Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tip
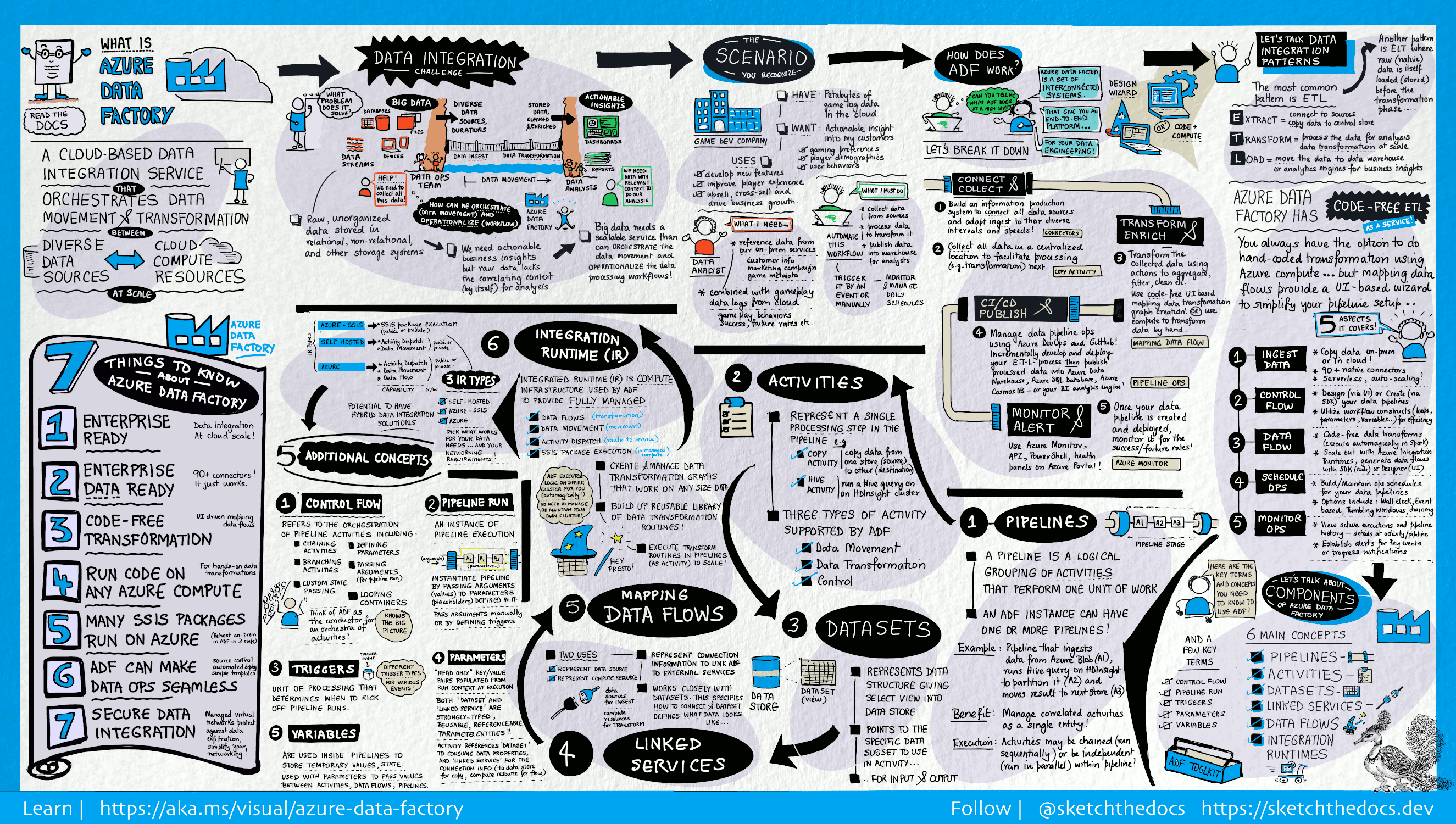
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Dalam dunia big data, data mentah dan tidak terorganisir sering kali disimpan dalam sistem penyimpanan relasional, non-relasional, dan lainnya. Namun, dengan sendirinya, data mentah tidak memiliki konteks atau makna yang tepat untuk memberikan wawasan yang bermakna kepada analis, ilmuwan data, atau pembuat keputusan bisnis.
Big data memerlukan layanan yang dapat mengatur dan mengoperasionalkan proses untuk memperbaiki penyimpanan data mentah yang sangat besar ini menjadi wawasan bisnis yang dapat ditindaklanjuti. Azure Data Factory adalah layanan cloud terkelola yang dibangun untuk proyek ekstraksi-transformasi-muat (ETL), ekstraksi-muat-transformasi (ELT), dan integrasi data hibrida kompleks ini.
Fitur Azure Data Factory
Selama aktivitas Salin Data, dimungkinkan untuk mengompresi data dan menulis data terkompresi ke sumber data target. Fitur ini membantu mengoptimalkan penggunaan bandwidth dalam penyalinan data.
Dukungan Konektivitas Ekstensif untuk Sumber Data yang Berbeda: Azure Data Factory menyediakan dukungan konektivitas yang luas untuk menyambungkan ke sumber data yang berbeda. Ini berguna ketika Anda ingin menarik atau menulis data dari sumber data yang berbeda.
Pemicu Peristiwa Kustom: Azure Data Factory memungkinkan Anda mengotomatiskan pemrosesan data menggunakan pemicu peristiwa kustom. Fitur ini memungkinkan Anda untuk secara otomatis menjalankan tindakan tertentu ketika peristiwa tertentu terjadi.
Pratinjau dan Validasi Data: Selama Copy Activity, alat disediakan untuk mempratinjau dan memvalidasi data. Fitur ini membantu Anda memastikan bahwa data disalin dengan benar dan ditulis ke sumber data target dengan benar.
Aliran Data yang Dapat Disesuaikan: Azure Data Factory memungkinkan Anda membuat aliran data yang dapat disesuaikan. Fitur ini memungkinkan Anda menambahkan tindakan atau langkah kustom untuk pemrosesan data.
Keamanan Terintegrasi: Azure Data Factory menawarkan fitur keamanan terintegrasi seperti integrasi Entra ID dan kontrol akses berbasis peran untuk mengontrol akses ke aliran data. Fitur ini meningkatkan keamanan dalam pemrosesan data dan melindungi data Anda.
Skenario penggunaan
Misalnya, bayangkan perusahaan game yang mengumpulkan petabyte log game yang diproduksi oleh game di cloud. Perusahaan tersebut ingin menganalisis log ini untuk mendapatkan wawasan tentang preferensi pelanggan, demografi, dan perilaku penggunaan. Perusahaan tersebut juga ingin mengidentifikasi peluang up-sell dan cross-sell, mengembangkan fitur baru yang menarik, mendorong pertumbuhan bisnis, dan memberikan pengalaman yang lebih baik kepada pelanggan.
Untuk menganalisis log ini, perusahaan perlu menggunakan data referensi seperti informasi pelanggan, informasi game, dan informasi kampanye pemasaran yang ada di penyimpanan data lokal. Perusahaan ingin menggunakan data ini dari penyimpanan data lokal, menggabungkannya dengan data log tambahan yang ada di penyimpanan data cloud.
Untuk mengekstrak wawasan, ia berharap untuk memproses data yang bergabung dengan menggunakan kluster Spark di cloud (Azure HDInsight), dan menerbitkan data yang diubah menjadi gudang data cloud seperti Azure Synapse Analytics untuk dengan mudah membangun laporan di atasnya. Mereka ingin mengotomatisasi alur kerja ini, dan memantau dan mengelolanya di jadwal harian. Mereka juga ingin mengeksekusinya ketika file mendarat di kontainer penyimpanan blob.
