Szöveg és információ kinyerése képekből az AI-bővítésben
Az AI-bővítés révén az Azure AI Search számos lehetőséget kínál a kereshető szövegek képekből való létrehozására és kinyerására, többek között a következőkre:
- OCR a szöveg és számjegyek optikai karakterfelismeréséhez
- Képelemzés , amely vizuális funkciókon keresztül írja le a képeket
- Egyéni képességek bármely külső képfeldolgozás meghívásához, amelyet meg szeretne adni
Az OCR-n keresztül kinyerheti a szöveget olyan fényképekből vagy képekből, amelyek alfanumerikus szöveget tartalmaznak, például a "STOP" szót egy stopjelben. A képelemzéssel szövegábrázolást hozhat létre egy képről, például pitypangot ábrázoló fényképhez, vagy a "sárga" színhez. A kép metaadatait is kinyerheti, például a méretét.
Ez a cikk a képek használatának alapjait ismerteti, és számos gyakori forgatókönyvet is ismertet, például beágyazott képekkel való munkát, egyéni képességeket és az eredeti képek vizualizációinak felülírását.
Ahhoz, hogy képtartalmakkal dolgozzon egy készségkészletben, a következőkre lesz szüksége:
- Képeket tartalmazó forrásfájlok
- Képműveletekhez konfigurált keresési indexelő
- Beépített vagy egyéni képességekkel rendelkező készségkészlet, amely OCR-t vagy képelemzést hív meg
- Keresési index az elemzett szöveg kimenetének fogadásához szükséges mezőkkel, valamint a társításokat létesítő indexelő kimeneti mezőleképezéseivel.
Igény szerint előrejelzéseket is meghatározhat, hogy képelemzéssel rendelkező kimenetet fogadjon el egy tudástárban adatbányászati forgatókönyvek esetén.
Forrásfájlok beállítása
A képfeldolgozás indexelőalapú, ami azt jelenti, hogy a nyers bemeneteknek támogatott adatforrásban kell lenniük.
- A képelemzés támogatja a JPEG, a PNG, a GIF és a BMP használatát
- Az OCR támogatja a JPEG, a PNG, a BMP és a TIF használatát
A képek különálló bináris fájlok vagy dokumentumokba (PDF, RTF és Microsoft-alkalmazásfájlok) vannak beágyazva. Egy adott dokumentumból legfeljebb 1000 kép nyerhető ki. Ha egy dokumentumban több mint 1000 kép található, az első 1000 ki lesz nyerve, majd figyelmeztetés jön létre.
Az Azure Blob Storage a képfeldolgozáshoz leggyakrabban használt tároló az Azure AI Searchben. A blobtárolóból származó képek lekéréséhez három fő feladat kapcsolódik:
Engedélyezze a tárolóban lévő tartalomhoz való hozzáférést. Ha olyan teljes hozzáférésű kapcsolati sztring használ, amely tartalmaz egy kulcsot, a kulcs engedélyt ad a tartalomra. Másik lehetőségként hitelesíthet a Microsoft Entra-azonosítóval , vagy megbízható szolgáltatásként csatlakozhat.
Hozzon létre egy "azureblob" típusú adatforrást , amely a fájlokat tároló blobtárolóhoz csatlakozik.
Tekintse át a szolgáltatási szint korlátait , és győződjön meg arról, hogy a forrásadatok az indexelők és a bővítés maximális méret- és mennyiségi korlátai alatt vannak.
Indexelők konfigurálása képfeldolgozáshoz
A forrásfájlok beállítása után engedélyezze a kép normalizálását a imageAction paraméter indexelőkonfigurációjában való beállításával. A kép normalizálása segít egységesebbé tenni a képeket az alsóbb rétegbeli feldolgozáshoz. A kép normalizálása a következő műveleteket foglalja magában:
- A nagyméretű képek mérete a maximális magasságra és szélességre van átméretezve, hogy egységesek legyenek.
- A tájoláson metaadatokkal rendelkező képek esetében a kép elforgatása a függőleges betöltéshez van igazítva.
A metaadatok módosításait az egyes képekhez létrehozott összetett típus rögzíti. A kép normalizálási követelményét nem lehet kikapcsolni. A képeket iteráló készségek, például az OCR és a képelemzés normalizált képeket várnak.
Indexelő létrehozása vagy frissítése a konfigurációs tulajdonságok beállításához:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Állítsa be a (kötelező) értéket
dataToExtractcontentAndMetadata.Ellenőrizze, hogy az
parsingModealapértelmezett érték van-e beállítva (kötelező).Ez a paraméter határozza meg az indexben létrehozott keresési dokumentumok részletességét. Az alapértelmezett mód egy-az-egyhez levelezést állít be, így egy blob egyetlen keresési dokumentumot eredményez. Ha a dokumentumok nagy méretűek, vagy ha a készségek kisebb szövegrészeket igényelnek, a szöveg felosztása képesség hozzáadható, amely feldolgozás céljából feloszt egy dokumentumot lapozásra. Keresési forgatókönyvek esetén azonban dokumentumonként egy blobra van szükség, ha a bővítés képfeldolgozást is tartalmaz.
Állítsa be
imageActionúgy, hogy engedélyezze a normalized_images csomópontot egy bővítőfán (kötelező):generateNormalizedImagesnormalizált képek tömbjének létrehozása a dokumentumrepedés részeként.generateNormalizedImagePerPage(csak PDF esetén) normalizált képek tömbjének létrehozásához, ahol a PDF minden oldala egyetlen kimeneti képre jelenik meg. A nem PDF-fájlok esetében a paraméter viselkedése hasonló, mintha a "generateNormalizedImages" értéket állította volna be. Vegye figyelembe azonban, hogy a "generateNormalizedImagePerPage" beállítással az indexelési művelet kevésbé teljesíthető a tervezés (különösen a nagyméretű dokumentumok esetében), mivel több lemezképet kell létrehozni.
Igény szerint állítsa be a létrehozott normalizált képek szélességét vagy magasságát:
normalizedImageMaxWidth(képpontban). Az alapértelmezett érték 2000. A maximális érték 10000.normalizedImageMaxHeight(képpontban). Az alapértelmezett érték 2000. A maximális érték 10000.
A normalizált képek maximális szélessége és magassága alapértelmezés szerint 2000 képpont, amely az OCR-képesség és a képelemzési képesség által támogatott maximális méreteken alapul. Az OCR-képesség legfeljebb 4200 szélességet és magasságot támogat a nem angol nyelvű nyelvek esetében, angolul pedig 10000-et. Ha növeli a maximális korlátokat, a feldolgozás a készségek definíciójától és a dokumentumok nyelvétől függően nagyobb képeken is meghiúsulhat.
Ha a számítási feladat egy adott fájltípust céloz meg, adja meg a fájltípus feltételeit . A blobindexelő konfigurációja fájlbefoglalási és kizárási beállításokat tartalmaz. Szűrheti a nem kívánt fájlokat.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Tudnivalók a normalizált képekről
Ha imageAction nem "none" értékre van beállítva, az új normalized_images mező képtömböt tartalmaz. Minden kép egy összetett típus, amelynek tagjai a következők:
| Képtag | Leírás |
|---|---|
| adatok | A normalizált kép BASE64 kódolású sztringje JPEG formátumban. |
| width (szélesség) | A normalizált kép szélessége képpontban. |
| height (magasság) | A normalizált kép magassága képpontban. |
| originalWidth | A kép eredeti szélessége a normalizálás előtt. |
| originalHeight | A kép eredeti magassága normalizálás előtt. |
| rotációFromOriginal | Az óramutató járásával ellentétes irányban forgott a normalizált kép létrehozásához használt fok. 0 és 360 fok közötti érték. Ez a lépés beolvassa a kamerával vagy képolvasóval létrehozott kép metaadatait. Általában 90 fok többszöröse. |
| contentOffset | A tartalommezőben lévő karaktereltolás, amelyből a rendszerképet kinyerték. Ez a mező csak beágyazott képeket tartalmazó fájlokra vonatkozik. A PDF-dokumentumokból kinyert képek contentOffsetje mindig a dokumentumból kinyert oldalon lévő szöveg végén található. Ez azt jelenti, hogy a képek a lapon lévő összes szöveg után jelennek meg, függetlenül a kép eredeti helyétől. |
| pageNumber | Ha a képet PDF-fájlból nyerték ki vagy renderelték, ez a mező az oldalszámot tartalmazza a PDF-ben, amelyből kinyerték vagy renderelték, 1-től kezdve. Ha a kép nem PDF-fájlból származik, akkor ez a mező 0. |
A normalized_images mintaértéke:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Képességkészletek definiálása képfeldolgozáshoz
Ez a szakasz kiegészíti a képességekkel kapcsolatos referenciacikkeket azáltal, hogy kontextust biztosít a képességbemenetek, kimenetek és minták kezeléséhez a képfeldolgozáshoz kapcsolódóan.
Készségek hozzáadásához hozzon létre vagy frissítsen egy készségkészletet .
Sablonokat adhat hozzá az OCR-hez és a képelemzéshez a portálról, vagy másolja a definíciókat a szakértelem-referenciadokumentációból . Szúrja be őket a készségkészlet definíciójának készségtömbjébe.
Szükség esetén vegye fel a többszolgáltatásos kulcsot a képességkészlet Azure AI-szolgáltatások tulajdonságára. Az Azure AI Search meghív egy számlázható Azure AI-szolgáltatási erőforrást az OCR-hez, és képelemzést végez az ingyenes korlátot meghaladó tranzakciókhoz (indexelőnként naponta 20). Az Azure AI-szolgáltatásoknak ugyanabban a régióban kell lenniük, mint a keresési szolgáltatásnak.
Ha az eredeti képek PDF-fájlba vagy alkalmazásfájlokba, például PPTX-be vagy DOCX-be vannak ágyazva, akkor hozzá kell adnia egy szövegegyesítési képességet, ha a képkimenetet és a szövegkimenetet együtt szeretné megjeleníteni. A beágyazott rendszerképek használatának további ismertetését ebben a cikkben találjuk.
Miután létrehozta a készségkészlet alapszintű keretrendszerét, és konfigurálta az Azure AI-szolgáltatásokat, az egyes képi képességekre összpontosíthat, meghatározhatja a bemeneteket és a forráskörnyezetet, valamint leképezheti a kimeneteket egy index vagy tudástár mezőire.
Feljegyzés
Lásd a REST-oktatóanyagot: A REST és az AI használatával kereshető tartalmakat hozhat létre az Azure-blobokból egy példakészség-halmazhoz, amely egyesíti a képfeldolgozást az alsóbb rétegbeli természetes nyelvi feldolgozással. Bemutatja, hogyan adagolhatja a készségkép-kimenetet az entitásfelismerésbe és a kulcskifejezések kinyeréséhez.
A képfeldolgozás bemenetei
Mint említettük, a rendszer a dokumentum repedése során kinyeri a képeket, majd az előzetes lépésként normalizálja. A normalizált képek minden képfeldolgozási képesség bemenetei, és mindig egy bővített dokumentumfában jelennek meg két módon:
/document/normalized_images/*olyan dokumentumokhoz készült, amelyek egészben vannak feldolgozva./document/normalized_images/*/pagesadattömbökben (lapokban) feldolgozott dokumentumokhoz készült.
Függetlenül attól, hogy az OCR-t és a képelemzést azonos módon használja-e, a bemenetek felépítése gyakorlatilag megegyezik:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Kimenetek leképezése keresési mezőkre
A képességkészletekben a képelemzés és az OCR-képességkimenet mindig szöveg. A kimeneti szöveg csomópontként jelenik meg egy belső bővített dokumentumfában, és minden csomópontot le kell képezni egy keresési index mezőire vagy egy tudástárban lévő előrejelzésekre, hogy a tartalom elérhetővé legyen az alkalmazásban.
A készségkészletben tekintse át az
outputsegyes képességek szakaszát annak megállapításához, hogy mely csomópontok találhatók a bővített dokumentumban:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Hozzon létre vagy frissítsen egy keresési indexet , hogy mezőket adjon hozzá a képességkimenetek elfogadásához.
A következő mezőgyűjteményi példában a "content" blobtartalom. A "Metadata_storage_name" a fájl nevét tartalmazza (győződjön meg arról, hogy a fájl "lekérthető"). A "Metadata_storage_path" a blob egyedi elérési útja, és az alapértelmezett dokumentumkulcs. A "Merged_content" a szövegegyesítés kimenete (képek beágyazásakor hasznos).
A "Text" és az "layoutText" OCR-képességkimenetek, és sztringgyűjteménynek kell lenniük ahhoz, hogy a teljes dokumentum összes OCR által generált kimenetét rögzíthesse.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Frissítse az indexelőt a képességkészlet kimenetének (bővítési fában lévő csomópontok) indexmezőkre való leképezéséhez.
