Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure AI Search az Azure Blob Storage-ban tárolt PDF-dokumentumokból is kinyerhet és indexelhet szövegeket és képeket. Ez az oktatóanyag bemutatja, hogyan hozhat létre többmodális indexelési folyamatot a vizualizációk természetes nyelvű leírásával és a dokumentumszövegek mellé való beágyazásával.
A forrásdokumentumból minden képet átadnak a GenAI Prompt készségnek (előzetes verzió), hogy tömör szöveges leírást hozzon létre. Ezek a leírások az eredeti dokumentumszöveggel együtt vektoros ábrázolásokba vannak beágyazva az Azure OpenAI 3-nagy méretű szövegbe ágyazott modelljével. Az eredmény egyetlen index, amely szemantikailag kereshető tartalmat tartalmaz mindkét módból: szövegből és verbális képekből.
Ebben az oktatóanyagban a következőket használja:
36 oldalas PDF-dokumentum, amely gazdag vizuális tartalmakat, például diagramokat, infografikákat és beolvasott oldalakat kombinál hagyományos szöveggel.
A normalizált képek és szövegek kinyerésére szolgáló dokumentumkinyerési képesség .
A GenAI Prompt (előzetes verzió) képességgel képaláírásokat hozhat létre, amelyek vizuális tartalom szöveges leírásait szolgáltatják a kereséshez és kontextus-megadáshoz.
A szöveg- és képbeágyazások tárolására és a vektoralapú hasonlóság keresésének támogatására konfigurált keresési index.
Ez az oktatóanyag alacsonyabb költségű megközelítést mutat be a multimodális tartalom indexelésére dokumentumkivonási képesség és képaláírások készítésének használatával. Lehetővé teszi a szövegek és képek kinyerését és keresését az Azure Blob Storage-ban tárolt dokumentumokból. Nem tartalmazza azonban a szöveg helyadatait, például az oldalszámokat vagy a határoló régiókat.
A strukturált szövegelrendezést és térbeli metaadatokat tartalmazó átfogóbb megoldásért tekintse meg a blobok szöveggel és képekkel való indexelését a többmodális RAG-forgatókönyvekhez képi verbális és dokumentumelrendezési képesség használatával.
Megjegyzés:
Ehhez az oktatóanyaghoz a imageActiongenerateNormalizedImages beállítása szükséges, és az Azure AI Search díjszabása szerint további díjat számítanak fel a képek kinyeréséért.
REST-ügyfél és a Search REST API-k használatával a következőt fogja használni:
- Mintaadatok beállítása és adatforrás konfigurálása
azureblob - Index létrehozása szöveg- és képbeágyazások támogatásával
- Képességkészlet definiálása kinyerési, feliratozási és beágyazási lépésekkel
- Indexelő létrehozása és futtatása tartalom feldolgozásához és indexeléséhez
- Keresés az újonnan létrehozott indexben
Előfeltételek
Egy Azure-fiók, aktív előfizetéssel. Hozzon létre egy fiókot ingyenesen.
Azure AI Search, alapszintű tarifacsomag vagy magasabb, felügyelt identitással. Hozzon létre egy szolgáltatást , vagy keressen egy meglévő szolgáltatást az aktuális előfizetésében.
Visual Studio Code REST-ügyféllel.
Fájlok letöltése
Töltse le a következő PDF-mintafájlt:
Mintaadatok feltöltése az Azure Storage-ba
Az Azure Storage-ban hozzon létre egy doc-extraction-image-verbalization-container nevű új tárolót.
Rendszer által hozzárendelt felügyelt identitással létesített kapcsolatokhoz. Adjon meg egy ResourceId azonosítót tartalmazó kapcsolati sztringet fiókkulcs vagy jelszó nélkül. A ResourceId azonosítónak tartalmaznia kell a tárfiók előfizetési azonosítóját, a tárfiók erőforráscsoportját és a tárfiók nevét. Az összekötő karakterlánc hasonló az alábbi példához:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }Felhasználó által hozzárendelt felügyelt identitással létesített kapcsolatokhoz. Adjon meg egy ResourceId azonosítót tartalmazó kapcsolati sztringet fiókkulcs vagy jelszó nélkül. A ResourceId azonosítónak tartalmaznia kell a tárfiók előfizetési azonosítóját, a tárfiók erőforráscsoportját és a tárfiók nevét. Adja meg az identitást az alábbi példában látható szintaxis használatával. A userAssignedIdentity beállítása a felhasználó által hozzárendelt felügyelt identitásra; a kapcsolati sztring hasonló a következő példához.
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }, "identity" : { "@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity" : "/subscriptions/00000000-0000-0000-0000-00000000/resourcegroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.ManagedIdentity/userAssignedIdentities/MY-DEMO-USER-MANAGED-IDENTITY" }
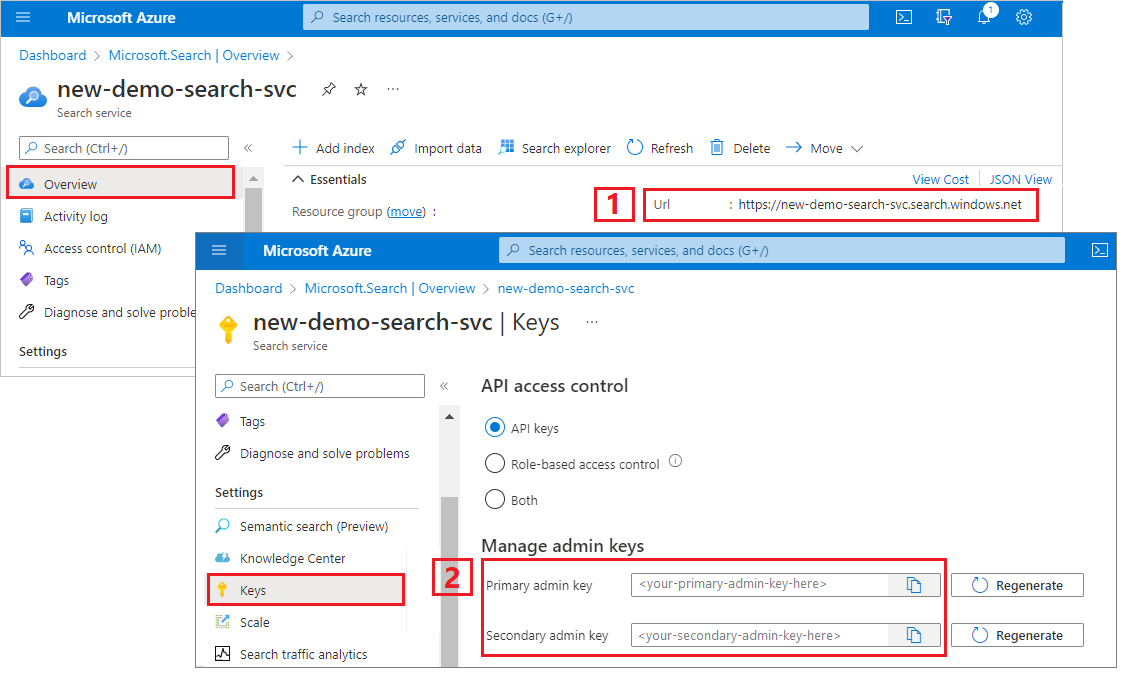
Keresési szolgáltatás URL-címének és API-kulcsának másolása
Ebben az oktatóanyagban az Azure AI Searchhez való csatlakozáshoz végpontra és API-kulcsra van szükség. Ezeket az értékeket az Azure Portalon szerezheti be. Alternatív kapcsolati módszerekért tekintse meg a felügyelt identitásokat.
Jelentkezzen be az Azure Portalra, lépjen a keresési szolgáltatás áttekintési oldalára, és másolja az URL-címet. A végpontok például a következőképpen nézhetnek ki:
https://mydemo.search.windows.net.A Beállítások> területen másolja ki a rendszergazdai kulcsot. A rendszergazdai kulcsok objektumok hozzáadására, módosítására és törlésére szolgálnak. Két felcserélhető rendszergazdai kulcs van. Másolja valamelyiket.
A REST-fájl beállítása
Indítsa el a Visual Studio Code-ot, és hozzon létre egy új fájlt.
Adja meg a kérelemben használt változók értékeit.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @openAIResourceUri = PUT-YOUR-OPENAI-URI-HERE @openAIKey = PUT-YOUR-OPENAI-KEY-HERE @chatCompletionResourceUri = PUT-YOUR-CHAT-COMPLETION-URI-HERE @chatCompletionKey = PUT-YOUR-CHAT-COMPLETION-KEY-HERE @imageProjectionContainer=PUT-YOUR-IMAGE-PROJECTION-CONTAINER-HEREMentse a fájlt a
.restvagy a.httpfájlkiterjesztés használatával.
A REST-ügyféllel kapcsolatos segítségért tekintse meg a következő rövid útmutatót: Teljes szöveges keresés REST használatával.
Adatforrás létrehozása
Az Adatforrás létrehozása (REST) létrehoz egy adatforrás-kapcsolatot, amely meghatározza az indexelendő adatokat.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnection}}"
},
"container": {
"name": "doc-extraction-image-verbalization-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Küldje el a kérést. A válasznak így kell kinéznie:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows-int.net:443/datasources('doc-extraction-image-verbalization-ds')?api-version=2025-05-01-preview -Preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 4eb8bcc3-27b5-44af-834e-295ed078e8ed
elapsed-time: 346
Date: Sat, 26 Apr 2025 21:25:24 GMT
Connection: close
{
"name": "doc-extraction-image-verbalization-ds",
"description": "A test datasource",
"type": "azureblob",
"subtype": null,
"indexerPermissionOptions": [],
"credentials": {
"connectionString": null
},
"container": {
"name": "doc-extraction-multimodality-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Index létrehozása
Az Index létrehozása (REST) létrehoz egy keresési indexet a keresési szolgáltatásban. Az index határozza meg az összes paramétert és ezek attribútumait.
Beágyazott JSON esetén az indexmezőknek meg kell egyezniük a forrásmezőkével. Az Azure AI Search jelenleg nem támogatja a beágyazott JSON-ra való mezőleképezést, ezért a mezőneveknek és adattípusoknak teljesen egyeznie kell. Az alábbi index a nyers tartalom JSON-elemeihez igazodik.
### Create an index
POST {{baseUrl}}/indexes?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 3072,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "offset",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "location_metadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "{{vectorizer}}"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "{{vectorizer}}",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"modelName": "text-embedding-3-large"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
Összefoglalás:
A szöveg- és képbeágyazások a
content_embeddingmezőben vannak tárolva, és megfelelő dimenziókkal (például 3072) és vektorkeresési profillal kell konfigurálni.location_metadataMinden normalizált képhez rögzíti a határoló sokszöget és az oldalszám metaadatait, így lehetővé teszi a pontos térbeli keresést vagy felhasználói felületi átfedéseket.location_metadataebben a forgatókönyvben csak képek esetén létezik. Ha a szöveg helyadatait is rögzíteni szeretné, fontolja meg a Dokumentumelrendezési képesség használatát. A részletes oktatóanyag az oldal alján található.A vektorkereséssel kapcsolatos további információkért lásd: Vektorok az Azure AI Searchben.
További információ a szemantikai rangsorolásról: Szemantikai rangsorolás az Azure AI Searchben
Készségkészlet létrehozása
A Skillset (REST) létrehozása keresési indexet hoz létre a keresési szolgáltatásban. Az index határozza meg az összes paramétert és ezek attribútumait.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-skillset",
"description": "A test skillset",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentExtractionSkill",
"name": "document-extraction-skill",
"description": "Document extraction skill to exract text and images from documents",
"parsingMode": "default",
"dataToExtract": "contentAndMetadata",
"configuration": {
"imageAction": "generateNormalizedImages",
"normalizedImageMaxWidth": 2000,
"normalizedImageMaxHeight": 2000
},
"context": "/document",
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "content",
"targetName": "extracted_content"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "split-skill",
"description": "Split skill to chunk documents",
"context": "/document",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 200,
"unit": "characters",
"inputs": [
{
"name": "text",
"source": "/document/extracted_content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "text-embedding-skill",
"description": "Embedding skill for text",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Custom.ChatCompletionSkill",
"name": "genAI-prompt-skill",
"description": "GenAI Prompt skill for image verbalization",
"uri": "{{chatCompletionResourceUri}}",
"timeout": "PT1M",
"apiKey": "{{chatCompletionKey}}",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "systemMessage",
"source": "='You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: \"A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks.\"\n\nChart: \"A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1.\"\n\nFigure: \"A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers.\"'"
},
{
"name": "userMessage",
"source": "='Please describe this image.'"
},
{
"name": "image",
"source": "/document/normalized_images/*/data"
}
],
"outputs": [
{
"name": "response",
"targetName": "verbalizedImage"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "verblized-image-embedding-skill",
"description": "Embedding skill for verbalized images",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "verbalizedImage_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "shaper-skill",
"description": "Shaper skill to reshape the data to fit the index schema"
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='{{imageProjectionContainer}}/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
},
{
"name": "location_metadata",
"sourceContext": "/document/normalized_images/*",
"inputs": [
{
"name": "page_number",
"source": "/document/normalized_images/*/pageNumber"
},
{
"name": "bounding_polygons",
"source": "/document/normalized_images/*/boundingPolygon"
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "{{index}}",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/pages/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/pages/*/text_vector"
},
{
"name": "content_text",
"source": "/document/pages/*"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "{{index}}",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_text",
"source": "/document/normalized_images/*/verbalizedImage"
},
{
"name": "content_embedding",
"source": "/document/normalized_images/*/verbalizedImage_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "document_title",
"source": "/document/document_title"
},
{
"name": "locationMetadata",
"source": "/document/normalized_images/*/new_normalized_images/location_metadata"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"knowledgeStore": {
"storageConnectionString": "{{storageConnection}}",
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
Ez a képességkészlet kinyeri a szöveget és a képeket, vektorizálja mindkettőt, és formázja a kép metaadatait az indexbe való kivetítéshez.
Összefoglalás:
A
content_textmező kétféleképpen van feltöltve:A Dokumentumkinyerési képesség használatával kinyert és a Szövegfelosztási képesség használatával kicsomagolt dokumentumszövegből
Képtartalomból a GenAI Prompt képesség használatával, amely leíró feliratokat hoz létre minden normalizált képhez
A
content_embeddingmező 3072 dimenziós beágyazást tartalmaz az oldalszöveghez és a verbális képleírásokhoz is. Ezek az Azure OpenAI-ból származó 3-nagy méretű szöveges beágyazási modellel jönnek létre.content_patha kép fájl relatív elérési útvonalát tartalmazza a kijelölt képkonténeren belül. Ez a mező csak PDF-fájlokból kinyert képekhez kerül létrehozásra, haimageActionbe van állítvagenerateNormalizedImages, és amely a forrásmező/document/normalized_images/*/imagePath-ből származó bővített dokumentumból leképezhető.
Indexelő létrehozása és futtatása
Az Indexelő létrehozása létrehoz egy indexelőt a keresési szolgáltatásban. Az indexelő csatlakozik az adatforráshoz, betölti az adatokat, futtat egy készségkészletet, és indexeli a bővített adatokat.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"dataSourceName": "doc-extraction-image-verbalization-ds",
"targetIndexName": "doc-extraction-image-verbalization-index",
"skillsetName": "doc-extraction-image-verbalization-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
Lekérdezések futtatása
Az első dokumentum betöltése után azonnal megkezdheti a keresést.
### Query the index
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Küldje el a kérést. Ez egy meghatározatlan teljes szöveges keresési lekérdezés, amely az indexben lekérdezhetőként megjelölt mezőket és a dokumentumok számát adja vissza. A válasznak így kell kinéznie:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 712ca003-9493-40f8-a15e-cf719734a805
elapsed-time: 198
Date: Wed, 30 Apr 2025 23:20:53 GMT
Connection: close
{
"@odata.count": 100,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview "
}
A válasz 100 dokumentumot ad vissza.
Szűrők esetén logikai operátorokat (és vagy nem) és összehasonlító operátorokat (eq, ne, gt, lt, ge, le) is használhat. A sztring-összehasonlítások megkülönböztetik a kis- és nagybetűket. További információkért és példákért lásd az egyszerű keresési lekérdezések példáit.
Megjegyzés:
A $filter paraméter csak az index létrehozásakor szűrhetőként megjelölt mezőkön működik.
Íme néhány példa más lekérdezésekre:
### Query for only images
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true,
"filter": "image_document_id ne null"
}
### Query for text or images with content related to energy, returning the id, parent document, and text (extracted text for text chunks and verbalized image text for images), and the content path where the image is saved in the knowledge store (only populated for images)
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "energy",
"count": true,
"select": "content_id, document_title, content_text, content_path"
}
Alaphelyzetbe állítás és ismételt futtatás
Az indexelők visszaállíthatók a csúcsérték törléséhez, ami lehetővé teszi a teljes folyamat újrafuttatását. A következő POST-kérések visszaállításra, majd újrafuttatásra szolgálnak.
### Reset the indexer
POST {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/reset?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/run?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/status?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
Erőforrások tisztítása
Ha a saját előfizetésedben dolgozol, a projekt végén célszerű eltávolítani azokat az erőforrásokat, amelyekre már nincs szükséged. A továbbra is futó erőforrások pénzbe kerülhetnek. Az erőforrásokat törölheti egyesével, vagy az erőforráscsoport törlésével eltávolíthatja a benne lévő összes erőforrást is.
Az Azure Portal használatával törölheti az indexeket, indexelőket és adatforrásokat.
Lásd még
Most, hogy már ismeri a multimodális indexelési forgatókönyv minta implementációját, tekintse meg a következőt: