Modell online végponton történő üzembe helyezése egyéni tároló használatával
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Megtudhatja, hogyan helyezhet üzembe egy modellt egy online végponton az Azure Machine Learningben egyéni tároló használatával.
Az egyéni tárolótelepítések az Azure Machine Learning által használt alapértelmezett Python Flask-kiszolgálótól eltérő webkiszolgálókat is használhatnak. Ezen üzemelő példányok felhasználói továbbra is kihasználhatják az Azure Machine Learning beépített monitorozási, skálázási, riasztási és hitelesítési előnyeit.
Az alábbi táblázat olyan egyéni tárolókat használó üzembe helyezési példákat sorol fel, mint a TensorFlow-kiszolgáló, a TorchServe, a Triton Inference Server, a Plumber R-csomag és az Azure Machine Learning Következtetés minimális rendszerképe.
| Példa | Szkript (CLI) | Leírás |
|---|---|---|
| minimális/többmodelles | deploy-custom-container-minimal-multimodel | Több modell üzembe helyezése egyetlen üzembe helyezéshez az Azure Machine Learning Következtetés minimális rendszerképének kibővítésével. |
| minimális/egymodelles | deploy-custom-container-minimal-single-model | Egyetlen modell üzembe helyezése az Azure Machine Learning Következtetés minimális rendszerképének kibővítésével. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Helyezzen üzembe két különböző Python-követelményeket tartalmazó MLFlow-modellt két különálló üzembe helyezésre egyetlen végpont mögött az Azure Machine Learning Következtetés minimális rendszerképének használatával. |
| r/többmodelles vízvezeték-szerelő | deploy-custom-container-r-multimodel-plumber | Három regressziós modell üzembe helyezése egy végponton a Plumber R csomag használatával |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Egy Half Plus Két modell üzembe helyezése egyéni TensorFlow-tárolóval a standard modellregisztrációs folyamattal. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Egy Half Plus Two modell üzembe helyezése egy Egyéni TensorFlow-tároló használatával a modell képbe integrált használatával. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Egyetlen modell üzembe helyezése egyéni TorchServe-tárolóval. |
| triton/egymodell | deploy-custom-container-triton-single-model | Triton-modell üzembe helyezése egyéni tároló használatával |
Ez a cikk egy TensorFlow-modell és a TensorFlow (TF) szolgáltatással való kiszolgálására összpontosít.
Figyelmeztetés
Előfordulhat, hogy a Microsoft nem tud segíteni az egyéni rendszerképek által okozott problémák elhárításában. Ha problémákat tapasztal, előfordulhat, hogy az alapértelmezett rendszerkép vagy a Microsoft által biztosított képek egyikének használatával állapítja meg, hogy a probléma az Ön képére vonatkozik-e.
Előfeltételek
A cikkben ismertetett lépések végrehajtása előtt győződjön meg arról, hogy rendelkezik a következő előfeltételekkel:
Egy Azure Machine Learning-munkaterület. Ha nincs ilyenje, a gyorsútmutató lépéseit követve hozzon létre egyet a munkaterület erőforrásainak létrehozása című cikkben.
Az Azure CLI és a
mlbővítmény vagy az Azure Machine Learning Python SDK v2:Az Azure CLI és a bővítmény telepítéséhez lásd a parancssori felület (v2) telepítését, beállítását és használatát.
Fontos
A jelen cikkben szereplő CLI-példák feltételezik, hogy a Bash (vagy kompatibilis) rendszerhéjat használja. Például linuxos rendszerből vagy Linuxos Windows-alrendszer.
A Python SDK v2 telepítéséhez használja a következő parancsot:
pip install azure-ai-ml azure-identityHa frissíteni szeretné az SDK meglévő telepítését a legújabb verzióra, használja a következő parancsot:
pip install --upgrade azure-ai-ml azure-identityTovábbi információ: Az Azure Machine Learninghez készült Python SDK v2 telepítése.
Önnek vagy a használt szolgáltatásnévnek közreműködői hozzáféréssel kell rendelkeznie a munkaterületet tartalmazó Azure-erőforráscsoporthoz. Ilyen erőforráscsoporttal rendelkezik, ha a gyorsútmutató-cikk használatával konfigurálta a munkaterületet.
A helyi üzembe helyezéshez helyileg kell futtatnia a Docker-motort . Ez a lépés erősen ajánlott. Segít a hibák hibakeresésében.
Forráskód letöltése
Az oktatóanyagot követve klónozza a forráskódot a GitHubról.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Környezeti változók inicializálása
Környezeti változók definiálása:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
TensorFlow-modell letöltése
Töltse le és bontsa ki azt a modellt, amely két bemenettel osztja el a bemenetet, és 2-et ad hozzá az eredményhez:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
TF-kiszolgáló lemezképének helyi futtatása annak ellenőrzéséhez, hogy működik-e
A docker használatával helyileg futtathatja a rendszerképet teszteléshez:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Ellenőrizze, hogy küldhet-e élősséget és pontozási kéréseket a képre
Először ellenőrizze, hogy a tároló életben van-e, ami azt jelenti, hogy a tárolón belüli folyamat továbbra is fut. 200 (OK) választ kell kapnia.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Ezután ellenőrizze, hogy kaphat-e előrejelzéseket a címkézetlen adatokról:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
A kép leállítása
Most, hogy helyileg tesztelt, állítsa le a képet:
docker stop tfserving-test
Az online végpont üzembe helyezése az Azure-ban
Ezután helyezze üzembe az online végpontot az Azure-ban.
YAML-fájl létrehozása a végponthoz és az üzembe helyezéshez
A felhőbeli üzembe helyezést a YAML használatával konfigurálhatja. Tekintse meg a példához tartozó YAML-mintát:
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Ebben a YAML/Python-paraméterben néhány fontos fogalmat érdemes figyelembe venni:
Alaprendszerkép
Az alaprendszerkép paraméterként van megadva a környezetben, és docker.io/tensorflow/serving:latest ebben a példában használatos. A tároló vizsgálata során láthatja, hogy ez a kiszolgáló egy belépési pont szkriptjének elindítására használja ENTRYPOINT , amely felveszi az olyan környezeti változókat, mint MODEL_BASE_PATH például az és MODEL_NAME, és elérhetővé teszi az olyan portokat, mint a 8501. Ezek a részletek a kiválasztott kiszolgáló összes konkrét információi. A kiszolgáló ezen ismerete alapján meghatározhatja az üzemelő példány definiálását. Ha például környezeti változókat MODEL_BASE_PATH állít be az üzembehelyezési definícióhoz és MODEL_NAME a környezet definíciójában, a kiszolgáló (ebben az esetben a TF-kiszolgáló) a kiszolgáló indításához veszi az értékeket. Hasonlóképpen, ha beállítja az útvonalak 8501 portját az üzembehelyezési definícióban, a rendszer helyesen irányítja az ilyen útvonalakra irányuló felhasználói kérést a TF kiszolgálóra.
Vegye figyelembe, hogy ez a konkrét példa a TF-kiszolgálói eseten alapul, de bármilyen tárolót használhat, amely továbbra is naprakész marad, és válaszol az élethez, a felkészültséghez és a pontozási útvonalakhoz érkező kérésekre. További példákra is hivatkozhat, és megtekintheti, hogyan jön létre a dockerfile (például ahelyettENTRYPOINT), CMD hogy létrehozza a tárolókat.
Következtetés konfigurációja
A következtetési konfiguráció egy paraméter a környezetben, és az útvonal 3 típusának portját és elérési útját adja meg: az élőképességet, a készültséget és a pontozási útvonalat. Következtetési konfigurációra van szükség, ha saját tárolót szeretne futtatni felügyelt online végponttal.
Készültségi útvonal és élőség útvonala
A választott API-kiszolgáló módot biztosíthat a kiszolgáló állapotának ellenőrzésére. Az útvonalnak két típusa van: az élőség és a felkészültség. A rendszer egy élőségi útvonalat használ annak ellenőrzésére, hogy a kiszolgáló fut-e. A rendszer készenléti útvonalat használ annak ellenőrzésére, hogy a kiszolgáló készen áll-e a munkára. A gépi tanulási következtetés kontextusában a kiszolgáló a modell betöltése előtt 200 OK-ra válaszolhatott egy élességi kérelemre, a kiszolgáló pedig csak a modell memóriába való betöltése után tudott válaszolni a 200 OK-ra.
Az élettel és a készültségi mintavételekkel kapcsolatos további információkért tekintse meg a Kubernetes dokumentációját.
Az élettartamot és a készültségi útvonalakat az Ön által választott API-kiszolgáló határozza meg, amint azt a tároló helyi tesztelésekor azonosította volna a korábbi lépésben. Vegye figyelembe, hogy a cikkben szereplő példatelepítés ugyanazt az útvonalat használja mind az élőség, mind a felkészültség szempontjából, mivel a TF-kiszolgáló csak egy élőségi útvonalat határoz meg. Az útvonalak meghatározásához tekintse meg a különböző mintákra vonatkozó egyéb példákat.
Pontozási útvonal
A választott API-kiszolgáló módot adna a hasznos adatok fogadására, hogy működjenek. A gépi tanulási következtetés kontextusában a kiszolgáló egy adott útvonalon kapja meg a bemeneti adatokat. Azonosítsa ezt az útvonalat az API-kiszolgálóhoz, amikor a tárolót helyileg teszteli a korábbi lépésben, és adja meg, amikor meghatározza a létrehozandó üzembe helyezést.
Vegye figyelembe, hogy az üzembe helyezés sikeres létrehozása a végpont scoring_uri paraméterét is frissíti, amelyet ellenőrizheti az ml online-endpoint show -n <name> --query scoring_uri.
A csatlakoztatott modell keresése
Amikor online végpontként helyez üzembe egy modellt, az Azure Machine Learning csatlakoztatja a modellt a végponthoz. A modell csatlakoztatása lehetővé teszi a modell új verzióinak üzembe helyezését anélkül, hogy új Docker-lemezképet kellene létrehoznia. Alapértelmezés szerint a foo névvel és az 1. verzióval regisztrált modell a következő elérési úton található az üzembe helyezett tárolóban: /var/azureml-app/azureml-models/foo/1
Ha például a /azureml-examples/cli/endpoints/online/custom-container könyvtárstruktúrája van a helyi gépen, ahol a modell neve half_plus_two:
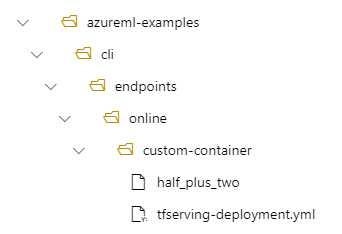
És tfserving-deployment.yml a következőket tartalmazza:
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Ezután a modell a /var/azureml-app/azureml-models/tfserving-deployment/1 területen található az üzembe helyezés során:
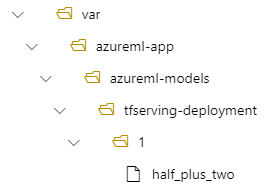
Igény szerint konfigurálhatja a .model_mount_path Lehetővé teszi a modell csatlakoztatási útvonalának módosítását.
Fontos
Az model_mount_path elérési útnak érvényes abszolút elérési útnak kell lennie Linuxon (a tárolórendszerkép operációs rendszerének).
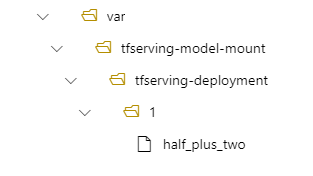
Például rendelkezhet model_mount_path paramétert a tfserving-deployment.yml:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
Ezután a modell a /var/tfserving-model-mount/tfserving-deployment/1 helyen található az üzembe helyezésben. Vegye figyelembe, hogy már nem az azureml-app/azureml-models alatt van, hanem a megadott csatlakoztatási útvonal alatt:
A végpont és az üzembe helyezés létrehozása
Most, hogy megismerte a YAML létrehozásának módját, hozza létre a végpontot.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
Az üzembe helyezés létrehozása eltarthat néhány percig.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
A végpont meghívása
Az üzembe helyezés befejezése után ellenőrizze, hogy tud-e pontozási kérelmet küldeni az üzembe helyezett végpontra.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
A végpont törlése
Most, hogy sikeresen pontszámot szerzett a végponttal, törölheti azt: