Spark-feladatdefiníció migrálása az Azure Synapse-ból a Fabricbe
A Spark-feladatdefiníciók (SJD) Az Azure Synapse-ból a Fabricbe való áthelyezéséhez két különböző lehetőség közül választhat:
- 1. lehetőség: hozzon létre manuálisan Spark-feladatdefiníciót a Fabricben.
- 2. lehetőség: szkripttel exportálhatja a Spark-feladatdefiníciókat az Azure Synapse-ból, és importálhatja őket a Fabricbe az API használatával.
A Spark-feladatok definíciójának szempontjaiért tekintse meg az Azure Synapse Spark és a Fabric közötti különbségeket.
Előfeltételek
Ha még nem rendelkezik ilyenrel, hozzon létre egy Háló-munkaterületet a bérlőjében.
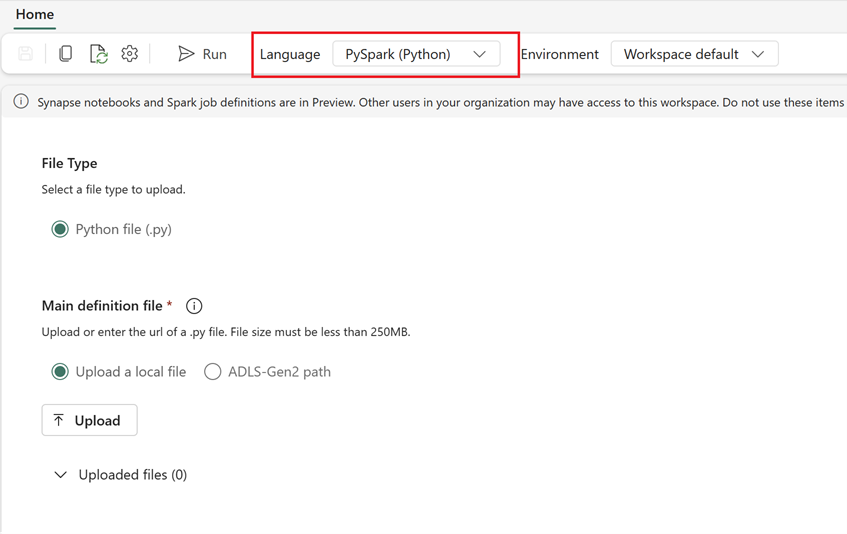
1. lehetőség: Spark-feladatdefiníció manuális létrehozása
Spark-feladatdefiníció exportálása az Azure Synapse-ból:
- Nyissa meg a Synapse Studiót: Jelentkezzen be az Azure-ba. Lépjen az Azure Synapse-munkaterületre, és nyissa meg a Synapse Studiót.
- Keresse meg a Python-/Scala/R Spark-feladatot: Keresse meg és azonosítsa a migrálni kívánt Python-/Scala/R Spark-feladatdefiníciót.
- Exportálja a feladatdefiníció konfigurációját:
- Nyissa meg a Spark-feladatdefiníciót a Synapse Studióban.
- Exportálja vagy jegyezze fel a konfigurációs beállításokat, beleértve a szkriptfájl helyét, a függőségeket, a paramétereket és minden egyéb releváns részletet.
Új Spark-feladatdefiníció (SJD) létrehozása a Fabricben exportált SJD-adatok alapján:
- Access Fabric-munkaterület: Jelentkezzen be a Fabricbe, és férhessen hozzá a munkaterülethez.
- Hozzon létre egy új Spark-feladatdefiníciót a Fabricben:
- A Fabricben lépjen adatmérnök kezdőlapjára.
- Válassza a Spark-feladatdefiníciót.
- Konfigurálja a feladatot a Synapse-ból exportált adatok alapján, beleértve a szkript helyét, a függőségeket, a paramétereket és a fürtbeállításokat.
- Adaptálás és tesztelés: Végezze el a szkripthez vagy konfigurációhoz szükséges módosításokat a Fabric-környezetnek megfelelően. Tesztelje a feladatot a Hálóban, és ellenőrizze, hogy megfelelően fut-e.
A Spark-feladat definíciójának létrehozása után ellenőrizze a függőségeket:
- Győződjön meg arról, hogy ugyanazt a Spark-verziót használja.
- Ellenőrizze a fő definíciós fájl meglétét.
- Ellenőrizze a hivatkozott fájlok, függőségek és erőforrások meglétét.
- Társított szolgáltatások, adatforrás-kapcsolatok és csatlakoztatási pontok.
További információ arról, hogyan hozhat létre Apache Spark-feladatdefiníciót a Fabricben.
2. lehetőség: A Fabric API használata
Kövesse az alábbi főbb lépéseket a migráláshoz:
- Előfeltételek.
- 1. lépés: Spark-feladatdefiníció exportálása az Azure Synapse-ból a OneLake-be (.json).
- 2. lépés: A Spark-feladat definíciójának importálása automatikusan a Fabricbe a Fabric API használatával.
Előfeltételek
Az előfeltételek közé tartoznak azok a műveletek, amelyeket figyelembe kell vennie a Spark-feladatdefiníció fabricbe való migrálása előtt.
- Háló munkaterület.
- Ha még nincs ilyenje, hozzon létre egy Fabric lakehouse-t a munkaterületen.
1. lépés: Spark-feladatdefiníció exportálása az Azure Synapse-munkaterületről
Az 1. lépés középpontjában a Spark-feladat definíciójának exportálása az Azure Synapse-munkaterületről a OneLake-be json formátumban. Ez a folyamat a következő:
- 1.1) SJD-migrálási jegyzetfüzet importálása Fabric-munkaterületre. Ez a jegyzetfüzet exportálja az összes Spark-feladatdefiníciót egy adott Azure Synapse-munkaterületről egy köztes könyvtárba a OneLake-ben. A Synapse API az SJD exportálására szolgál.
- 1.2) Konfigurálja az első parancs paramétereit a Spark-feladatdefiníció közbenső tárolóba (OneLake) való exportálásához. Ez csak a json metaadatfájlt exportálja. A forrás- és célparaméterek konfigurálásához az alábbi kódrészlet szolgál. Győződjön meg arról, hogy a saját értékeire cseréli őket.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
- 1.3) Futtassa az exportálási/importálási jegyzetfüzet első két celláját a Spark-feladatdefiníció metaadatainak a OneLake-be való exportálásához. A cellák befejezése után létrejön ez a mappastruktúra a köztes kimeneti könyvtár alatt.
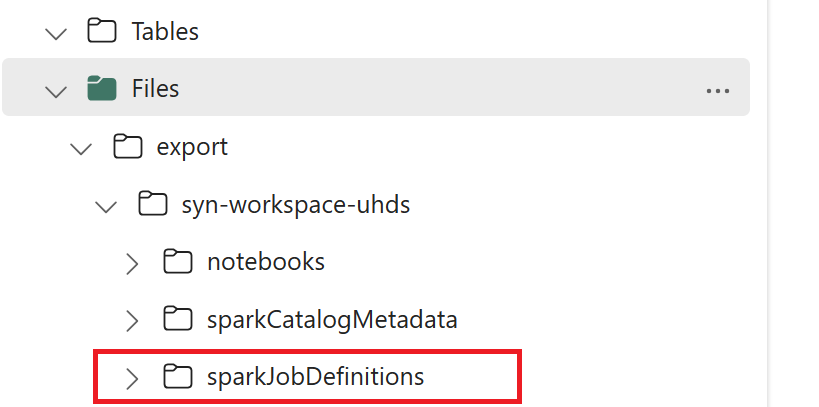
2. lépés: Spark-feladatdefiníció importálása a Hálóba
A 2. lépés az, amikor a Spark-feladatdefiníciók köztes tárolóból importálódnak a Háló munkaterületre. Ez a folyamat a következő:
- 2.1) Ellenőrizze az 1.2 konfigurációit , hogy a megfelelő munkaterület és előtag legyen megjelölve a Spark-feladatdefiníciók importálásához.
- 2.2) Futtassa az exportálási/importálási jegyzetfüzet harmadik celláját az összes Spark-feladatdefiníció közbenső helyről való importálásához.
Feljegyzés
Az exportálási beállítás json metaadatfájlt ad ki. Győződjön meg arról, hogy a Spark-feladatdefiníció végrehajtható fájljai, referenciafájljai és argumentumai elérhetők a Fabricből.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: