Memantau kualitas dan penggunaan token aplikasi alur prompt yang disebarkan
Penting
Beberapa fitur yang dijelaskan dalam artikel ini mungkin hanya tersedia dalam pratinjau. Pratinjau ini disediakan tanpa perjanjian tingkat layanan, dan kami tidak merekomendasikannya untuk beban kerja produksi. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Memantau aplikasi yang disebarkan ke produksi adalah bagian penting dari siklus hidup aplikasi AI generatif. Perubahan perilaku data dan konsumen dapat memengaruhi aplikasi Anda dari waktu ke waktu, yang mengakibatkan sistem kedaluarsa yang berdampak negatif pada hasil bisnis dan mengekspos organisasi terhadap risiko kepatuhan, ekonomi, dan reputasi.
Pemantauan Azure AI untuk aplikasi AI generatif memungkinkan Anda memantau aplikasi Anda dalam produksi untuk penggunaan token, kualitas pembuatan, dan metrik operasional.
Integrasi untuk memantau penyebaran alur perintah memungkinkan Anda untuk:
- Kumpulkan data inferensi produksi dari aplikasi alur prompt yang Anda sebarkan.
- Terapkan metrik evaluasi AI yang Bertanggung Jawab seperti groundedness, koherensi, kefasihan, dan relevansi, yang dapat dioperasikan dengan metrik evaluasi aliran prompt.
- Pantau perintah, penyelesaian, dan total penggunaan token di setiap penyebaran model dalam alur permintaan Anda.
- Pantau metrik operasional, seperti jumlah permintaan, latensi, dan tingkat kesalahan.
- Gunakan pemberitahuan dan default yang telah dikonfigurasi sebelumnya untuk menjalankan pemantauan secara berulang.
- Gunakan visualisasi data dan konfigurasikan perilaku tingkat lanjut di Azure AI Studio.
Prasyarat
Sebelum mengikuti langkah-langkah dalam artikel ini, pastikan Anda memiliki prasyarat berikut:
Langganan Azure dengan metode pembayaran yang valid. Langganan Azure gratis atau uji coba tidak akan berfungsi. Jika Anda tidak memiliki langganan Azure, buat akun Azure berbayar untuk memulai.
Proyek Azure AI Studio.
Alur prompt siap untuk penyebaran. Jika Anda tidak memilikinya, lihat Mengembangkan alur permintaan.
Kontrol akses berbasis peran Azure (Azure RBAC) digunakan untuk memberikan akses ke operasi di Azure AI Studio. Untuk melakukan langkah-langkah dalam artikel ini, akun pengguna Anda harus diberi peran Pengembang Azure AI pada grup sumber daya. Untuk informasi selengkapnya tentang izin, lihat Kontrol akses berbasis peran di Azure AI Studio.
Persyaratan untuk memantau metrik
Metrik pemantauan dihasilkan oleh model bahasa GPT canggih tertentu yang dikonfigurasi dengan instruksi evaluasi tertentu (templat perintah). Model ini bertindak sebagai model evaluator untuk tugas urutan ke urutan. Penggunaan teknik ini untuk menghasilkan metrik pemantauan menunjukkan hasil empiris yang kuat dan korelasi tinggi dengan penilaian manusia jika dibandingkan dengan metrik evaluasi AI generatif standar. Untuk informasi selengkapnya tentang evaluasi alur perintah, lihat mengirimkan pengujian massal dan mengevaluasi alur dan evaluasi serta memantau metrik untuk AI generatif.
Model GPT yang menghasilkan metrik pemantauan adalah sebagai berikut. Model GPT ini didukung dengan pemantauan dan dikonfigurasi sebagai sumber daya Azure OpenAI Anda:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Metrik yang didukung untuk pemantauan
Metrik berikut didukung untuk pemantauan:
| Metrik | Deskripsi |
|---|---|
| Groundedness | Mengukur seberapa baik jawaban yang dihasilkan model selaras dengan informasi dari data sumber (konteks yang ditentukan pengguna.) |
| Relevansi | Mengukur sejauh mana respons model yang dihasilkan berkaitan dan terkait langsung dengan pertanyaan yang diberikan. |
| Koherensi | Mengukur sejauh mana respons yang dihasilkan model secara logis konsisten dan terhubung. |
| Kelancaran | Mengukur kecakupan tata bahasa jawaban terprediksi AI generatif. |
Pemetaan nama kolom
Saat membuat alur, Anda perlu memastikan bahwa nama kolom Anda dipetakan. Nama kolom data input berikut digunakan untuk mengukur keamanan dan kualitas pembuatan:
| Nama kolom input | Definisi | Diperlukan/Opsional |
|---|---|---|
| Pertanyaan | Perintah asli yang diberikan (juga dikenal sebagai "input" atau "pertanyaan") | Wajib |
| Jawaban | Penyelesaian akhir dari panggilan API yang dikembalikan (juga dikenal sebagai "output" atau "jawaban") | Wajib |
| Konteks | Data konteks apa pun yang dikirim ke panggilan API, bersama dengan prompt asli. Misalnya, jika Anda berharap untuk mendapatkan hasil pencarian hanya dari sumber informasi atau situs web bersertifikat tertentu, Anda dapat menentukan konteks ini dalam langkah-langkah evaluasi. | Opsional |
Parameter yang diperlukan untuk metrik
Parameter yang dikonfigurasi dalam aset data Anda menentukan metrik apa yang dapat Anda hasilkan, sesuai dengan tabel ini:
| Metric | Pertanyaan | Jawaban | Konteks |
|---|---|---|---|
| Koherensi | Wajib | Wajib | - |
| Kelancaran | Wajib | Wajib | - |
| Groundedness | Wajib | Diperlukan | Wajib |
| Relevansi | Wajib | Diperlukan | Wajib |
Untuk informasi selengkapnya tentang persyaratan pemetaan data tertentu untuk setiap metrik, lihat Persyaratan metrik jawaban atas pertanyaan.
Menyiapkan pemantauan untuk alur perintah
Untuk menyiapkan pemantauan untuk aplikasi alur perintah, Anda harus terlebih dahulu menyebarkan aplikasi alur perintah dengan pengumpulan data inferensi, lalu Anda dapat mengonfigurasi pemantauan untuk aplikasi yang disebarkan.
Menyebarkan aplikasi alur perintah Anda dengan pengumpulan data inferensi
Di bagian ini, Anda belajar menyebarkan alur prompt dengan mengaktifkan pengumpulan data inferensi. Untuk informasi terperinci tentang penyebaran alur prompt Anda, lihat Menyebarkan alur untuk inferensi real-time.
Masuk ke Azure AI Studio.
Buka proyek Azure AI Studio Anda.
Dari bilah navigasi kiri, buka Alur Permintaan Alat>.
Pilih alur perintah yang Anda buat sebelumnya.
Catatan
Artikel ini mengasumsikan bahwa Anda sudah membuat alur perintah yang siap untuk penyebaran. Jika Anda tidak memilikinya, lihat Mengembangkan alur permintaan.
Konfirmasikan bahwa alur Anda berhasil berjalan dan bahwa input dan output yang diperlukan dikonfigurasi untuk metrik yang ingin Anda nilai.
Menyediakan parameter minimum yang diperlukan (pertanyaan/input dan jawaban/output) hanya menyediakan dua metrik: koherensi dan kefasihan. Anda harus mengonfigurasi alur seperti yang dijelaskan di bagian persyaratan untuk metrik pemantauan. Contoh ini menggunakan,
question(Pertanyaan) danchat_history(Konteks) sebagai input alur, dananswer(Jawaban) sebagai output alur.Pilih Sebarkan untuk mulai menyebarkan alur Anda.
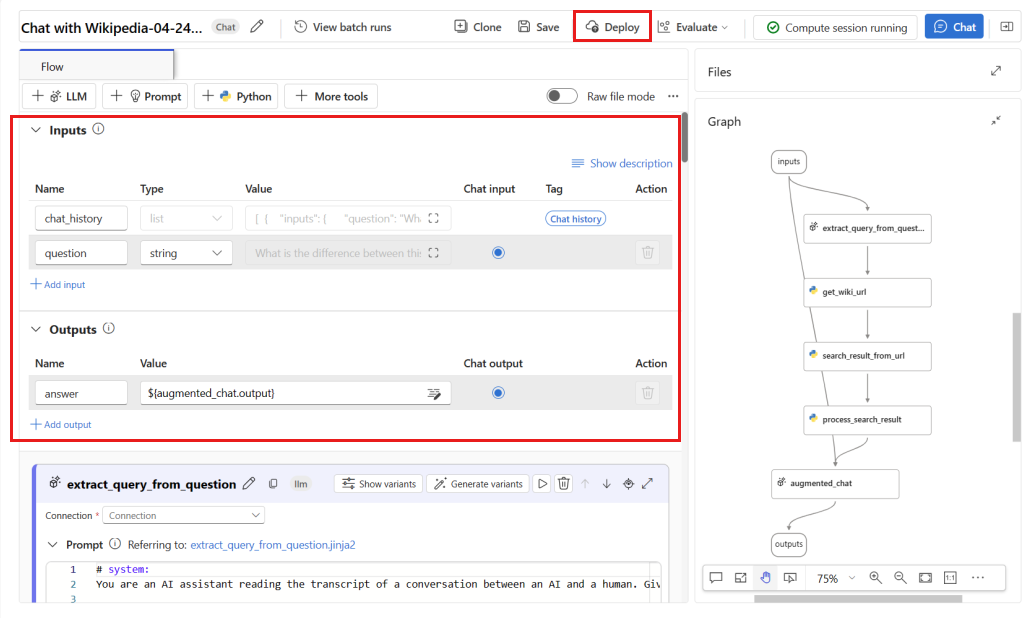
Di jendela penyebaran, pastikan pengumpulan data Inferensi diaktifkan, yang akan mengumpulkan data inferensi aplikasi Anda dengan lancar ke Blob Storage. Pengumpulan data ini diperlukan untuk pemantauan.
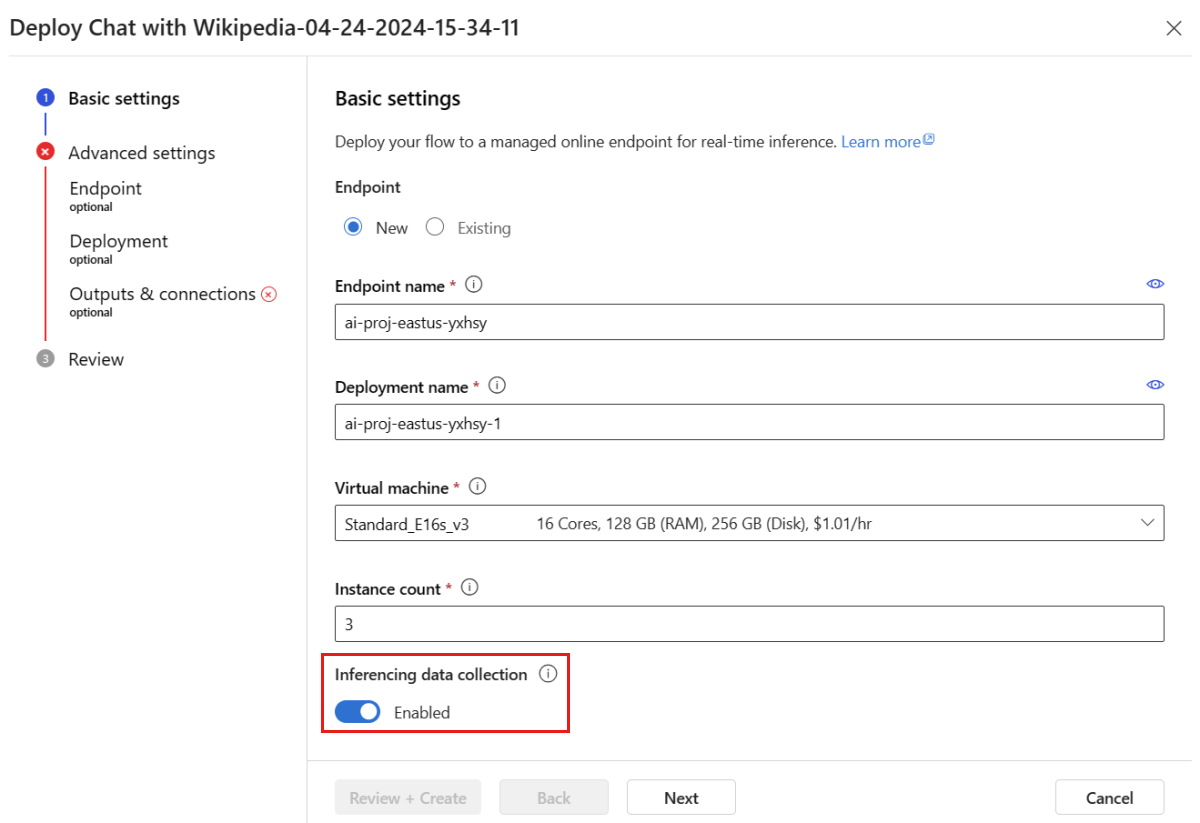
Lanjutkan melalui langkah-langkah di jendela penyebaran untuk menyelesaikan pengaturan Tingkat Lanjut.
Pada halaman "Tinjau", tinjau konfigurasi penyebaran dan pilih Buat untuk menyebarkan alur Anda.
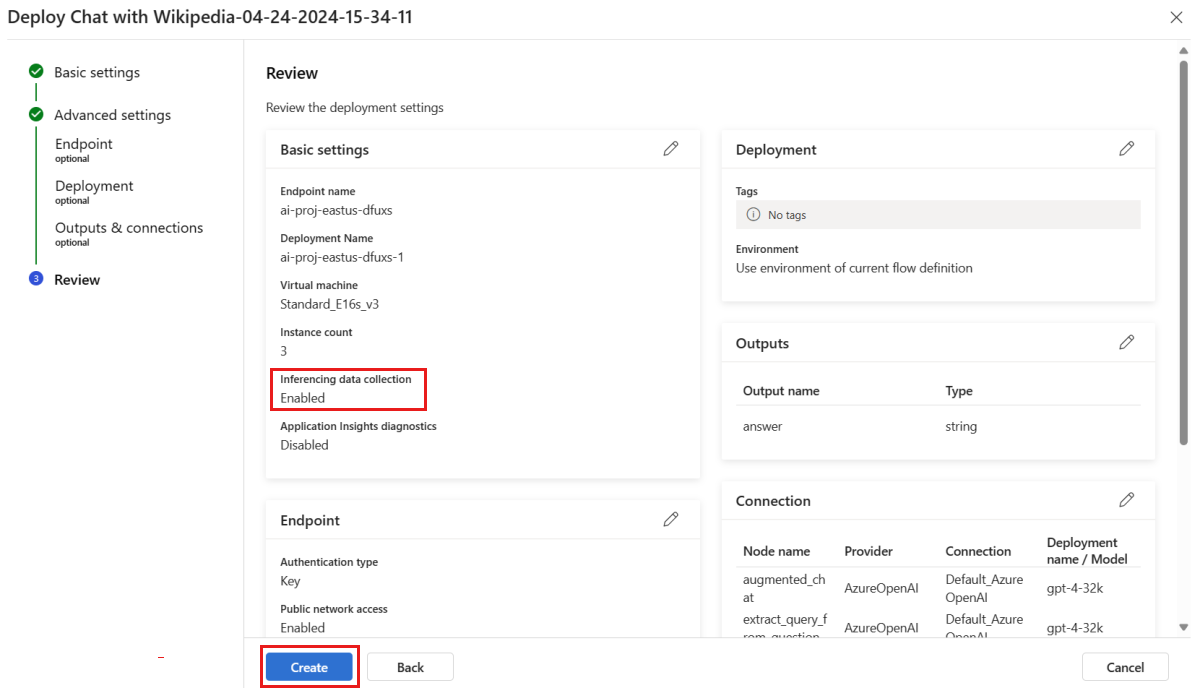
Catatan
Secara default, semua input dan output aplikasi alur prompt yang Anda sebarkan dikumpulkan ke Blob Storage Anda. Saat penyebaran dipanggil oleh pengguna, data dikumpulkan untuk digunakan oleh monitor Anda.
Pilih tab Uji pada halaman penyebaran, dan uji penyebaran Anda untuk memastikan bahwa penyebaran berfungsi dengan baik.
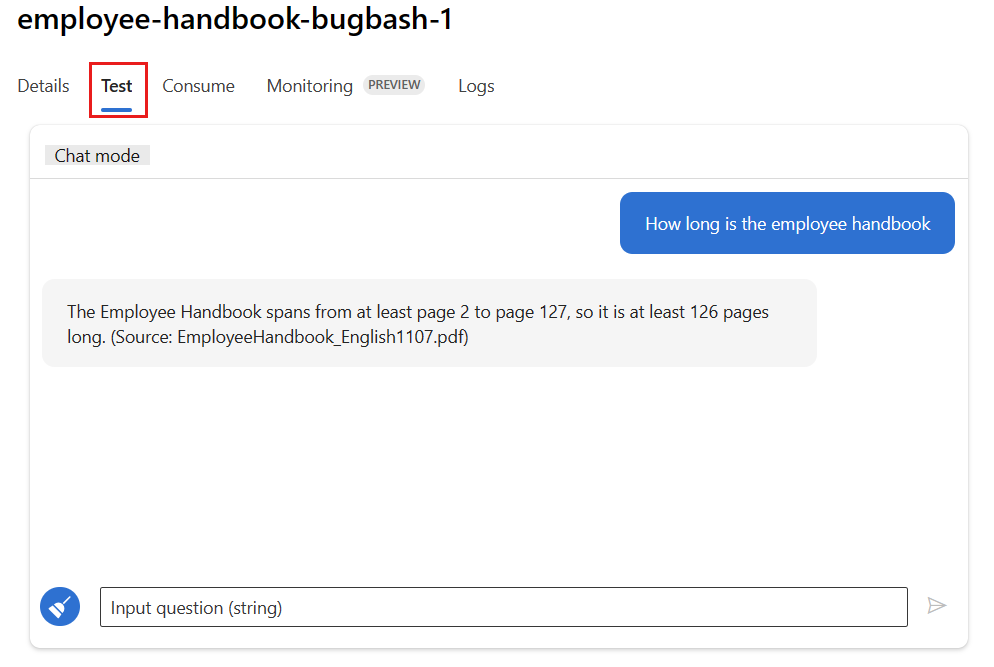
Catatan
Pemantauan mengharuskan setidaknya satu titik data berasal dari sumber selain tab Uji dalam penyebaran. Sebaiknya gunakan REST API yang tersedia di tab Konsumsi untuk mengirim permintaan sampel ke penyebaran Anda. Untuk informasi selengkapnya tentang cara mengirim permintaan sampel ke penyebaran Anda, lihat Membuat penyebaran online.




Mengonfigurasi pemantauan
Di bagian ini, Anda mempelajari cara mengonfigurasi pemantauan untuk aplikasi alur prompt yang disebarkan.
Dari bilah navigasi kiri, buka Penyebaran Komponen>.
Pilih penyebaran alur perintah yang baru saja Anda buat.
Pilih Aktifkan dalam kotak Aktifkan pemantauan kualitas pembuatan.
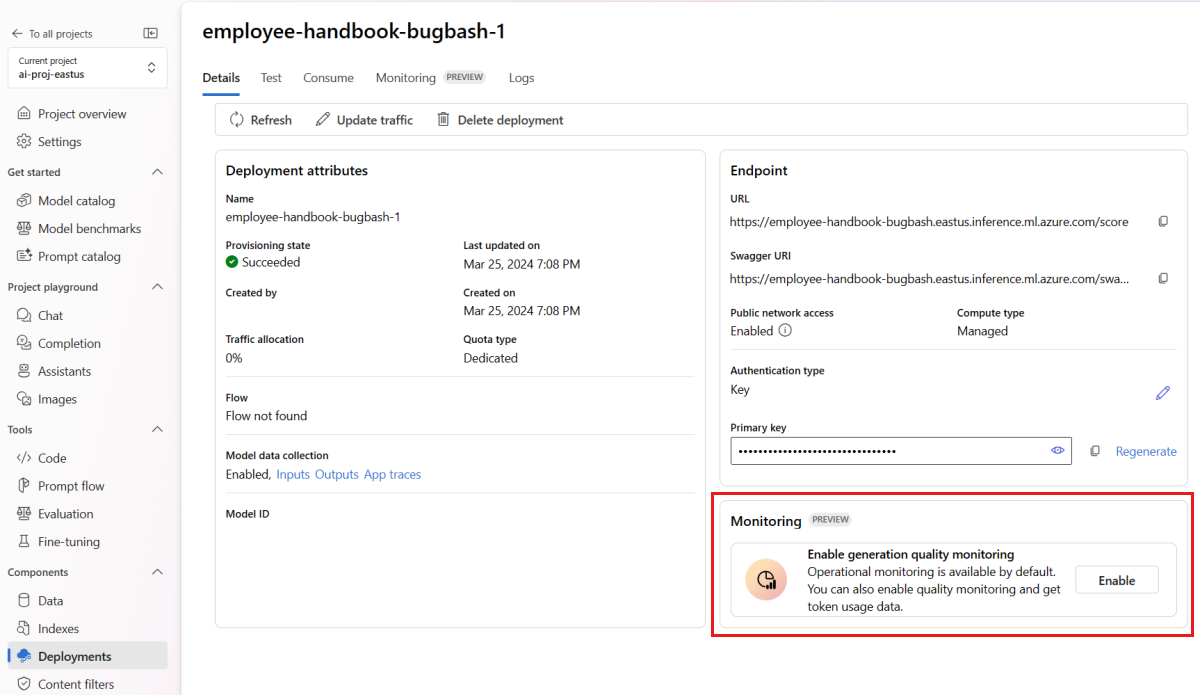
Mulai konfigurasikan pemantauan dengan memilih metrik yang Anda inginkan.
Konfirmasikan bahwa nama kolom Anda dipetakan dari alur Anda seperti yang ditentukan dalam Pemetaan nama kolom.
Pilih Koneksi dan Penyebaran Azure OpenAI yang ingin Anda gunakan untuk melakukan pemantauan untuk aplikasi alur permintaan Anda.
Pilih Opsi tingkat lanjut untuk melihat opsi lainnya untuk dikonfigurasi.
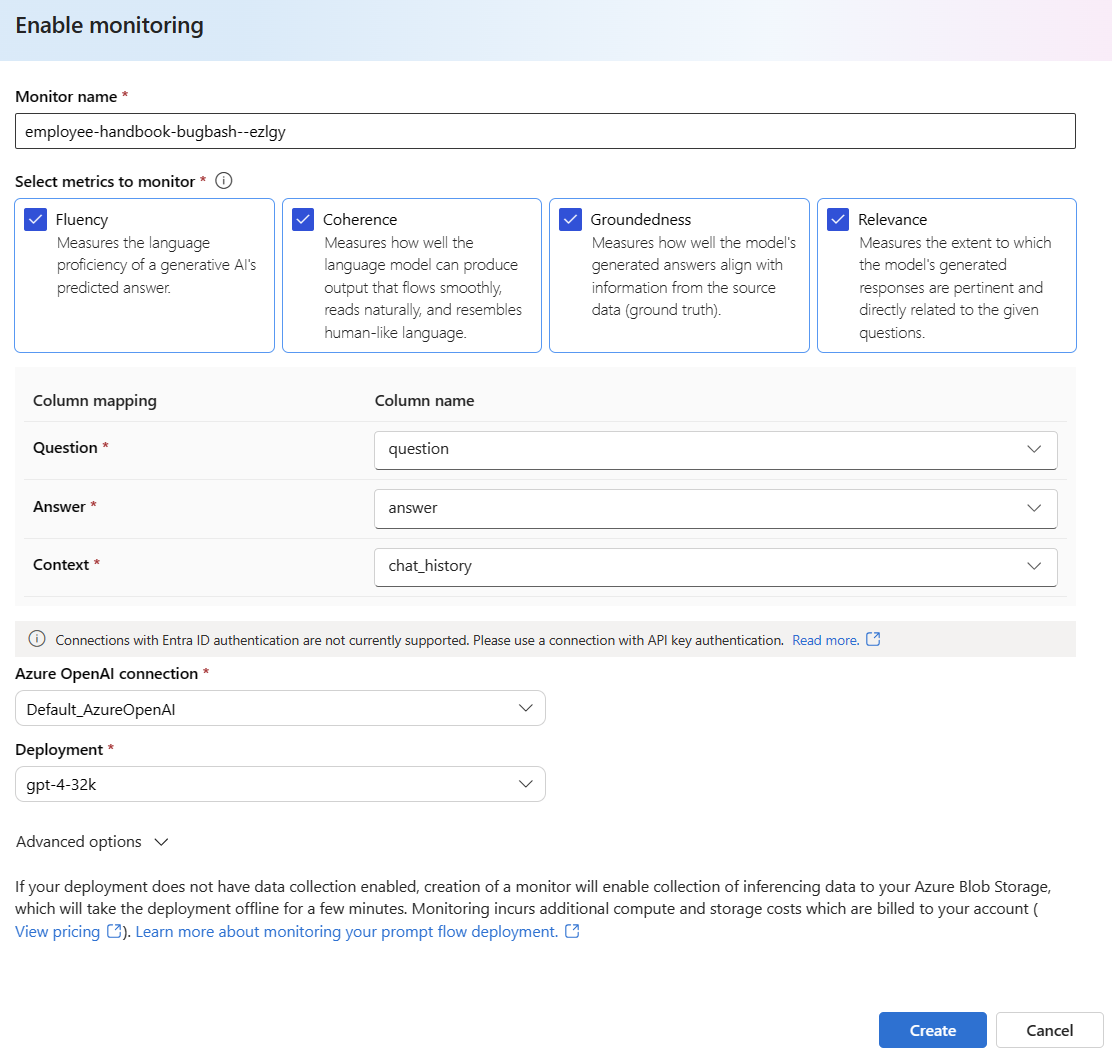
Sesuaikan laju pengambilan sampel, ambang batas untuk metrik yang Dikonfigurasi, dan tentukan alamat email yang harus menerima pemberitahuan saat skor rata-rata untuk metrik tertentu berada di bawah ambang batas.
Catatan
Jika penyebaran Anda tidak mengaktifkan pengumpulan data, pembuatan monitor akan memungkinkan pengumpulan data inferensi ke Azure Blob Storage Anda, yang akan membuat penyebaran offline selama beberapa menit.
Pilih Buat untuk membuat monitor Anda.



Mengonsumsi hasil pemantauan
Setelah Anda membuat monitor, monitor akan berjalan setiap hari untuk menghitung penggunaan token dan metrik kualitas pembuatan.
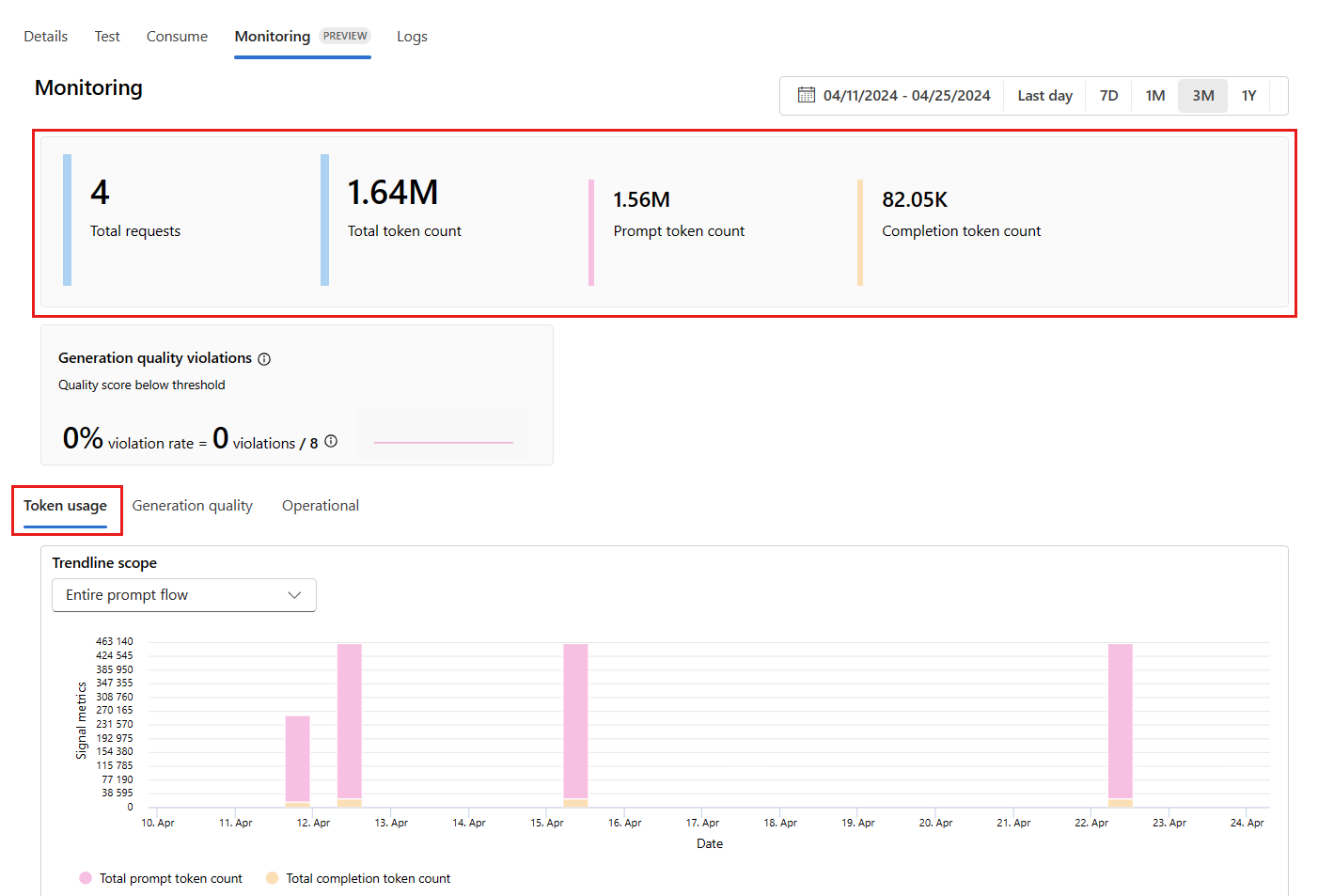
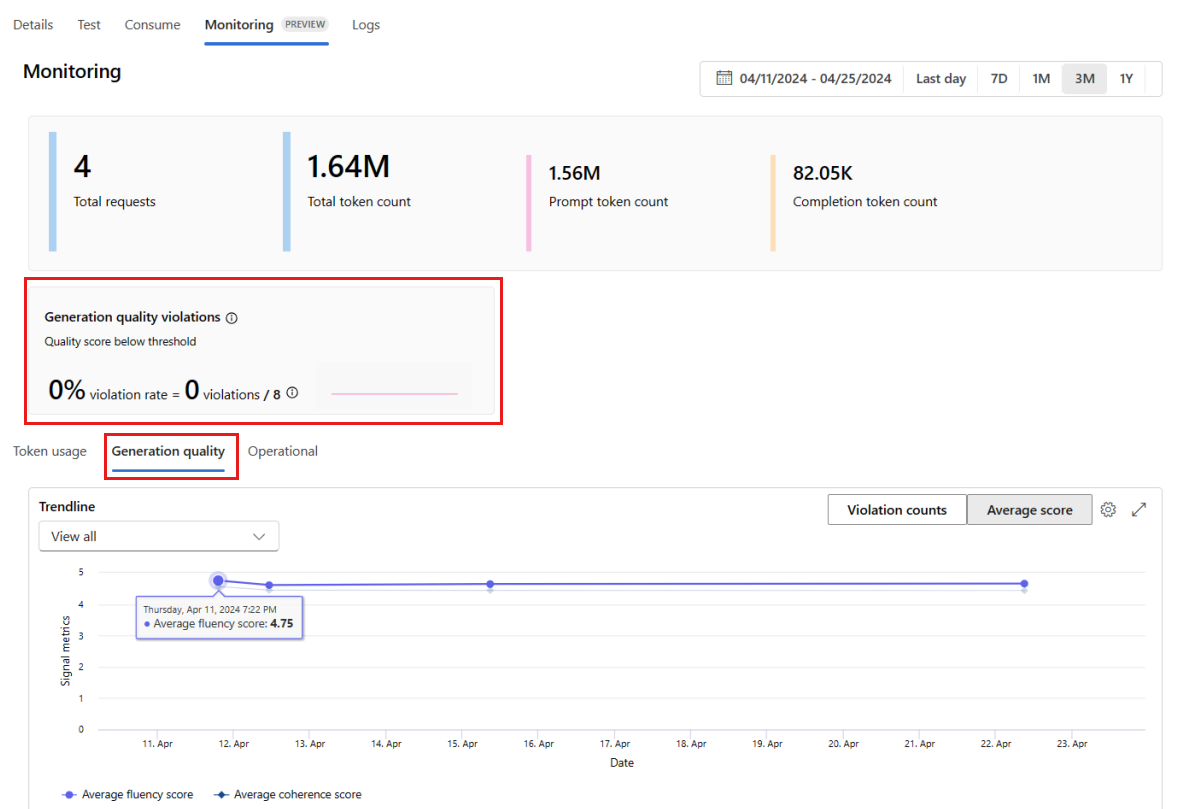
Buka tab Pemantauan (pratinjau) dari dalam penyebaran untuk melihat hasil pemantauan. Di sini, Anda akan melihat gambaran umum hasil pemantauan selama jendela waktu yang dipilih. Anda dapat menggunakan pemilih tanggal untuk mengubah jendela waktu data yang Anda pantau. Metrik berikut tersedia dalam gambaran umum ini:
- Jumlah permintaan total: Jumlah total permintaan yang dikirim ke penyebaran selama jendela waktu yang dipilih.
- Jumlah token total: Jumlah total token yang digunakan oleh penyebaran selama jendela waktu yang dipilih.
- Jumlah token perintah: Jumlah token prompt yang digunakan oleh penyebaran selama jendela waktu yang dipilih.
- Jumlah token penyelesaian: Jumlah token penyelesaian yang digunakan oleh penyebaran selama jendela waktu yang dipilih.
Lihat metrik di tab Penggunaan token (tab ini dipilih secara default). Di sini, Anda dapat melihat penggunaan token aplikasi Anda dari waktu ke waktu. Anda juga dapat melihat distribusi token perintah dan penyelesaian dari waktu ke waktu. Anda dapat mengubah cakupan Trendline untuk memantau semua token di seluruh aplikasi atau penggunaan token untuk penyebaran tertentu (misalnya, gpt-4) yang digunakan dalam aplikasi Anda.
Buka tab Kualitas pembuatan untuk memantau kualitas aplikasi Anda dari waktu ke waktu. Metrik berikut diperlihatkan dalam bagan waktu:
- Jumlah pelanggaran: Jumlah pelanggaran untuk metrik tertentu (misalnya, Fluency) adalah jumlah pelanggaran selama jendela waktu yang dipilih. Pelanggaran terjadi untuk metrik ketika metrik dihitung (defaultnya adalah harian) jika nilai komputasi untuk metrik berada di bawah nilai ambang yang ditetapkan.
- Skor rata-rata: Skor rata-rata untuk metrik tertentu (misalnya, Fluency) adalah jumlah skor untuk semua instans (atau permintaan) dibagi dengan jumlah instans (atau permintaan) selama jendela waktu yang dipilih.
Kartu Pelanggaran kualitas pembuatan menunjukkan tingkat pelanggaran selama jendela waktu yang dipilih. Tingkat pelanggaran adalah jumlah pelanggaran yang dibagi dengan jumlah total kemungkinan pelanggaran. Anda dapat menyesuaikan ambang batas untuk metrik dalam pengaturan. Secara default, metrik dihitung setiap hari; frekuensi ini juga dapat disesuaikan dalam pengaturan.
Dari tab Pemantauan (Pratinjau) , Anda juga dapat melihat tabel komprehensif dari semua permintaan sampel yang dikirim ke penyebaran selama jendela waktu yang dipilih.
Catatan
Pemantauan menetapkan laju pengambilan sampel default pada 10%. Ini berarti bahwa jika 100 permintaan dikirim ke penyebaran Anda, 10 mendapatkan sampel dan digunakan untuk menghitung metrik kualitas pembuatan. Anda dapat menyesuaikan laju pengambilan sampel di pengaturan.
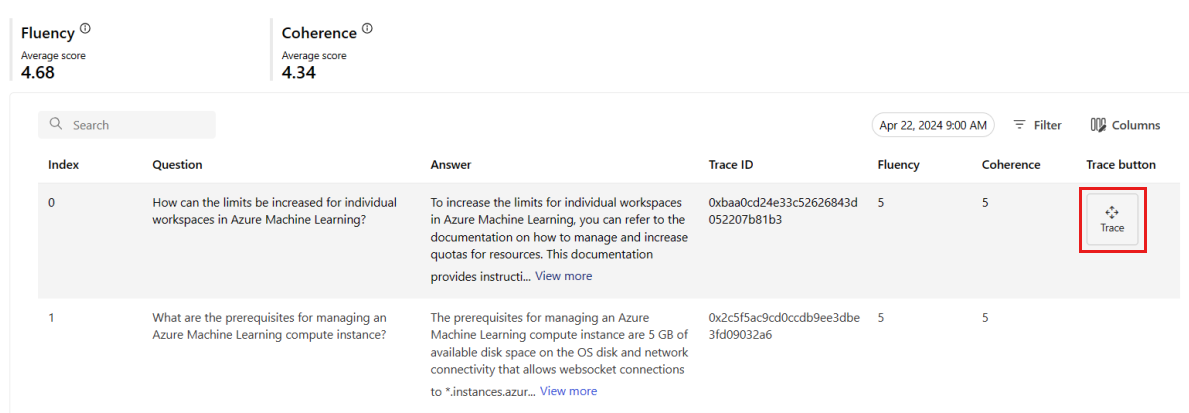
Pilih tombol Lacak di sisi kanan baris dalam tabel untuk melihat detail pelacakan untuk permintaan tertentu. Tampilan ini menyediakan detail pelacakan komprehensif untuk permintaan ke aplikasi Anda.
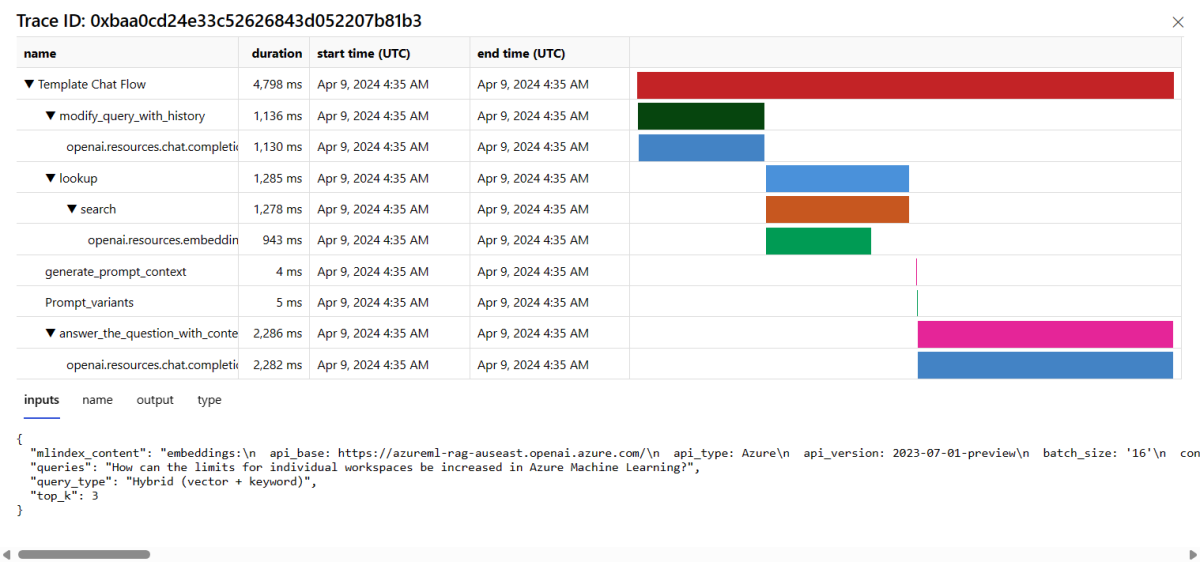
Tutup tampilan Pelacakan.
Buka tab Operasional untuk melihat metrik operasional untuk penyebaran mendekati real-time. Kami mendukung metrik operasional berikut:
- Jumlah permintaan
- Latensi
- Tingkat kesalahan
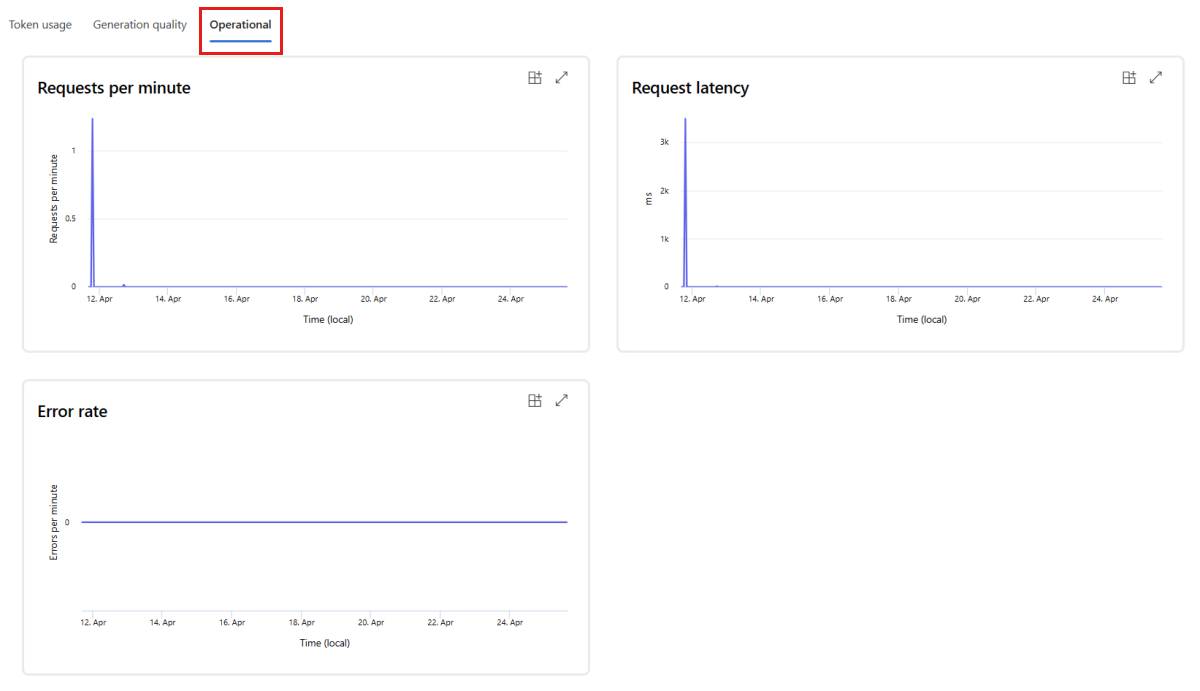





Hasilnya di tab Pemantauan (pratinjau) penyebaran Anda memberikan wawasan untuk membantu Anda secara proaktif meningkatkan performa aplikasi alur prompt Anda.
Konfigurasi pemantauan tingkat lanjut dengan SDK v2
Pemantauan juga mendukung opsi konfigurasi tingkat lanjut dengan SDK v2. Skenario berikut didukung:
Mengaktifkan pemantauan untuk penggunaan token
Jika Anda hanya tertarik untuk mengaktifkan pemantauan penggunaan token untuk aplikasi alur prompt yang disebarkan, Anda dapat menyesuaikan skrip berikut dengan skenario Anda:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
workspace_name = "INSERT YOUR WORKSPACE NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=workspace_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Mengaktifkan pemantauan untuk kualitas pembuatan
Jika Anda hanya tertarik untuk mengaktifkan pemantauan kualitas generasi untuk aplikasi alur prompt yang disebarkan, Anda dapat menyesuaikan skrip berikut dengan skenario Anda:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
workspace_name = "INSERT YOUR WORKSPACE NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=workspace_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Setelah membuat monitor dari SDK, Anda dapat menggunakan hasil pemantauan di AI Studio.
Konten terkait
- Pelajari selengkapnya tentang apa yang dapat Anda lakukan di Azure AI Studio
- Dapatkan jawaban atas pertanyaan yang sering diajukan di artikel Tanya Jawab Umum Azure AI