TensorFlow-modellek nagy léptékű betanítása az Azure Machine Learning használatával
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azure-ai-ml v2 (aktuális)
Python SDK azure-ai-ml v2 (aktuális)
Ebből a cikkből megtudhatja, hogyan futtathatja a TensorFlow-betanítási szkripteket nagy méretekben az Azure Machine Learning Python SDK 2-es verzióval.
A cikkben szereplő példakód betanít egy TensorFlow-modellt a kézzel írt számjegyek besorolására egy mély neurális hálózat (DNN) használatával; a modell regisztrálása; és üzembe helyezheti egy online végponton.
Akár az alapoktól fejleszt TensorFlow-modellt, akár meglévő modellt hoz a felhőbe, az Azure Machine Learning használatával rugalmas felhőbeli számítási erőforrások használatával skálázhatja fel a nyílt forráskódú betanítási feladatokat. Az Azure Machine Learning használatával éles üzemű modelleket hozhat létre, helyezhet üzembe, futtathat és monitorozhat.
Előfeltételek
A cikk előnyeinek kihasználásához a következőkre van szükség:
- Azure-előfizetés elérése. Ha még nem rendelkezik ilyen fiókkal, hozzon létre egy ingyenes fiókot.
- Futtassa a jelen cikkben szereplő kódot egy Azure Machine Learning számítási példány vagy egy saját Jupyter-notebook használatával.
- Azure Machine Learning számítási példány – nincs szükség letöltésre vagy telepítésre
- Az első lépésekhez végezze el az Erőforrások létrehozása oktatóanyagot, amely egy dedikált, az SDK-val és a mintaadattárral előre betöltött jegyzetfüzet-kiszolgálót hoz létre.
- A jegyzetfüzet-kiszolgáló mintái mélytanulási mappájában keressen egy befejezett és bővített jegyzetfüzetet a következő könyvtárra navigálva: v2 > sdk > Python-feladatok > > egylépéses > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- A Jupyter notebook-kiszolgálója
- Azure Machine Learning számítási példány – nincs szükség letöltésre vagy telepítésre
- Töltse le a következő fájlokat:
- betanítási szkript tf_mnist.py
- pontozási szkript score.py
- mintakérési fájl sample-request.json
Az útmutató egy kész Jupyter Notebook-verzióját is megtalálhatja a GitHub-minták oldalán.
Ahhoz, hogy a cikkben szereplő kód futtatásával GPU-fürtöt hozzon létre, kvótanövelést kell kérnie a munkaterülethez.
A feladat beállítása
Ez a szakasz betanításra állítja be a feladatot a szükséges Python-csomagok betöltésével, a munkaterülethez való csatlakozással, egy számítási erőforrás létrehozásával egy parancsfeladat futtatásához, valamint a feladat futtatásához szükséges környezet létrehozásával.
Csatlakozás a munkaterülethez
Először csatlakoznia kell az Azure Machine Learning-munkaterülethez. Az Azure Machine Learning-munkaterület a szolgáltatás legfelső szintű erőforrása. Központosított helyet biztosít az Azure Machine Learning használatakor létrehozott összes összetevővel való munkához.
A munkaterülethez való hozzáférést használjuk DefaultAzureCredential . Ennek a hitelesítő adatnak képesnek kell lennie a legtöbb Azure SDK-hitelesítési forgatókönyv kezelésére.
Ha DefaultAzureCredential nem működik az Ön számára, tekintse meg azure-identity reference documentation vagy Set up authentication keresse meg a további elérhető hitelesítő adatokat.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Ha inkább böngészőt használ a bejelentkezéshez és a hitelesítéshez, törölje a következő kódot, és használja helyette.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Ezután szerezze be a munkaterület leíróját az előfizetés azonosítójának, az erőforráscsoport nevének és a munkaterület nevének megadásával. A paraméterek megkeresése:
- Keresse meg a munkaterület nevét az Azure Machine Learning Studio eszköztárának jobb felső sarkában.
- Válassza ki a munkaterület nevét az erőforráscsoport és az előfizetés azonosítójának megjelenítéséhez.
- Másolja az erőforráscsoport és az előfizetés azonosítójának értékeit a kódba.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)A szkript futtatásának eredménye egy munkaterületi leíró, amellyel más erőforrásokat és feladatokat kezelhet.
Feljegyzés
- A létrehozás
MLClientnem fogja csatlakoztatni az ügyfelet a munkaterülethez. Az ügyfél inicializálása lusta, és az első alkalommal vár, amikor hívást kell kezdeményeznie. Ebben a cikkben ez a számítás létrehozása során fog történni.
Számítási erőforrás létrehozása
Az Azure Machine Learningnek számítási erőforrásra van szüksége egy feladat futtatásához. Ez az erőforrás lehet egy- vagy többcsomópontos gép Linux vagy Windows operációs rendszerrel, vagy egy adott számítási háló, például a Spark.
A következő példaszkriptben kiépítünk egy Linuxot compute cluster. A virtuális gépek méreteinek és árainak teljes listáját tartalmazó oldal látható Azure Machine Learning pricing . Mivel ehhez a példához GPU-fürtre van szükségünk, válasszunk egy STANDARD_NC6 modellt, és hozzunk létre egy Azure Machine Learning-számítást.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Feladatkörnyezet létrehozása
Azure Machine Learning-feladat futtatásához környezetre van szükség. Az Azure Machine Learning-környezet magában foglalja a számítógép-tanulási betanítási szkript számítási erőforráson való futtatásához szükséges függőségeket (például szoftveres futtatókörnyezetet és kódtárakat). Ez a környezet hasonló a helyi gépen lévő Python-környezethez.
Az Azure Machine Learning lehetővé teszi, hogy válogatott (vagy kész) környezetet használjon – amely általános betanítási és következtetési forgatókönyvekhez hasznos –, vagy egyéni környezetet hozhat létre Docker-rendszerkép vagy Conda-konfiguráció használatával.
Ebben a cikkben újra felhasználja a válogatott Azure Machine Learning-környezetet AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu. A környezet legújabb verzióját használja az @latest irányelv használatával.
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"A betanítási feladat konfigurálása és elküldése
Ebben a szakaszban a betanításhoz szükséges adatok bevezetésével kezdjük. Ezután bemutatjuk, hogyan futtathat egy betanítási feladatot egy általunk biztosított betanítási szkripttel. A betanítási feladat összeállításához konfigurálja a betanítási szkript futtatására szolgáló parancsot. Ezután beküldi a betanítási feladatot az Azure Machine Learningben való futtatáshoz.
A betanítási adatok beszerzése
A kézzel írt számjegyek módosított Nemzeti Szabványügyi és Technológiai Intézetének (MNIST) adatbázisából származó adatokat fogja használni. Ezek az adatok Yan LeCun webhelyéről származnak, és egy Azure-tárfiókban találhatók.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Az MNIST-adatkészletről a Yan LeCun webhelyén talál további információt.
A betanítási szkript előkészítése
Ebben a cikkben a betanítási szkriptet tf_mnist.py. A gyakorlatban képesnek kell lennie bármilyen egyéni betanítási szkriptet használni, és anélkül futtatni az Azure Machine Learningben, hogy módosítania kellene a kódot.
A megadott betanítási szkript a következőket teszi:
- kezeli az adatok előfeldolgozását, az adatok tesztelésre és betanításra való felosztását;
- modell betanítása az adatok használatával; és
- A kimeneti modellt adja vissza.
A folyamat futtatása során az MLFlow használatával naplózza a paramétereket és a metrikákat. Az MLFlow nyomon követésének engedélyezéséről az ML-kísérletek és modellek nyomon követése az MLflow-nal című témakörben olvashat.
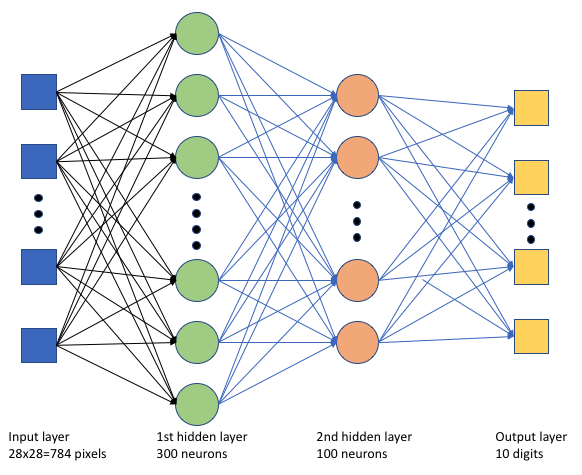
A betanítási szkriptben tf_mnist.pylétrehozunk egy egyszerű mély neurális hálózatot (DNN). Ez a DNN a következő:
- Egy bemeneti réteg 28 * 28 = 784 neuronokkal. Minden neuron egy kép képpontot jelöl.
- Két rejtett réteg. Az első rejtett réteg 300 neuron, a második rejtett réteg 100 neuron.
- Egy kimeneti réteg 10 neuronnal. Minden neuron egy célzott címkét jelöl 0 és 9 között.
A betanítási feladat létrehozása
Most, hogy rendelkezik a feladat futtatásához szükséges összes eszközzel, itt az ideje, hogy az Azure Machine Learning Python SDK 2-s v2 használatával hozza létre. Ebben a példában létrehozunk egy command.
Az Azure Machine Learning command egy erőforrás, amely megadja a betanítási kód felhőben való végrehajtásához szükséges összes részletet. Ezek a részletek tartalmazzák a bemeneteket és kimeneteket, a használandó hardver típusát, a telepíteni kívánt szoftvereket és a kód futtatásának módját. A command parancsok végrehajtásához szükséges információkat tartalmazza.
A parancs konfigurálása
Az általános célt command használja a betanítási szkript futtatására és a kívánt feladatok végrehajtására. Hozzon létre egy objektumot Command a betanítási feladat konfigurációs adatainak megadásához.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)A parancs bemenetei közé tartozik az adatok helye, a köteg mérete, az első és a második réteg neuronjainak száma és a tanulási sebesség. Figyelje meg, hogy közvetlenül bemenetként haladtunk át a webes elérési úton.
A paraméterértékek esetében:
- adja meg a parancs futtatásához létrehozott számítási fürtöt
gpu_compute_target = "gpu-cluster"; - adja meg a korábban deklarált válogatott környezetet
curated_env_name; - konfigurálja magát a parancssori műveletet – ebben az esetben a parancs a következő
python tf_mnist.py: . A parancs bemeneteit és kimeneteit a${{ ... }}jelölésen keresztül érheti el; és - konfigurálja a metaadatokat, például a megjelenítendő nevet és a kísérlet nevét; ahol egy kísérlet egy tároló egy adott projekten végzett összes iterációhoz. Az azonos kísérletnévvel elküldött összes feladat egymás mellett szerepelne az Azure Machine Learning Studióban.
- adja meg a parancs futtatásához létrehozott számítási fürtöt
Ebben a példában a
UserIdentityparancs futtatásához használja a parancsot. A felhasználói identitás használata azt jelenti, hogy a parancs az ön identitásával futtatja a feladatot, és hozzáfér az adatokhoz a blobból.
Feladat küldése
Itt az ideje, hogy elküldje a feladatot az Azure Machine Learningben való futtatáshoz. Ezúttal a következőt ml_client.jobsfogja használnicreate_or_update: .
ml_client.jobs.create_or_update(job)Miután végzett, a feladat regisztrál egy modellt a munkaterületen (a betanítás eredményeként), és egy hivatkozást ad ki a feladat Azure Machine Learning Studióban való megtekintéséhez.
Figyelmeztetés
Az Azure Machine Learning a teljes forráskönyvtár másolásával futtat betanítási szkripteket. Ha olyan bizalmas adatokkal rendelkezik, amelyeket nem szeretne feltölteni, használjon .ignore fájlt , vagy ne vegye fel azokat a forráskönyvtárba.
Mi történik a feladat végrehajtása során?
A feladat végrehajtása során a következő szakaszokon megy keresztül:
Előkészítés: A rendszer létrehoz egy Docker-rendszerképet a megadott környezetnek megfelelően. A rendszerképet a rendszer feltölti a munkaterület tárolóregisztrációs adatbázisára, és gyorsítótárazza a későbbi futtatásokhoz. A naplók a feladatelőzményekbe is streamelhetők, és megtekinthetők a folyamat figyeléséhez. Ha egy válogatott környezet van megadva, a rendszer a gyorsítótárazott rendszerképet fogja használni a válogatott környezethez.
Skálázás: A fürt megkísérli a vertikális felskálázást, ha a futtatás végrehajtásához több csomópontra van szükség, mint amennyi jelenleg elérhető.
Futtatás: A szkriptmappa src összes szkriptje fel lesz töltve a számítási célba, az adattárak csatlakoztatva vannak vagy másolódnak, és a szkript végrehajtása megtörténik. Az stdout és a ./logs mappa kimenetei a feladatelőzményekbe kerülnek, és a feladat figyelésére használhatók.
Modell hiperparamétereinek finomhangolása
Most, hogy megismerte, hogyan futtathat TensorFlow-betanítást az SDK használatával, nézzük meg, hogy tovább javíthatja-e a modell pontosságát. Az Azure Machine Learning képességeivel hangolhatja és optimalizálhatja a modell hiperparamétereit sweep .
A modell hiperparamétereinek finomhangolásához adja meg azt a paraméterteret, amelyben a betanítás során keresni szeretne. Ezt úgy teheti meg, hogy lecseréli a betanítási feladatnak átadott paraméterek egy részét (batch_size, first_layer_neuronsés second_layer_neuronslearning_rate) a azure.ml.sweep csomag speciális bemeneteivel.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Ezután konfigurálja a takarítást a parancsfeladaton bizonyos, takarításra vonatkozó paraméterekkel, például a figyelendő elsődleges metrikával és a használandó mintavételezési algoritmussal.
Az alábbi kódban véletlenszerű mintavételezést használunk a hiperparaméterek különböző konfigurációs készleteinek kipróbálására, hogy maximalizáljuk az elsődleges metrikát. validation_acc
Meghatározunk egy korai felmondási szabályzatot is – a BanditPolicy. Ez a szabályzat úgy működik, hogy két iterációnként ellenőrzi a feladatot. Ha az elsődleges metrika validation_acca felső 10 százalékos tartományon kívül esik, az Azure Machine Learning leállítja a feladatot. Ez menti a modellt attól, hogy folytassa a hiperparaméterek felderítését, amelyek nem ígérik, hogy segítenek elérni a célmetrikát.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Most már a korábbiakhoz hasonlóan küldheti el ezt a feladatot. Ezúttal egy takarítási feladatot fog futtatni, amely átsöpri a vonatfeladatot.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)A feladatot a feladat futtatása során megjelenő studio felhasználói felület hivatkozásával figyelheti.
A legjobb modell megkeresése és regisztrálása
Miután az összes futtatás befejeződött, megtalálhatja a modellt a legnagyobb pontossággal előállító futtatásokat.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Ezután regisztrálhatja ezt a modellt.
registered_model = ml_client.models.create_or_update(model=model)A modell üzembe helyezése online végpontként
A modell regisztrálása után üzembe helyezheti azt online végpontként , vagyis webszolgáltatásként az Azure-felhőben.
Gépi tanulási szolgáltatás üzembe helyezéséhez általában a következőkre van szüksége:
- Az üzembe helyezni kívánt modellegységek. Ezek az eszközök tartalmazzák a modell azon fájlját és metaadatait, amelyeket már regisztrált a betanítási feladatban.
- Néhány szolgáltatásként futtatandó kód. A kód egy adott bemeneti kérésen (belépési szkripten) hajtja végre a modellt. Ez a bejegyzésszkript fogadja az üzembe helyezett webszolgáltatásnak küldött adatokat, és továbbítja azokat a modellnek. Miután a modell feldolgozta az adatokat, a szkript visszaadja a modell válaszát az ügyfélnek. A szkript a modellre jellemző, és ismernie kell a modell által várt és visszaadott adatokat. MLFlow-modell használata esetén az Azure Machine Learning automatikusan létrehozza ezt a szkriptet.
További információ az üzembe helyezésről: Gépi tanulási modell üzembe helyezése és pontszáma felügyelt online végponttal Python SDK v2 használatával.
Új online végpont létrehozása
A modell üzembe helyezésének első lépéseként létre kell hoznia az online végpontot. A végpont nevének egyedinek kell lennie a teljes Azure-régióban. Ebben a cikkben egy univerzálisan egyedi azonosító (UUID) használatával hoz létre egyedi nevet.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")A végpont létrehozása után az alábbiak szerint kérdezheti le:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)A modell üzembe helyezése a végponton
A végpont létrehozása után üzembe helyezheti a modellt a belépési szkripttel. Egy végpont több üzembe helyezéssel is rendelkezhet. A szabályok használatával a végpont ezután átirányíthatja a forgalmat ezekre az üzemelő példányokra.
Az alábbi kódban egyetlen üzembe helyezést hoz létre, amely a bejövő forgalom 100%-át kezeli. Az üzembe helyezéshez tetszőleges színnevet (tff-blue) használunk. Az üzembe helyezéshez bármilyen más nevet is használhat, például tff-green vagy tff-red . A modell végponton való üzembe helyezéséhez szükséges kód a következő:
- a korábban regisztrált modell legjobb verzióját telepíti;
- pontszámot ad a modellnek a
score.pyfájl használatával; és - Ugyanazt a válogatott környezetet használja (amelyet korábban deklarált) a következtetés végrehajtásához.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Feljegyzés
Az üzembe helyezés várhatóan egy kis időt vesz igénybe.
Az üzembe helyezés tesztelése minta lekérdezéssel
Miután üzembe helyezte a modellt a végponton, előrejelezheti az üzembe helyezett modell kimenetét a invoke végponton található metódus használatával. A következtetés futtatásához használja a kérelemmappából származó mintakérésfájlt sample-request.json .
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)Ezután kinyomtathatja a visszaadott előrejelzéseket, és a bemeneti képekkel együtt ábrázolhatja őket. A hibásan besorolt minták kiemeléséhez használjon piros betűszínt és fordított képet (feketén fehér).
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Feljegyzés
Mivel a modell pontossága magas, előfordulhat, hogy néhányszor futtatnia kell a cellát, mielőtt helytelenül besorolt mintát látna.
Az erőforrások eltávolítása
Ha nem használja a végpontot, törölje az erőforrás használatának leállításához. A törlés előtt győződjön meg arról, hogy más üzemelő példányok nem használják a végpontot.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Feljegyzés
Várjon egy kis időt a törlés befejezésére.
Következő lépések
Ebben a cikkben betanított és regisztrált egy TensorFlow-modellt. A modellt egy online végponton is üzembe helyezte. Az Azure Machine Learningről további információt az alábbi cikkekben talál.