munkaterület-felügyeleti beállítások adatmérnök a Microsoft Fabricben
A következőkre vonatkozik:✅ adatmérnök és Adattudomány a Microsoft Fabricben
Amikor létrehoz egy munkaterületet a Microsoft Fabricben, a rendszer automatikusan létrehoz egy , a munkaterülethez társított kezdőkészletet . A Microsoft Fabric egyszerűsített beállításával nincs szükség a csomópont vagy a gép méretének kiválasztására, mivel ezeket a beállításokat a színfalak mögött kezelheti. Ez a konfiguráció gyorsabb (5–10 másodperces) Apache Spark-munkamenet-indítási élményt biztosít a felhasználók számára az Apache Spark-feladatok elindításához és futtatásához számos gyakori forgatókönyvben anélkül, hogy a számítás beállításával kellene foglalkozniuk. Speciális számítási követelményekkel rendelkező forgatókönyvek esetén a felhasználók létrehozhatnak egy egyéni Apache Spark-készletet, és a teljesítményigényük alapján méretezhetik a csomópontokat.
Ha módosítani szeretné egy munkaterület Apache Spark-beállításait, rendelkeznie kell az adott munkaterület rendszergazdai szerepkörével. További információ: Szerepkörök a munkaterületeken.
A munkaterülethez társított készlet Spark-beállításainak kezelése:
Nyissa meg a munkaterület munkaterület-beállításait, és a adatmérnök ing/Science lehetőséget választva bontsa ki a menüt:
A Spark Compute lehetőség megjelenik a bal oldali menüben:
Feljegyzés
Ha az alapértelmezett készletet a Kezdőkészletről egyéni Spark-készletre módosítja, hosszabb munkamenet-kezdés (~3 perc) jelenhet meg.

Készlet
A munkaterület alapértelmezett készlete
Használhatja az automatikusan létrehozott kezdőkészletet, vagy létrehozhat egyéni készleteket a munkaterülethez.
Kezdőkészlet: Az előre hidratált élő készletek automatikusan létrejönnek a gyorsabb működés érdekében. Ezek a fürtök közepes méretűek. A kezdőkészlet a megvásárolt Fabric-kapacitás termékváltozata alapján alapértelmezett konfigurációra van beállítva. A rendszergazdák a Spark számítási feladatok méretezési követelményei alapján testre szabhatják a maximális csomópontokat és végrehajtókat. További információ: Kezdőkészletek konfigurálása
Egyéni Spark-készlet: A Spark-feladat követelményei alapján méretezheti a csomópontokat, automatikusan skálázhatja és dinamikusan lefoglalhatja a végrehajtókat. Egyéni Spark-készlet létrehozásához a kapacitásadminisztrátornak engedélyeznie kell a Testreszabott munkaterületkészletek beállítást a Kapacitás-rendszergazdai beállítások Spark Compute szakaszában.
Feljegyzés
A testreszabott munkaterületkészletek kapacitásszint-vezérlése alapértelmezés szerint engedélyezve van. További információ: A Fabric-kapacitások adatmérnöki és adatelemzési beállításainak konfigurálása és kezelése.
A rendszergazdák az Új készlet beállítás kiválasztásával egyéni Spark-készleteket hozhatnak létre a számítási igényeik alapján.

A Microsoft Fabrichez készült Apache Spark támogatja az egycsomópontos fürtöket, így a felhasználók kiválaszthatják az 1-ből álló minimális csomópontkonfigurációt, amely esetben az illesztőprogram és a végrehajtó egyetlen csomóponton fut. Ezek az egyetlen csomópontfürtök helyreállítható magas rendelkezésre állást biztosítanak a csomóponthibák során, és jobb feladatmegbízhatóságot biztosítanak a kisebb számítási követelményeket támasztó számítási feladatokhoz. Az egyéni Spark-készletek automatikus skálázási beállítását is engedélyezheti vagy letilthatja. Ha az automatikus skálázás engedélyezve van, a készlet új csomópontokat szerez be a felhasználó által megadott maximális csomópontkorláton belül, és a feladat végrehajtása után kivonja őket a jobb teljesítmény érdekében.
Azt is választhatja, hogy dinamikusan lefoglalja a végrehajtókat az adatmennyiség alapján megadott maximális korláton belül automatikusan optimális számú végrehajtó készletéhez a jobb teljesítmény érdekében.

További információ a Fabrichez készült Apache Spark-számításról.
- Az elemek számítási konfigurációjának testreszabása: Munkaterület-rendszergazdaként engedélyezheti a felhasználóknak, hogy a számítási konfigurációkat (az illesztőprogramot/végrehajtó magot, az illesztőprogramot/végrehajtó memóriát is tartalmazó munkamenetszintű tulajdonságokat) módosítják az egyes elemek, például jegyzetfüzetek, Spark-feladatdefiníciók környezettel való beállításához.
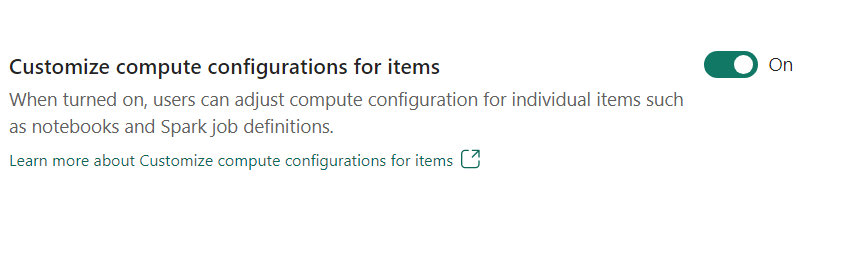
Ha a munkaterület rendszergazdája kikapcsolja a beállítást, a rendszer az alapértelmezett készletet és annak számítási konfigurációit használja a munkaterület összes környezetéhez.
Környezet
A környezet rugalmas konfigurációkat biztosít a Spark-feladatok futtatásához (jegyzetfüzetek, Spark-feladatdefiníciók). Egy környezetben konfigurálhatja a számítási tulajdonságokat, válasszon ki különböző futtatókörnyezetet, és állítsa be a kódtárcsomag függőségeit a számítási feladatok követelményei alapján.
A környezet lapon beállíthatja az alapértelmezett környezetet. Kiválaszthatja, hogy a Spark melyik verzióját szeretné használni a munkaterülethez.
Háló-munkaterület rendszergazdájaként kiválaszthat egy környezetet alapértelmezett munkaterületként.
A Környezet legördülő listában újat is létrehozhat.

Ha letiltja az alapértelmezett környezet beállítását, választhatja a Fabric futtatókörnyezet verzióját a legördülő menüben felsorolt elérhető futtatókörnyezeti verziók közül.

További információ az Apache Spark-futtatókörnyezetekről.
Feladatok
A feladatok beállításai lehetővé teszik a rendszergazdák számára a munkaterület összes Spark-feladatának feladatbeléptetési logikájának szabályozását.

Alapértelmezés szerint minden munkaterület engedélyezve van optimista feladatbeléptetéssel. További információ a Spark feladatbeléptetéséről a Microsoft Fabricben.
Engedélyezheti, hogy az aktív Spark-feladatok maximális magjainak lefoglalása optimista feladatbeléptetés-alapú megközelítést válthasson, és maximális magokat foglaljon le Spark-feladataikhoz.
Beállíthatja a Spark-munkamenet időtúllépését is, hogy testre szabja a munkamenet lejárati idejét az összes jegyzetfüzet interaktív munkamenetéhez.
Feljegyzés
Az interaktív Spark-munkamenetek alapértelmezett lejárati ideje 20 perc.
Magas egyidejűség
A magas egyidejűségi mód lehetővé teszi, hogy a felhasználók ugyanazokat a Spark-munkameneteket osztják meg az Apache Spark for Fabric adatelemzési és adatelemzési számítási feladataiban. Egy olyan elem, mint egy jegyzetfüzet, Spark-munkamenetet használ a végrehajtáshoz, és ha engedélyezve van, a felhasználók egyetlen Spark-munkamenetet oszthatnak meg több jegyzetfüzet között.

További információ az Apache Spark for Fabric magas egyidejűségéről.
Automatikus naplózás Machine Learning-modellekhez és kísérletekhez
A rendszergazdák mostantól engedélyezhetik az automatikus naplózást a gépi tanulási modelljeikhez és kísérleteikhez. Ez a beállítás automatikusan rögzíti a gépi tanulási modell bemeneti paramétereinek, kimeneti metrikáinak és kimeneti elemeinek értékeit a betanítás során. További információ az automatikus keresésről.

Kapcsolódó tartalom
- További információ az Apache Spark-futtatókörnyezetekről a Fabricben – Áttekintés, verziószámozás, több futtatókörnyezet támogatása és a Delta Lake Protocol frissítése.
- További információ az Apache Spark nyilvános dokumentációjából.
- Válaszokat találhat a gyakori kérdésekre: Apache Spark-munkaterület felügyeleti beállításai – gyakori kérdések.