Catatan
Artikel ini bergantung pada pustaka sumber terbuka yang dihosting di GitHub di: https://github.com/mspnp/spark-monitoring.
Pustaka asli mendukung Azure Databricks Runtimes 10.x (Spark 3.2.x) dan yang lebih lama.
Databricks telah berkontribusi versi yang diperbarui untuk mendukung Azure Databricks Runtimes 11.0 (Spark 3.3.x) ke atas pada l4jv2 cabang di: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Harap dicatat bahwa rilis 11.0 tidak kompatibel mundur karena sistem pengelogan yang berbeda yang digunakan dalam Databricks Runtimes. Pastikan untuk menggunakan build yang benar untuk Databricks Runtime Anda. Pustaka dan repositori GitHub berada dalam mode pemeliharaan. Tidak ada rencana untuk rilis lebih lanjut, dan dukungan masalah hanya akan menjadi upaya terbaik. Untuk pertanyaan tambahan mengenai pustaka atau peta jalan untuk pemantauan dan pengelogan lingkungan Azure Databricks Anda, silakan hubungi azure-spark-monitoring-help@databricks.com.
Solusi ini menunjukkan pola dan metrik pengamatan untuk meningkatkan performa pemrosesan sistem big data yang menggunakan Azure Databricks.
Sistem

Unduh file Visio arsitektur ini.
Alur kerja
Solusinya melibatkan langkah-langkah berikut:
Server mengirimkan file GZIP besar yang dikelompokkan oleh pelanggan ke folder Sumber di Azure Data Lake Storage (ADLS).
ADLS kemudian mengirimkan file pelanggan yang berhasil diekstrak ke Azure Event Grid, yang mengubah data file pelanggan menjadi beberapa pesan.
Azure Event Grid mengirim pesan ke layanan Azure Queue Storage, yang menyimpannya dalam antrean.
Azure Queue Storage mengirimkan antrean ke platform analitik data Azure Databricks untuk diproses.
Azure Databricks membongkar dan memproses data antrean ke dalam file yang diproses yang dikirimnya kembali ke ADLS:
Jika file yang diproses valid, file tersebut masuk ke folder Pendaratan.
Jika tidak, file masuk ke pohon folder Buruk. Awalnya, file masuk ke subfolder Coba lagi, dan ADLS mencoba melakukan pemrosesan file pelanggan lagi (langkah 2). Jika sepasang upaya percobaan ulang masih mengarah ke Azure Databricks menghasilkan file tidak valid yang diproses, maka file yang diproses masuk ke subfolder Kegagalan.
Karena Azure Databricks membongkar dan memproses data pada langkah sebelumnya, Microsoft juga mengirimkan log dan metrik aplikasi ke Azure Monitor untuk penyimpanan.
Ruang kerja Azure Log Analytics menerapkan kueri Kusto pada log aplikasi dan metrik dari Azure Monitor untuk pemecahan masalah dan diagnostik mendalam.
Komponen
- Azure Data Lake Storage adalah serangkaian kemampuan yang dikhususkan untuk analitik data besar.
- Azure Event Grid memungkinkan pengembang dengan mudah membangun aplikasi dengan arsitektur berbasis peristiwa.
- Azure Queue Storage adalah layanan untuk menyimpan pesan dalam jumlah besar. Ini memungkinkan akses ke pesan dari mana saja di dunia melalui panggilan yang diautentikasi menggunakan HTTP atau HTTPS. Anda dapat menggunakan antrean untuk membuat backlog pekerjaan untuk memprosesnya secara asinkron.
- Azure Databricks adalah platform analitik data yang dioptimalkan untuk platform cloud Azure. Salah satu dari dua lingkungan yang ditawarkan Azure Databricks untuk mengembangkan aplikasi intensif data adalah Azure Databricks Workspace, mesin analitik terpadu berbasis Apache Spark untuk pemrosesan data skala besar.
- Azure Monitor mengumpulkan dan menganalisis telemetri aplikasi, seperti metrik performa dan log aktivitas.
- Azure Log Analytics adalah alat yang digunakan untuk mengedit dan menjalankan kueri log dengan data.
Detail skenario
Tim pengembangan Anda dapat menggunakan pola dan metrik yang dapat diamati untuk menemukan kemacetan dan meningkatkan kinerja sistem big data. Tim Anda harus melakukan pengujian beban aliran metrik volume tinggi pada aplikasi skala tinggi.
Skenario ini menawarkan panduan untuk penyetelan kinerja. Karena skenario menghadirkan tantangan kinerja untuk melakukan pengelogan per pelanggan, skenario ini menggunakan Azure Databricks, yang dapat memantau item ini dengan kuat:
- Metrik aplikasi kustom
- Peristiwa kueri streaming
- Pesan log aplikasi
Azure Databricks dapat mengirim data pemantauan ini ke berbagai layanan pengelogan, seperti Azure Log Analytics.
Skenario ini menguraikan penyerapan kumpulan besar data yang telah dikelompokkan menurut pelanggan dan disimpan dalam file arsip GZIP. Log terperinci tidak tersedia dari Azure Databricks di luar antarmuka pengguna Apache Spark™ real-time, sehingga tim Anda memerlukan cara untuk menyimpan semua data untuk setiap pelanggan, lalu menjadikannya tolok ukur dan membandingkan. Dengan skenario data yang besar, penting dalam menemukan kumpulan eksekutor kombinasi optimal dan ukuran mesin virtual (VM) agar mendapatkan waktu pemrosesan tercepat. Untuk skenario bisnis ini, aplikasi secara keseluruhan bergantung pada kecepatan penyerapan dan persyaratan kueri, sehingga throughput sistem tidak menurun secara tak terduga seiring dengan peningkatan volume kerja. Skenario harus menjamin bahwa sistem memenuhi perjanjian tingkat layanan (SLA) yang ditetapkan dengan pelanggan Anda.
Kemungkinan kasus penggunaan
Skenario yang dapat memperoleh manfaat dari solusi ini meliputi:
- Pemantauan kesehatan sistem.
- Pemeliharaan kinerja.
- Pemantauan penggunaan sistem sehari-hari.
- Pengamatan tren yang mungkin menyebabkan masalah di masa depan jika tidak ditangani.
Pertimbangan
Pertimbangan ini mengimplementasikan pilar Azure Well-Architected Framework, yang merupakan serangkaian tenet panduan yang dapat digunakan untuk meningkatkan kualitas beban kerja. Untuk informasi selengkapnya, lihat Microsoft Azure Well-Architected Framework.
Ingatlah poin-poin berikut ketika mempertimbangkan arsitektur ini:
Azure Databricks dapat secara otomatis mengalokasikan sumber daya komputasi yang diperlukan untuk pekerjaan besar, yang menghindari masalah yang ditemukan pada solusi lain. Misalnya, dengan penskalaan otomatis yang dioptimalkan untuk databricks pada Apache Spark, penyediaan yang berlebihan dapat menyebabkan penggunaan sumber daya yang tidak optimal. Atau Anda mungkin tidak mengetahui jumlah eksekutor yang diperlukan untuk suatu pekerjaan.
Pesan antrean di Azure Queue Storage dapat berukuran hingga 64 KB. Antrean mungkin berisi jutaan pesan antrean, hingga batas kapasitas total akun penyimpanan.
Pengoptimalan biaya
Optimalisasi biaya adalah tentang mencari cara untuk mengurangi pengeluaran yang tidak perlu dan meningkatkan efisiensi operasional. Untuk informasi selengkapnya, lihat Gambaran umum pilar pengoptimalan biaya.
Gunakan kalkulator harga Azure untuk memperkirakan biaya penerapan solusi ini.
Menyebarkan skenario ini
Catatan
Langkah-langkah penyebaran yang dijelaskan di sini hanya berlaku untuk Azure Databricks, Azure Monitor, dan Azure Log Analytics. Penyebaran komponen lain tidak tercakup dalam artikel ini.
Untuk mendapatkan semua log dan informasi proses, siapkan Azure Log Analytics dan pustaka pemantauan Azure Databricks. Pustaka pemantauan mengalirkan peristiwa tingkat Apache Spark dan metrik Spark Structured Streaming dari pekerjaan Anda ke Azure Monitor. Anda tidak perlu melakukan perubahan pada kode aplikasi Anda untuk peristiwa dan metrik ini.
Langkah-langkah untuk mengatur penyetelan kinerja untuk sistem big data adalah sebagai berikut:
Di portal Azure, buat ruang kerja Azure Databricks. Salin dan simpan ID langganan Azure (GUID), nama grup sumber daya, nama ruang kerja Databricks, dan URL portal ruang kerja untuk digunakan nanti.
Di browser web, buka URL ruang kerja Databricks dan buat token akses pribadi Databricks. Salin dan simpan string token yang muncul (yang dimulai dengan
dapidan nilai heksadesimal 32 karakter) untuk digunakan nanti.Kloning repositori GitHub mspnp/spark-monitoring ke komputer lokal Anda. Repositori ini memiliki kode sumber untuk komponen berikut:
- Templat Azure Resource Manager (ARM) untuk membuat ruang kerja Azure Log Analytics, yang juga memasang kueri bawaan untuk mengumpulkan metrik Spark
- Pustaka pemantauan Azure Databricks
- Aplikasi sampel untuk mengirim metrik aplikasi dan log aplikasi dari Azure Databricks ke Azure Monitor
Menggunakan perintah Azure CLI untuk menerapkan templat ARM, buat ruang kerja Azure Log Analytics dengan kueri metrik Spark bawaan. Dari output perintah, salin dan simpan nama yang dihasilkan untuk ruang kerja Log Analytics baru (dalam format spark-monitoring-<randomized-string>).
Di portal Azure, salin dan simpan ID dan kunci ruang kerja Log Analytics Anda untuk digunakan nanti.
Pasang Community Edition IntelliJ IDEA, lingkungan pengembangan terintegrasi (IDE) yang memiliki dukungan bawaan untuk Java Development Kit (JDK) dan Apache Maven. Tambahkan plug-in Scala.
Dengan menggunakan IntelliJ IDEA, buat pustaka pemantauan Azure Databricks. Untuk melakukan langkah build yang sebenarnya, pilih Tampilkan>Jendela Alat>Maven untuk menampilkan jendela alat Maven, lalu pilih Jalankan paket Maven Goal>mvn.
Dengan menggunakan alat instalasi paket Python, pasang Azure Databricks CLI dan siapkan autentikasi dengan token akses pribadi Databricks yang Anda salin sebelumnya.
Konfigurasikan ruang kerja Azure Databricks dengan memodifikasi skrip init Databricks dengan nilai Databricks dan Log Analytics yang Anda salin sebelumnya, lalu gunakan Azure Databricks CLI untuk menyalin skrip init dan pustaka pemantauan Azure Databricks ke ruang kerja Databricks Anda.
Di portal ruang kerja Databricks Anda, buat dan konfigurasikan kluster Azure Databricks.
Di IntelliJ IDEA, buat aplikasi sampel menggunakan Maven. Kemudian di portal ruang kerja Databricks Anda, jalankan aplikasi sampel untuk menghasilkan log sampel dan metrik untuk Azure Monitor.
Saat pekerjaan sampel berjalan di Azure Databricks, buka portal Azure untuk melihat dan mengkueri jenis peristiwa (log aplikasi dan metrik) di antarmuka Log Analytics:
- Pilih Tabel>Log Kustom untuk melihat skema tabel untuk peristiwa listener Spark (SparkListenerEvent_CL), peristiwa logging Spark (SparkLoggingEvent_CL), dan metrik Spark (SparkMetric_CL).
- Pilih Penjelajah kueri>Kueri Tersimpan>Metrik Spark untuk melihat dan menjalankan kueri yang ditambahkan saat Anda membuat ruang kerja Log Analytics.
Baca selengkapnya tentang menampilkan dan menjalankan kueri bawaan dan kustom di bagian berikutnya.
Kuerikan log dan metrik di Azure Log Analytics
Mengakses kueri bawaan
Nama kueri bawaan untuk mengambil metrik Spark tercantum di bawah ini.
- % Waktu CPU Per Eksekutor
- % Waktu Deserialisasi Per Eksekutor
- % Waktu JVM Per Eksekutor
- % Waktu Serialisasi Per Eksekutor
- Byte Disk Meluap
- Jejak Kesalahan (Catatan Buruk Atau File Buruk)
- Byte Sistem File Dibaca Per Eksekutor
- Penulisan Byte Sistem File Per Eksekutor
- Kesalahan Pekerjaan Per Pekerjaan
- Latensi Pekerjaan Per Pekerjaan (Durasi Batch)
- Throughput Pekerjaan
- Eksekutor Berjalan
- Byte Acak Dibaca
- Byte Acak Dibaca Per Eksekutor
- Byte Acak Dibaca ke Disk Per Eksekutor
- Memori Langsung Klien Acak
- Memori Klien Acak Per Eksekutor
- Byte Disk Acak Meluap Per Eksekutor
- Memori Menumpuk Acak Per Eksekutor
- Byte Memori Acak Meluap Per Eksekutor
- Latensi Tahap Per Tahap (Durasi Tahap)
- Throughput Tahap Per Tahap
- Kesalahan Streaming Per Streaming
- Latensi Streaming Per Streaming
- Baris/Detik Input Throughput Streaming
- Baris/Detik Throughput Streaming Diproses
- Jumlah Eksekusi Tugas Per Host
- Waktu Deserialisasi Tugas
- Kesalahan Tugas Per Tahap
- Waktu Komputasi Eksekutor Tugas (Waktu Condong Data)
- Byte Input Tugas Dibaca
- Latensi Tugas Per Tahap (Durasi Tugas)
- Waktu Serialisasi Hasil Tugas
- Latensi Penundaan Penjadwal Tugas
- Byte Acak Tugas Dibaca
- Byte Acak Tugas Ditulis
- Waktu Baca Pengacak Tugas
- Waktu Tulis Pengacak Tugas
- Throughput Tugas (Jumlah Tugas Per Tahap)
- Tugas Per Eksekutor (Jumlah Tugas Per Eksekutor)
- Tugas Per Tahap
Menulis kueri kustom
Anda juga dapat menulis kueri Anda sendiri di Kusto Query Language (KQL). Cukup pilih panel tengah atas, yang dapat diedit, dan sesuaikan kueri dengan kebutuhan Anda.
Dua kueri berikut menarik data dari peristiwa pengelogan Spark:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Dan kedua contoh ini adalah kueri pada log metrik Spark:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Terminologi kueri
Tabel berikut menjelaskan beberapa istilah yang digunakan saat Anda membuat kueri log aplikasi dan metrik.
| Term | ID | Keterangan |
|---|---|---|
| Cluster_init | ID aplikasi | |
| Antrean | ID Eksekusi | Satu ID yang dijalankan setara dengan beberapa batch. |
| Batch | ID batch | Satu batch setara dengan dua pekerjaan. |
| Tugas | ID Pekerjaan | Satu pekerjaan setara dengan dua tahap. |
| Tahap | ID Tahap | Satu tahap memiliki ID tugas 100-200 tergantung pada tugas (baca, acak, atau tulis). |
| Tugas | ID Tugas | Satu tugas ditetapkan untuk satu eksekutor. Satu tugas ditetapkan untuk melakukan partitionBy untuk satu partisi. Untuk sekitar 200 pelanggan, harus ada 200 tugas. |
Bagian berikut berisi metrik khas yang digunakan dalam skenario ini untuk memantau throughput sistem, status operasi pekerjaan Spark, dan penggunaan sumber daya sistem.
Throughput sistem
| Nama | Pengukuran | Unit-unit |
|---|---|---|
| Throughput aliran | Tingkat input rata-rata di atas tingkat peroses rata-rata per menit | Baris per menit |
| Durasi pekerjaan | Rata-rata durasi pekerjaan Spark yang berakhir per menit | Durasi per menit |
| Jumlah pekerjaan | Jumlah rata-rata pekerjaan Spark yang berakhir per menit | Jumlah pekerjaan per menit |
| Durasi tahap | Rata-rata durasi tahapan yang diselesaikan per menit | Durasi per menit |
| Jumlah tahap | Jumlah rata-rata tahapan yang diselesaikan per menit | Jumlah tahapan per menit |
| Durasi tugas | Rata-rata durasi tugas selesai per menit | Durasi per menit |
| Jumlah tugas | Jumlah rata-rata tugas yang selesai per menit | Jumlah tugas per menit |
Status menjalankan pekerjaan Spark
| Nama | Pengukuran | Unit-unit |
|---|---|---|
| Jumlah kumpulan penjadwal | Jumlah kumpulan penjadwal yang berbeda per menit (jumlah kueri yang beroperasi) | Jumlah kolam penjadwal |
| Jumlah eksekutor yang berjalan | Jumlah eksekutor yang berjalan per menit | Jumlah eksekutor yang berjalan |
| Jejak kesalahan | Semua log kesalahan dengan tingkat Error dan tugas/tahapan yang sesuai (ditampilkan di thread_name_s) |
Penggunaan sumber daya sistem
| Nama | Pengukuran | Unit-unit |
|---|---|---|
| Penggunaan CPU rata-rata per eksekutor/keseluruhan | Persentase CPU yang digunakan per eksekutor per menit | % per menit |
| Rata-rata memori langsung (MB) digunakan per host | Rata-rata memori langsung digunakan per eksekutor per menit | MB per menit |
| Memori meluap per host | Rata-rata memori meluap per eksekutor | MB per menit |
| Memantau dampak condong data pada durasi | Ukuran rentang dan perbedaan persentil ke-70-90 dan persentil ke-90-100 dalam durasi tugas | Selisih bersih antara 100%, 90%, dan 70%; perbedaan persentase antara 100%, 90%, dan 70% |
Putuskan cara menghubungkan input pelanggan, yang digabungkan ke dalam file arsip GZIP, ke file output Azure Databricks tertentu, karena Azure Databricks menangani seluruh operasi batch sebagai sebuah unit. Di sini, Anda menerapkan granularitas untuk pelacakan. Anda juga menggunakan metrik kustom untuk melacak satu file output ke file input asli.
Untuk definisi lebih rinci dari setiap metrik, lihat Visualisasi di dasbor di situs web ini, atau lihat bagian Metrik di dokumentasi Apache Spark.
Menilai opsi penyetelan kinerja
Definisi dasar
Anda dan tim pengembangan Anda harus menetapkan garis besar, sehingga Anda dapat membandingkan keadaan aplikasi di masa depan.
Ukur kinerja aplikasi Anda secara kuantitatif. Dalam skenario ini, metrik utama adalah latensi kerja, yang merupakan hal biasa dari sebagian besar pra pemprosesan dan konsumsi data. Cobalah untuk mempercepat waktu pemrosesan data dan fokus pada pengukuran latensi, seperti pada bagan di bawah ini:

Ukur latensi eksekusi untuk pekerjaan: pandangan kasar tentang kinerja pekerjaan secara keseluruhan, dan durasi eksekusi pekerjaan dari awal hingga selesai (waktu microbatch). Pada grafik di atas, pada tanda 19:30, dibutuhkan waktu sekitar 40 detik untuk memproses pekerjaan.
Jika Anda melihat lebih jauh ke dalam 40 detik tersebut, Anda akan melihat data di bawah ini untuk tahapan:
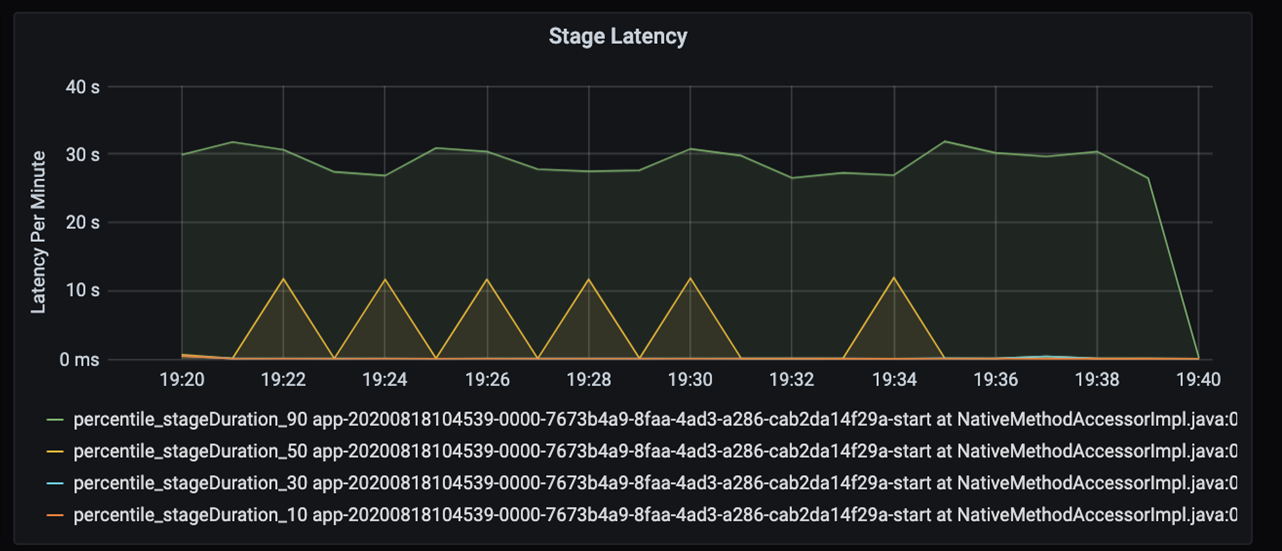
Pada tanda 19:30, ada dua tahap: tahap oranye 10 detik, dan tahap hijau pada 30 detik. Pantau apakah ada lonjakan tahap, karena lonjakan menunjukkan penundaan dalam suatu tahap.
Selidiki kapan tahap tertentu berjalan lambat. Dalam skenario partisi, biasanya ada setidaknya dua tahap: satu tahap untuk membaca file, dan tahap lainnya untuk mengacak, partisi, dan menulis file. Jika Anda mengalami latensi tahap tinggi di sebagian besar tahap penulisan, Anda mungkin mengalami masalah penyempitan selama partisi.

Amati tugas sebagai tahapan dalam pekerjaan yang dijalankan secara berurutan, dengan tahap awal memblokir tahap selanjutnya. Dalam satu tahap, jika satu tugas menjalankan partisi acak lebih lambat dari tugas lain, semua tugas dalam kluster harus menunggu tugas yang lebih lambat selesai untuk menyelesaikannya. Tugas kemudian merupakan cara untuk memantau kecondongan data dan kemungkinan penyempitan. Pada bagan di atas, Anda dapat melihat bahwa semua tugas didistribusikan secara merata.
Sekarang pantau waktu pemrosesan. Karena Anda memiliki skenario streaming, lihat throughput streaming.
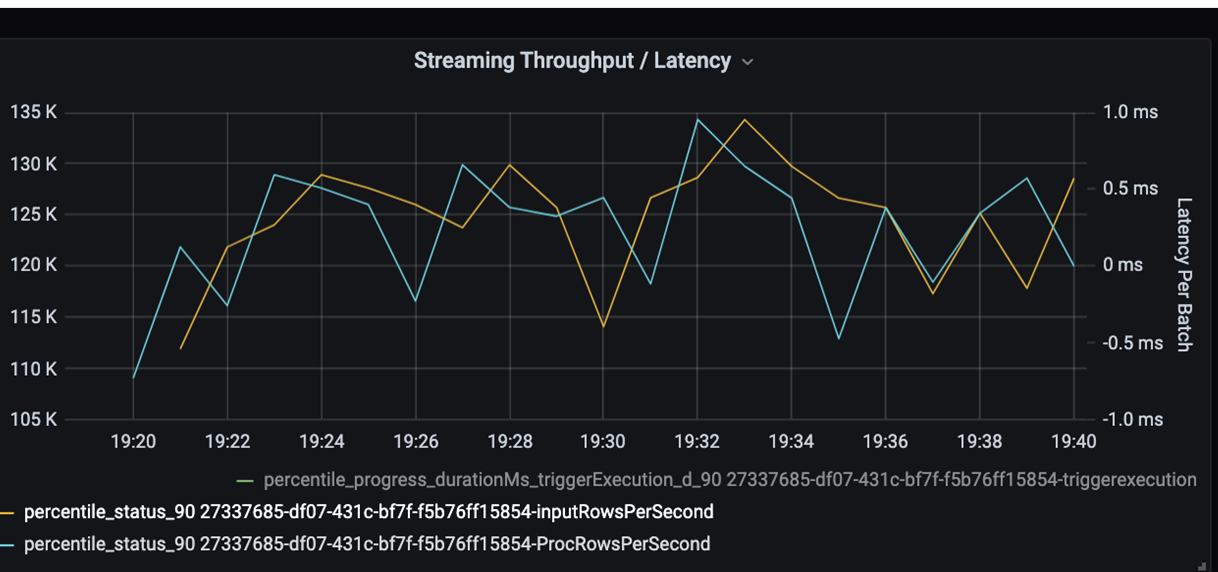
Dalam bagan latensi throughput/batch streaming di atas, garis oranye mewakili laju input (baris input per detik). Garis biru mewakili tingkat pemrosesan (baris pemrosesan per detik). Pada beberapa titik, tingkat pemrosesan tidak menangkap tingkat input. Masalah potensialnya adalah bahwa file input menumpuk dalam antrian.
Karena laju pemrosesan tidak cocok dengan laju input dalam grafik, coba tingkatkan laju proses untuk menutupi laju input sepenuhnya. Salah satu alasan yang mungkin adalah ketidakseimbangan data pelanggan di setiap kunci partisi yang menyebabkan penyempitan. Untuk langkah selanjutnya dan solusi potensial, manfaatkan skalabilitas Azure Databricks.
Investigasi partisi
Pertama, identifikasi lebih lanjut jumlah pelaksana penskalaan yang Anda perlukan dengan Azure Databricks. Terapkan aturan praktis menetapkan setiap partisi dengan CPU khusus dalam menjalankan eksekutor. Misalnya, jika Anda memiliki 200 kunci partisi, jumlah CPU dikalikan dengan jumlah eksekutor harus sama dengan 200. (Misalnya, delapan CPU yang dikombinasikan dengan 25 eksekutor akan cocok.) Dengan 200 kunci partisi, setiap pelaksana hanya dapat bekerja pada satu tugas, yang mengurangi kemungkinan penyempitan.
Karena beberapa partisi lambat ada dalam skenario ini, selidiki varians tinggi dalam durasi tugas. Periksa setiap lonjakan durasi tugas. Satu tugas menangani satu partisi. Jika tugas membutuhkan lebih banyak waktu, partisi mungkin terlalu besar dan menyebabkan penyempitan.

Penelusuran kesalahan
Tambahkan dasbor untuk pelacakan kesalahan sehingga Anda dapat menemukan kegagalan data khusus pelanggan. Dalam pra pemrosesan data, ada kalanya file rusak, dan rekaman dalam file tidak cocok dengan skema data. Dasbor berikut menangkap banyak file buruk dan catatan buruk.
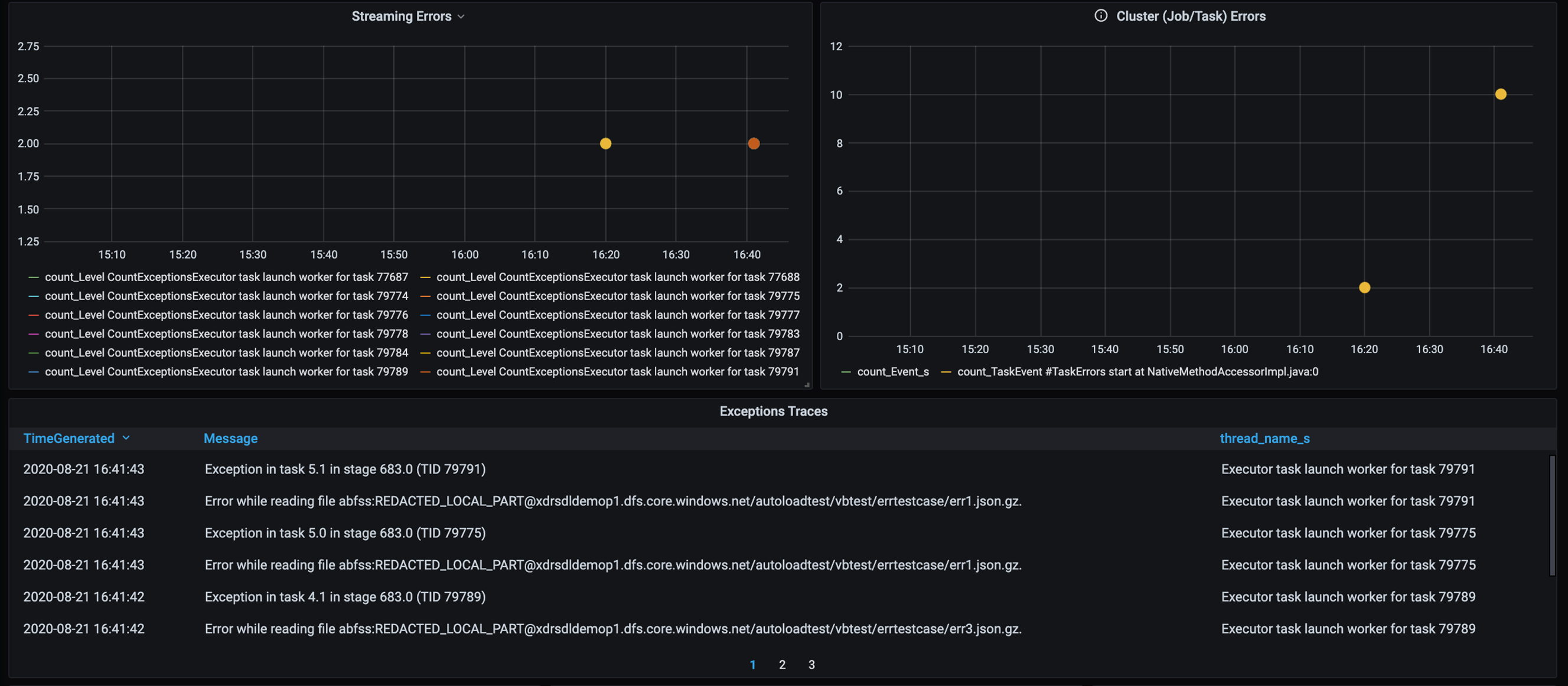
Dasbor ini menampilkan jumlah kesalahan, pesan kesalahan, dan ID tugas untuk debugging. Dalam pesan, Anda dapat dengan mudah melacak kesalahan kembali ke file kesalahan. Ada beberapa file yang mengalami kesalahan saat membaca. Anda meninjau garis waktu teratas dan menyelidiki pada titik-titik tertentu dalam grafik kami (16:20 dan 16:40).
Penyempitan lainnya
Untuk contoh dan panduan selengkapnya, lihat Memecahkan masalah hambatan kinerja di Azure Databricks.
Ringkasan penilaian penyetelan kinerja
Untuk skenario ini, metrik ini mengidentifikasi pengamatan berikut:
- Dalam bagan latensi tahap, tahap penulisan memakan waktu pemrosesan paling banyak.
- Dalam bagan latensi tugas, latensi tugas stabil.
- Dalam bagan throughput streaming, tingkat output lebih rendah dari tingkat input di beberapa titik.
- Dalam tabel durasi tugas, ada perbedaan tugas karena ketidakseimbangan data pelanggan.
- Untuk mendapatkan kinerja yang dioptimalkan dalam tahap partisi, jumlah eksekutor penskalaan harus sesuai dengan jumlah partisi.
- Ada kesalahan pelacakan, seperti file buruk dan catatan buruk.
Untuk mendiagnosis masalah ini, Anda menggunakan metrik berikut:
- Latensi pekerjaan
- Latensi Tahap
- Latensi Tugas
- Throughput streaming
- Durasi tugas (maks, rata-rata, menit) per tahap
- Jejak kesalahan (hitungan, pesan, ID tugas)
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- David McGhee | Manajer Program Utama
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.
Langkah berikutnya
- Baca tutorial Log Analytics.
- Memantau Azure Databricks di ruang kerja Azure Log Analytics
- Penyebaran Azure Log Analytics dengan metrik Spark
- Pola yang dapat diamati