Contoh arsitektur ini didasarkan pada arsitektur contoh aplikasi web Dasar dan memperluasnya untuk ditampilkan:
- Praktik yang terbukti untuk meningkatkan skalabilitas dan performa dalam aplikasi web Azure App Service
- Cara menjalankan aplikasi Azure App Service di beberapa wilayah untuk mencapai ketersediaan tinggi
Sistem
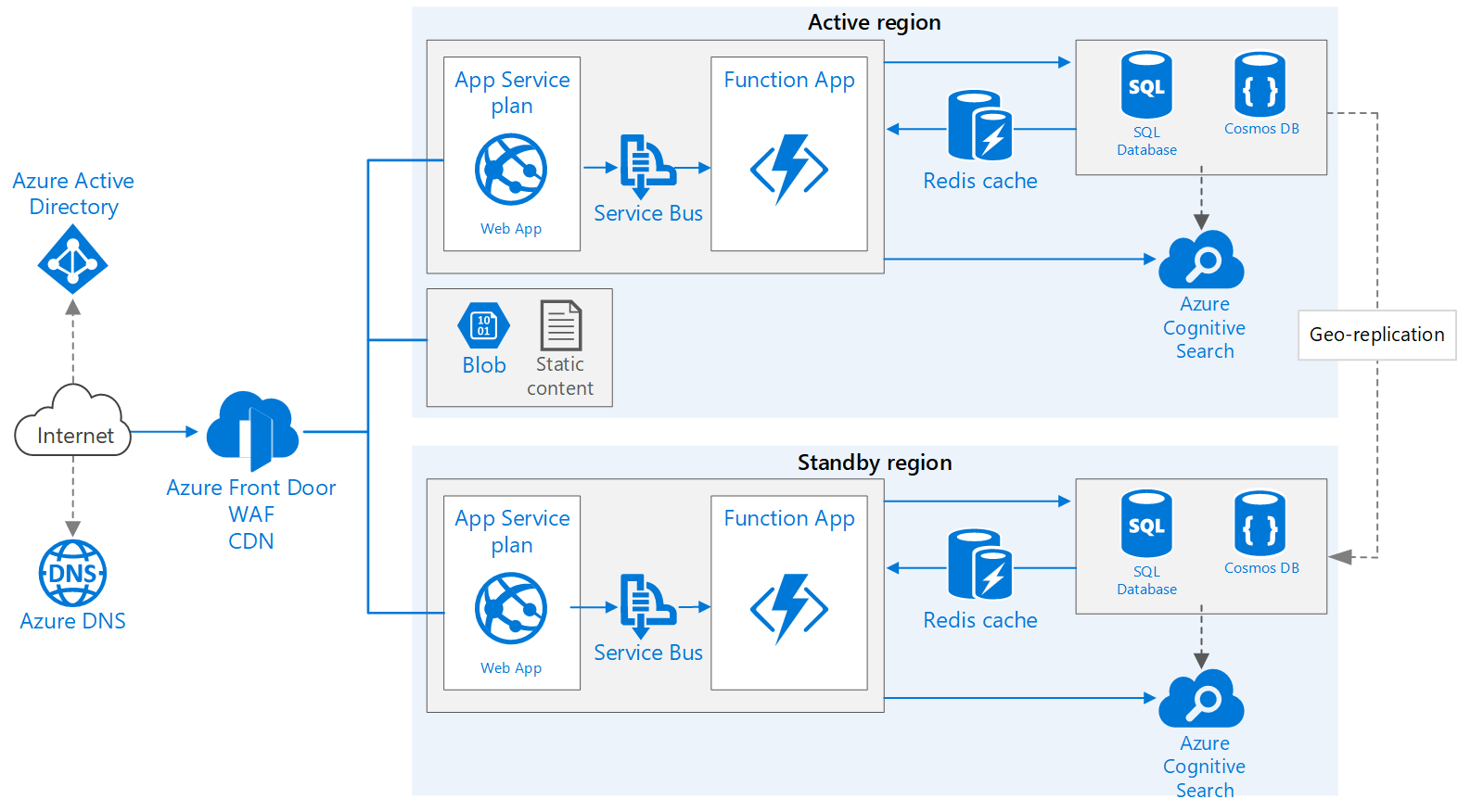
Unduh file Visio arsitektur ini.
Alur kerja
Alur kerja ini membahas aspek multi-wilayah arsitektur dan dibangun di atas aplikasi web Dasar.
- Wilayah primer dan sekunder. Arsitektur ini menggunakan dua wilayah untuk mencapai ketersediaan yang lebih tinggi. Aplikasi ini disebarkan ke setiap wilayah. Selama operasi normal, lalu lintas jaringan diarahkan ke wilayah utama. Jika wilayah utama menjadi tidak tersedia, lalu lintas diarahkan ke wilayah sekunder.
- Front Door. Azure Front Door adalah load balancer yang direkomendasikan untuk implementasi multi-wilayah. Ini terintegrasi dengan firewall aplikasi web (WAF) untuk melindungi dari eksploitasi umum dan menggunakan fungsionalitas penembolokan konten asli Front Door. Dalam arsitektur ini, Front Door dikonfigurasi untuk perutean prioritas , yang mengirim semua lalu lintas ke wilayah utama kecuali menjadi tidak tersedia. Jika wilayah utama menjadi tidak tersedia, Front Door merutekan semua lalu lintas ke wilayah sekunder.
- Replikasi geografis Akun Penyimpanan, SQL Database, dan/atau Azure Cosmos DB.
Catatan
Untuk gambaran umum terperinci tentang penggunaan Azure Front Door untuk arsitektur multi-wilayah, termasuk dalam konfigurasi yang diamankan jaringan, silakan lihat Implementasi ingress aman jaringan.
Komponen
Teknologi utama yang digunakan untuk mengimplementasikan arsitektur ini:
- MICROSOFT Entra ID adalah layanan manajemen identitas dan akses berbasis cloud yang memungkinkan karyawan mengakses aplikasi cloud yang dikembangkan untuk organisasi Anda.
- Azure DNS adalah layanan hosting untuk domain DNS, yang menyediakan resolusi nama menggunakan infrastruktur Microsoft Azure. Dengan menghosting domain Anda di Azure, Anda bisa mengelola catatan DNS Anda menggunakan kredensial, API, alat, dan tagihan yang sama dengan layanan Azure lainnya. Untuk menggunakan nama domain kustom (seperti
contoso.com), buat rekaman DNS yang memetakan nama domain kustom ke alamat IP. Untuk informasi selengkapnya, lihat Mengonfigurasi nama domain kustom di Azure App Service. - Azure Content Delivery Network adalah solusi global untuk mengirimkan konten bandwidth tinggi dengan menyimpannya di simpul fisik yang ditempatkan secara strategis di seluruh dunia.
- Azure Front Door adalah load balancer lapisan 7. Dalam arsitektur ini, penyeimbang beban ini merutekan permintaan HTTP ke front end web. Front Door juga menyediakan web application firewall (WAF) yang melindungi aplikasi dari eksploitasi dan kerentanan umum. Front Door juga digunakan untuk solusi Content Delivery Network (CDN) dalam desain ini.
- Azure AppService adalah platform yang dikelola sepenuhnya untuk membuat dan menyebarkan aplikasi cloud. Ini memungkinkan Anda menentukan sekumpulan sumber daya komputasi untuk aplikasi web yang akan dijalankan, menyebarkan aplikasi web, dan mengonfigurasi slot penyebaran.
- Azure Function Apps dapat digunakan untuk menjalankan tugas latar belakang. Fungsi dipanggil oleh pemicu, seperti peristiwa pengatur waktu atau pesan yang ditempatkan pada antrean. Untuk tugas stateful yang berjalan lama, gunakan Fungsi Tahan Lama.
- Azure Storage adalah solusi penyimpanan cloud untuk skenario penyimpanan data modern, menawarkan penyimpanan yang sangat tersedia, dapat diskalakan secara besar-besaran, tahan lama, dan aman untuk berbagai objek data di cloud.
- Azure Redis Cache adalah layanan penembolokan berperforma tinggi yang menyediakan penyimpanan data dalam memori untuk pengambilan data yang lebih cepat, berdasarkan cache Redis implementasi sumber terbuka.
- Azure SQL Database adalah database relasional sebagai layanan di cloud. SQL Database berbagi basis kodenya dengan mesin database Microsoft SQL Server.
- Azure Cosmos DB adalah database API multi-model, latensi rendah, latensi rendah, multi-model yang didistribusikan secara global untuk mengelola data dalam skala besar.
- Azure Cognitive Search dapat digunakan untuk menambahkan fungsionalitas pencarian seperti saran pencarian, pencarian fuzzy, dan pencarian khusus bahasa. Pencarian Azure biasanya digunakan bersama dengan penyimpanan data lain, terutama jika penyimpanan data utama memerlukan konsistensi yang ketat. Dalam pendekatan ini, simpan data otoritatif di penyimpanan data lain dan indeks pencarian di Azure Search. Azure Search juga dapat digunakan untuk mengkonsolidasikan indeks pencarian tunggal dari beberapa penyimpanan data.
Detail skenario
Ada beberapa pendekatan umum untuk mencapai ketersediaan tinggi di seluruh wilayah:
Aktif/Pasif dengan siaga panas: lalu lintas menuju satu wilayah, sementara yang lain menunggu dalam siaga panas. Siaga panas berarti App Service di wilayah sekunder dialokasikan dan selalu berjalan.
Aktif/Pasif dengan siaga dingin: lalu lintas menuju satu wilayah, sementara yang lain menunggu dalam siaga dingin. Siaga dingin berarti App Service di wilayah sekunder tidak dialokasikan sampai diperlukan untuk failover. Pendekatan ini membutuhkan biaya lebih sedikit untuk dijalankan, tetapi umumnya akan memakan waktu lebih lama untuk online saat terjadi kegagalan.
Aktif/Aktif: kedua wilayah aktif, dan permintaan seimbang antara keduanya. Jika satu wilayah menjadi tidak tersedia, wilayah tersebut diambil dari rotasi.
Referensi ini berfokus pada aktif/pasif dengan siaga panas.
Kemungkinan kasus penggunaan
Kasus penggunaan ini dapat mengambil manfaat dari penerapan multi-wilayah:
Rancang rencana kelangsungan bisnis dan pemulihan bencana untuk aplikasi LoB.
Menyebarkan aplikasi misi penting yang berjalan di Windows atau Linux.
Tingkatkan pengalaman pengguna dengan menjaga aplikasi tetap tersedia.
Rekomendasi
Persyaratan Anda mungkin berbeda dari arsitektur yang dijelaskan di sini. Gunakan rekomendasi di bagian ini sebagai titik awal.
Pasangan regional
Setiap wilayah Azure dipasangkan dengan wilayah lain dalam geografi yang sama. Secara umum, pilih wilayah dari pasangan wilayah yang sama (misalnya, AS Timur 2 dan AS Tengah). Manfaat melakukannya meliputi:
- Jika ada pemadaman yang luas, pemulihan setidaknya satu wilayah dari setiap pasangan diprioritaskan.
- Pembaruan sistem Azure yang direncanakan diluncurkan ke wilayah yang dipasangkan secara berurutan untuk meminimalkan kemungkinan waktu henti.
- Dalam kebanyakan kasus, pasangan wilayah berada dalam geografi yang sama untuk memenuhi persyaratan residensi data.
Namun, pastikan kedua wilayah mendukung semua layanan Azure yang diperlukan untuk aplikasi Anda. Lihat Layanan menurut wilayah. Untuk informasi selengkapnya tentang pasangan regional, lihat Kelangsungan bisnis dan pemulihan bencana (BCDR): Azure Paired Regions.
Kelompok Sumber Daya
Pertimbangkan untuk menempatkan wilayah utama, wilayah sekunder, dan Front Door ke dalam grup sumber daya terpisah. Alokasi ini memungkinkan Anda mengelola sumber daya yang disebarkan ke setiap wilayah sebagai satu koleksi.
Aplikasi App Service
Sebaiknya buat aplikasi web dan API web sebagai aplikasi App Service yang terpisah. Desain ini memungkinkan Anda menjalankannya dalam paket App Service terpisah sehingga dapat diskalakan secara independen. Jika Anda tidak memerlukan tingkat skalabilitas itu pada awalnya, Anda dapat menerapkan aplikasi ke dalam paket yang sama dan memindahkannya ke paket terpisah nanti jika perlu.
Catatan
Untuk paket Dasar, Standar, Premium, dan Terisolasi, Anda akan ditagih untuk instans VM dalam paket, bukan per aplikasi. Lihat Harga App Service
Konfigurasi Front Door
Perutean. Front Door mendukung beberapa mekanisme perutean. Untuk skenario yang dijelaskan dalam artikel ini, gunakan perutean prioritas. Dengan pengaturan ini, Front Door mengirimkan semua permintaan ke wilayah utama kecuali titik akhir untuk wilayah tersebut menjadi tidak terjangkau. Pada saat itu, Traffic Manager akan secara otomatis melakukan failover ke wilayah sekunder. Atur kumpulan asal dengan nilai prioritas yang berbeda, 1 untuk wilayah aktif dan 2 atau lebih tinggi untuk wilayah siaga atau pasif.
Pemeriksaan kesehatan. Front Door menggunakan pemeriksaan HTTPS untuk memantau ketersediaan setiap back end. Probe memberikan Front Door tes lulus/gagal karena gagal ke wilayah sekunder. Ini bekerja dengan mengirimkan permintaan ke jalur URL yang ditentukan. Jika mendapat respons non-200 dalam periode waktu habis, probe gagal. Anda dapat mengonfigurasi frekuensi pemeriksaan kesehatan, jumlah sampel yang diperlukan untuk evaluasi, dan jumlah sampel yang berhasil yang diperlukan agar asal ditandai sebagai sehat. Jika Front Door menandai asal sebagai terdegradasi, itu gagal ke asal lainnya. Untuk detailnya, lihat Probe Kesehatan.
Sebagai praktik terbaik, buat jalur pemeriksaan kesehatan di asal aplikasi Anda yang melaporkan kesehatan aplikasi secara keseluruhan. Pemeriksaan kesehatan ini harus memeriksa dependensi penting seperti aplikasi App Service, antrean penyimpanan, dan Database SQL. Jika tidak, pemeriksaan mungkin melaporkan asal yang sehat ketika bagian penting dari aplikasi benar-benar gagal. Di sisi lain, jangan gunakan pemeriksaan kesehatan untuk memeriksa layanan dengan prioritas lebih rendah. Misalnya, jika layanan email mati, aplikasi dapat beralih ke penyedia kedua atau hanya mengirim email nanti. Untuk diskusi selengkapnya tentang pola desain ini, lihat Pola Pemantauan Titik Akhir Kesehatan.
Mengamankan asal-usul dari internet adalah bagian penting dari penerapan aplikasi yang dapat diakses publik. Lihat implementasi ingress aman Jaringan untuk mempelajari tentang desain dan pola implementasi microsoft yang direkomendasikan untuk mengamankan komunikasi masuk aplikasi Anda dengan Front Door.
CDN. Gunakan fungsionalitas CDN asli Front Door untuk menyimpan konten statis. Manfaat utama CDN adalah mengurangi latensi bagi pengguna, karena konten di-cache di server tepi yang secara geografis dekat dengan pengguna. CDN juga dapat mengurangi beban pada aplikasi, karena lalu lintas tersebut tidak ditangani oleh aplikasi. Front Door juga menawarkan akselerasi situs dinamis yang memungkinkan Anda memberikan pengalaman pengguna secara keseluruhan yang lebih baik untuk aplikasi web Anda daripada yang akan tersedia hanya dengan penembolokan konten statis.
Catatan
CDN Front Door tidak dirancang untuk menyajikan konten yang memerlukan autentikasi.
SQL Database
Gunakan Replikasi geografis aktif dan grup failover otomatis untuk membuat database Anda tangguh. Replikasi geografis aktif memungkinkan Anda mereplikasi database Anda dari wilayah utama ke satu atau beberapa (hingga empat) wilayah lain. Grup failover otomatis dibangun di atas replikasi geografis aktif dengan memungkinkan Anda melakukan failover ke database sekunder tanpa perubahan kode apa pun pada aplikasi Anda. Failover dapat dilakukan secara manual atau otomatis, sesuai dengan definisi kebijakan yang Anda buat. Untuk menggunakan grup failover otomatis, Anda harus mengonfigurasi string koneksi dengan failover string koneksi dibuat secara otomatis untuk grup failover, bukan string koneksi database individual.
Azure Cosmos DB
Azure Cosmos DB mendukung replikasi geografis di seluruh wilayah dalam pola aktif-aktif dengan beberapa wilayah tulis. Atau, Anda dapat menetapkan satu wilayah sebagai wilayah yang dapat ditulis dan yang lainnya sebagai replika hanya-baca. Jika ada pemadaman regional, Anda dapat melakukan failover dengan memilih wilayah lain untuk menjadi wilayah tulis. SDK klien secara otomatis mengirimkan permintaan tulis ke wilayah penulisan saat ini, jadi Anda tidak perlu memperbarui konfigurasi klien setelah failover. Untuk informasi selengkapnya, lihat Distribusi data global dengan Azure Cosmos DB.
Penyimpanan
Untuk Penyimpanan Azure, gunakan penyimpanan geo-redundan akses baca (RA-GRS). Dengan penyimpanan RA-GRS, data direplikasi ke wilayah sekunder. Anda memiliki akses baca-saja ke data di wilayah sekunder melalui titik akhir terpisah. Failover yang dimulai pengguna ke wilayah sekunder didukung untuk akun penyimpanan yang direplikasi secara geografis. Memulai failover akun penyimpanan secara otomatis memperbarui catatan DNS untuk menjadikan akun penyimpanan sekunder sebagai akun penyimpanan utama baru. Failover hanya boleh dilakukan ketika Anda dianggap perlu. Persyaratan ini ditentukan oleh rencana pemulihan bencana organisasi Anda, dan Anda harus mempertimbangkan implikasi seperti yang dijelaskan di bagian Pertimbangan di bawah ini.
Jika ada pemadaman regional atau bencana, tim Azure Storage mungkin memutuskan untuk melakukan geo-failover ke wilayah sekunder. Untuk jenis failover ini, tidak ada tindakan pelanggan yang diperlukan. Failback ke wilayah utama juga dikelola oleh tim penyimpanan Azure dalam kasus ini.
Dalam beberapa kasus , replikasi objek untuk blob blok akan menjadi solusi replikasi yang memadai untuk beban kerja Anda. Fitur replikasi ini memungkinkan Anda menyalin blob blok individual dari akun penyimpanan utama ke akun penyimpanan di wilayah sekunder Anda. Manfaat dari pendekatan ini adalah kontrol terperinci atas data apa yang sedang direplikasi. Anda dapat menentukan kebijakan replikasi untuk kontrol yang lebih terperinci dari jenis blob blok yang direplikasi. Contoh definisi kebijakan termasuk, tetapi tidak terbatas pada:
- Hanya blob blok yang ditambahkan berikutnya untuk membuat kebijakan yang direplikasi
- Hanya blob blok yang ditambahkan setelah tanggal dan waktu tertentu yang direplikasi
- Hanya blob blok yang cocok dengan awalan tertentu yang direplikasi.
Penyimpanan antrean direferensikan sebagai opsi olahpesan alternatif ke Azure Bus Layanan untuk skenario ini. Namun, jika Anda menggunakan penyimpanan antrean untuk solusi olahpesan Anda, panduan yang diberikan di atas relatif terhadap replikasi geografis berlaku di sini, karena penyimpanan antrean berada di akun penyimpanan. Namun, penting untuk dipahami bahwa pesan tidak direplikasi ke wilayah sekunder dan statusnya tidak dapat dieksplisit dari wilayah tersebut.
Azure Service Bus
Untuk mendapatkan manfaat dari ketahanan tertinggi yang ditawarkan untuk Azure Bus Layanan, gunakan tingkat premium untuk namespace Anda. Tingkat premium memanfaatkan zona ketersediaan, yang membuat namespace Anda tahan terhadap pemadaman pusat data. Jika ada bencana luas yang memengaruhi beberapa pusat data, fitur Pemulihan bencana geografis yang disertakan dengan tingkat premium dapat membantu Anda pulih. Fitur pemulihan Geo-Disaster memastikan bahwa seluruh konfigurasi namespace layanan (antrean, topik, langganan, dan filter) terus direplikasi dari namespace utama ke namespace layanan sekunder saat dipasangkan. Ini memungkinkan Anda untuk memulai perpindahan failover sekali-saja dari primer ke sekunder kapan saja. Langkah failover akan menunjuk kembali nama alias yang dipilih untuk namespace ke namespace sekunder lalu membatalkan pemasangan. Failover hampir dijalankan seketika setelah dimulai.
Azure Cognitive Search
Dalam Cognitive Search, ketersediaan dicapai melalui beberapa replika, sedangkan kelangsungan bisnis dan pemulihan bencana (BCDR) dicapai melalui beberapa layanan pencarian.
Dalam Cognitive Search, replika adalah salinan indeks Anda. Memiliki beberapa replika memungkinkan Azure Cognitive Search melakukan reboot komputer dan pemeliharaan terhadap satu replika, sementara eksekusi kueri berlanjut pada replika lain. Untuk informasi selengkapnya tentang menambahkan replika, lihat Menambah atau mengurangi replika dan partisi.
Anda dapat menggunakan Zona Ketersediaan dengan Azure Cognitive Search dengan menambahkan dua replika atau lebih ke layanan pencarian Anda. Setiap replika akan ditempatkan di Zona Ketersediaan yang berbeda di wilayah tersebut.
Untuk pertimbangan BCDR, lihat dokumentasi Beberapa layanan di wilayah geografis terpisah.
Azure Cache untuk Redis
Meskipun semua tingkatan Azure Cache for Redis menawarkan replikasi Standar untuk ketersediaan tinggi, tingkat Premium atau Enterprise disarankan untuk memberikan tingkat ketahanan dan pemulihan yang lebih tinggi. Tinjau Ketersediaan tinggi dan pemulihan bencana untuk daftar lengkap fitur dan opsi ketahanan dan pemulihan untuk tingkat ini. Persyaratan bisnis Anda akan menentukan tingkat mana yang paling cocok untuk infrastruktur Anda.
Pertimbangan
Pertimbangan ini mengimplementasikan pilar Azure Well-Architected Framework, yang merupakan serangkaian tenet panduan yang dapat digunakan untuk meningkatkan kualitas beban kerja. Untuk informasi selengkapnya, lihat Microsoft Azure Well-Architected Framework.
Keandalan
Keandalan memastikan aplikasi Anda dapat mencapai komitmen yang Anda buat kepada pelanggan Anda. Untuk informasi selengkapnya, lihat Gambaran Umum pilar keandalan. Pertimbangkan poin-poin ini saat mendesain ketersediaan tinggi di seluruh wilayah.
Azure Front Door
Azure Front Door secara otomatis gagal jika wilayah utama menjadi tidak tersedia. Ketika Front Door gagal, ada periode waktu (biasanya sekitar 20-60 detik) ketika klien tidak dapat mencapai aplikasi. Durasi dipengaruhi oleh faktor-faktor berikut:
- Frekuensi pemeriksaan kesehatan. Semakin sering pemeriksaan kesehatan dikirim, semakin cepat Front Door dapat mendeteksi waktu henti atau asal kembali sehat.
- Konfigurasi ukuran sampel. Konfigurasi ini mengontrol berapa banyak sampel yang diperlukan untuk pemeriksaan kesehatan untuk mendeteksi bahwa asal utama telah menjadi tidak dapat dijangkau. Jika nilai ini terlalu rendah, Anda bisa mendapatkan hasil positif palsu dari masalah yang terputus-putus.
Front Door adalah kemungkinan titik kegagalan dalam sistem. Jika layanan gagal, klien tidak dapat mengakses aplikasi Anda selama waktu henti. Tinjau Perjanjian tingkat layanan (SLA) Front Door dan tentukan apakah menggunakan Front Door saja memenuhi persyaratan bisnis Anda untuk ketersediaan tinggi. Jika tidak, pertimbangkan untuk menambahkan solusi manajemen lalu lintas lain sebagai cadangan. Jika layanan Front Door gagal, ubah rekaman nama kanonik (CNAME) Anda di DNS untuk menunjuk ke layanan manajemen lalu lintas lainnya. Langkah ini harus dilakukan secara manual, dan aplikasi Anda tidak akan tersedia sampai perubahan DNS disebarkan.
Tingkat Azure Front Door Standard dan Premium menggabungkan kemampuan Azure Front Door (klasik), Azure CDN Standard dari Microsoft (klasik), dan Azure WAF ke dalam satu platform. Menggunakan Azure Front Door Standard atau Premium mengurangi titik kegagalan dan memungkinkan kontrol, pemantauan, dan keamanan yang ditingkatkan. Untuk informasi selengkapnya, lihat Gambaran Umum tingkat Azure Front Door.
SQL Database
Tujuan titik pemulihan (RPO) dan perkiraan tujuan waktu pemulihan (RTO) untuk SQL Database didokumentasikan dalam Gambaran Umum kelangsungan bisnis dengan Azure SQL Database.
Perhatikan bahwa replikasi geografis aktif secara efektif menggandakan biaya setiap database yang direplikasi. Database sandbox, pengujian, dan pengembangan biasanya tidak disarankan untuk replikasi.
Azure Cosmos DB
RPO dan tujuan waktu pemulihan (RTO) untuk Azure Cosmos DB dapat dikonfigurasi melalui tingkat konsistensi yang digunakan, yang menyediakan trade-off antara ketersediaan, durabilitas data, dan throughput. Azure Cosmos DB menyediakan RTO minimum 0 untuk tingkat konsistensi santai dengan multi-master atau RPO 0 untuk konsistensi yang kuat dengan master tunggal. Untuk mempelajari selengkapnya tentang tingkat konsistensi Azure Cosmos DB, lihat Tingkat konsistensi dan durabilitas data di Azure Cosmos DB.
Penyimpanan
Penyimpanan RA-GRS menyediakan penyimpanan yang tahan lama, tetapi penting untuk mempertimbangkan faktor-faktor berikut saat merenungkan melakukan failover:
Mengantisipasi kehilangan data: Replikasi data ke wilayah sekunder dilakukan secara asinkron. Oleh karena itu, jika geo-failover dilakukan, beberapa kehilangan data harus diantisipasi jika perubahan pada akun utama belum sepenuhnya disinkronkan ke akun sekunder. Anda dapat memeriksa properti Waktu Sinkronisasi Terakhir dari akun penyimpanan sekunder untuk melihat terakhir kali data dari wilayah utama berhasil ditulis ke wilayah sekunder.
Rencanakan tujuan waktu pemulihan Anda (RTO) yang sesuai: Failover ke wilayah sekunder biasanya memakan waktu sekitar satu jam, sehingga rencana DR Anda harus memperhitungkan informasi ini saat menghitung parameter RTO Anda.
Rencanakan failback Anda dengan hati-hati: Penting untuk dipahami bahwa ketika akun penyimpanan gagal, data di akun utama asli hilang. Mencoba failback ke wilayah utama tanpa perencanaan yang cermat berisiko. Setelah failover selesai, primer baru - di wilayah failover - akan dikonfigurasi untuk penyimpanan redundan lokal (LRS). Anda harus mengonfigurasi ulang secara manual sebagai penyimpanan yang direplikasi secara geografis untuk memulai replikasi ke wilayah utama dan kemudian memberikan waktu yang cukup untuk membiarkan akun disinkronkan.
Kegagalan sementara, seperti pemadaman jaringan, tidak akan memicu failover penyimpanan. Rancang aplikasi Anda agar tahan terhadap kegagalan sementara. Opsi mitigasi meliputi:
- Baca dari wilayah sekunder.
- Beralih sementara ke akun penyimpanan lain untuk operasi tulis baru (misalnya, untuk mengantre pesan).
- Salin data dari wilayah sekunder ke akun penyimpanan lain.
- Menyediakan fungsionalitas yang dikurangi hingga sistem gagal kembali.
Untuk informasi selengkapnya, lihat Apa yang harus dilakukan jika pemadaman Microsoft Azure Storage terjadi.
Lihat prasyarat dan peringatan untuk dokumentasi replikasi objek untuk pertimbangan saat menggunakan replikasi objek untuk blob blok.
Azure Service Bus
Penting untuk dipahami bahwa fitur pemulihan bencana geografis yang disertakan dalam tingkat Bus Layanan Azure premium memungkinkan kelangsungan operasi instan dengan konfigurasi yang sama. Namun, itu tidak mereplikasi pesan yang disimpan dalam antrean atau langganan topik atau antrean surat mati. Dengan demikian, strategi mitigasi diperlukan untuk memastikan failover yang lancar ke wilayah sekunder. Untuk deskripsi terperinci tentang pertimbangan dan strategi mitigasi lainnya, lihat poin-poin penting yang perlu dipertimbangkan dan dokumentasi pertimbangan pemulihan bencana.
Keamanan
Keamanan memberikan jaminan terhadap serangan yang disukai dan penyalahgunaan data dan sistem berharga Anda. Untuk informasi selengkapnya, lihat Gambaran Umum pilar keamanan.
Batasi lalu lintas masuk Konfigurasikan aplikasi untuk menerima lalu lintas hanya dari Front Door. Ini memastikan bahwa semua lalu lintas melewati WAF sebelum mencapai aplikasi. Untuk informasi selengkapnya, lihat Bagaimana cara mengunci akses ke backend saya hanya ke Azure Front Door?
Berbagi Sumber Daya Lintas Asal (CORS) Jika Anda membuat situs web dan API web sebagai aplikasi terpisah, situs web tidak dapat melakukan panggilan AJAX sisi klien ke API kecuali Anda mengaktifkan CORS.
Catatan
Keamanan browser mencegah halaman web untuk membuat permintaan AJAX ke domain lain. Pembatasan ini disebut kebijakan asal yang sama, dan mencegah situs yang berbahaya membaca data yang bersifat sensitif dari situs lain. CORS adalah standar W3C yang memungkinkan server untuk melonggarkan kebijakan asal yang sama dan mengizinkan beberapa permintaan lintas asal sambil menolak yang lain.
App Service memiliki dukungan bawaan untuk CORS, tanpa perlu menulis kode aplikasi apa pun. Lihat Mengonsumsi aplikasi API dari JavaScript menggunakan CORS. Tambahkan situs web ke daftar asal API yang diizinkan.
Enkripsi SQL Database Gunakan Enkripsi Data Transparan jika Anda perlu mengenkripsi data tidak aktif dalam database. Fitur ini melakukan enkripsi dan dekripsi real-time dari seluruh database (termasuk backup dan file log transaksi) dan tidak memerlukan perubahan pada aplikasi. Enkripsi memang menambahkan beberapa latensi, jadi merupakan praktik yang baik untuk memisahkan data yang harus aman ke dalam databasenya sendiri dan mengaktifkan enkripsi hanya untuk database tersebut.
Identitas Saat Anda menentukan identitas untuk komponen dalam arsitektur ini, gunakan identitas terkelola sistem jika memungkinkan untuk mengurangi kebutuhan Anda untuk mengelola kredensial dan risiko yang melekat pada pengelolaan kredensial. Jika tidak memungkinkan untuk menggunakan identitas terkelola sistem, pastikan bahwa setiap identitas terkelola pengguna hanya ada di satu wilayah dan tidak pernah dibagikan di seluruh batas wilayah.
Firewall layanan Saat mengonfigurasi firewall layanan untuk komponen, pastikan bahwa hanya layanan lokal wilayah yang memiliki akses ke layanan dan bahwa layanan hanya mengizinkan koneksi keluar, yang secara eksplisit diperlukan untuk replikasi dan fungsionalitas aplikasi. Pertimbangkan untuk menggunakan Azure Private Link untuk kontrol dan segmentasi yang lebih ditingkatkan. Untuk informasi selengkapnya tentang mengamankan aplikasi web, lihat Garis besar aplikasi web redundan zona yang sangat tersedia.
Pengoptimalan biaya
Optimalisasi biaya adalah tentang mencari cara untuk mengurangi pengeluaran yang tidak perlu dan meningkatkan efisiensi operasional. Untuk informasi selengkapnya, lihat Gambaran umum pilar pengoptimalan biaya.
Penembolokan Gunakan penembolokan untuk mengurangi beban pada server yang melayani konten yang tidak sering berubah. Setiap siklus render halaman dapat memengaruhi biaya karena menghabiskan komputasi, memori, dan bandwidth. Biaya tersebut dapat dikurangi secara signifikan dengan menggunakan penembolokan, terutama untuk layanan konten statis, seperti aplikasi satu halaman JavaScript dan konten streaming media.
Jika aplikasi Anda memiliki konten statis, gunakan CDN untuk mengurangi beban di server frontend. Untuk data yang tidak sering berubah, gunakan Azure Cache for Redis.
Aplikasi Stateless yang dikonfigurasi untuk penskalaan otomatis lebih hemat biaya daripada aplikasi stateful. Untuk aplikasi ASP.NET yang menggunakan status sesi, simpan di memori dengan Azure Cache for Redis. Untuk informasi selengkapnya, lihat Penyedia Status Sesi ASP.NET untuk Azure Cache for Redis. Opsi lain adalah menggunakan Azure Cosmos DB sebagai penyimpanan status backend melalui penyedia status sesi. Lihat Menggunakan Azure Cosmos DB sebagai status sesi ASP.NET dan penyedia penembolokan.
Functions Pertimbangkan untuk menempatkan aplikasi fungsi ke dalam paket App Service khusus sehingga tugas latar belakang tidak berjalan pada instans yang sama yang menangani permintaan HTTP. Jika tugas latar belakang berjalan terputus-putus, pertimbangkan untuk menggunakan rencana konsumsi, yang ditagih berdasarkan jumlah eksekusi dan sumber daya yang digunakan, bukan per jam.
Untuk informasi selengkapnya, lihat bagian biaya di Microsoft Azure Well-Architected Framework.
Menggunakan kalkulator harga untuk memperkirakan biaya. Rekomendasi di bagian ini dapat membantu Anda mengurangi biaya.
Azure Front Door
Penagihan Front Door Azure memiliki tiga tingkatan harga: transfer data keluar, transfer data masuk, dan aturan perutean. Untuk info selengkapnya Lihat Harga Azure Front Door. Bagan harga tidak termasuk biaya mengakses data dari layanan asal dan mentransfer ke Front Door. Biaya tersebut ditagih berdasarkan biaya transfer data, yang dijelaskan dalam Rincian Harga Bandwidth.
Azure Cosmos DB
Ada dua faktor yang menentukan harga Azure Cosmos DB:
Throughput yang disediakan atau Unit Permintaan per detik (RU/s).
Ada dua jenis throughput yang dapat disediakan di Azure Cosmos DB, standar dan skala otomatis. Throughput standar mengalokasikan sumber daya yang diperlukan untuk menjamin RU/s yang Anda tentukan. Untuk skala otomatis, Anda menyediakan throughput maksimum, dan Azure Cosmos DB langsung meningkatkan atau menurunkan skala tergantung pada beban, dengan minimal 10% dari throughput skala otomatis maksimum. Throughput standar dikenakan biaya untuk throughput yang disediakan setiap jam. Throughput penskalaan otomatis dikenakan biaya untuk throughput maksimum yang dikonsumsi setiap jam.
Penyimpanan yang dikonsumsi. Anda ditagih tarif tetap untuk jumlah total penyimpanan (GB) yang digunakan untuk data dan indeks selama satu jam tertentu.
Untuk informasi selengkapnya, lihat bagian biaya di Microsoft Azure Well-Architected Framework.
Efisiensi kinerja
Manfaat utama Azure App Service adalah kemampuan untuk menskalakan aplikasi Anda berdasarkan beban. Berikut adalah beberapa pertimbangan yang perlu diingat ketika berencana untuk menskalakan aplikasi Anda.
Aplikasi App Service
Jika solusi Anda mencakup beberapa aplikasi App Service, sebaiknya sebarkan aplikasi untuk memisahkan paket App Service. Pendekatan ini memungkinkan Anda untuk menskalakannya secara independen karena berjalan pada instans terpisah.
SQL Database
Tingkatkan skalabilitas database SQL dengan membagi database. Sharding mengacu pada mempartisi database secara horizontal. Sharding memungkinkan Anda menskalakan database secara horizontal menggunakan alat Database Elastis. Potensi manfaat dari sharding meliputi:
- Throughput transaksi yang lebih baik.
- Kueri dapat berjalan lebih cepat pada sub himpunan data.
Azure Front Door
Front Door dapat melakukan pembongkaran SSL dan juga mengurangi jumlah total koneksi TCP dengan aplikasi web backend. Ini meningkatkan skalabilitas karena aplikasi web mengelola volume jabat tangan SSL dan koneksi TCP yang lebih kecil. Peningkatan performa ini berlaku bahkan jika Anda meneruskan permintaan ke aplikasi web sebagai HTTPS, karena tingkat penggunaan kembali koneksi yang tinggi.
Pencarian Azure
Azure Search menghilangkan overhead dalam melakukan pencarian data yang kompleks dari penyimpanan data utama, dan dapat menskalakan untuk menangani beban. Lihat Menskalakan tingkat sumber daya untuk kueri dan beban kerja pengindeksan di Pencarian Azure.
Keunggulan operasional
Keunggulan operasional mengacu pada proses operasi yang menyebarkan aplikasi dan membuatnya tetap berjalan dalam produksi dan merupakan ekstensi dari panduan Keandalan Kerangka Kerja Yang Dirancang Dengan Baik. Panduan ini memberikan gambaran umum terperinci tentang merancang ketahanan ke dalam kerangka kerja aplikasi Anda untuk memastikan beban kerja Anda tersedia dan dapat pulih dari kegagalan dalam skala apa pun. Prinsip inti dari pendekatan ini adalah merancang infrastruktur aplikasi Anda agar sangat tersedia, secara optimal di beberapa wilayah geografis seperti yang diilustrasikan desain ini.
Langkah berikutnya
Pelajari lebih dalam tentang Azure Front Door - metode perutean lalu lintas
Buat pemeriksaan kesehatan yang melaporkan kesehatan aplikasi secara keseluruhan berdasarkan pola pemantauan titik akhir
Aktifkan grup kegagalan otomatis Azure SQL
Memastikan kelangsungan bisnis dan pemulihan bencana menggunakan Wilayah Berpasangan Azure
Sumber daya terkait
Aplikasi tingkat-N multi-wilayah adalah skenario yang serupa. Ini menunjukkan aplikasi N-tier yang berjalan di beberapa wilayah Azure