiszolgáló nélküli Spark-számítás a munkaterülethez csatolt, felhasználó által hozzárendelt felügyelt identitásra támaszkodik. Felhasználó által hozzárendelt felügyelt identitást csatolhat egy meglévő Azure Machine Tanulás-munkaterülethez az Azure Machine Tanulás CLI 2-vel vagy a ARMClient.
Következő lépések
- Apache Spark az Azure Machine Tanulás
- Synapse Spark-készlet csatolása és kezelése az Azure Machine Tanulás
- Interaktív adatkonvergálás az Apache Sparkkal az Azure Machine-Tanulás
- Spark-feladatok küldése az Azure Machine Tanulás
- Kódminták Spark-feladatokhoz az Azure Machine Tanulás parancssori felületével
- Kódminták Spark-feladatokhoz az Azure Machine Tanulás Python SDK használatával