2. oktatóanyag: Hitelkockázati modellek betanítása – Machine Learning Studio (klasszikus)
A KÖVETKEZŐKRE VONATKOZIK:  Machine Learning Studio (klasszikus)
Machine Learning Studio (klasszikus)  Azure Machine Learning
Azure Machine Learning
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- A gépi tanulási projektek ML Studióból (klasszikus) Azure Machine Learningbe való áthelyezéséről szóló információk.
- További információ az Azure Machine Learningről
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Ebben az oktatóanyagban részletes áttekintést nyújt a prediktív elemzési megoldások fejlesztésének folyamatáról. Egy egyszerű modellt fejleszthet a Machine Learning Studióban (klasszikus). Ezután gépi tanulási webszolgáltatásként kell üzembe helyeznie a modellt. Ez az üzembe helyezett modell új adatokkal tud előrejelzéseket készíteni. Ez az oktatóanyag egy háromrészes oktatóanyag-sorozat második része.
Tegyük fel, hogy előrejelzést kell készíteni egy személy hitelkockázatáról az általa kitöltött hitelkérelemben megadott adatok alapján.
A hitelkockázat-felmérés összetett probléma, de ez az oktatóanyag egy kicsit leegyszerűsíti. Példaként fogja használni, hogyan hozhat létre prediktív elemzési megoldást a Machine Learning Studióval (klasszikus). Ehhez a megoldáshoz a Machine Learning Studio (klasszikus) és a Machine Learning webszolgáltatást fogja használni.
Ebben a háromrészes oktatóanyagban a nyilvánosan elérhető hitelkockázati adatokkal kezd. Ezután fejleszthet és taníthat be egy prediktív modellt. Végül webszolgáltatásként helyezi üzembe a modellt.
Az oktatóanyag első részében létrehozott egy Machine Learning Studio-munkaterületet (klasszikus), feltöltött adatokat, és létrehozott egy kísérletet.
Az oktatóanyag jelen részében a következőket fogja elkönyvelni:
- Több modell betanítása
- A modellek pontszáma és kiértékelése
Az oktatóanyag harmadik részében webszolgáltatásként fogja üzembe helyezni a modellt.
Előfeltételek
Végezze el az oktatóanyag első részét.
Több modell betanítása
A Machine Learning Studio (klasszikus) gépi tanulási modellek létrehozásának egyik előnye, hogy egyszerre több modellt is kipróbálhat egyetlen kísérletben, és összehasonlíthatja az eredményeket. Ez a fajta kísérletezés segít megtalálni a legjobb megoldást a problémára.
Az oktatóanyagban fejlesztendő kísérletben két különböző modelltípust fog létrehozni, majd összehasonlítja a pontozási eredményeket, hogy eldöntse, melyik algoritmust szeretné használni a végső kísérletben.
Különböző modellek közül választhat. Az elérhető modellek megtekintéséhez bontsa ki a Machine Learning csomópontot a modulpalettán, majd bontsa ki a Modell inicializálása és az alatta lévő csomópontok csomópontjait. A kísérlet céljaira a kétosztályos támogatási vektorgépet (SVM) és a kétosztályos emelt szintű döntési fa modulokat fogja kiválasztani.
Ebben a kísérletben a kétosztályos emelt szintű döntési fa modult és a kétosztályos támogatási vektorgép-modult is hozzáadja.
Kétosztályos súlyozott döntési fa
Először állítsa be a megnövelt döntésifa-modellt.
Keresse meg a kétosztályos emelt szintű döntési fa modult a modulpalettán, és húzza a vászonra.
Keresse meg a Modell betanítása modult, húzza a vászonra, majd csatlakoztassa a Kétosztályos növelt döntési fa modul kimenetét a Modell betanítása modul bal oldali bemeneti portjához.
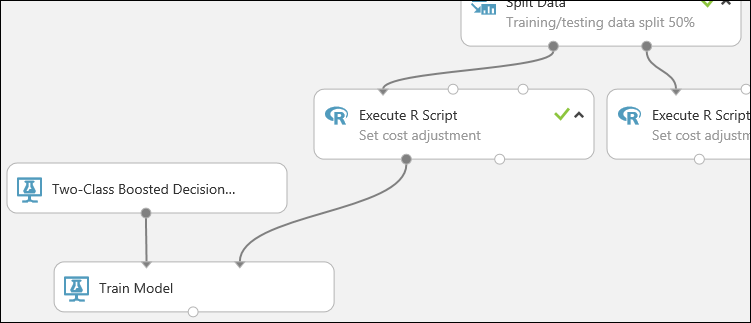
A kétosztályos emelt szintű döntési fa modul inicializálja az általános modellt, a Betanítási modell pedig betanítási adatokat használ a modell betanításához.
Csatlakoztassa a bal oldali Execute R Script modul bal kimenetét a Betanítási modell modul jobb bemeneti portjához (ebben az oktatóanyagban a Split Data modul bal oldaláról érkező adatokat használta betanításhoz).
Tipp.
Ehhez a kísérlethez nincs szükség két bemenetre és az Execute R Script modul egyik kimenetére, így azok nem lesznek gyorsítótárazva.
A kísérlet ezen része a következőképpen néz ki:
Most meg kell mondania a Modell betanítása modulnak, hogy a modell előrejelzi a hitelkockázat értékét.
Válassza a Modell betanítása modult. A Tulajdonságok panelen kattintson a Launch column selector (Oszlop indítása) gombra.
Az Egyetlen oszlop kijelölése párbeszédpanelen írja be a "hitelkockázat" kifejezést az Elérhető oszlopok keresőmezőbe, válassza az alatta lévő "Hitelkockázat" lehetőséget, majd a jobb nyílra (>) kattintva helyezze át a "Hitelkockázat" szöveget a kijelölt oszlopokra.
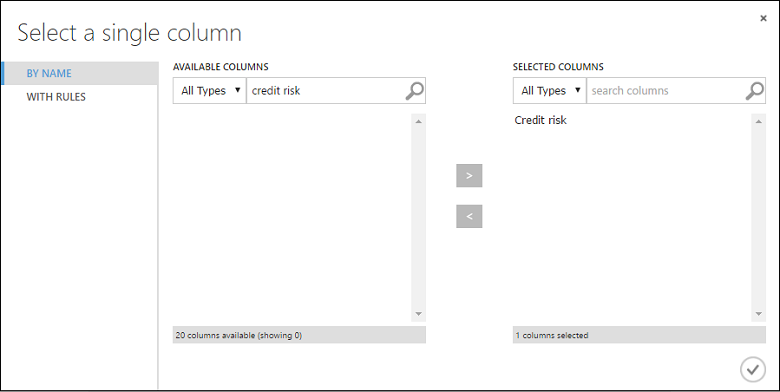
Kattintson az OK pipára .
Kétosztályos támogató vektorgép
Ezután be kell állítania az SVM-modellt.
Először is, egy kis magyarázat az SVM-ről. A megnövelt döntési fák bármilyen típusú funkcióval jól működnek. Mivel azonban az SVM-modul lineáris osztályozót hoz létre, az általa létrehozott modell a legjobb teszthiba, ha minden numerikus funkció azonos skálával rendelkezik. Ha az összes numerikus funkciót ugyanarra a skálára szeretné konvertálni, "Tanh" átalakítást kell használnia (az Adatok normalizálása modullal). Ez átalakítja a számokat a [0,1] tartományba. Az SVM-modul a sztringszolgáltatásokat kategorikus, majd bináris 0/1 funkciókká alakítja át, így nem kell manuálisan átalakítania a sztringfunkciókat. Emellett nem szeretné átalakítani a Hitelkockázat oszlopot (21. oszlop) – ez numerikus, de ez az az érték, amelyet a modell előrejelzésére tanítunk be, ezért egyedül kell hagynia.
Az SVM-modell beállításához tegye a következőket:
Keresse meg a kétosztályos támogatási vektorgép modult a modulpalettán, és húzza a vászonra.
Kattintson a jobb gombbal a Modell betanítása modulra, válassza a Másolás lehetőséget, majd kattintson a jobb gombbal a vászonra, és válassza a Beillesztés parancsot. A Modell betanítása modul másolata ugyanazzal az oszlopkiválasztással rendelkezik, mint az eredeti.
Csatlakoztassa a kétosztályos támogatási vektorgép modul kimenetét a második Betanított modell modul bal oldali bemeneti portjához.
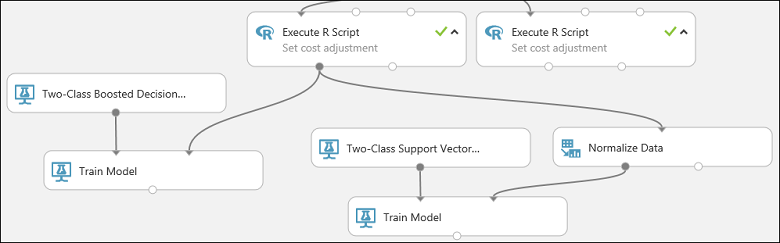
Keresse meg a Normalize Data modult, és húzza a vászonra.
Csatlakoztassa a bal oldali Execute R Script modul bal kimenetét a modul bemenetéhez (figyelje meg, hogy egy modul kimeneti portja több modulhoz is csatlakoztatható).
Csatlakoztassa a Normalize Data modul bal oldali kimeneti portját a második Betanítási modell modul jobb oldali bemeneti portjához.
A kísérlet ezen részének a következőhöz hasonlóan kell kinéznie:
Most konfigurálja az Adat normalizálása modult:
Kattintson ide az Adatok normalizálása modul kiválasztásához. A Tulajdonságok panelen válassza a Tanh lehetőséget az Átalakítási módszer paraméterhez.
Kattintson a Launch column selector (Oszlop indítása) gombra, válassza a "Nincs oszlop" lehetőséget a Kezdő gombnál, válassza a Belefoglalás lehetőséget az első legördülő menübe, válassza ki az oszloptípust a második legördülő menüben, és válassza a Numerikus lehetőséget a harmadik legördülő listában. Ez azt határozza meg, hogy az összes numerikus oszlop (és csak numerikus) átalakítva legyen.
Kattintson a sortól jobbra található pluszjelre (+) – ez legördülő sorokat hoz létre. Válassza a Kizárás lehetőséget az első legördülő menüben, jelölje ki az oszlopneveket a második legördülő menüben, és írja be a "Hitelkockázat" kifejezést a szövegmezőbe. Ez azt határozza meg, hogy a Hitelkockázat oszlopot figyelmen kívül kell hagyni (ezt azért kell megtennie, mert ez az oszlop numerikus, ezért a rendszer átalakítja, ha nem zárja ki).
Kattintson az OK pipára .
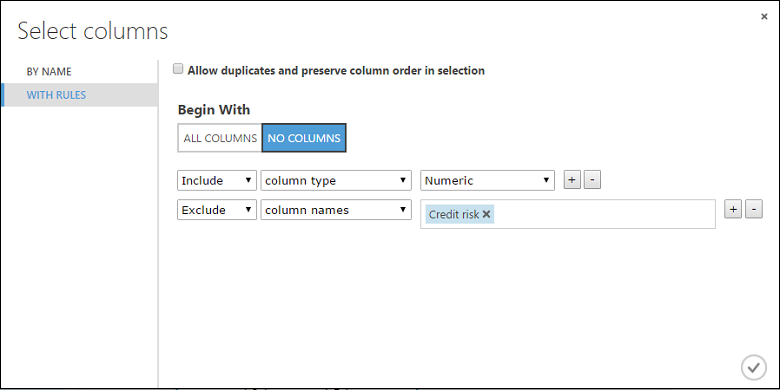
Az Adat normalizálása modul mostantól úgy van beállítva, hogy tanh-átalakítást hajtson végre az összes numerikus oszlopon, kivéve a Hitelkockázat oszlopot.
A modellek pontszáma és kiértékelése
a Split Data modul által elválasztott tesztelési adatokat használja a betanított modellek pontozásához. Ezután összehasonlíthatja a két modell eredményeit, hogy lássa, melyik hozott létre jobb eredményeket.
A Score Model modulok hozzáadása
Keresse meg a Score Model modult, és húzza a vászonra.
Csatlakoztassa a Modell betanítása modult, amely a Kétosztályos növelt döntési fa modulhoz csatlakozik a Score Model modul bal oldali bemeneti portjához.
Csatlakoztassa a megfelelő Execute R Script modult (a tesztelési adatokat) a Score Model modul megfelelő bemeneti portjához.
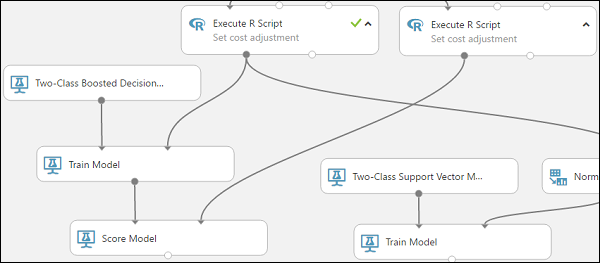
A Pontszámmodell modul mostantól a tesztelési adatokból átveheti a kreditadatokat, futtathatja a modellt, és összehasonlíthatja a modell által generált előrejelzéseket a tesztelési adatok tényleges hitelkockázati oszlopával.
Másolja és illessze be a Score Model modult egy második példány létrehozásához.
Csatlakoztassa az SVM-modell kimenetét (azaz a Kétosztályos támogatási vektorgép modulhoz csatlakoztatott Modell betanítása modul kimeneti portját) a második Pontszámmodell modul bemeneti portjához.
Az SVM-modell esetében ugyanazt az átalakítást kell elvégeznie a tesztelési adatokon, mint a betanítási adatokon. Másolja és illessze be a Normalize Data modult egy második példány létrehozásához, és csatlakoztassa a megfelelő Execute R Script modulhoz.
Csatlakoztassa a második Normalize Data modul bal oldali kimenetét a második Score Model modul jobb bemeneti portjához.
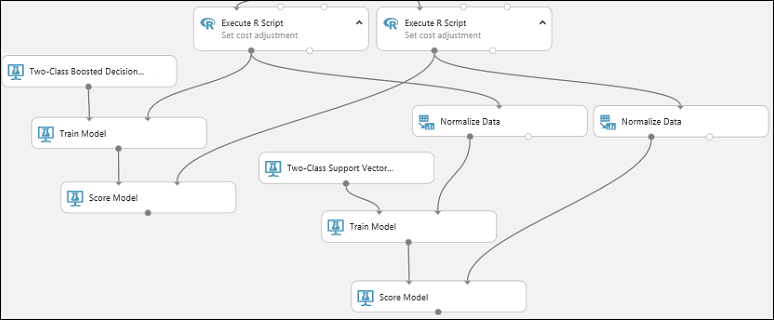
A Modell kiértékelése modul hozzáadása
A két pontozási eredmény kiértékeléséhez és összehasonlításához egy Modell kiértékelése modult kell használnia.
Keresse meg a Modell kiértékelése modult, és húzza a vászonra.
Csatlakoztassa a kiemelt döntési famodellhez társított Score Model modul kimeneti portját a Modell kiértékelése modul bal oldali bemeneti portjához.
Csatlakoztassa a másik Score Model modult a megfelelő bemeneti porthoz.
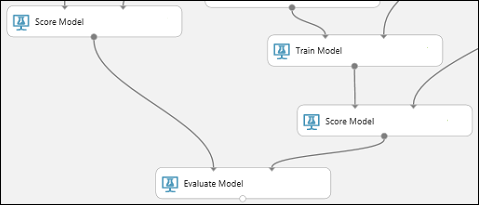
A kísérlet futtatása és az eredmények ellenőrzése
A kísérlet futtatásához kattintson a vászon alatti FUTTATÁS gombra. Ez eltarthat néhány percig. Az egyes modulokon forgó jelző jelzi, hogy fut, majd egy zöld pipa jelzi, hogy mikor fejeződött be a modul. Ha az összes modul rendelkezik pipával, a kísérlet befejeződött.
A kísérletnek így kell kinéznie:
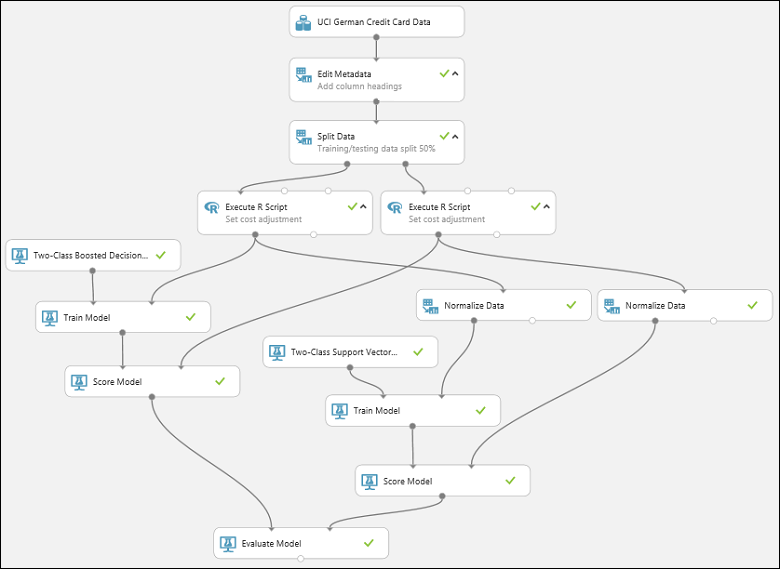
Az eredmények ellenőrzéséhez kattintson a Modell kiértékelése modul kimeneti portjára, és válassza a Vizualizáció lehetőséget.
A Modell kiértékelése modul olyan görbéket és metrikákat hoz létre, amelyek lehetővé teszik a két pontozott modell eredményeinek összehasonlítását. Az eredményeket a Receiver Operator Characteristic (ROC) görbék, a pontossági/visszahívási görbék vagy a Lift görbékként tekintheti meg. A további megjelenített adatok közé tartozik egy keveredési mátrix, a görbe alatti terület összesített értékei (AUC) és egyéb metrikák. A küszöbértéket a csúszka balra vagy jobbra mozgatásával módosíthatja, és megtekintheti, hogy ez hogyan befolyásolja a metrikák készletét.
A diagram jobb oldalán kattintson a Pontozott adathalmaz vagy a Pontozott adathalmaz elemre a kapcsolódó görbe kiemeléséhez és az alábbi metrikák megjelenítéséhez. A görbék jelmagyarázatában a "Scored dataset" a Modell kiértékelése modul bal oldali bemeneti portjának felel meg – esetünkben ez a megnövelt döntésifa-modell. Az "összehasonlítandó pontozott adatkészlet" a megfelelő bemeneti portnak felel meg – esetünkben az SVM-modellnek. Amikor az egyik címkére kattint, a modell görbéje ki lesz emelve, és megjelennek a megfelelő metrikák, ahogy az alábbi ábrán látható.
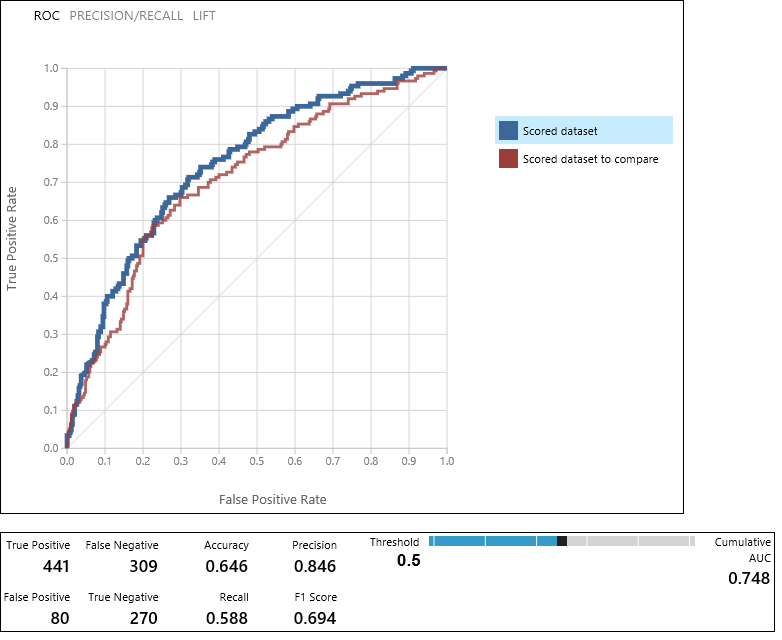
Az értékek vizsgálatával eldöntheti, hogy melyik modell áll legközelebb a keresett eredmények megadásához. Visszatérhet a kísérlethez, és iterálhat a különböző modellek paraméterértékeinek módosításával.
Az eredmények értelmezésének és a modell teljesítményének finomhangolásának tudománya és művészete kívül esik az oktatóanyag hatókörén. További segítségért olvassa el a következő cikkeket:
- Modellteljesítmény kiértékelése a Machine Learning Studióban (klasszikus)
- Paraméterek kiválasztása az algoritmusok optimalizálásához a Machine Learning Studióban (klasszikus)
- Modelleredmények értelmezése a Machine Learning Studióban (klasszikus)
Tipp.
Minden alkalommal, amikor futtatja a kísérletet, az iteráció rekordja a futtatási előzmények között marad. Ezeket az iterációkat megtekintheti, és bármelyikre visszatérhet, ha a vásznon a FUTTATÁSI ELŐZMÉNYEK MEGTEKINTÉSE gombra kattint. A Tulajdonságok panelen az Előzetes futtatás gombra kattintva visszatérhet a megnyitott iterációhoz.
A kísérlet iterációiról másolatot készíthet a vászon alatti MENTÉS MÁSKÉNT gombra kattintva. A kísérlet összegzési és leírási tulajdonságaival rögzítheti, hogy mit próbált meg a kísérlet iterációiban.
További információ: Kísérlet iterációk kezelése a Machine Learning Studióban (klasszikus)
Az erőforrások eltávolítása
Ha már nincs szüksége a cikk használatával létrehozott erőforrásokra, törölje őket, hogy elkerülje a díjak felmerülését. Ebből a cikkből megtudhatja, hogyan exportálhatja és törölheti a terméken belüli felhasználói adatokat.
Következő lépések
Ebben az oktatóanyagban az alábbi lépéseket hajtotta végre:
- Kísérlet létrehozása
- Több modell betanítása
- A modellek pontszáma és kiértékelése
Most már készen áll az adatok modelljeinek üzembe helyezésére.