Proyek klien ini membantu perusahaan makanan Fortune 500 meningkatkan prakiraan permintaannya. Perusahaan mengirimkan produk langsung ke beberapa outlet ritel. Peningkatan tersebut membantu mereka mengoptimalkan stoking produk mereka di berbagai toko di beberapa wilayah Amerika Serikat. Untuk mencapai hal ini, tim Teknik Perangkat Lunak Komersial (CSE) Microsoft bekerja dengan ilmuwan data klien pada studi pilot untuk mengembangkan model pembelajaran mesin yang disesuaikan untuk wilayah yang dipilih. Model memperhitungkan:
- Demografi pembeli
- Cuaca historis dan prakiraan
- Pengiriman sebelumnya
- Pengembalian produk
- Kejadian khusus
Tujuan untuk mengoptimalkan stoking mewakili komponen utama proyek dan klien menyadari peningkatan penjualan yang signifikan dalam uji coba lapangan awal. Selain itu, tim melihat pengurangan 40% dalam perkiraan rata-rata kesalahan persentase absolut (MAPE) jika dibandingkan dengan model garis besar rata-rata historis.
Bagian utama dari proyek ini adalah mencari tahu cara meningkatkan alur kerja ilmu data dari studi pilot ke tingkat produksi. Alur kerja tingkat produksi ini mengharuskan tim CSE untuk:
- Mengembangkan model untuk berbagai daerah.
- Terus memperbarui dan memantau performa model.
- Memfasilitasi kolaborasi antara tim data dan teknik.
Alur kerja ilmu data yang khas saat ini lebih dekat ke lingkungan lab satu kali daripada alur kerja produksi. Lingkungan untuk ilmuwan data harus cocok untuk mereka untuk:
- Menyiapkan data.
- Bereksperimen dengan model yang berbeda.
- Menyetel hiperparameter.
- Buat siklus build-test-evaluate-refine.
Sebagian besar alat yang digunakan untuk tugas-tugas ini memiliki tujuan khusus dan tidak cocok untuk otomatisasi. Dalam operasi pembelajaran mesin tingkat produksi, harus ada lebih banyak pertimbangan yang diberikan untuk manajemen siklus hidup aplikasi dan DevOps.
Tim CSE membantu klien meningkatkan skala operasi ke tingkat produksi. Mereka menerapkan berbagai aspek kemampuan integrasi berkelanjutan dan pengiriman berkelanjutan (CI/CD) dan mengatasi masalah seperti pengamatan, dan integrasi dengan kemampuan Azure. Selama implementasi, tim mengungkap celah dalam panduan MLOps yang ada. Kesenjangan tersebut perlu diisi sehingga MLOps lebih dipahami dan diterapkan dalam skala besar.
Memahami praktik MLOps membantu organisasi memastikan bahwa model pembelajaran mesin yang dihasilkan sistem adalah model kualitas produksi yang meningkatkan performa bisnis. Ketika MLOps diterapkan, organisasi tidak lagi harus menghabiskan waktu mereka pada detail tingkat rendah yang berkaitan dengan infrastruktur dan pekerjaan teknik yang diperlukan untuk mengembangkan dan menjalankan model pembelajaran mesin untuk operasi tingkat produksi. Menerapkan MLOps juga membantu komunitas ilmu data dan rekayasa perangkat lunak belajar bekerja sama untuk memberikan sistem siap produksi.
Tim CSE menggunakan proyek ini untuk mengatasi kebutuhan komunitas pembelajaran mesin dengan mengatasi masalah seperti mengembangkan model kematangan MLOps. Upaya ini bertujuan untuk meningkatkan adopsi MLOps dengan memahami tantangan khas pemain utama dalam proses MLOps.
Skenario keterlibatan dan teknis
Skenario keterlibatan membahas tantangan dunia nyata yang harus diselesaikan tim CSE. Skenario teknis mendefinisikan persyaratan untuk membuat siklus hidup MLOps yang dapat diandalkan serta siklus hidup DevOps yang mapan.
Skenario keterlibatan
Klien mengirimkan produk langsung ke outlet pasar ritel sesuai jadwal reguler. Setiap outlet ritel bervariasi dalam pola penggunaan produknya, sehingga inventaris produk perlu bervariasi dalam setiap pengiriman mingguan. Memaksimalkan penjualan dan meminimalkan pengembalian produk dan peluang penjualan yang hilang adalah tujuan metodologi prakiraan permintaan yang digunakan klien. Proyek ini berfokus pada penggunaan pembelajaran mesin untuk meningkatkan prakiraan.
Tim CSE membagi proyek menjadi dua fase. Fase 1 berfokus pada pengembangan model pembelajaran mesin untuk mendukung studi percontohan berbasis lapangan tentang efektivitas prakiraan pembelajaran mesin untuk wilayah penjualan yang dipilih. Keberhasilan Fase 1 menyebabkan Fase 2, di mana tim meningkatkan studi pilot awal dari sekelompok model minimal yang mendukung satu wilayah geografis ke serangkaian model tingkat produksi berkelanjutan untuk semua wilayah penjualan klien. Pertimbangan utama untuk solusi peningkatan skala adalah kebutuhan untuk mengakomodasi sejumlah besar wilayah geografis dan outlet ritel lokal mereka. Tim mendedikasikan model pembelajaran mesin untuk gerai ritel besar dan kecil di setiap wilayah.
Studi pilot Fase 1 menentukan bahwa model yang didedikasikan untuk outlet ritel satu wilayah dapat menggunakan riwayat penjualan lokal, demografi lokal, cuaca, dan peristiwa khusus untuk mengoptimalkan perkiraan permintaan untuk outlet di wilayah tersebut. Empat model prakiraan pembelajaran mesin ansambel melayani outlet pasar dalam satu wilayah. Model memproses data dalam batch mingguan. Selain itu, tim mengembangkan dua model dasar menggunakan data historis sebagai perbandingan.
Untuk versi pertama solusi Fase 2 yang ditingkatkan, tim CSE memilih 14 wilayah geografis untuk berpartisipasi, termasuk outlet pasar kecil dan besar. Mereka menggunakan lebih dari 50 model peramalan pembelajaran mesin. Tim mengharapkan pertumbuhan sistem lebih lanjut dan terus menyempurnakan model pembelajaran mesin. Dengan cepat menjadi jelas bahwa solusi pembelajaran mesin berskala lebih luas ini berkelanjutan hanya jika didasarkan pada prinsip praktik terbaik DevOps untuk lingkungan pembelajaran mesin.
| Lingkungan | Wilayah Pasar | Format | Model | Subdivisi Model | Deskripsi Model |
|---|---|---|---|---|---|
| Lingkungan Pengembangan | Setiap pasar/wilayah geografis (misalnya Texas Utara) | Toko berformat besar (supermarket, toko kotak besar, dan sebagainya) | Dua model ansambel | Produk yang bergerak lambat | Lambat dan cepat keduanya memiliki ansambel model regresi linier penyusutan dan pemilihan operator seleksi (LASSO) paling sedikit absolut dan jaringan saraf dengan penyematan kategoris |
| Produk yang bergerak cepat | Lambat dan cepat keduanya memiliki ansambel model regresi linier LASSO dan jaringan neural dengan penyematan kategoris | ||||
| Satu model ansambel | T/A | Rata-rata riwayat | |||
| Toko berformat kecil (apotek, toko serba ada, dan sebagainya) | Dua model ansambel | Produk yang bergerak lambat | Lambat dan cepat keduanya memiliki ansambel model regresi linier LASSO dan jaringan neural dengan penyematan kategoris | ||
| Produk yang bergerak cepat | Lambat dan keduanya memiliki ansambel model regresi linier LASSO dan jaringan neural dengan penyematan kategoris | ||||
| Satu model ansambel | T/A | Rata-rata riwayat | |||
| Sama seperti di atas untuk 13 wilayah geografis tambahan | |||||
| Sama seperti di atas untuk lingkungan prod |
Proses MLOps menyediakan kerangka kerja untuk sistem yang ditingkatkan skalanya yang membahas siklus hidup penuh model pembelajaran mesin. Kerangka kerja ini mencakup pengembangan, pengujian, penyebaran, operasi, dan pemantauan. Ini memenuhi kebutuhan proses CI/CD klasik. Namun, karena belum begitu matang dibandingkan dengan DevOps, sudah jelas bahwa panduan MLOps yang ada memiliki celah. Tim proyek bekerja untuk mengisi beberapa celah tersebut. Mereka ingin menyediakan model proses fungsional yang memastikan kelangsungan solusi pembelajaran mesin yang ditingkatkan skalanya.
Proses MLOps yang dikembangkan dari proyek ini membuat langkah dunia nyata yang signifikan untuk memindahkan MLOps ke tingkat kematangan dan kelangsungan hidup yang lebih tinggi. Proses baru ini secara langsung berlaku untuk proyek pembelajaran mesin lainnya. Tim CSE menggunakan apa yang mereka pelajari untuk membangun draf model kematangan MLOps yang dapat diterapkan siapa pun ke proyek pembelajaran mesin lainnya.
Skenario teknis
MLOps, juga dikenal sebagai DevOps untuk pembelajaran mesin, adalah istilah payung yang mencakup filosofi, praktik, dan teknologi yang terkait dengan penerapan siklus hidup pembelajaran mesin di lingkungan produksi. Ini masih konsep yang relatif baru. Ada banyak upaya untuk menentukan apa itu MLOps dan banyak orang telah mempertanyakan apakah MLOps dapat menyurutkan segalanya mulai dari bagaimana ilmuwan data menyiapkan data hingga bagaimana mereka pada akhirnya mengirimkan, memantau, dan mengevaluasi hasil pembelajaran mesin. Meskipun DevOps telah bertahun-tahun mengembangkan serangkaian praktik mendasar, MLOps masih awal pengembangannya. Seiring berkembangnya, kami menemukan tantangan untuk menyaingkan dua disiplin ilmu yang sering beroperasi dengan set keterampilan dan prioritas yang berbeda: rekayasa perangkat lunak/operasi, dan ilmu data.
Menerapkan MLOps di lingkungan produksi dunia nyata memiliki tantangan unik yang harus diatasi. Teams dapat menggunakan Azure untuk mendukung pola MLOps. Azure juga dapat memberi klien layanan manajemen aset dan orkestrasi untuk mengelola siklus hidup pembelajaran mesin secara efektif. Layanan Azure adalah fondasi untuk solusi MLOps yang kami jelaskan dalam artikel ini.
Persyaratan model pembelajaran mesin
Sebagian besar pekerjaan selama studi lapangan pilot Fase 1 adalah menciptakan model pembelajaran mesin yang diterapkan tim CSE ke toko ritel besar dan kecil dalam satu wilayah. Persyaratan penting untuk model termasuk:
Penggunaan layanan Azure Pembelajaran Mesin.
Model eksperimental awal yang dikembangkan di notebook Jupyter dan diimplementasikan di Python.
Catatan
Teams menggunakan pendekatan pembelajaran mesin yang sama untuk penyimpanan besar dan kecil, tetapi data pelatihan dan penilaian tergantung pada ukuran penyimpanan.
Data yang memerlukan persiapan untuk konsumsi model.
Data yang diproses berdasarkan batch daripada secara real time.
Pelatihan ulang model setiap kali kode atau data berubah, atau model menjadi basi.
Menampilkan performa model di dasbor Power BI.
Performa model dalam penilaian yang dianggap signifikan ketika MAPE <= 45% jika dibandingkan dengan model garis besar rata-rata historis.
Persyaratan MLOps
Tim harus memenuhi beberapa persyaratan utama untuk meningkatkan solusi dari studi lapangan pilot Fase 1, di mana hanya beberapa model yang dikembangkan untuk satu wilayah penjualan. Fase 2 menerapkan model pembelajaran mesin kustom untuk beberapa wilayah. Implementasinya meliputi:
Pemrosesan batch mingguan untuk penyimpanan besar dan kecil di setiap wilayah untuk melatih kembali model dengan himpunan data baru.
Penyempurnaan model pembelajaran mesin berkelanjutan.
Integrasi proses pengembangan/pengujian/pengemasan/pengujian/penyebarab yang umum untuk CI/CD dalam lingkungan pemrosesan seperti DevOps untuk MLOps.
Catatan
Ini merupakan pergeseran dalam cara ilmuwan data dan teknisi data biasanya bekerja di masa lalu.
Model unik yang mewakili setiap wilayah untuk penyimpanan besar dan kecil berdasarkan riwayat penyimpanan, demografi, dan variabel kunci lainnya. Model harus memproses seluruh himpunan data untuk meminimalkan risiko kesalahan pemrosesan.
Kemampuan untuk awalnya meningkatkan skala untuk mendukung 14 wilayah penjualan dengan rencana untuk meningkatkan skala lebih lanjut.
Rencana untuk model tambahan untuk peramalan jangka panjang untuk wilayah dan kluster toko lainnya.
Solusi model pembelajaran mesin
Siklus hidup pembelajaran mesin, juga dikenal sebagai siklus hidup ilmu data, cocok kira-kira dengan alur proses tingkat tinggi berikut:
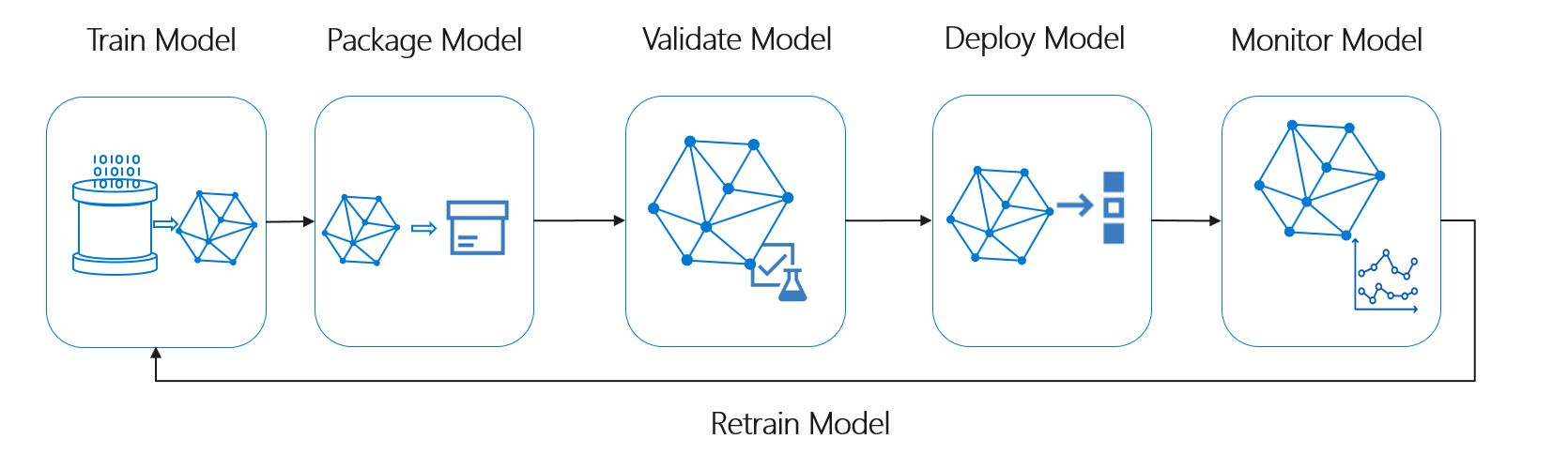
Sebarkan Model di sini mewakili penggunaan operasional apa pun dari model pembelajaran mesin yang divalidasi. Dibandingkan dengan DevOps, MLOps menyajikan tantangan tambahan untuk mengintegrasikan siklus hidup pembelajaran mesin ke dalam proses CI/CD yang khas.
Siklus hidup ilmu data tidak mengikuti siklus hidup pengembangan perangkat lunak yang khas. Ini termasuk penggunaan Azure Pembelajaran Mesin untuk melatih dan menilai model, sehingga langkah-langkah ini harus disertakan dalam otomatisasi CI/CD.
Pemrosesan batch data adalah dasar arsitektur. Dua alur Azure Machine Learning adalah pusat proses, satu untuk pelatihan dan yang lainnya untuk penilaian. Diagram ini menunjukkan metodologi ilmu data yang digunakan untuk fase awal proyek klien:
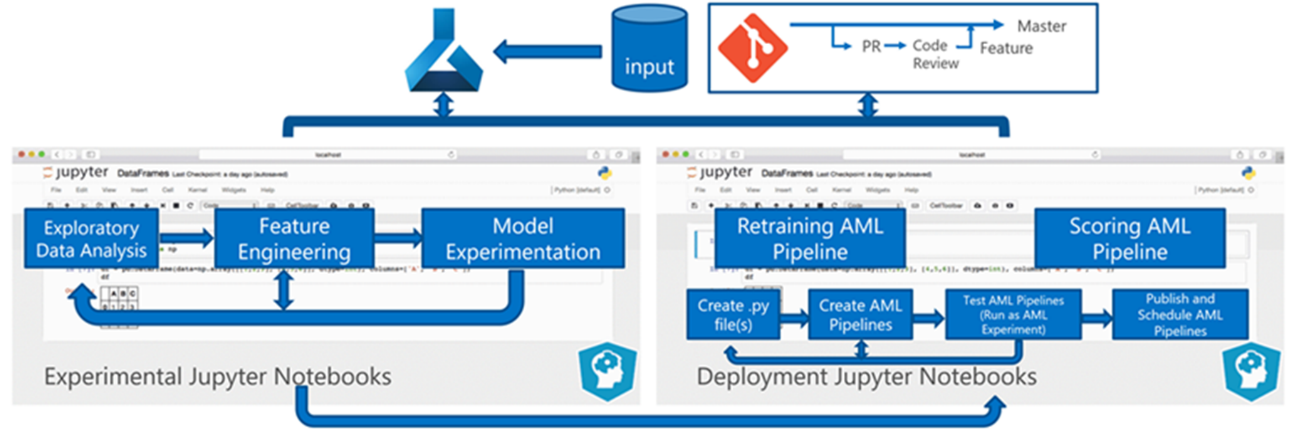
Tim menguji beberapa algoritma. Mereka akhirnya memilih desain ansambel dari model regresi linier LASSO dan jaringan neural dengan penyematan kategoris. Tim menggunakan model yang sama, ditentukan berdasarkan tingkat produk yang dapat disimpan klien di lokasi, untuk toko besar dan kecil. Tim selanjutnya membagi model menjadi produk yang bergerak cepat dan bergerak lambat.
Ilmuwan data melatih model pembelajaran mesin ketika tim merilis kode baru dan kapan data baru tersedia. Pelatihan biasanya terjadi mingguan. Akibatnya, setiap eksekusi pemrosesan melibatkan data dalam jumlah besar. Karena tim mengumpulkan data dari banyak sumber dalam format yang berbeda, perlu pengkondisian untuk memasukkan data ke dalam format yang dapat dikonsumsi sebelum ilmuwan data dapat memprosesnya. Pengondisian data memerlukan upaya manual yang signifikan dan tim CSE mengidentifikasinya sebagai kandidat utama untuk otomatisasi.
Seperti disebutkan, ilmuwan data mengembangkan dan menerapkan model azure Pembelajaran Mesin eksperimental ke satu wilayah penjualan dalam studi bidang pilot Fase 1 untuk mengevaluasi kegunaan pendekatan prakiraan ini. Tim CSE menilai bahwa angkat penjualan untuk toko-toko dalam studi pilot signifikan. Keberhasilan ini membenarkan penerapan solusi ke tingkat produksi penuh di Fase 2, dimulai dengan 14 wilayah geografis dan ribuan toko. Tim kemudian dapat menggunakan pola yang sama untuk menambahkan wilayah tambahan.
Model pilot berfungsi sebagai dasar untuk solusi yang ditingkatkan skalanya, tetapi tim CSE tahu bahwa model tersebut membutuhkan penyempurnaan lebih lanjut secara berkelanjutan untuk meningkatkan performanya.
Solusi MLOps
Saat konsep MLOps matang, tim sering menemukan tantangan dalam menyatukan ilmu data dan disiplin Ilmu DevOps. Alasannya adalah bahwa pemain utama dalam disiplin ilmu, insinyur perangkat lunak dan ilmuwan data, beroperasi dengan set keterampilan dan prioritas yang berbeda.
Tetapi ada kesamaan untuk dibangun. MLOps, seperti DevOps, adalah proses pengembangan yang diterapkan oleh toolchain. Toolchain MLOps mencakup hal-hal seperti:
- Kontrol versi
- Analisis kode
- Otomatisasi build
- Integrasi berkelanjutan
- Menguji kerangka kerja dan otomatisasi
- Kebijakan kepatuhan yang diintegrasikan dengan alur CI/CD
- Otomatisasi penyebaran
- Pemantauan
- Pemulihan bencana dan ketersediaan tinggi
- Manajemen paket dan kontainer
Seperti disebutkan di atas, solusi ini memanfaatkan panduan DevOps yang ada, tetapi diperbanyak untuk membuat implementasi MLOps yang lebih matang yang memenuhi kebutuhan klien dan komunitas ilmu data. MLOps dibangun berdasarkan panduan DevOps dengan persyaratan tambahan ini:
- Penerapan versi data dan model tidak sama dengan penerapan versi kode: Harus ada penerapan versi himpunan data saat skema dan data asal berubah.
- Persyaratan jejak audit digital: Melacak semua perubahan saat menangani kode dan data klien.
- Generalisasi: Model berbeda dari kode untuk digunakan kembali, karena ilmuwan data harus menyetel model berdasarkan data input dan skenario. Untuk menggunakan kembali model untuk skenario baru, Anda mungkin perlu menyempurnakan/mentransfer/mempelajarinya. Anda membutuhkan alur pelatihan.
- Model usang: Model cenderung usang dari waktu ke waktu dan Anda memerlukan kemampuan untuk melatihnya kembali sesuai permintaan untuk memastikan mereka tetap relevan dalam produksi.
Tantangan MLOps
Standar MLOps yang belum matang
Pola standar untuk MLOps masih berkembang. Solusi biasanya dibangun dari awal dan dibuat agar sesuai dengan kebutuhan klien atau pengguna tertentu. Tim CSE mengetahui kesenjangan ini dan berusaha menggunakan praktik terbaik DevOps dalam proyek ini. Mereka menambahkan proses DevOps agar sesuai dengan persyaratan tambahan MLOps. Proses yang dikembangkan tim adalah contoh yang tepat dari seperti apa pola standar MLOps.
Perbedaan dalam set keterampilan
Insinyur perangkat lunak dan ilmuwan data membawa set keterampilan unik ke tim. Set keterampilan yang berbeda ini dapat membuat menemukan solusi yang sesuai dengan kebutuhan semua orang sulit. Membangun alur kerja yang dipahami dengan baik untuk pengiriman model dari eksperimen ke produksi adalah penting. Anggota tim harus berbagi pemahaman tentang bagaimana mereka dapat mengintegrasikan perubahan ke dalam sistem tanpa merusak proses MLOps.
Mengelola beberapa model
Sering kali ada kebutuhan untuk beberapa model untuk memecahkan skenario pembelajaran mesin yang sulit. Salah satu tantangan MLOps adalah mengelola model-model ini, termasuk:
- Memiliki skema penerapan versi yang koheren.
- Terus mengevaluasi dan memantau semua model.
Silsilah data dan kode yang dapat dilacak juga diperlukan untuk mendiagnosis masalah model dan membuat model yang dapat direproduksi. Dasbor kustom dapat memahami performa model yang disebarkan dan menunjukkan kapan harus melakukan intervensi. Tim membuat dasbor tersebut untuk proyek ini.
Kebutuhan untuk pengondisian data
Data yang digunakan dengan model ini berasal dari berbagai sumber pribadi dan publik. Karena data asli tidak terorganisir, tidak mungkin bagi model pembelajaran mesin untuk mengonsumsinya dalam keadaan mentah. Ilmuwan data harus mengondisikan data ke dalam format standar untuk konsumsi model pembelajaran mesin.
Sebagian besar uji lapangan percontohan difokuskan pada pengondisian data mentah sehingga model pembelajaran mesin dapat memprosesnya. Dalam sistem MLOps, tim harus mengotomatiskan proses ini, dan melacak output-nya.
Model kematangan MLOps
Tujuan dari model kematangan MLOps adalah untuk mengklarifikasi prinsip dan praktik dan mengidentifikasi kesenjangan dalam implementasi MLOps. Ini juga merupakan cara untuk menunjukkan kepada klien cara menumbuhkan kemampuan MLOps mereka secara bertahap alih-alih mencoba melakukan semuanya sekaligus. Klien harus menggunakannya sebagai panduan untuk:
- Memperkirakan cakupan pekerjaan untuk proyek.
- Menetapkan kriteria keberhasilan.
- Identifikasi hasil.
Model kematangan MLOps mendefinisikan lima tingkat kemampuan teknis:
| Tingkat | Deskripsi |
|---|---|
| 0 | Tidak Ada Ops |
| 1 | DevOps tetapi tanpa MLOps |
| 2 | Pelatihan otomatis |
| 3 | Penyebaran model otomatis |
| 4 | Operasi otomatis (MLOps penuh) |
Untuk model kematangan MLOps versi saat ini, lihat artikel model kematangan MLOps.
Definisi proses MLOps
MLOps mencakup semua aktivitas mulai dari memperoleh data mentah hingga memberikan output model, juga dikenal sebagai penilaian:
- Pengondisian data
- Pelatihan model
- Pengujian dan evaluasi model
- Membuat definisi dan alur
- Alur rilis
- Penyebaran
- Penilaian
Proses pembelajaran mesin dasar
Proses pembelajaran mesin dasar menyerupan pengembangan perangkat lunak tradisional, tetapi ada perbedaan yang signifikan. Diagram ini menggambarkan langkah-langkah utama dalam proses pembelajaran mesin:
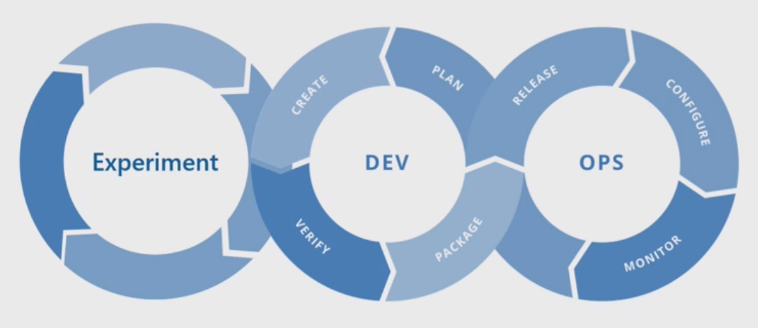
Fase Eksperimen unik untuk siklus hidup ilmu data, yang mencerminkan bagaimana ilmuwan data secara tradisional melakukan pekerjaan mereka. Ini berbeda dari bagaimana pengembang kode melakukan pekerjaan mereka. Diagram berikut menggambarkan siklus hidup ini secara lebih rinci.
Mengintegrasikan proses pengembangan data ini ke MLOps menimbulkan tantangan. Di sini Anda melihat pola yang digunakan tim untuk mengintegrasikan proses ke dalam formulir yang dapat didukung MLOps:
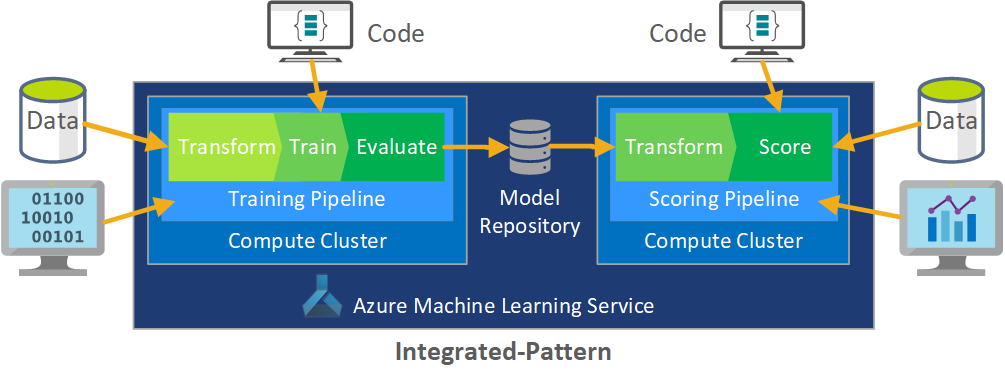
Peran MLOps adalah membuat proses terkoordinasi yang dapat secara efisien mendukung lingkungan CI/CD skala besar yang umum dalam sistem tingkat produksi. Secara konseptual, model MLOps harus mencakup semua persyaratan proses dari eksperimen hingga penilaian.
Tim CSE menyempurnakan proses MLOps agar sesuai dengan kebutuhan spesifik klien. Kebutuhan yang paling penting adalah pemrosesan batch alih-alih pemrosesan real-time. Ketika tim mengembangkan sistem peningkatan skala, mereka mengidentifikasi dan menyelesaikan beberapa kekurangan. Kekurangan yang paling signifikan ini menyebabkan pengembangan jembatan antara Azure Data Factory dan Azure Pembelajaran Mesin, yang diterapkan tim dengan menggunakan konektor bawaan di Azure Data Factory. Mereka membuat komponen ini diatur untuk memudahkan pemicuan dan pemantauan status yang diperlukan untuk membuat otomatisasi proses bekerja.
Perubahan mendasar lainnya adalah bahwa ilmuwan data membutuhkan kemampuan untuk mengekspor kode eksperimental dari notebook Jupyter ke dalam proses penyebaran MLOps daripada memicu pelatihan dan penilaian secara langsung.
Berikut adalah konsep model proses MLOps akhir:
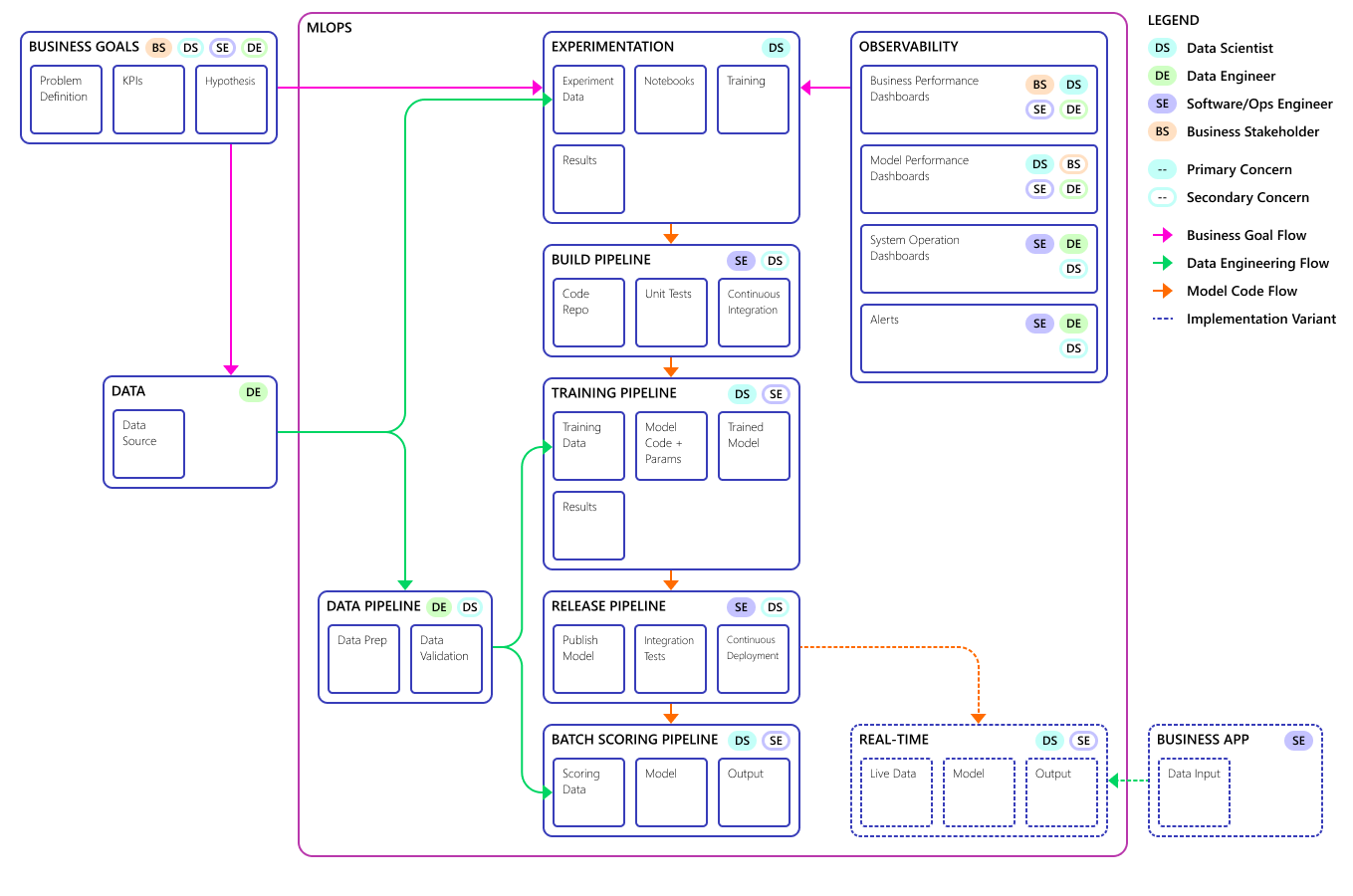
Penting
Penilaian adalah langkah terakhir. Proses ini menjalankan model pembelajaran mesin untuk membuat prediksi. Ini membahas persyaratan kasus penggunaan bisnis dasar untuk peramalan permintaan. Tim menilai kualitas prediksi menggunakan MAPE, yang merupakan ukuran akurasi prediksi metode prakiraan statistik dan fungsi kerugian untuk masalah regresi dalam pembelajaran mesin. Dalam proyek ini, tim menganggap MAPE sebesar <= 45% signifikan.
Alur proses MLOps
Diagram berikut menjelaskan cara menerapkan pengembangan CI/CD dan melepaskan alur kerja ke siklus hidup pembelajaran mesin:
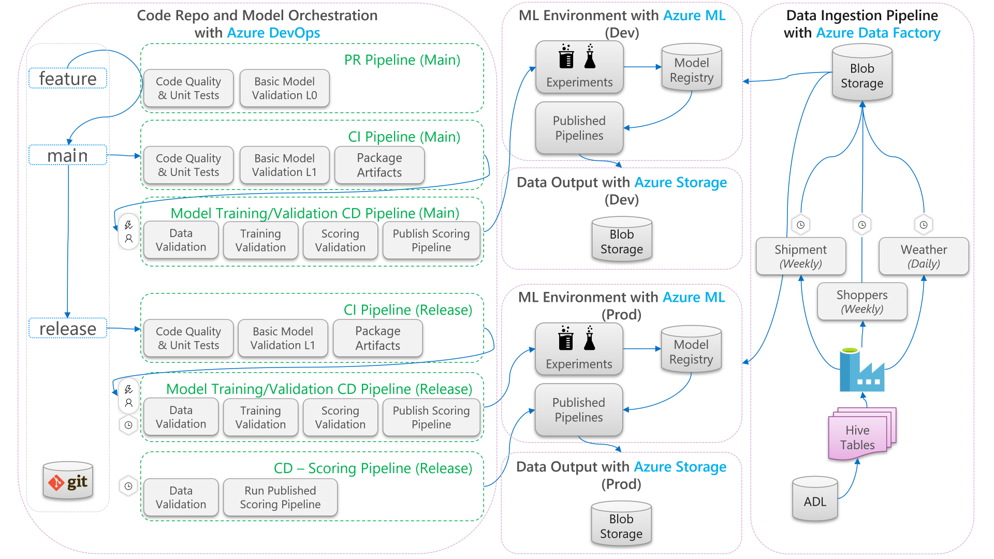
- Ketika permintaan pull (PR) dibuat dari cabang fitur, alur menjalankan pengujian validasi kode untuk memvalidasi kualitas kode melalui pengujian unit dan pengujian kualitas kode. Untuk memvalidasi kualitas ke hulu, alur juga menjalankan pengujian validasi model dasar untuk memvalidasi pelatihan end-to-end dan langkah-langkah penilaian dengan satu set sampel data palsu.
- Saat PR digabungkan dengan cabang utama, alur CI akan menjalankan pengujian validasi kode yang sama dan tes validasi model dasar dengan peningkatan waktu. Alur kemudian akan mengemas artefak, yang mencakup kode dan biner, untuk dijalankan di lingkungan pembelajaran mesin.
- Setelah artefak tersedia, alur CD validasi model dipicu. Ini akan menjalankan validasi end-to-end di lingkungan pembelajaran mesin pengembangan. Mekanisme penilaian diterbitkan. Untuk skenario penilaian batch, alur penilaian diterbitkan ke lingkungan pembelajaran mesin dan dipicu untuk membuahkan hasil. Jika Anda ingin menggunakan skenario penilaian real-time, Anda dapat menerbitkan aplikasi web atau menyebarkan kontainer.
- Setelah tonggak pencapaian dibuat dan digabungkan ke cabang rilis, alur CI yang sama dan alur CD validasi model dipicu. Kali ini, mereka berjalan terhadap kode dari cabang rilis.
Anda dapat mempertimbangkan aliran data proses MLOps yang ditunjukkan di atas sebagai kerangka kerja arketipe untuk proyek yang membuat pilihan arsitektur serupa.
Pengujian validasi kode
Pengujian validasi kode untuk pembelajaran mesin berfokus pada validasi kualitas dasar kode. Ini adalah konsep yang sama dengan proyek rekayasa apa pun yang memiliki pengujian kualitas kode (linting), pengujian unit, dan pengukuran cakupan kode.
Pengujian validasi model dasar
Validasi model biasanya mengacu pada validasi langkah-langkah proses end-to-end penuh yang diperlukan untuk menghasilkan model pembelajaran mesin yang valid. Ini termasuk langkah-langkah seperti:
- Validasi data: Memastikan bahwa data input valid.
- Validasi pelatihan: Memastikan bahwa model dapat berhasil dilatih.
- Validasi penilaian: Memastikan bahwa tim dapat berhasil menggunakan model terlatih untuk melakukan penilaian dengan data input.
Menjalankan serangkaian langkah lengkap ini di lingkungan pembelajaran mesin memang mahal dan memakan waktu. Akibatnya, tim melakukan pengujian validasi model dasar secara lokal pada mesin pengembangan. Ini menjalankan langkah-langkah di atas dan menggunakan yang berikut:
- Himpunan data pengujian lokal: Himpunan data kecil, seringkali himpunan data yang dikaburkan, yang dicek masuk ke repositori dan digunakan sebagai sumber data input.
- Bendera lokal: Bendera atau argumen dalam kode model yang menunjukkan bahwa kode menginginkan himpunan data dijalankan secara lokal. Bendera memberi tahu kode untuk melewati panggilan apa pun ke lingkungan pembelajaran mesin.
Tujuan dari pengujian validasi ini bukanlah untuk mengevaluasi performa model terlatih. Sebaliknya, ini untuk memvalidasi bahwa kode untuk proses end-to-end memiliki kualitas yang baik. Ini memastikan kualitas kode yang didorong ke hulu, seperti penggabungan pengujian validasi model dalam build PR dan CI. Ini juga memungkinkan teknisi dan ilmuwan data untuk menempatkan titik henti ke dalam kode untuk tujuan penelusuran kesalahan.
Alur CD validasi model
Tujuan dari alur validasi model adalah memvalidasi pelatihan model end-to-end dan langkah-langkah penilaian di lingkungan pembelajaran mesin dengan data aktual. Setiap model terlatih yang diproduksi akan ditambahkan ke registri model dan ditandai, untuk menunggu promosi setelah validasi selesai. Untuk prediksi batch, promosi dapat menjadi penerbitan alur penilaian yang menggunakan versi model ini. Untuk penilaian real-time, model dapat ditandai untuk menunjukkan bahwa model telah dipromosikan.
Alur CD penilaian
Alur CD penilaian berlaku untuk skenario inferensi batch, di mana orkestrator model yang sama yang digunakan untuk validasi model memicu alur penilaian yang diterbitkan.
Lingkungan pengembangan vs. produksi
Ini adalah praktik yang baik untuk memisahkan lingkungan pengembangan (dev) dari lingkungan produksi (prod). Pemisahan memungkinkan sistem untuk memicu alur CD validasi model dan menilai alur CD pada jadwal yang berbeda. Untuk alur MLOps yang dijelaskan, alur yang menargetkan cabang utama berjalan di lingkungan dev, dan alur yang menargetkan cabang rilis berjalan di lingkungan prod.
Perubahan kode vs. perubahan data
Bagian sebelumnya sebagian besar menangani cara menangani perubahan kode dari pengembangan ke rilis. Namun, perubahan data harus mengikuti kekakuan yang sama dengan perubahan kode untuk memberikan kualitas validasi dan konsistensi yang sama dalam produksi. Dengan pemicu perubahan data atau pemicu timer, sistem dapat memicu alur CD validasi model dan alur CD penilaian dari orkestrator model untuk menjalankan proses yang sama yang dijalankan untuk perubahan kode di lingkungan prod cabang rilis.
Persona dan peran MLOps
Persyaratan utama untuk setiap proses MLOps adalah memenuhi kebutuhan banyak pengguna proses. Untuk tujuan desain, pertimbangkan pengguna ini sebagai persona individu. Untuk proyek ini, tim mengidentifikasi persona ini:
- Ilmuwan data: Menciptakan model pembelajaran mesin dan algoritmanya.
- Teknisi
- Teknisi data: Menangani pengondisian data.
- Teknisi perangkat lunak: Menangani integrasi model ke dalam paket aset dan alur kerja CI/CD.
- Operasi atau IT: Mengawasi operasi sistem.
- Pemangku kepentingan bisnis: Berkaitan dengan prediksi yang dibuat oleh model pembelajaran mesin dan bagaimana mereka membantu bisnis.
- Pengguna akhir data: Mengonsumsi output model sedemikian rupa sehingga membantu dalam membuat keputusan bisnis.
Tim harus membahas tiga temuan penting dari persona dan studi peran:
- Ilmuwan dan teknisi data memiliki ketidakcocokan pendekatan dan keterampilan dalam pekerjaan mereka. Memudahkan ilmuwan data dan insinyur untuk berkolaborasi adalah pertimbangan utama untuk desain alur proses MLOps. Ini membutuhkan akuisisi keterampilan baru oleh semua anggota tim.
- Ada kebutuhan untuk menyatukan semua persona utama tanpa mengasingkan siapa pun. Cara untuk melakukan ini adalah dengan:
- Pastikan mereka memahami model konseptual untuk MLOps.
- Setujui anggota tim yang akan bekerja sama.
- Tetapkan pedoman kerja untuk mencapai tujuan bersama.
- Jika pemangku kepentingan bisnis dan pengguna akhir data memerlukan cara untuk berinteraksi dengan output data dari model, UI yang mudah digunakan adalah solusi standar.
Tim lain pasti akan menemukan masalah serupa dalam proyek pembelajaran mesin lainnya saat meningkatkan skala penggunaan produksi.
Arsitektur solusi MLOps
Arsitektur logis
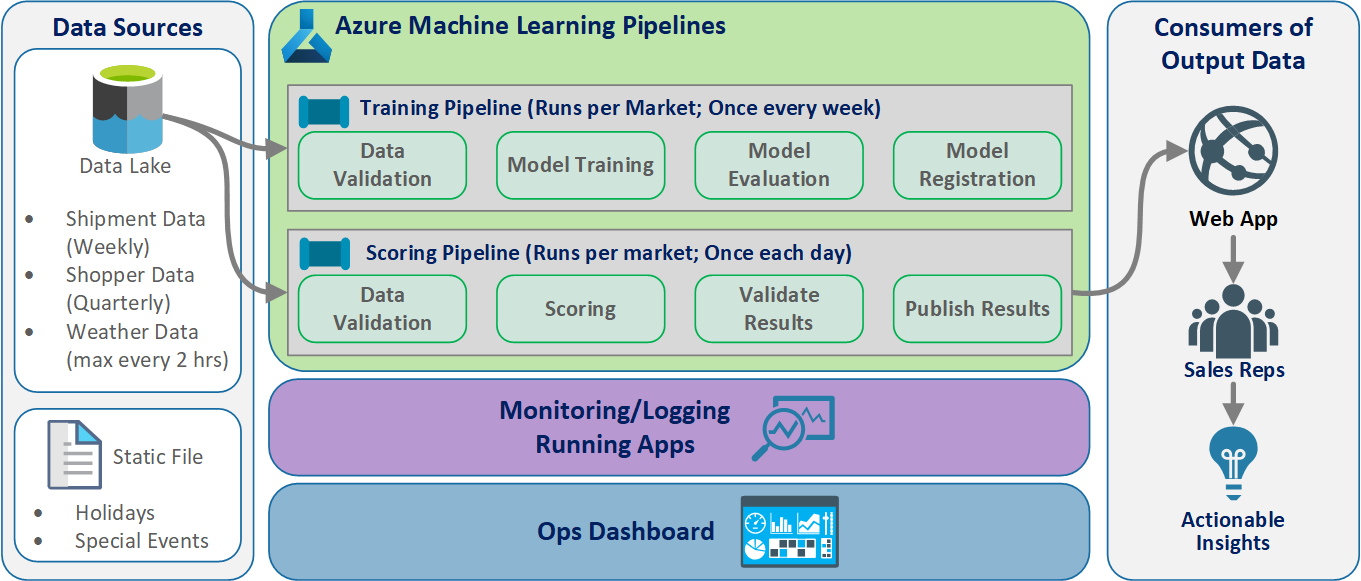
Data berasal dari banyak sumber dalam berbagai format, sehingga dikondisikan sebelum dimasukkan ke dalam data lake. Pengkondisian dilakukan dengan menggunakan layanan mikro yang beroperasi sebagai Azure Functions. Klien menyesuaikan layanan mikro agar sesuai dengan sumber data dan mengubahnya menjadi format csv standar yang dikonsumsi alur pelatihan dan penilaian.
Arsitektur sistem
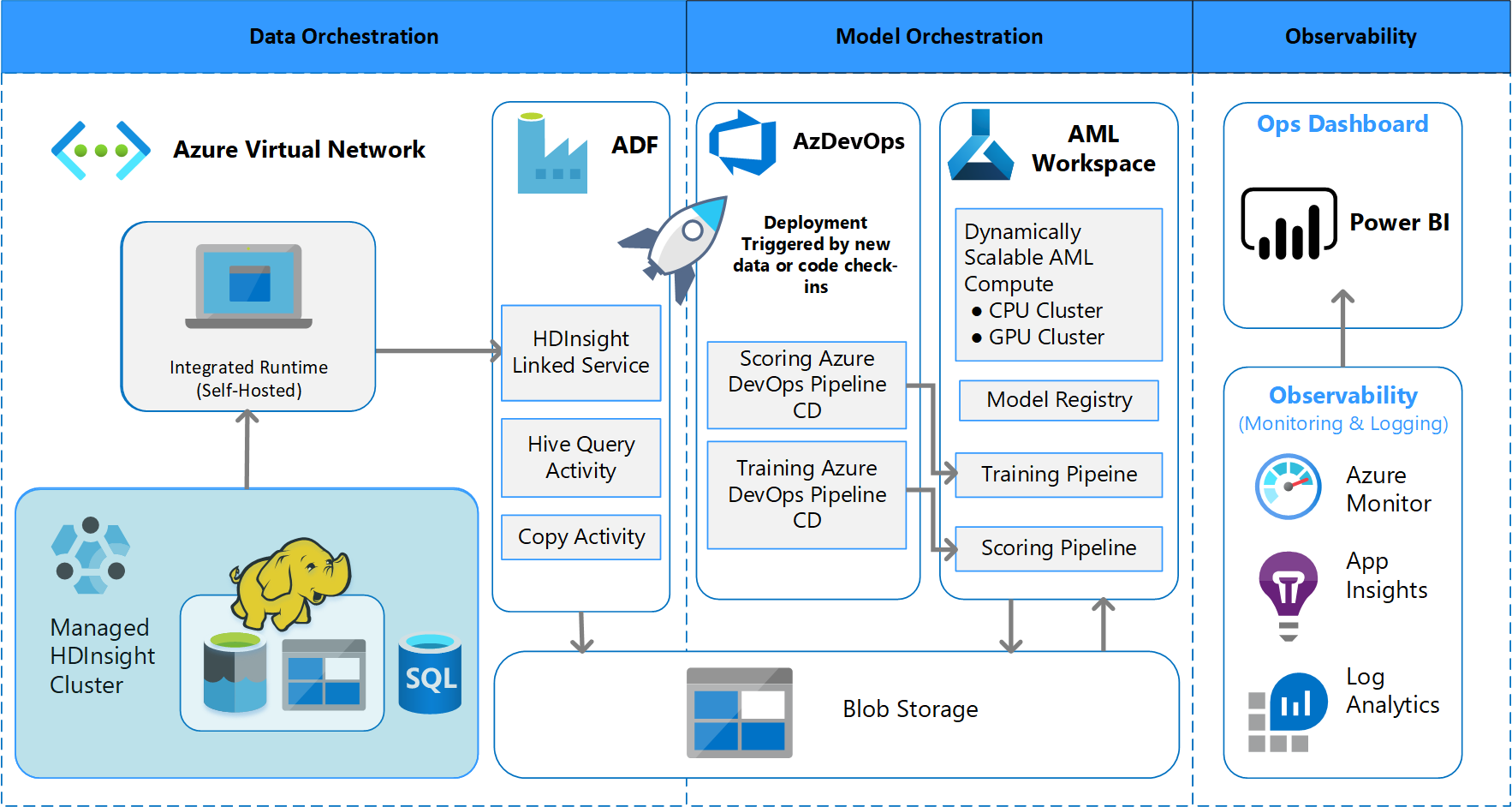
Arsitektur pemrosesan batch
Tim merancang desain arsitektur untuk mendukung skema pemrosesan data batch. Ada alternatif, tetapi apa pun yang digunakan harus mendukung proses MLOps. Penggunaan penuh layanan Azure yang tersedia adalah persyaratan desain. Diagram berikut menunjukkan arsitektur ini:
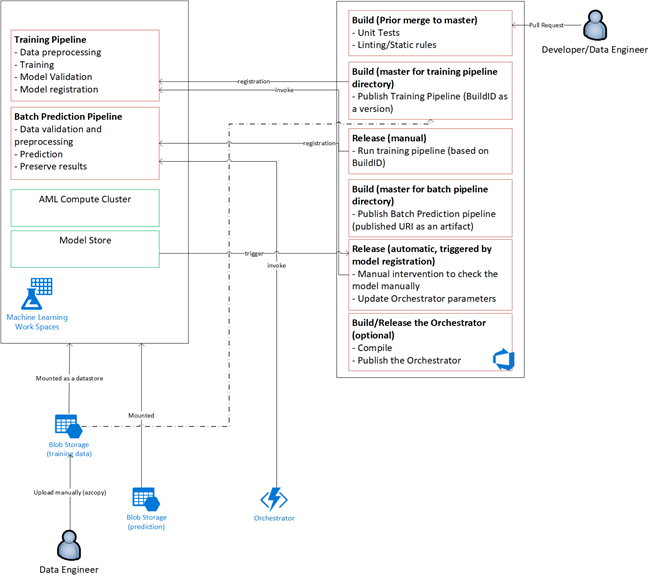
Ikhtisar solusi
Azure Data Factory melakukan hal berikut:
- Memicu fungsi Azure untuk memulai penyerapan data dan menjalankan alur Azure Pembelajaran Mesin.
- Meluncurkan fungsi tahan lama untuk melakukan polling alur Azure Pembelajaran Mesin untuk penyelesaian.
Dasbor kustom di Power BI menampilkan hasilnya. Dasbor Azure lainnya yang tersambung ke Azure SQL, Azure Monitor, dan App Insights melalui OpenCensus Python SDK, melacak sumber daya Azure. Dasbor ini memberikan informasi tentang kesehatan sistem pembelajaran mesin. Mereka juga menghasilkan data yang digunakan klien untuk prakiraan pesanan produk.
Orkestrasi model
Orkestrasi model mengikuti langkah-langkah ini:
- Saat PR dikirimkan, DevOps memicu alur validasi kode.
- Alur menjalankan pengujian unit, pengujian kualitas kode, dan pengujian validasi model.
- Ketika digabungkan ke cabang utama, pengujian validasi kode yang sama dijalankan, dan DevOps mengemas artefak.
- Pengumpulan artefak DevOps memicu Azure Pembelajaran Mesin untuk dilakukan:
- Validasi data.
- Validasi pelatihan.
- Validasi penilaian.
- Setelah validasi selesai, alur penilaian akhir berjalan.
- Mengubah data dan mengirimkan PR baru memicu alur validasi lagi, diikuti oleh alur penilaian akhir.
Mengaktifkan eksperimen
Seperti disebutkan, siklus hidup pembelajaran mesin ilmu data tradisional tidak mendukung proses MLOps tanpa modifikasi. Ini menggunakan berbagai jenis alat manual dan eksperimen, validasi, pengemasan, dan penyerahan model yang tidak dapat dengan mudah diskalakan untuk proses CI/CD yang efektif. MLOps menuntut otomatisasi proses tingkat tinggi. Apakah model pembelajaran mesin baru sedang dikembangkan atau model lama dimodifikasi, perlu untuk mengotomatiskan siklus hidup model pembelajaran mesin. Dalam proyek Fase 2, tim menggunakan Azure DevOps untuk mengatur dan menerbitkan ulang alur Azure Pembelajaran Mesin untuk tugas pelatihan. Cabang utama yang berjalan lama melakukan pengujian dasar model, dan mendorong rilis stabil melalui cabang rilis yang berjalan lama.
Kontrol sumber menjadi bagian penting dari proses ini. Git adalah sistem kontrol versi yang digunakan untuk melacak buku catatan dan kode model. Ini juga mendukung otomatisasi proses. Alur kerja dasar yang diimplementasikan untuk kontrol sumber menerapkan prinsip-prinsip berikut:
- Gunakan penerapan versi formal untuk kode dan himpunan data.
- Gunakan cabang untuk pengembangan kode baru hingga kode sepenuhnya dikembangkan dan divalidasi.
- Setelah kode baru divalidasi, kode dapat digabungkan ke cabang utama.
- Untuk rilis, cabang versi permanen dibuat yang terpisah dari cabang utama.
- Gunakan versi dan kontrol sumber untuk himpunan data yang telah dikondisikan untuk pelatihan atau konsumsi, sehingga Anda dapat mempertahankan integritas setiap himpunan data.
- Menggunakan kontrol sumber untuk melacak eksperimen Jupyter Notebook Anda.
Integrasi dengan sumber data
Ilmuwan data menggunakan berbagai sumber data mentah dan himpunan data yang diproses untuk bereksperimen dengan model pembelajaran mesin yang berbeda. Volume data dalam lingkungan produksi bisa sangat banyak. Agar ilmuwan data bereksperimen dengan model yang berbeda, mereka perlu menggunakan alat manajemen seperti Azure Data Lake. Persyaratan untuk identifikasi formal dan kontrol versi berlaku untuk semua data mentah, himpunan data yang disiapkan, dan model pembelajaran mesin.
Dalam proyek, ilmuwan data mengkondisikan data berikut untuk dimasukkan ke dalam model:
- Data pengiriman mingguan historis sejak Januari 2017
- Data cuaca harian historis dan prakiraan untuk setiap kode pos
- Data pembeli untuk setiap ID penyimpanan
Integrasi dengan kontrol sumber
Untuk mendapatkan ilmuwan data untuk menerapkan praktik terbaik teknik, perlu untuk mengintegrasikan alat yang mereka gunakan dengan sistem kontrol sumber seperti GitHub. Praktik ini memungkinkan penerapan versi model pembelajaran mesin, kolaborasi antara anggota tim, dan pemulihan bencana jika tim mengalami kehilangan data atau pemadaman sistem.
Dukungan ansambel model
Desain model dalam proyek ini adalah model ensambel. Artinya, ilmuwan data menggunakan banyak algoritma dalam desain model akhir. Dalam hal ini, model menggunakan desain algoritma dasar yang sama. Satu-satunya perbedaan adalah bahwa mereka menggunakan data pelatihan yang berbeda dan data penilaian. Model menggunakan kombinasi algoritma regresi linier LASSO dan jaringan saraf.
Tim mengeksplorasi, tetapi tidak menerapkan, opsi untuk meneruskan proses ke titik di mana tim akan mendukung memiliki banyak model real-time yang berjalan dalam produksi untuk melayani permintaan tertentu. Opsi ini dapat mengakomodasi penggunaan model ansambel dalam pengujian A/B dan eksperimen yang saling terkait.
Antarmuka pengguna akhir
Tim mengembangkan UI pengguna akhir untuk keteramatan, pemantauan, dan instrumentasi. Seperti disebutkan, dasbor secara visual menampilkan data model pembelajaran mesin. Dasbor ini menampilkan data berikut dalam format yang mudah digunakan:
- Langkah-langkah alur, termasuk pra-pemrosesan data input.
- Untuk memantau kesehatan pemrosesan model pembelajaran mesin:
- Metrik apa yang Anda kumpulkan dari model yang disebarkan?
- MAPE: Rata-rata kesalahan persentase absolut, metrik utama untuk melacak performa keseluruhan. (Targetkan nilai <MAPE = 0,45 untuk setiap model.)
- RMSE 0: Kesalahan root-mean-square (RMSE) saat nilai target aktual = 0.
- RMSE All: RMSE pada seluruh himpunan data.
- Bagaimana Anda mengevaluasi apakah model Anda berkinerja seperti yang diharapkan dalam produksi?
- Apakah ada cara untuk mengetahui apakah data produksi menyimpang terlalu jauh dari nilai yang diharapkan?
- Apakah performa model Anda buruk dalam produksi?
- Apakah Anda mengalami status failover?
- Metrik apa yang Anda kumpulkan dari model yang disebarkan?
- Melacak kualitas data yang diproses.
- Menampilkan skor/prediksi yang dihasilkan oleh model pembelajaran mesin.
Aplikasi mengisi dasbor sesuai dengan sifat data dan cara data diproses dan dianalisis. Dengan demikian, tim harus merancang tata letak dasbor yang tepat untuk setiap kasus penggunaan. Berikut dua contoh dasbor:
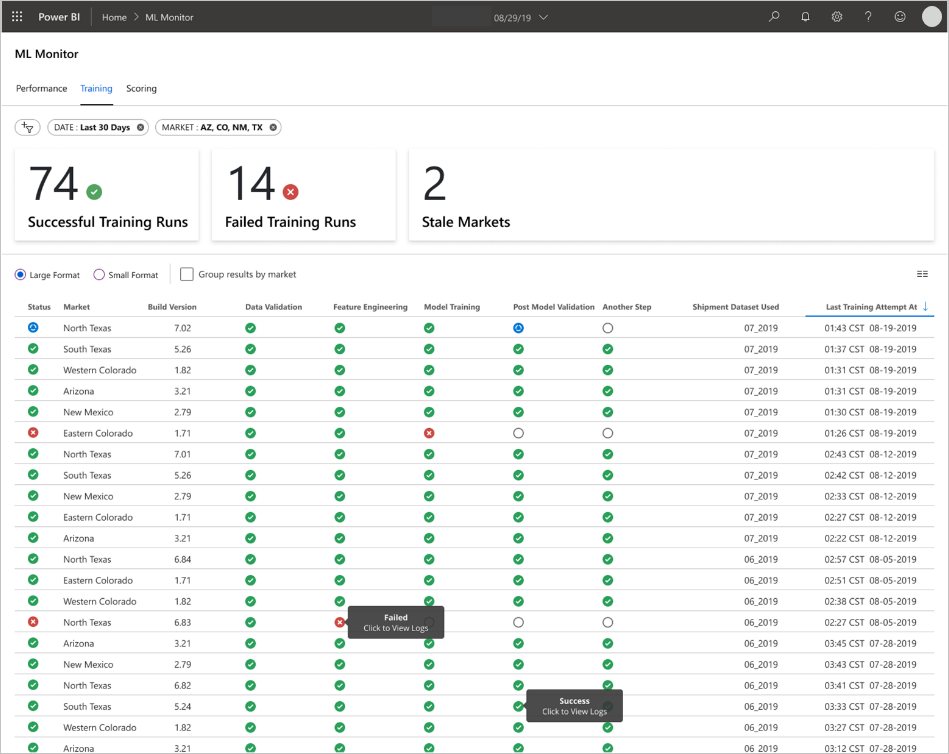
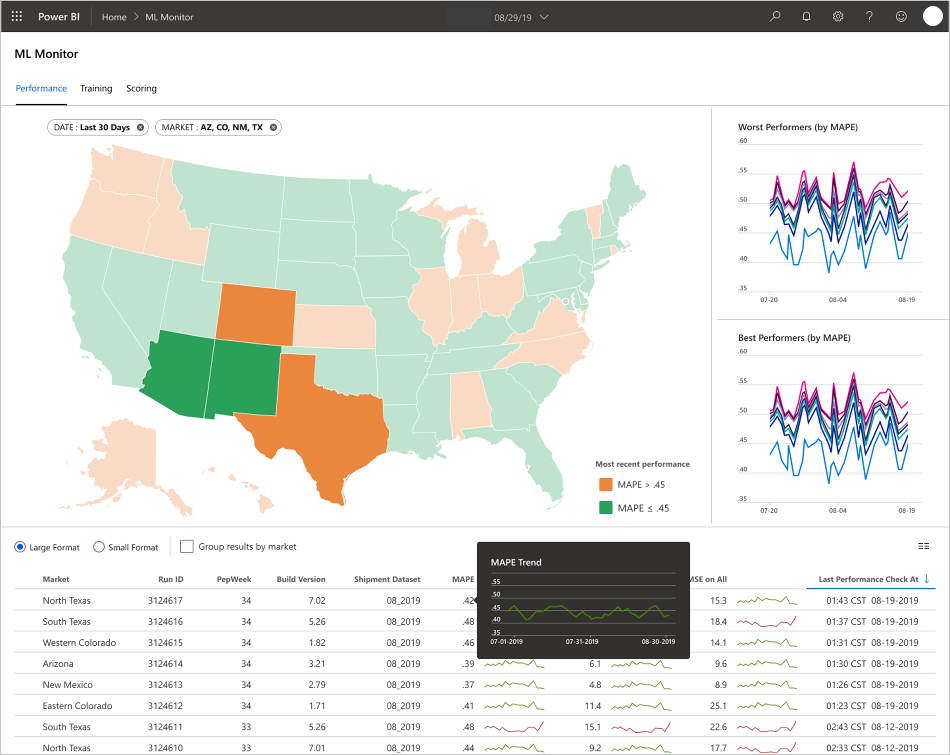
Dasbor dirancang untuk memberikan informasi yang mudah digunakan untuk dikonsumsi oleh pengguna akhir prediksi model pembelajaran mesin.
Catatan
Model kedaluarsa adalah penilaian berjalan di mana ilmuwan data melatih model yang digunakan untuk menilai lebih dari 60 hari sejak penilaian terjadi. halaman Penilaian di dasbor Pemantauan ML menampilkan metrik kesehatan ini.
Komponen
- Pembelajaran Mesin Azure
- Penyimpanan Blob Azure
- Azure Data Lake Storage
- Alur Azure
- Azure Data Factory
- Azure Functions untuk Python
- Azure Monitor
- Azure SQL Database
- Azure Dashboards
- Power BI
Pertimbangan
Di sini Anda akan menemukan daftar pertimbangan yang perlu dijelajahi. Pertimbangan ini didasarkan pada pelajaran yang diambil tim CSE selama proyek.
Pertimbangan lingkungan
- Ilmuwan data mengembangkan sebagian besar model pembelajaran mesin mereka dengan menggunakan Python, sering dimulai dengan notebook Jupyter. Notebook ini kemungkinan sulit diimplementasikan sebagai kode produksi. Notebook Jupyter lebih dari sekedar alat eksperimental, sedangkan skrip Python lebih tepat untuk produksi. Teams sering kali harus perlu menghabiskan waktu dalam merefaktorisasi kode pembuatan model ke dalam skrip Python.
- Buat klien yang baru mengenal DevOps dan pembelajaran mesin menyadari bahwa eksperimen dan produksi membutuhkan kekakuan yang berbeda, jadi praktik yang baik untuk memisahkan keduanya.
- Alat seperti Azure Pembelajaran Mesin Visual Designer atau AutoML dapat efektif dalam mendapatkan model dasar dari tanah sementara klien meningkatkan praktik DevOps standar untuk diterapkan ke solusi lainnya.
- Azure DevOps memiliki plug-in yang dapat diintegrasikan dengan Azure Pembelajaran Mesin untuk membantu memicu langkah-langkah alur. Repositori MLOpsPython memiliki beberapa contoh alur tersebut.
- Pembelajaran mesin sering membutuhkan mesin unit pemrosesan grafis (GPU) yang kuat untuk pelatihan. Jika klien belum memiliki perangkat keras seperti itu yang tersedia, Azure Pembelajaran Mesin kluster komputasi dapat menyediakan jalur yang efektif untuk menyediakan perangkat keras canggih hemat biaya dengan cepat yang diskalakan otomatis. Jika klien memiliki kebutuhan keamanan atau pemantauan tingkat lanjut, ada opsi lain seperti VM standar, Databricks, atau komputasi lokal.
- Agar klien berhasil, tim pembuat model mereka (ilmuwan data) dan tim penyebaran (teknisi DevOps) harus memiliki saluran komunikasi yang kuat. Mereka dapat menyelesaikan ini dengan rapat stand-up harian atau layanan obrolan online formal. Kedua pendekatan membantu dalam mengintegrasikan upaya pengembangan mereka dalam kerangka kerja MLOps.
Pertimbangan persiapan data
Solusi paling sederhana dalam menggunakan Azure Machine Learning adalah menyimpan data dalam solusi penyimpanan data yang didukung. Alat seperti Azure Data Factory adalah alat yang efektif untuk mengalirkan data ke dan dari lokasi tersebut sesuai jadwal.
Penting bagi klien untuk sering mengambil data pelatihan ulang tambahan untuk menjaga model mereka tetap terbarui. Jika belum memiliki alur data, klien harus membuatnya sebagai bagian dari solusi menyeluruh. Penggunaan solusi seperti Himpunan Data di Azure Machine Learning dapat berguna untuk penerapan versi data guna memudahkan pelacakan model.
Pertimbangan pelatihan dan evaluasi model
Ini luar biasa bagi klien yang baru saja memulai perjalanan pembelajaran mesin mereka untuk mencoba menerapkan alur MLOps penuh. Jika perlu, mereka dapat memudahkan ke dalamnya dengan menggunakan Azure Pembelajaran Mesin untuk melacak eksekusi eksperimen dan dengan menggunakan komputasi Azure Pembelajaran Mesin sebagai target pelatihan. Opsi ini mungkin menimbulkan penghalang solusi entri yang lebih rendah dalam memulai integrasi layanan Azure.
Beralih dari eksperimen notebook ke skrip yang dapat diulang adalah transisi kasar bagi banyak ilmuwan data. Semakin cepat Anda bisa membuat mereka menulis kode pelatihan mereka dalam skrip Python semakin mudah bagi mereka untuk mulai membuat versi kode pelatihan mereka dan memungkinkan pelatihan ulang.
Itu bukan satu-satunya kemungkinan metode. Databricks mendukung penjadwalan notebook sebagai pekerjaan. Tetapi, berdasarkan pengalaman klien saat ini, pendekatan ini sulit untuk diinstrumentasi dengan praktik DevOps penuh karena keterbatasan pengujian.
Perlu juga dipahami metrik yang digunakan untuk mempertimbangkan model berhasil. Akurasi saja sering kali tidak cukup baik dalam menentukan performa keseluruhan satu model versus yang lain.
Menghitung pertimbangan
- Pelanggan harus mempertimbangkan untuk menggunakan kontainer untuk membakukan lingkungan komputasi. Hampir semua dukungan target komputasi Azure Pembelajaran Mesin menggunakan Docker. Memiliki kontainer yang menangani dependensi dapat mengurangi gesekan secara signifikan, terutama jika tim menggunakan banyak target komputasi.
Pertimbangan penyajian model
- Azure Pembelajaran Mesin SDK menyediakan opsi untuk menyebarkan langsung ke Azure Kubernetes Service (AKS) dari model terdaftar, membuat batasan tentang keamanan/metrik apa yang ada. Anda dapat mencoba menemukan solusi yang lebih mudah bagi klien untuk menguji model mereka, tetapi yang terbaik adalah mengembangkan penyebaran yang lebih kuat ke AKS untuk beban kerja produksi.
Langkah berikutnya
- Pelajari selengkapnya tentang MLOps
- MLOps di Azure
- Visualisasi Azure Monitor
- Siklus hidup Azure Machine Learning
- Ekstensi Azure DevOps Machine Learning
- Azure Machine Learning CLI
- Memicu aplikasi, proses, atau alur kerja CI/CD berdasarkan peristiwa Azure Machine Learning
- Menyiapkan pelatihan dan penyebaran model dengan Azure DevOps
Sumber daya terkait
- Model kematangan MLOps
- Mengatur MLOps di Azure Databricks menggunakan Databricks Notebook
- MLOps untuk model Python menggunakan Azure Machine Learning
- Ilmu data dan pembelajaran mesin dengan Azure Databricks
- Citizen AI dengan Power Platform
- Menyebarkan AI dan komputasi pembelajaran mesin lokal dan ke tepi