Azure Data Factory adalah platform yang memecahkan skenario data tersebut. Ini adalah layanan ETL dan integrasi data berbasis cloud yang memungkinkan Anda membuat alur kerja berbasis data untuk mengkoordinasikan pergerakan data dan mengubah data dalam skala besar. Dengan menggunakan Azure Data Factory, Anda dapat membuat dan menjadwalkan alur kerja berbasis data (disebut alur) yang dapat menyerap data dari penyimpanan data yang berbeda. Anda dapat membangun proses ETL kompleks yang mengubah data secara visual dengan aliran data atau dengan menggunakan layanan komputasi seperti Azure HDInsight Hadoop, Azure Databricks, dan Azure SQL Database.
Selain itu, Anda dapat menerbitkan data yang diubah ke penyimpanan data seperti Azure Synapse Analytics untuk digunakan aplikasi kecerdasan bisnis (BI). Pada akhirnya, melalui Azure Data Factory, data mentah dapat diatur ke dalam penyimpanan data dan data lake yang bermakna untuk keputusan bisnis yang lebih baik.
Bagaimana cara kerjanya?
Azure Data Factory (ADF) berisi serangkaian sistem yang saling terhubung, yang menyediakan platform end-to-end lengkap untuk para teknisi data.

Panduan visual ini memberikan gambaran umum terperinci tentang arsitektur lengkap Data Factory:

Untuk melihat detail selengkapnya, pilih gambar sebelumnya untuk memperbesar, atau telusuri ke gambar resolusi tinggi. Pelajari tentang pengembangan panduan visual ini dan sketsa proyek dokumen di sini.
{kind=link}
Menyambungkan dan mengumpulkan
Perusahaan memiliki berbagai jenis data yang terletak di sumber yang berbeda di lokal, di cloud, terstruktur, tidak terstruktur, dan semi-terstruktur, semuanya tiba pada interval dan kecepatan yang berbeda.
Langkah pertama dalam membangun sistem produksi informasi adalah terhubung ke semua sumber data dan pemrosesan yang diperlukan, seperti layanan perangkat lunak sebagai layanan (SaaS), database, berbagi file, dan layanan web FTP. Kemudian pindahkan data sesuai kebutuhan ke lokasi terpusat untuk pemrosesan berikutnya.
Tanpa Data Factory, perusahaan harus membangun komponen pemindahan data kustom atau menulis layanan kustom untuk mengintegrasikan sumber data dan pemrosesan ini. Mahal dan sulit untuk mengintegrasikan dan memelihara sistem tersebut. Sistem ini juga sering tidak memiliki pemantauan, pemberitahuan, dan kontrol tingkat perusahaan yang dapat ditawarkan oleh layanan yang dikelola penuh.
Dengan Data Factory, Anda dapat menggunakan Aktivitas Salin dalam alur data untuk memindahkan data dari penyimpanan data sumber baik lokal maupun cloud ke penyimpanan data terpusat di cloud untuk analisis lanjutan. Misalnya, Anda dapat mengumpulkan data dalam Azure Data Lake Storage dan mengubah data nanti dengan menggunakan layanan komputasi Azure Data Lake Analytics. Anda juga dapat mengumpulkan data di penyimpanan Blob Azure dan mengubahnya nanti dengan menggunakan kluster Azure HDInsight Hadoop.
Mengubah dan memperkaya
Setelah data ada di penyimpanan data terpusat di cloud, proses atau transformasi data yang dikumpulkan dengan menggunakan alur data pemetaan ADF. Alur data memungkinkan teknisi data untuk membangun dan memelihara grafik transformasi data yang dijalankan pada Spark tanpa perlu memahami kluster Spark atau pemrograman Spark.
Jika Anda lebih suka mengodekan transformasi dengan tangan, ADF mendukung aktivitas eksternal untuk menjalankan transformasi Anda pada layanan komputasi seperti HDInsight Hadoop, Spark, Data Lake Analytics, dan Machine Learning.
CI/CD dan publikasi
Data Factory menawarkan dukungan penuh untuk CI/CD alur data Anda menggunakan Azure DevOps dan GitHub. Ini memungkinkan Anda untuk secara bertahap mengembangkan dan memberikan proses ETL Anda sebelum menerbitkan produk jadi. Setelah data mentah disempurnakan ke dalam bentuk siap konsumsi untuk bisnis, muat data ke dalam Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB, atau mesin analitik mana pun yang dapat diakses oleh pengguna bisnis Anda dari alat kecerdasan bisnis mereka.
Monitor
Setelah Anda berhasil membangun dan menerapkan alur integrasi data Anda, memberikan nilai bisnis dari data yang disempurnakan, pantau aktivitas dan alur terjadwal untuk tingkat keberhasilan dan kegagalan. Azure Data Factory memiliki dukungan bawaan untuk pemantauan alur melalui Azure Monitor, API, PowerShell, log Azure Monitor, dan panel kesehatan di portal Azure.
Konsep tingkat atas
Langganan Azure mungkin memiliki satu atau beberapa instans Azure Data Factory (atau pabrik data). Azure Data Factory terdiri dari komponen utama berikut:
- Pipelines
- Aktivitas
- Datasets
- Layanan Tertaut
- Aliran Data
- Waktu Jalankan Integrasi
Komponen-komponen ini bekerja sama untuk menyediakan platform tempat Anda dapat menyusun alur kerja berbasis data dengan langkah-langkah untuk memindahkan dan mengubah data.
Pipeline
Pabrik data dapat memiliki satu atau beberapa alur. Jalur adalah pengelompokan logis dari aktivitas-aktivitas yang menjalankan satu unit kerja. Aktivitas dalam alur bekerja sama untuk melakukan tugas tertentu. Misalnya, alur dapat berisi sekelompok aktivitas yang menyerap data dari blob Azure, lalu menjalankan kueri Apache Hive pada kluster HDInsight untuk mempartisi data.
Keuntungannya adalah bahwa alur memungkinkan Anda untuk mengelola aktivitas sebagai satu kesatuan alih-alih masing-masing secara individual. Kegiatan dalam pipa dapat dirangkai bersama untuk beroperasi secara berurutan, atau mereka dapat beroperasi secara independen secara paralel.
Aliran data pemetaan
Buat dan kelola grafik logika transformasi data yang bisa Anda gunakan untuk mentransformasi data berukuran apa pun. Anda dapat membangun perpustakaan yang dapat digunakan kembali dari rutinitas transformasi data dan menjalankan proses tersebut dengan cara yang terdistribusi dari pipeline ADF Anda. Azure Data Factory akan mengeksekusi logika Anda pada kluster Spark yang berputar ke atas dan bawah saat Anda membutuhkannya. Anda tidak perlu mengelola atau memelihara kluster.
Aktivitas
Aktivitas mewakili langkah pemrosesan dalam alur kerja. Misalnya, Anda dapat menggunakan aktivitas salin untuk menyalin data dari satu penyimpanan data ke penyimpanan data lain. Demikian pula, Anda mungkin menggunakan aktivitas Apache Hive, yang menjalankan kueri Apache Hive pada kluster Azure HDInsight, untuk mengubah atau menganalisis data Anda. Azure Data Factory memiliki tiga pengelompokan aktivitas: aktivitas pemindahan data, aktivitas transformasi data, dan aktivitas kontrol.
Datasets
Himpunan data mewakili struktur data dalam penyimpanan data, yang hanya menunjuk ke atau mereferensikan data yang ingin Anda gunakan dalam aktivitas Anda sebagai input atau output.
Layanan Tertaut
Layanan tertaut mirip seperti string koneksi, yang menentukan informasi koneksi yang diperlukan agar Data Factory tersambung ke sumber daya eksternal. Anggap seperti ini: layanan tertaut menentukan koneksi ke sumber data dan himpunan data mewakili struktur data. Misalnya, layanan tertaut Azure Storage menentukan connection string untuk tersambung ke akun Azure Storage. Selain itu, himpunan data blob Azure menentukan kontainer blob dan folder yang berisi data.
Layanan tertaut digunakan karena dua alasan di Data Factory:
Untuk mewakili penyimpanan data yang mencakup, tetapi tidak terbatas pada, database SQL Server, database Oracle, berbagi file, atau akun penyimpanan blob Azure. Untuk daftar penyimpanan data yang didukung, lihat artikel aktivitas salin.
Untuk mewakili sumber daya komputasi yang dapat menghosting eksekusi aktivitas. Misalnya, aktivitas HDInsightHive yang berjalan pada kluster HDInsight Hadoop. Untuk daftar aktivitas transformasi dan lingkungan komputasi yang didukung, lihat artikel data transformasi.
Integration Runtime
Di Data Factory, aktivitas menentukan tindakan yang akan dilakukan. Layanan tertaut menentukan penyimpanan data target atau layanan komputasi. Waktu proses integrasi berfungsi sebagai jembatan antara aktivitas dan layanan yang ditautkan. Ini dirujuk oleh layanan atau aktivitas tertaut, dan menyediakan lingkungan komputasi tempat aktivitas dijalankan atau dikirim. Dengan begitu, aktivitas dapat dilakukan di wilayah yang paling dekat dengan penyimpanan data target atau layanan komputasi melalui cara paling berperforma sekaligus memenuhi kebutuhan keamanan dan kepatuhan.
Pemicu
Pemicu mewakili unit pemrosesan yang menentukan kapan eksekusi pipeline harus dimulai. Ada berbagai jenis pemicu untuk berbagai jenis peristiwa.
Eksekusi alur
Sebuah run alur adalah sebuah instans dari eksekusi alur. Jalannya pipeline biasanya diinisiasi dengan meneruskan argumen ke parameter yang ditentukan dalam pipeline. Argumen dapat dilewatkan secara manual atau dalam definisi pemicu.
Parameters
Parameter adalah pasangan kunci-nilai dari konfigurasi baca-saja. Parameter-parameter didefinisikan dalam alur kerja. Argumen untuk parameter yang ditentukan diteruskan selama eksekusi dari konteks proses yang dibuat oleh pemicu atau alur yang dijalankan secara manual. Aktivitas dalam alur mengonsumsi nilai parameter.
Himpunan data adalah parameter yang bertipe kuat dan entitas yang dapat digunakan kembali serta dapat direferensikan. Aktivitas dapat mereferensikan himpunan data dan dapat menggunakan properti yang ditentukan dalam definisi himpunan data.
Layanan tertaut juga merupakan parameter yang diketik dengan kuat yang berisi informasi koneksi ke penyimpanan data atau lingkungan komputasi. Ini juga merupakan entitas yang dapat digunakan kembali/dapat direferensikan.
Alur kontrol
Alur kontrol aliran adalah orkestrasi aktivitas dalam alur pemrosesan yang mencakup perangkaian aktivitas secara berurutan, percabangan, penentuan parameter pada tingkat alur pemrosesan, dan penerusan argumen saat memanggil alur pemrosesan sesuai permintaan atau dari pemicu. Ini juga mencakup pemrosesan status kustom dan kontainer pengulangan, yaitu iterasi 'for-each'.
Variables
Variabel dapat digunakan di dalam pipa data untuk menyimpan nilai sementara dan juga dapat digunakan bersama dengan parameter untuk memungkinkan meneruskan nilai antara pipa data, aliran data, dan aktivitas lainnya.
Konten terkait
Berikut adalah dokumen langkah penting berikutnya untuk dijelajahi: