Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Data lake adalah repositori penyimpanan yang menyimpan sejumlah besar data dalam format asli dan mentahnya. Penyimpanan data lake dioptimalkan untuk menskalakan ukurannya menjadi terabyte dan petabyte data. Data biasanya berasal dari berbagai sumber dan dapat mencakup data terstruktur, semi terstruktur, atau tidak terstruktur. Data lake membantu Anda menyimpan semuanya dalam status aslinya yang tidak ditransformasi. Metode ini berbeda dari gudang data tradisional, yang mengubah dan memproses data pada saat penyerapan.
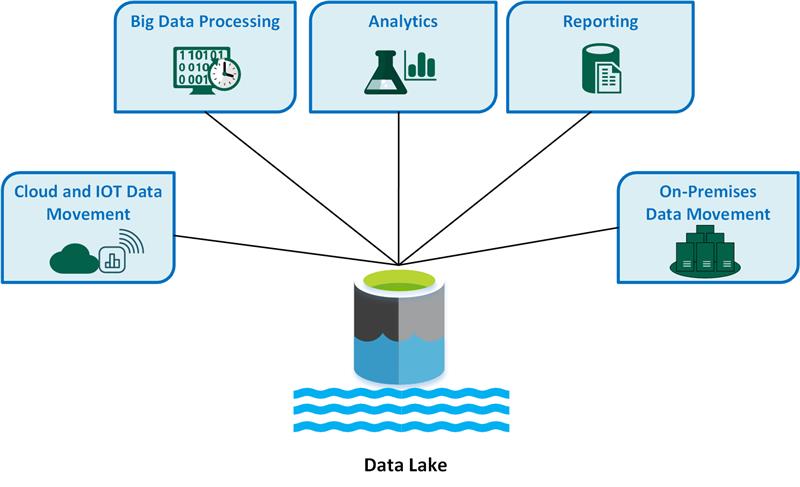
Kasus penggunaan data lake utama meliputi:
- Pergerakan data Cloud dan Internet of Things (IoT).
- Pemrosesan big data.
- Analitik.
- Pelaporan.
- Pergerakan data lokal.
Pertimbangkan keuntungan data lake berikut:
Data lake tidak pernah menghapus data karena menyimpan data dalam format mentahnya. Fitur ini sangat berguna di lingkungan big data karena Anda mungkin tidak tahu terlebih dahulu wawasan apa yang bisa Anda dapatkan dari data.
Pengguna dapat menjelajahi data dan membuat kueri mereka sendiri.
Data lake mungkin lebih cepat daripada alat ekstrak, transformasi, pemuatan (ETL) tradisional.
Data lake lebih fleksibel daripada gudang data karena dapat menyimpan data yang tidak terstruktur dan semi terstruktur.
Solusi data lake lengkap terdiri dari penyimpanan dan pemrosesan. Penyimpanan data lake dirancang untuk toleransi kesalahan, skalabilitas tak terbatas, dan penyerapan throughput tinggi dari berbagai bentuk dan ukuran data. Pemrosesan data lake melibatkan satu atau beberapa mesin pemrosesan yang dapat menggabungkan tujuan ini dan dapat beroperasi pada data yang disimpan dalam data lake dalam skala besar.
Kapan Anda harus menggunakan data lake
Kami menyarankan agar Anda menggunakan data lake untuk eksplorasi data, analitik data, dan pembelajaran mesin.
Data lake dapat bertindak sebagai sumber data untuk gudang data. Saat Anda menggunakan metode ini, data lake menyerap data mentah lalu mengubahnya menjadi format yang dapat dikueri terstruktur. Biasanya, transformasi ini menggunakan alur ekstrak, muat, transformasi (ELT) di mana data dimuat dan diubah di tempat. Data sumber relasional mungkin langsung masuk ke gudang data melalui proses ETL dan melewati data lake.
Anda dapat menggunakan penyimpanan data lake dalam streaming peristiwa atau skenario IoT karena data lake dapat mempertahankan sejumlah besar data relasional dan nonrelasional tanpa transformasi atau definisi skema. Data lake dapat menangani penulisan kecil dalam volume tinggi pada latensi rendah dan dioptimalkan untuk throughput besar-besaran.
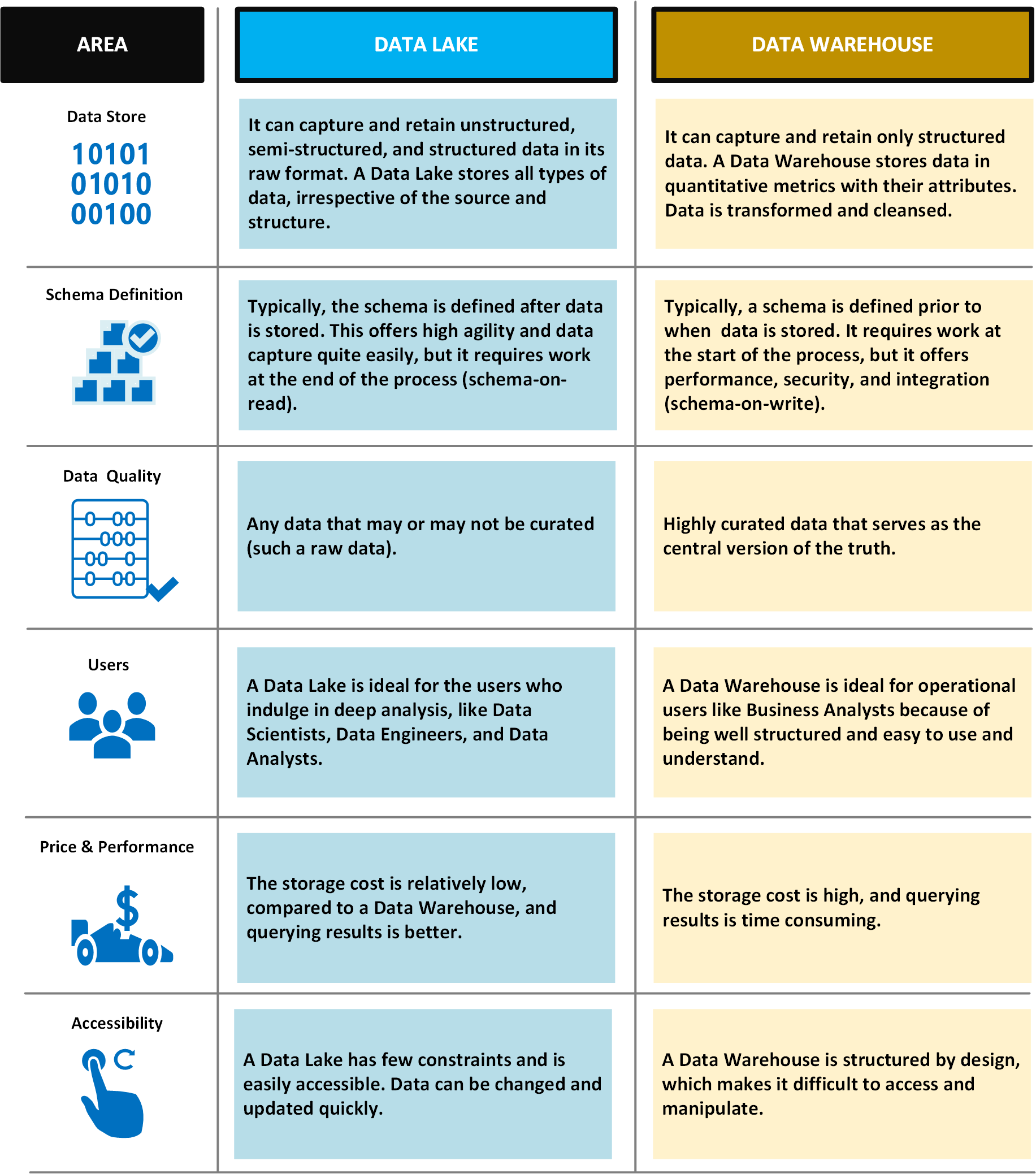
Tabel berikut membandingkan data lake dan gudang data.
Tantangan
Data dalam volume besar: Manajemen sejumlah besar data mentah dan tidak terstruktur dapat menjadi kompleks dan intensif sumber daya, sehingga Anda memerlukan infrastruktur dan alat yang kuat.
Potensi hambatan: Pemrosesan data dapat memperkenalkan penundaan dan inefisiensi, terutama ketika Anda memiliki volume data yang tinggi dan jenis data yang beragam.
Risiko kerusakan data: Validasi dan pemantauan data yang tidak tepat menimbulkan risiko kerusakan data, yang dapat membahayakan integritas data lake.
Masalah kontrol kualitas: Kualitas data yang tepat adalah tantangan karena berbagai sumber dan format data. Anda harus menerapkan praktik tata kelola data yang ketat.
Masalah performa: Performa kueri dapat turun seiring pertumbuhan data lake, sehingga Anda harus mengoptimalkan strategi penyimpanan dan pemrosesan.
Pilihan teknologi
Saat Anda membangun solusi data lake yang komprehensif di Azure, pertimbangkan teknologi berikut:
Azure Data Lake Storage menggabungkan Azure Blob Storage dengan kemampuan data lake, yang menyediakan akses yang kompatibel dengan Apache Hadoop, kemampuan namespace hierarkis, dan keamanan yang ditingkatkan untuk analitik big data yang efisien.
Azure Databricks adalah platform terpadu yang dapat Anda gunakan untuk memproses, menyimpan, menganalisis, dan memonetisasi data. Ini mendukung proses ETL, dasbor, keamanan, eksplorasi data, pembelajaran mesin, dan AI generatif.
Azure Synapse Analytics adalah layanan terpadu yang dapat Anda gunakan untuk menyerap, menjelajahi, menyiapkan, mengelola, dan melayani data untuk kecerdasan bisnis segera dan kebutuhan pembelajaran mesin. Ini terintegrasi secara mendalam dengan data lake Azure sehingga Anda dapat mengkueri dan menganalisis himpunan data besar secara efisien.
Azure Data Factory adalah layanan integrasi data berbasis cloud yang dapat Anda gunakan untuk membuat alur kerja berbasis data untuk kemudian mengatur dan mengotomatiskan pergerakan dan transformasi data.
Microsoft Fabric adalah platform data komprehensif yang menyatukan rekayasa data, ilmu data, pergudangan data, analitik real time, dan kecerdasan bisnis ke dalam satu solusi.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Avijit Prasad | Konsultan Cloud
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.
Langkah berikutnya
- Apa itu OneLake?
- Pengantar Data Lake Storage
- Dokumentasi Azure Data Lake Analytics
- Pelatihan: Pengantar Data Lake Storage
- Integrasi Hadoop dan Azure Data Lake Storage
- Menyambungkan ke Data Lake Storage dan Blob Storage
- Memuat data ke Dalam Data Lake Storage dengan Azure Data Factory