Diperlukan aktivitas pelanggan
Pra-insiden
Untuk layanan Azure
- Kenali Azure Service Health di portal Azure. Halaman ini akan bertindak sebagai "toko serba ada" selama insiden
- Pertimbangkan penggunaan pemberitahuan Service Health, yang dapat dikonfigurasi untuk secara otomatis menghasilkan pemberitahuan saat insiden Azure terjadi
Untuk Power BI
- Kenali Service Health di pusat admin Microsoft 365. Halaman ini akan bertindak sebagai "toko serba ada" selama insiden
- Pertimbangkan penggunaan aplikasi seluler Admin Microsoft 365 untuk mendapatkan pemberitahuan pemberitahuan insiden layanan otomatis
Selama insiden
Untuk layanan Azure
- Azure Service Health dalam portal manajemen Azure mereka akan memberikan pembaruan terbaru
- Jika ada masalah saat mengakses Service Health, lihat halaman Status Azure
- Jika pernah ada masalah saat mengakses halaman Status, buka @AzureSupport X (sebelumnya Twitter)
- Jika dampak/masalah tidak cocok dengan insiden (atau berlanjut setelah mitigasi), hubungi dukungan untuk menaikkan tiket dukungan layanan
Untuk Power BI
- Halaman Service Health dalam pusat admin Microsoft 365 akan memberikan pembaruan terbaru
- Jika ada masalah saat mengakses Service Health, lihat halaman status Microsoft 365
- Jika dampak/masalah tidak cocok dengan insiden (atau jika masalah berlanjut setelah mitigasi), Anda harus menaikkan tiket dukungan layanan.
Pasca pemulihan Microsoft
Lihat bagian di bawah ini untuk detail ini.
Pasca insiden
Untuk Azure Services
- Microsoft akan menerbitkan PIR ke portal Azure - Service Health untuk ditinjau
Untuk Power BI
- Microsoft akan menerbitkan PIR ke Admin Microsoft 365 - Service Health untuk ditinjau
Tunggu proses Microsoft
Proses "Tunggu Microsoft" hanya menunggu Microsoft memulihkan semua komponen dan layanan di wilayah utama yang terkena dampak. Setelah dipulihkan, validasi pengikatan platform data ke layanan bersama perusahaan atau layanan lain, tanggal himpunan data, lalu jalankan proses membawa sistem hingga tanggal saat ini.
Setelah proses ini selesai, validasi pakar subjek teknis dan bisnis (UKM) dapat diselesaikan memungkinkan persetujuan pemangku kepentingan untuk pemulihan layanan.
Sebarkan ulang pada bencana
Untuk strategi "Sebarkan ulang pada Bencana", alur proses tingkat tinggi berikut dapat dijelaskan.
Recover Contoso – Layanan Bersama Perusahaan dan sistem sumber

- Langkah ini adalah prasyarat untuk pemulihan platform data
- Langkah ini akan diselesaikan oleh berbagai grup dukungan operasional Contoso yang bertanggung jawab atas layanan bersama perusahaan dan sistem sumber operasional
Pulihkan layanan Azure Azure Services mengacu pada aplikasi dan layanan yang membuat penawaran Azure Cloud, tersedia dalam wilayah sekunder untuk penyebaran.

Azure Services mengacu pada aplikasi dan layanan yang membuat penawaran Azure Cloud, tersedia dalam wilayah sekunder untuk penyebaran.
- Langkah ini adalah prasyarat untuk pemulihan platform data
- Langkah ini akan diselesaikan oleh Microsoft dan mitra platform as a service (PaaS)/software as a service (SaaS) lainnya
Memulihkan fondasi platform data
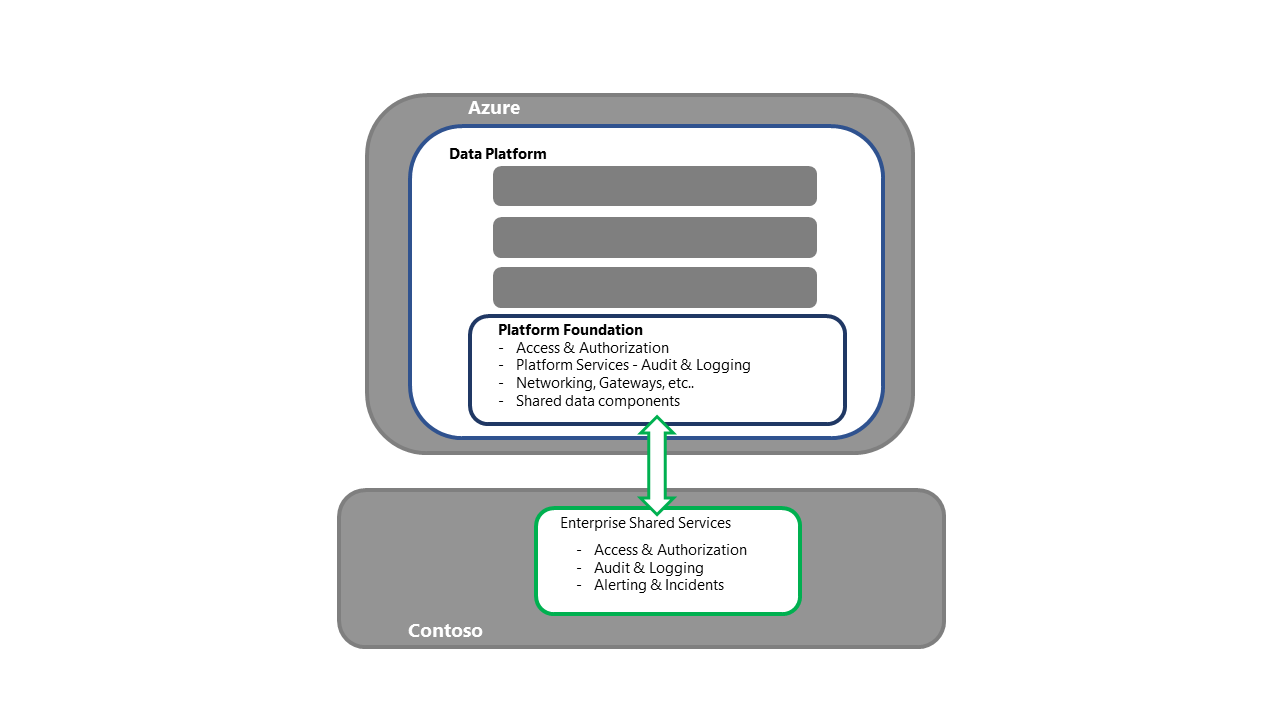
- Langkah ini adalah titik masuk untuk aktivitas pemulihan Platform
- Untuk strategi Penyebaran Ulang, setiap komponen/layanan yang diperlukan akan diakui dan disebarkan ke wilayah sekunder
- Lihat Bagian Layanan dan Komponen Azure dalam seri ini untuk perincian terperinci tentang komponen dan strategi penyebaran
- Proses ini juga harus mencakup aktivitas seperti pengikatan ke layanan bersama perusahaan, memastikan konektivitas untuk mengakses/mengautentikasi, dan memvalidasi bahwa offloading log berfungsi, sekaligus memastikan konektivitas ke proses hulu dan hilir
- Data/Pemrosesan harus dikonfirmasi. Misalnya, validasi tanda waktu platform yang dipulihkan
- Jika ada pertanyaan tentang integritas data, keputusan dapat dibuat untuk kembali lebih jauh sebelum menjalankan pemrosesan baru untuk memperbarui platform
- Memiliki urutan prioritas untuk proses (berdasarkan dampak bisnis) akan membantu dalam mengatur pemulihan
- Langkah ini harus ditutup oleh validasi teknis kecuali pengguna bisnis langsung berinteraksi dengan layanan. Jika ada akses langsung, perlu ada langkah validasi bisnis
- Setelah validasi selesai, penyerahan kepada tim solusi individu untuk memulai proses pemulihan bencana (DR) mereka sendiri terjadi
- Penyerahan ini harus mencakup konfirmasi tanda waktu data/proses saat ini
- Jika proses data perusahaan inti akan dijalankan, solusi individu harus mengetahui hal ini - alur masuk/keluar, misalnya
Memulihkan solusi individual yang dihosting oleh platform
- Setiap solusi individu harus memiliki runbook DR sendiri. Runbook setidaknya harus berisi pemangku kepentingan bisnis yang dicalonkan yang akan menguji dan mengonfirmasi bahwa pemulihan layanan telah selesai
- Bergantung pada ketidakcocokan atau prioritas sumber daya, solusi/beban kerja utama dapat diprioritaskan daripada yang lain - proses perusahaan inti melalui lab ad hoc, misalnya
- Setelah langkah-langkah validasi selesai, penyerahan ke solusi hilir untuk memulai proses pemulihan DR mereka terjadi
Serah terima ke sistem hilir dan dependen
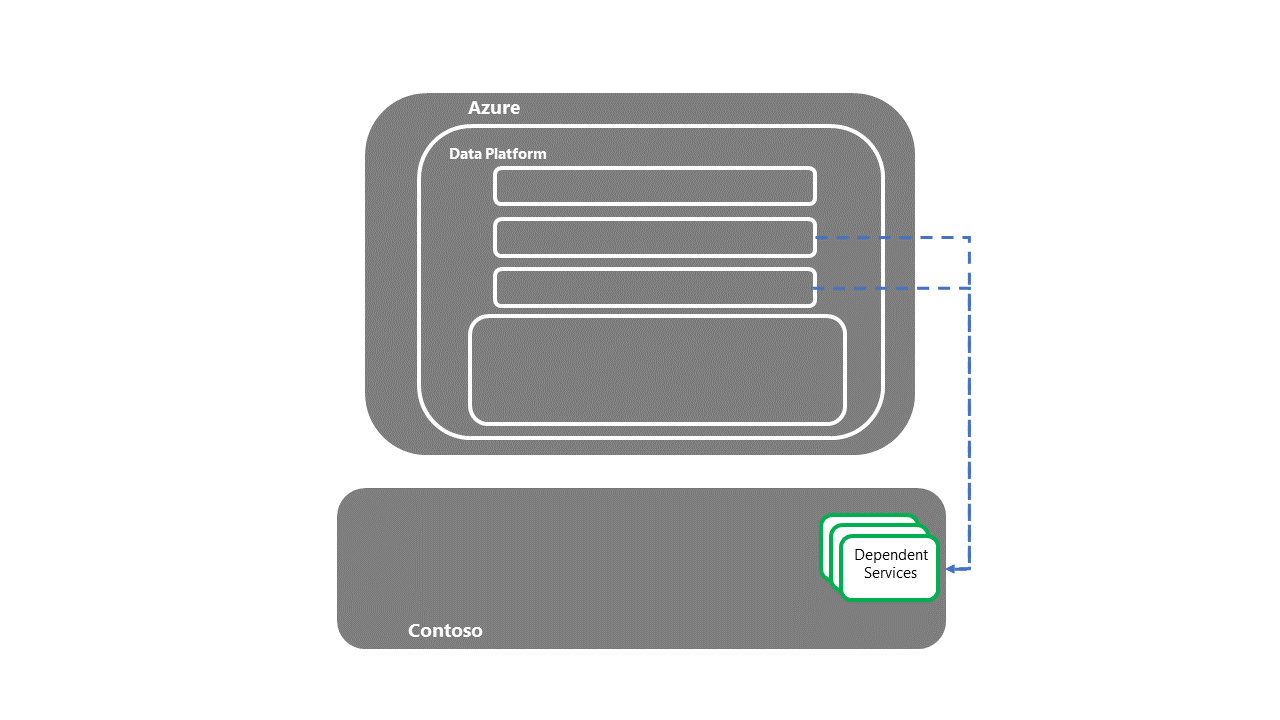
- Setelah layanan dependen dipulihkan, proses pemulihan E2E DR selesai
Catatan
Meskipun secara teoritis mungkin untuk sepenuhnya mengotomatiskan proses E2E DR, tidak mungkin mengingat risiko peristiwa vs. biaya aktivitas SDLC yang diperlukan untuk mencakup proses E2E
Fallback ke wilayah utama Fallback adalah proses pemindahan layanan platform data dan datanya kembali ke wilayah utama, setelah tersedia untuk BAU.
Tergantung pada sifat sistem sumber dan berbagai proses data, fallback platform data dapat dilakukan secara independen dari bagian lain dari sistem lingkungan data.
Pelanggan disarankan untuk meninjau dependensi platform data mereka sendiri (baik hulu maupun hilir) untuk membuat keputusan yang sesuai. Bagian berikut mengasumsikan pemulihan independen platform data.
- Setelah semua komponen/layanan yang diperlukan tersedia di wilayah utama, pelanggan akan menyelesaikan uji asap untuk memvalidasi pemulihan Microsoft
- Konfigurasi Komponen/Layanan akan divalidasi. Delta akan diatasi melalui penyebaran ulang dari kontrol sumber
- Tanggal sistem di wilayah utama akan ditetapkan di seluruh komponen stateful. Delta antara tanggal yang ditetapkan dan tanggal/tanda waktu di wilayah sekunder harus ditangani dengan mengeksekusi ulang atau memutar ulang proses penyerapan data dari titik tersebut ke depan
- Dengan persetujuan dari pemangku kepentingan bisnis dan teknis, jendela fallback akan dipilih. Idealnya, selama lull dalam aktivitas dan pemrosesan sistem
- Selama fallback, wilayah utama akan disinkronkan dengan wilayah sekunder, sebelum sistem dialihkan
- Setelah periode eksekusi paralel, wilayah sekunder akan diambil secara offline dari sistem
- Komponen di wilayah sekunder akan dihilangkan atau dilucuti kembali, tergantung pada strategi DR yang dipilih
Proses cadangan hangat
Untuk strategi "Warm Spare", alur proses tingkat tinggi selaras erat dengan "Penyebaran Ulang pada Bencana", perbedaan utama adalah bahwa komponen telah diakui di wilayah sekunder. Strategi ini menghilangkan risiko ketidakcocokan sumber daya dari organisasi lain yang ingin menyelesaikan DR mereka sendiri di wilayah tersebut.
Proses cadangan panas
Strategi "Hot Spare" berarti bahwa layanan Platform termasuk PaaS dan sistem infrastruktur sebagai layanan (IaaS) akan bertahan meskipun peristiwa bencana karena sistem sekunder berjalan bersama dengan sistem utama. Seperti strategi "Warm Spare", strategi ini menghilangkan risiko ketidakcocokan sumber daya dari organisasi lain yang ingin menyelesaikan DR mereka sendiri di wilayah tersebut.
Pelanggan Hot Spare akan memantau pemulihan komponen/layanan Microsoft di wilayah utama. Setelah selesai, pelanggan akan memvalidasi sistem wilayah utama dan menyelesaikan fallback ke wilayah utama. Proses ini akan mirip dengan proses Failover DR yaitu, periksa basis kode dan data yang tersedia, penyebaran ulang sesuai kebutuhan.
Catatan
Catatan khusus di sini harus dibuat untuk memastikan bahwa metadata sistem apa pun konsisten antara kedua wilayah.
- Setelah Fallback ke primer selesai, penyeimbang beban sistem dapat diperbarui untuk membawa wilayah utama kembali ke topologi sistem. Jika tersedia, pendekatan rilis kenari dapat digunakan untuk secara bertahap mengalihkan wilayah utama untuk sistem.
Struktur rencana DR
Paket DR yang efektif menyajikan panduan langkah demi langkah untuk pemulihan layanan yang dapat dijalankan oleh sumber daya teknis Azure. Dengan demikian, berikut ini mencantumkan struktur MVP yang diusulkan untuk Paket DR.
- Persyaratan Proses
- Setiap detail khusus proses DR pelanggan, seperti otorisasi yang benar yang diperlukan untuk memulai DR, dan membuat keputusan utama tentang pemulihan seperlunya (termasuk "definisi selesai"), referensi tiket dukungan layanan DR, dan detail ruang perang
- Konfirmasi sumber daya, termasuk prospek DR dan cadangan pelaksana. Semua sumber daya harus didokumenkan dengan kontak primer dan sekunder, jalur eskalasi, dan meninggalkan kalender. Dalam situasi DR kritis, sistem daftar mungkin perlu dipertimbangkan
- Laptop, paket daya dan/atau daya cadangan, konektivitas jaringan, dan detail ponsel untuk pelaksana DR, cadangan DR, dan titik eskalasi apa pun
- Proses yang akan diikuti jika salah satu persyaratan proses tidak terpenuhi
- Daftar Kontak
- Grup kepemimpinan dan dukungan DR
- UKM Bisnis yang akan menyelesaikan siklus pengujian/peninjauan untuk pemulihan teknis
- Pemilik Bisnis yang Terkena Dampak, termasuk pemberi izin pemulihan layanan
- Pemilik Teknis yang terkena dampak, termasuk pemberi izin pemulihan teknis
- Dukungan UKM di semua area yang terkena dampak, termasuk solusi utama yang dihosting oleh platform
- Sistem Hilir Dampak – dukungan operasional
- Sistem Sumber Upstream – dukungan operasional
- Kontak layanan bersama perusahaan. Misalnya, dukungan akses/autentikasi, pemantauan keamanan, dan dukungan gateway
- Vendor eksternal atau pihak ketiga apa pun, termasuk kontak dukungan untuk penyedia cloud
- Desain arsitektur
- Jelaskan detail skenario end-end to E2E, dan lampirkan semua dokumentasi dukungan terkait
- Dependensi
- Mencantumkan semua hubungan dan dependensi komponen
- Prasyarat DR
- Konfirmasi bahwa sistem sumber hulu tersedia sesuai kebutuhan
- Akses yang ditingkatkan di seluruh tumpukan telah diberikan ke sumber daya pelaksana DR
- Layanan Azure tersedia sesuai kebutuhan
- Proses yang akan diikuti jika salah satu prasyarat belum terpenuhi
- Pemulihan Teknis - Instruksi Langkah demi Langkah
- Jalankan pesanan
- Deskripsi langkah
- Prasyarat langkah
- Langkah-langkah proses terperinci untuk setiap tindakan diskrit, termasuk URL
- Petunjuk validasi, termasuk bukti yang diperlukan
- Waktu yang diharapkan untuk menyelesaikan setiap langkah, termasuk kontingensi
- Proses yang akan diikuti jika langkah gagal
- Poin eskalasi dalam kasus kegagalan atau dukungan UKM
- Pemulihan Teknis - Pascasarjana
- Mengonfirmasi tanda waktu tanggal sistem saat ini di seluruh komponen utama
- Mengonfirmasi URL & IP sistem DR
- Bersiaplah untuk proses peninjauan Pemangku Kepentingan Bisnis, termasuk konfirmasi akses sistem dan UKM bisnis yang menyelesaikan validasi dan persetujuan
- Tinjauan dan Persetujuan Pemangku Kepentingan Bisnis
- Detail kontak sumber daya bisnis
- Langkah-langkah validasi Bisnis sesuai pemulihan teknis di atas
- Jejak Bukti yang diperlukan dari pemberi izin Bisnis yang menandatangani pemulihan
- Pemulihan Pascasarjana
- Serah terima ke dukungan operasional untuk menjalankan proses data untuk memperbarui sistem
- Serah terima proses dan solusi hilir – mengonfirmasi tanggal dan detail koneksi sistem DR
- Konfirmasi proses pemulihan lengkap dengan prospek DR – mengonfirmasi jejak bukti dan runbook yang telah selesai
- Memberi tahu administrasi Keamanan bahwa hak istimewa akses yang ditingkatkan dapat dihapus dari tim DR
Callouts
- Disarankan untuk menyertakan cuplikan layar sistem dari setiap proses langkah. Cuplikan layar ini akan membantu mengatasi dependensi pada UKM sistem untuk menyelesaikan tugas
- Untuk mengurangi risiko dari layanan Cloud yang berkembang dengan cepat, paket DR harus secara teratur direvisi, diuji, dan dijalankan oleh sumber daya dengan pengetahuan Azure saat ini dan layanannya
- Langkah-langkah pemulihan teknis harus mencerminkan prioritas komponen dan solusi untuk organisasi. Misalnya, aliran data perusahaan inti dipulihkan sebelum lab analisis data ad hoc
- Langkah-langkah pemulihan teknis harus mengikuti urutan alur kerja (biasanya kiri ke kanan), setelah komponen/layanan fondasi seperti Key Vault telah dipulihkan. Strategi ini akan memastikan dependensi hulu tersedia dan komponen dapat diuji dengan tepat
- Setelah rencana langkah demi langkah selesai, total waktu untuk aktivitas dengan kontingensi harus diperoleh. Jika total ini melebihi tujuan waktu pemulihan (RTO) yang disepakati, ada beberapa opsi yang tersedia:
- Mengotomatiskan proses pemulihan yang dipilih (jika memungkinkan)
- Cari peluang untuk menjalankan langkah-langkah pemulihan yang dipilih secara paralel (jika memungkinkan). Namun, mencatat bahwa strategi ini mungkin memerlukan sumber daya pelaksana DR tambahan.
- Tingkatkan komponen utama ke tingkat tingkat layanan yang lebih tinggi seperti PaaS, di mana Microsoft bertanggung jawab lebih besar untuk aktivitas pemulihan layanan
- Memperluas RTO dengan pemangku kepentingan
Pengujian DR
Sifat penawaran layanan Azure Cloud menghasilkan batasan untuk skenario pengujian DR apa pun. Oleh karena itu, panduannya adalah membuat langganan DR dengan komponen platform data karena akan tersedia di wilayah sekunder.
Dari garis besar ini, runbook paket DR dapat dijalankan secara selektif, memberikan perhatian khusus pada layanan dan komponen yang dapat disebarkan dan divalidasi. Proses ini akan memerlukan himpunan data pengujian yang dikumpulkan, memungkinkan konfirmasi pemeriksaan validasi teknis dan bisnis sesuai rencana.
Rencana DR harus diuji secara teratur untuk tidak hanya memastikan bahwa itu sudah diperbarui, tetapi juga untuk membangun "memori otot" bagi tim yang melakukan aktivitas failover dan pemulihan.
- Pencadangan data dan konfigurasi juga harus diuji secara teratur untuk memastikan mereka "cocok untuk tujuan" untuk mendukung aktivitas pemulihan apa pun.
Area utama yang harus difokuskan selama pengujian DR adalah memastikan langkah-langkah preskriptif masih benar dan perkiraan waktunya masih relevan.
- Jika instruksi mencerminkan layar portal daripada kode - instruksi harus divalidasi setidaknya setiap 12 bulan karena irama perubahan cloud.
Meskipun aspirasinya adalah memiliki proses DR yang sepenuhnya otomatis, otomatisasi penuh mungkin tidak mungkin karena kelangkaan peristiwa. Oleh karena itu, disarankan untuk menetapkan garis besar pemulihan dengan infrastruktur Desired State Configuration (DSC) sebagai kode (IaC) yang digunakan untuk mengirimkan platform dan kemudian meningkatkan sebagai proyek baru yang dibangun berdasarkan garis besar.
- Seiring waktu karena komponen dan layanan diperluas, NFR harus diberlakukan, mengharuskan alur penyebaran produksi direfaktor untuk memberikan cakupan untuk DR.
Jika waktu runbook Anda melebihi RTO Anda, ada beberapa opsi:
- Memperluas RTO dengan pemangku kepentingan
- Menurunkan waktu yang diperlukan untuk aktivitas pemulihan, melalui otomatisasi, menjalankan tugas secara paralel atau migrasi ke tingkat server cloud yang lebih tinggi
Azure Chaos Studio
Azure Chaos Studio adalah layanan terkelola untuk meningkatkan ketahanan dengan menyuntikkan kesalahan ke aplikasi Azure Anda. Chaos Studio memungkinkan Anda mengatur injeksi kesalahan pada sumber daya Azure Anda dengan cara yang aman dan terkontrol, menggunakan eksperimen. Lihat dokumentasi produk untuk deskripsi jenis kesalahan yang saat ini didukung.
Iterasi Chaos Studio saat ini hanya mencakup subset komponen dan layanan Azure. Hingga lebih banyak pustaka kesalahan ditambahkan, Chaos Studio adalah pendekatan yang direkomendasikan untuk pengujian ketahanan terisolasi daripada pengujian DR sistem penuh.
Informasi lebih lanjut tentang chaos studio dapat ditemukan di sini
Azure Site Recovery
Untuk komponen IaaS, Azure Site Recovery akan melindungi sebagian besar beban kerja yang berjalan di VM atau server fisik yang didukung
Ada panduan yang kuat untuk:
- Menjalankan Latihan Pemulihan Bencana Azure VM
- Menjalankan failover DR ke Wilayah Sekunder
- Menjalankan fallback DR ke Wilayah Utama
- Mengaktifkan otomatisasi Paket DR
Sumber daya terkait
- Merancang untuk ketahanan dan ketersediaan
- Kelangsungan bisnis dan pemulihan bencana
- Pencadangan dan pemulihan bencana untuk aplikasi Azure
- Ketahanan di Azure
- Ringkasan perjanjian tingkat layanan (SLA)
- Lima Praktik Terbaik untuk Mengantisipasi Kegagalan
Langkah berikutnya
Setelah mempelajari cara menyebarkan skenario, Anda dapat membaca ringkasan seri platform data DR untuk Azure.