A bővített dokumentumok belsőek. Ha egy bővített dokumentumfában szeretné külsőleg létrehozni a csomópontokat, állítson be egy kimeneti mezőleképezést, amely meghatározza, hogy melyik indexmező fogadja a csomópont tartalmát. A bővített adatokat az alkalmazás egy indexmezőn keresztül éri el. Az alábbi példa egy "text" csomópontot (OCR-kimenetet) mutat be egy bővített dokumentumban, amely egy keresési index "szöveg" mezőjére van leképezve.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Futtassa az indexelőt a forrásdokumentum lekérésének, a képfeldolgozásnak és az indexelésnek a meghívásához.
Eredmények ellenőrzése
A képfeldolgozás eredményeinek ellenőrzéséhez futtasson egy lekérdezést az indexen. Keresési ügyfélként vagy HTTP-kéréseket küldő eszközként használja a Search Explorert . Az alábbi lekérdezés a képfeldolgozás kimenetét tartalmazó mezőket választja ki.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
Az OCR felismeri a képfájlokban lévő szöveget. Ez azt jelenti, hogy az OCR-mezők ("szöveg" és "layoutText") üresek, ha a forrásdokumentumok tiszta szöveg vagy tiszta képek. Hasonlóképpen, a képelemzési mezők ("imageCaption" és "imageTags") üresek, ha a forrásdokumentum bemenetei szigorúan szövegesek. Az indexelő végrehajtása figyelmeztetéseket ad ki, ha a képalkotó bemenetek üresek. Ilyen figyelmeztetések várhatók, ha a csomópontok nem lesznek feltöltve a bővített dokumentumban. Ne feledje, hogy a blobindexelés lehetővé teszi a fájltípusok hozzáadását vagy kizárását, ha külön szeretné használni a tartalomtípusokat. Ezekkel a beállításokkal csökkentheti a zajt az indexelő futtatása során.
Az eredmények ellenőrzésére szolgáló másik lekérdezés a "content" és a "merged_content" mezőket is tartalmazhatja. Figyelje meg, hogy ezek a mezők bármilyen blobfájl tartalmát tartalmazzák, még azokat is, ahol nem végeztek képfeldolgozást.
A képességkimenetek ismertetése
A képességkimenetek közé tartozik a "text" (OCR), "layoutText" (OCR), "merged_content", "captions" (képelemzés), "tags" (képelemzés):
A "text" az OCR által létrehozott kimenetet tárolja. Ezt a csomópontot típusmezőre
Collection(Edm.String)kell leképezni. Keresési dokumentumonként egy "szöveg" mező található, amely több képet tartalmazó dokumentumok vesszővel tagolt sztringjeiből áll. Az alábbi ábrán három dokumentum OCR-kimenete látható. Az első egy kép nélküli fájlt tartalmazó dokumentum. A második egy dokumentum (képfájl), amely egy szót tartalmaz: "Microsoft". A harmadik egy dokumentum, amely több képet tartalmaz, némelyik szöveg nélkül ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]Az "layoutText" az OCR által generált információkat tárolja a lap szöveghelyéről a normalizált kép határolókeretei és koordinátái alapján. Ezt a csomópontot típusmezőre
Collection(Edm.String)kell leképezni. A keresési dokumentumban egy "layoutText" mező található, amely vesszővel tagolt sztringekből áll.A "merged_content" egy szövegegyesítési képesség kimenetét tárolja, és egy nagy típusú
Edm.Stringmezőnek kell lennie, amely nyers szöveget tartalmaz a forrásdokumentumból, a kép helyett beágyazott "szöveggel". Ha a fájlok csak szövegesek, akkor az OCR-nek és a képelemzésnek nincs teendője, és a "merged_content" ugyanaz, mint a "content" (a blob tartalmát tartalmazó blobtulajdonság).Az "imageCaption" egy kép leírását rögzíti egyéni címkékként és hosszabb szöveges leírásként.
Az "imageTags" kulcsszavak gyűjteményeként tárolja a képek címkéit, egy gyűjteményt a forrásdokumentum összes képéhez.
Az alábbi képernyőkép egy szövegeket és beágyazott képeket tartalmazó PDF-ábrát ábrázol. A dokumentum repedése három beágyazott képet észlelt: sirályok nyája, térkép, sas. A példában szereplő többi szöveg (beleértve a címeket, címsorokat és szövegtörzseket) szövegként lett kinyerve, és ki lett zárva a képfeldolgozásból.
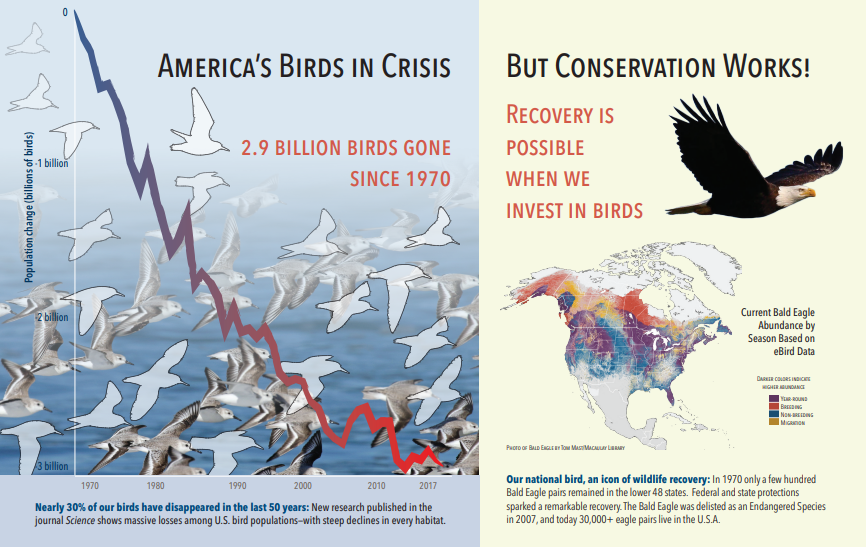
A képelemzés kimenetét az alábbi JSON szemlélteti (keresési eredmény). A képességdefinícióval megadhatja, hogy mely vizualizációs funkciók érdeklik. Ebben a példában címkék és leírások készültek, de több kimenet közül lehet választani.
Az "imageCaption" kimenet leírások tömbje, képenként egy, a képet leíró szavakból és hosszabb kifejezésekből álló "címkék" által jelölve. Figyelje meg a "sirályok nyája úszkál a vízben" vagy "egy madár közelről" címkét.
Az "imageTags" kimenet egyetlen címkékből álló tömb, amely a létrehozás sorrendjében szerepel. Figyelje meg, hogy a címkék ismétlődnek. Nincs összesítés vagy csoportosítás.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Forgatókönyv: Beágyazott képek PDF-fájlokban
Ha a feldolgozni kívánt képek más fájlokba (például PDF-be vagy DOCX-be) vannak ágyazva, a bővítési folyamat csak a képeket nyeri ki, majd átadja őket az OCR-nek vagy a képelemzésnek feldolgozás céljából. A kép kinyerése a dokumentum repedési fázisában történik, és a képek elválasztása után külön maradnak, kivéve, ha a feldolgozott kimenetet explicit módon egyesíti a forrásszövegben.
A Szövegegyesítés funkcióval a képfeldolgozási kimenet vissza lesz helyezve a dokumentumba. Bár a szövegegyesítés nem nehéz követelmény, a rendszer gyakran meghívja, hogy a képkimenet (OCR-szöveg, OCR-elrendezésszöveg, képcímkék, képfeliratok) újra be lehessen illeszteni a dokumentumba. A képességtől függően a képkimenet egy beágyazott bináris kép helyett egy helyben lévő szöveges megfelelőt ad vissza. A képelemzés kimenete egyesíthető a kép helyén. Az OCR-kimenet mindig az egyes lapok végén jelenik meg.
Az alábbi munkafolyamat ismerteti a kép kinyerésének, elemzésének, egyesítésének folyamatát, valamint azt, hogy a folyamat hogyan terjeszthető ki a képfelbontással feldolgozott kimenet más szövegalapú készségekre, például az entitásfelismerésre vagy a szövegfordításra.
Az adatforráshoz való csatlakozás után az indexelő betölti és feltöri a forrásdokumentumokat, kinyeri a képeket és a szöveget, és sorban áll minden egyes tartalomtípus feldolgozásra. Létrejön egy bővített dokumentum, amely csak gyökércsomópontból (
"document") áll.Az üzenetsorban lévő képek normalizálva lesznek, és csomópontként
"document/normalized_images"kerülnek át a bővített dokumentumokba.A képdúsítások bemenetként futnak
"/document/normalized_images".A rendszer képkimeneteket ad át a bővített dokumentumfának, és mindegyik kimenet külön csomópontként jelenik meg. A kimenetek szakértelem szerint változnak (szöveg és elrendezésSzöveg az OCR-hez, címkék és képaláírások a Képelemzéshez).
Nem kötelező, de ajánlott, ha azt szeretné, hogy a keresési dokumentumok a szöveg és a kép forrásszövegét együtt tartalmazzák, a Szövegegyesítés fut, és egyesíti a képek szöveges ábrázolását a fájlból kinyert nyers szöveggel. A szöveges adattömbök egyetlen nagy sztringbe vannak összesítve, ahol a szöveg először a sztringbe, majd az OCR szövegkimenetébe vagy képcímkéibe és felirataiba lesz beszúrva.
A Szövegegyesítés kimenete mostantól a végleges szöveg, amely elemezni tudja a szövegfeldolgozást végző alsóbb rétegbeli képességeket. Ha például a képességkészlet ocR-t és entitásfelismerést is tartalmaz, az entitásfelismerés bemenetének (a Szövegegyesítési képesség kimenetének célneve) kell lennie
"document/merged_text".Az összes készség végrehajtása után a bővített dokumentum befejeződött. Az utolsó lépésben az indexelők kimeneti mezőleképezésekre hivatkoznak, hogy gazdagított tartalmat küldjenek a keresési index egyes mezőinek.
Az alábbi példaismereti csoport létrehoz egy "merged_text" mezőt, amely a dokumentum eredeti szövegét tartalmazza beágyazott OCRed szöveggel beágyazott képek helyett. Tartalmaz egy entitásfelismerési képességet is, amely bemenetként használ "merged_text" .
Kérelem törzsszintaxisa
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Most, hogy rendelkezik egy merged_text mezővel, leképezheti az indexelő definíciójában kereshető mezőként. A fájlok összes tartalma, beleértve a képek szövegét is, kereshető lesz.
Forgatókönyv: Határolókeretek vizualizációja
Egy másik gyakori forgatókönyv a keresési eredmények elrendezési adatainak megjelenítése. Kiemelheti például, hogy hol található szöveg egy képen a keresési eredmények részeként.
Mivel az OCR-lépés a normalizált képeken történik, az elrendezési koordináták a normalizált képtérben vannak, de ha meg kell jelenítenie az eredeti képet, konvertálja az elrendezés koordinátapontjait az eredeti képkoordináta-rendszerbe.
A következő algoritmus a mintát szemlélteti:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Forgatókönyv: Egyéni képismeretek
A képeket egyéni képességekből is átadhatja és visszaadhatja. A base64 képességkészlet az egyéni képességnek átadott képet kódolja. Ha az egyéni képességen belül szeretné használni a képet, állítsa be "/document/normalized_images/*/data" az egyéni képesség bemeneteként. Az egyéni képességkódon belül a base64 dekódolja a sztringet, mielőtt képpé konvertálja. Ha vissza szeretne adni egy képet a képességkészletnek, a base64-kódolással kódolhatja a képet, mielőtt visszaküldené azt a készségkészletnek.
A rendszer az alábbi tulajdonságokkal rendelkező objektumként adja vissza a képet.
{
"$type": "file",
"data": "base64String"
}
Az Azure Search Python-minták adattára teljes mintával rendelkezik a Pythonban egy olyan egyéni képességből, amely gazdagítja a képeket.
Képek átadása egyéni képességeknek
Azokban az esetekben, amikor egyéni képesség szükséges a képeken való munkához, átadhat képeket az egyéni képességnek, és visszaadhatja a szöveget vagy képeket. A következő képességkészlet egy mintából származik.
Az alábbi képességkészlet a normalizált rendszerképet (a dokumentum repedése során nyert) és a kép szeleteit adja ki.
Mintakészség-halmaz
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Példa egyéni képességre
Maga az egyéni képesség kívül esik a képességkészleten. Ebben az esetben a Python-kód az, amely először a kérelemrekordok kötegét az egyéni képességformátumban ciklusozza át, majd a base64 kódolású sztringet képpé alakítja.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
A kép visszaadásához hasonlóan egy base64 kódolású sztringet ad vissza egy JSON-objektumon belül, $type amelynek tulajdonsága a filekövetkező: .
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}
Lásd még
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: