Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: ![]() NoSQL
NoSQL
Penting
Tips performa dalam artikel ini hanya untuk Azure Cosmos DB Java SDK v4. Silakan lihat Catatan rilis Azure Cosmos DB Java SDK v4, repositori Maven, dan panduan pemecahan masalah Azure Cosmos DB Java SDK v4 untuk informasi selengkapnya. Jika saat ini Anda menggunakan versi yang lebih lama dari v4, lihat panduan Migrasi ke Azure Cosmos DB Java SDK v4 untuk bantuan peningkatan ke v4.
Azure Cosmos DB merupakan database terdistribusi yang cepat dan fleksibel yang menskalakan secara lancar dengan tingkat latensi dan throughput terjamin. Anda tidak perlu membuat perubahan arsitektur besar atau menulis kode kompleks untuk menskalakan database dengan Azure Cosmos DB. Meningkatkan dan menurunkan skala semudah membuat satu panggilan API atau panggilan metode SDK. Namun karena Azure Cosmos DB diakses melalui panggilan jaringan, terdapat pengoptimalan sisi klien yang dapat Anda lakukan untuk mencapai performa puncak saat menggunakan Azure Cosmos DB Java SDK v4.
Jadi, jika Anda bertanya "Bagaimana cara meningkatkan kinerja database saya?" pertimbangkan opsi berikut ini:
Jaringan
Kolokasikan klien di wilayah Azure yang sama untuk performa
Jika memungkinkan, tempatkan aplikasi apa pun yang memanggil Azure Cosmos DB di wilayah yang sama dengan database Azure Cosmos DB. Sebagai perkiraan perbandingan, panggilan ke Azure Cosmos DB dalam wilayah yang sama selesai dalam 1-2 ms, tetapi latensi antara pantai Barat AS dan pantai Timur AS adalah >50 ms. Latensi ini dapat bervariasi dari permintaan ke permintaan tergantung pada rute yang diambil oleh permintaan saat melewati dari klien ke batas pusat data Azure. Latensi serendah mungkin dicapai dengan memastikan aplikasi panggilan berada di wilayah Azure yang sama dengan titik akhir Azure Cosmos DB yang tersedia. Untuk daftar wilayah yang tersedia, lihat Wilayah Azure.
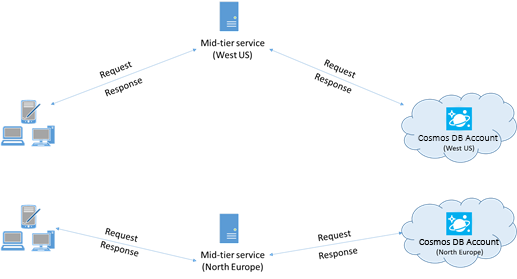
Aplikasi yang berinteraksi dengan akun Azure Cosmos DB multiwilayah perlu mengonfigurasi lokasi pilihan untuk memastikan bahwa permintaan menuju ke wilayah yang dikolokasikan.
Mengaktifkan jaringan yang dipercepat untuk mengurangi latensi dan jitter CPU
Kami sangat menyarankan untuk mengikuti instruksi untuk mengaktifkan Jaringan Terakselerasi di Windows Anda (pilih untuk instruksi) atau Linux (pilih untuk instruksi) Azure VM untuk memaksimalkan performa dengan mengurangi latensi dan jitter CPU.
Tanpa jaringan yang dipercepat, IO yang transit antara Azure VM Anda dan sumber daya Azure lainnya mungkin dirutekan melalui host dan sakelar virtual yang terletak antara VM dan kartu jaringannya. Memiliki host dan switch virtual tertanam dalam jalur data tidak hanya meningkatkan latensi dan jitter di saluran komunikasi, tetapi juga mencuri siklus CPU dari VM. Dengan jaringan yang dipercepat, VM berinteraksi langsung dengan NIC tanpa perantara. Semua detail kebijakan jaringan ditangani dalam perangkat keras di NIC, melewati host dan sakelar virtual. Umumnya Anda dapat mengharapkan latensi yang lebih rendah dan throughput yang lebih tinggi, serta latensi yang lebih konsisten dan pemanfaatan CPU yang menurun saat Anda mengaktifkan jaringan yang dipercepat.
Batasan: jaringan dipercepat harus didukung pada OS VM, dan hanya dapat diaktifkan ketika VM dihentikan dan dialokasikan ulang. VM tidak dapat disebarkan dengan Azure Resource Manager. App Service tidak mengaktifkan jaringan yang dipercepat.
Untuk informasi selengkapnya, lihat instruksi Windows dan Linux .
Ketersediaan tinggi
Untuk panduan umum tentang mengonfigurasi ketersediaan tinggi di Azure Cosmos DB, lihat Ketersediaan tinggi di Azure Cosmos DB.
Selain penyiapan dasar yang baik di platform database, ada teknik khusus yang dapat diimplementasikan di Java SDK itu sendiri, yang dapat membantu dalam skenario pemadaman. Dua strategi penting adalah strategi ketersediaan berbasis ambang batas dan pemutus sirkuit tingkat partisi.
Teknik ini menyediakan mekanisme lanjutan untuk mengatasi latensi dan tantangan ketersediaan tertentu, melampaui kemampuan coba lagi lintas wilayah yang dibangun ke dalam SDK secara default. Dengan secara proaktif mengelola potensi masalah pada tingkat permintaan dan partisi, strategi ini dapat secara signifikan meningkatkan ketahanan dan performa aplikasi Anda, terutama dalam kondisi beban tinggi atau terdegradasi.
Strategi ketersediaan berbasis ambang batas
Strategi ketersediaan berbasis ambang batas dapat meningkatkan latensi ekor dan ketersediaan dengan mengirim permintaan baca paralel ke wilayah sekunder (sebagaimana didefinisikan dalam preferredRegions) dan menerima respons tercepat. Pendekatan ini dapat secara drastis mengurangi dampak pemadaman regional atau kondisi latensi tinggi pada performa aplikasi. Selain itu, manajemen koneksi proaktif dapat digunakan untuk lebih meningkatkan performa dengan memanaskan koneksi dan cache di seluruh wilayah baca saat ini dan wilayah jarak jauh pilihan.
Konfigurasi contoh:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("East US", "East US 2", "West US"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Cara kerjanya:
Permintaan Awal: Pada saat T1, permintaan baca dibuat ke wilayah utama (misalnya, US Timur). SDK menunggu respons hingga 500 milidetik (
thresholdnilai).Permintaan Kedua: Jika tidak ada respons dari wilayah utama dalam 500 milidetik, permintaan paralel dikirim ke wilayah pilihan berikutnya (misalnya, US Timur 2).
Permintaan Ketiga: Jika wilayah utama maupun sekunder tidak merespons dalam 600 milidetik (500ms + 100ms,
thresholdStepnilainya), SDK mengirimkan permintaan paralel lain ke wilayah pilihan ketiga (misalnya, AS Barat).Kemenangan Respons Tercepat: Wilayah mana pun yang merespons terlebih dahulu, respons tersebut diterima, dan permintaan paralel lainnya diabaikan.
Manajemen koneksi proaktif membantu dengan menghangatkan koneksi dan cache untuk kontainer di seluruh wilayah pilihan, mengurangi latensi cold-start untuk skenario failover atau penulisan dalam penyiapan multi-wilayah.
Strategi ini dapat secara signifikan meningkatkan latensi dalam skenario di mana wilayah tertentu lambat atau sementara tidak tersedia, tetapi dapat dikenakan lebih banyak biaya dalam hal unit permintaan ketika permintaan lintas wilayah paralel diperlukan.
Catatan
Jika wilayah pilihan pertama mengembalikan kode status kesalahan non-sementara (misalnya, dokumen tidak ditemukan, kesalahan otorisasi, konflik, dll.), operasi itu sendiri akan gagal dengan cepat, karena strategi ketersediaan tidak akan memiliki manfaat dalam skenario ini.
Pemutus sirkuit tingkat partisi
Pemutus arus pada tingkat partisi meningkatkan latensi akhir dan ketersediaan penulisan dengan melacak dan memutus aliran permintaan secara langsung ke partisi fisik yang tidak sehat. Ini meningkatkan performa dengan menghindari partisi bermasalah yang diketahui dan mengalihkan permintaan ke wilayah yang lebih sehat.
Konfigurasi contoh:
Untuk mengaktifkan pemutus sirkuit tingkat partisi:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Untuk mengatur frekuensi proses latar belakang untuk memeriksa wilayah yang tidak tersedia:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Untuk mengatur durasi di mana partisi dapat tetap tidak tersedia:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Cara kerjanya:
Pelacakan Kegagalan: SDK melacak kegagalan terminal (misalnya, 503s, 500s, time-out) untuk partisi individual di wilayah tertentu.
Menandai sebagai Tidak Tersedia: Jika partisi di wilayah melebihi ambang batas kegagalan yang telah dikonfigurasi, partisi tersebut ditandai sebagai "Tidak Tersedia." Permintaan berikutnya ke partisi ini akan dihindari dan dialihkan ke wilayah lain yang kondisinya lebih baik.
Pemulihan Otomatis: Utas latar belakang secara berkala memeriksa partisi yang tidak tersedia. Setelah durasi tertentu, partisi ini secara tentatif ditandai sebagai "HealthyTentative" dan tunduk pada permintaan pengujian untuk memvalidasi pemulihan.
Promosi/Demosi Status Kesehatan: Berdasarkan keberhasilan atau kegagalan permintaan uji coba ini, status partisi dipromosikan kembali ke "Sehat" atau diturunkan menjadi "Tidak Tersedia."
Mekanisme ini membantu terus memantau kesehatan partisi dan memastikan bahwa permintaan dilayani dengan latensi minimal dan ketersediaan maksimum, tanpa ditahan oleh partisi yang bermasalah.
Catatan
Pemutus arus hanya berlaku untuk akun dengan penulisan multi-wilayah. Ketika sebuah partisi ditandai sebagai Unavailable, baik operasi baca maupun tulis akan dipindahkan ke wilayah pilihan berikutnya. Hal ini untuk mencegah pembacaan dan penulisan dari berbagai wilayah dilayani oleh instans klien yang sama, karena ini akan menjadi praktik buruk.
Penting
Anda harus menggunakan Java SDK versi 4.63.0 atau yang lebih tinggi untuk mengaktifkan Partition Level Circuit Breaker.
Membandingkan pengoptimalan ketersediaan
Strategi ketersediaan berbasis ambang batas:
- Manfaat: Mengurangi latensi ekor dengan mengirim permintaan baca paralel ke wilayah sekunder, dan meningkatkan ketersediaan dengan mendahului permintaan yang akan mengakibatkan waktu habis jaringan.
- Trade-off: Dikenakan biaya RU (Unit Permintaan) tambahan dibandingkan dengan pemutus sirkuit, karena permintaan lintas wilayah paralel tambahan (meskipun hanya selama periode saat ambang batas terlampaui).
- Penggunaan Kasus: Optimal untuk beban kerja yang dominan baca di mana mengurangi latensi sangat penting dan beberapa biaya tambahan (baik dalam hal biaya RU dan beban CPU pada klien) dapat diterima. Operasi tulis juga dapat menguntungkan jika memilih kebijakan coba ulang tulis non-idempoten dan akun memiliki kemampuan penulisan multi-wilayah.
Pemutus sirkuit dengan tingkat partisi:
- Manfaat: Meningkatkan ketersediaan dan latensi dengan menghindari partisi yang tidak sehat, memastikan permintaan dirutekan ke wilayah yang lebih sehat.
- Trade-off: Tidak dikenakan lebih banyak biaya RU, tetapi masih dapat memungkinkan beberapa kehilangan ketersediaan pada tahap awal untuk permintaan yang akan mengakibatkan pemutusan waktu jaringan.
- Kasus Penggunaan: Sangat cocok untuk beban kerja tulis yang berat atau campuran di mana performa yang konsisten sangat penting, terutama ketika berhadapan dengan partisi yang mungkin secara terputus-putus mengalami gangguan.
Kedua strategi dapat digunakan bersama-sama untuk meningkatkan ketersediaan baca dan tulis serta mengurangi latensi akhir. Partition Level Circuit Breaker dapat menangani berbagai skenario kegagalan sementara, termasuk yang dapat mengakibatkan replika berkinerja lambat, tanpa perlu melakukan permintaan paralel. Selain itu, menambahkan Strategi Berbasis Ambang Ketersediaan akan semakin meminimalkan latensi akhir dan menghilangkan kehilangan ketersediaan, jika biaya RU tambahan dianggap wajar.
Dengan menerapkan strategi ini, pengembang dapat memastikan aplikasi mereka tetap tangguh, mempertahankan performa tinggi, dan memberikan pengalaman pengguna yang lebih baik bahkan selama pemadaman regional atau kondisi latensi tinggi.
Konsistensi sesi yang dibatasi wilayah
Gambaran Umum
Untuk informasi selengkapnya tentang pengaturan konsistensi secara umum, lihat Tingkat konsistensi di Azure Cosmos DB. Java SDK menyediakan pengoptimalan untuk konsistensi sesi untuk akun penulisan multi-wilayah, dengan memungkinkan cakupannya menjadi berdasarkan wilayah. Ini meningkatkan performa dengan mengurangi latensi replikasi lintas regional melalui meminimalkan percobaan ulang sisi klien. Hal ini dicapai dengan mengelola token sesi di tingkat wilayah alih-alih secara global. Jika konsistensi dalam aplikasi Anda dapat dibatasi pada sejumlah kecil wilayah, melalui penerapan konsistensi sesi dengan cakupan wilayah, Anda dapat mencapai performa dan keandalan yang lebih baik untuk operasi baca dan tulis di akun dengan kemampuan menulis ganda dengan meminimalkan penundaan dan percobaan ulang replikasi lintas regional.
Keuntungan
- Latensi Berkurang: Dengan melokalisasi validasi token sesi ke tingkat wilayah, kemungkinan percobaan ulang lintas regional yang mahal berkurang.
- Peningkatan Performa: Meminimalkan dampak kegagalan regional dan jeda replikasi, menawarkan konsistensi baca/tulis yang lebih tinggi dan pemanfaatan CPU yang lebih rendah.
- Pemanfaatan Sumber Daya yang Dioptimalkan: Mengurangi overhead CPU dan jaringan pada aplikasi klien dengan membatasi kebutuhan akan percobaan ulang dan panggilan lintas regional, sehingga mengoptimalkan penggunaan sumber daya.
- Ketersediaan Tinggi: Dengan mempertahankan token sesi cakupan wilayah, aplikasi dapat terus beroperasi dengan lancar bahkan jika wilayah tertentu mengalami latensi yang lebih tinggi atau kegagalan sementara.
- Jaminan Konsistensi: Memastikan bahwa konsistensi sesi (membaca tulisan Anda, baca monotonik) terpenuhi dengan lebih andal tanpa perlu pengulangan.
- Efisiensi Biaya: Mengurangi jumlah panggilan lintas regional, sehingga berpotensi menurunkan biaya yang terkait dengan transfer data antar wilayah.
- Skalabilitas: Memungkinkan aplikasi untuk menskalakan lebih efisien dengan mengurangi pertikaian dan overhead yang terkait dengan mempertahankan token sesi global, terutama dalam pengaturan multi-wilayah.
Kompromi-Kompromi
- Peningkatan Penggunaan Memori: Filter Bloom dan penyimpanan token sesi yang khusus untuk wilayah memerlukan lebih banyak memori, yang mungkin menjadi pertimbangan penting untuk aplikasi dengan sumber daya terbatas.
- Kompleksitas Konfigurasi: Menyempurnakan jumlah penyisipan yang diharapkan dan tingkat positif palsu untuk filter mekar menambahkan lapisan kompleksitas ke proses konfigurasi.
- Potensi Positif Palsu: Meskipun bloom filter meminimalkan percobaan ulang lintas regional, masih ada sedikit kemungkinan positif palsu yang berdampak pada validasi token sesi, meskipun tingkatnya dapat dikendalikan. Positif palsu berarti token sesi global diselesaikan, sehingga meningkatkan kemungkinan percobaan kembali lintas regional jika wilayah lokal belum terjebak pada sesi global ini. Jaminan sesi terpenuhi bahkan dengan adanya positif palsu.
- Penerapan: Fitur ini paling bermanfaat untuk aplikasi dengan kardinalitas partisi logis yang tinggi dan restart reguler. Aplikasi dengan lebih sedikit penggunaan partisi logis ataupun jarang melakukan restart mungkin tidak mendapatkan manfaat yang signifikan.
Cara kerjanya
Mengatur token sesi
- Penyelesaian Permintaan: Setelah permintaan selesai, SDK mengambil token sesi dan mengaitkannya dengan wilayah dan kunci partisi.
-
Penyimpanan Tingkat Wilayah: Token sesi disimpan dalam berlapis
ConcurrentHashMapyang mempertahankan pemetaan antara rentang kunci partisi dan kemajuan tingkat wilayah. - Filter Mekar: Filter mekar melacak wilayah mana yang telah diakses oleh setiap partisi logis, membantu melokalisasi validasi token sesi.
Mengatasi token sesi
- Inisialisasi Permintaan: Sebelum permintaan dikirim, SDK mencoba menyelesaikan token sesi untuk wilayah yang sesuai.
- Pemeriksaan Token: Token diperiksa terhadap data regional untuk memastikan permintaan dialihkan ke replika yang paling mutakhir.
- Logika Coba Lagi: Jika token sesi tidak divalidasi dalam wilayah saat ini, SDK mencoba kembali dengan wilayah lain, tetapi mengingat penyimpanan yang dilokalkan, ini lebih jarang.
Menggunakan SDK
Berikut adalah cara menginisialisasi CosmosClient dengan konsistensi sesi yang dibatasi wilayah:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Mengaktifkan konsistensi sesi cakupan wilayah
Untuk mengaktifkan pengambilan sesi cakupan wilayah di aplikasi Anda, atur properti sistem berikut:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Mengonfigurasi bloom filter
Sesuaikan performa dengan mengonfigurasi penyisipan yang diharapkan dan tingkat kesalahan positif untuk bloom filter.
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Implikasi memori
Di bawah ini adalah ukuran yang dipertahankan (ukuran objek dan apa pun yang bergantung padanya) dari kontainer sesi internal (dikelola oleh SDK) dengan berbagai penyisipan yang diharapkan ke dalam filter mekar.
| Penyisipan yang Diharapkan | Tingkat Positif Palsu | Ukuran yang Dipertahankan |
|---|---|---|
| 10, 000 | 0,001 | 21 KB |
| 100, 000 | 0,001 | 183 KB |
| 1 juta | 0,001 | 1,8 MB |
| 10 juta | 0,001 | 17,9 MB |
| 100 juta | 0,001 | 179 MB |
| 1 miliar | 0,001 | 1,8 GB |
Penting
Anda harus menggunakan Java SDK versi 4.60.0 atau yang lebih tinggi untuk mengaktifkan konsistensi sesi cakupan wilayah.
Penyesuaian konfigurasi koneksi langsung dan gateway
Untuk mengoptimalkan konfigurasi koneksi mode langsung dan gateway, lihat cara menyetel konfigurasi koneksi untuk Java SDK v4.
Penggunaan SDK
- Menginstal SDK terbaru
Azure Cosmos DB SDK terus ditingkatkan untuk memberikan performa terbaik. Untuk menentukan peningkatan SDK terbaru, kunjungi Azure Cosmos DB SDK.
Setiap instans klien Azure Cosmos DB aman untuk penggunaan bersamaan dan melakukan manajemen koneksi serta caching alamat yang efisien. Untuk memungkinkan manajemen koneksi yang efisien dan performa yang lebih baik oleh klien Azure Cosmos DB, kami sangat menyarankan untuk menggunakan satu instans klien Azure Cosmos DB untuk masa pakai aplikasi.
Saat Anda membuat CosmosClient, konsistensi default yang digunakan jika tidak diatur secara eksplisit adalah Sesi. Jika konsistensi Sesi tidak diperlukan oleh logika aplikasi Anda, atur Konsistensi ke Eventual. Catatan: disarankan menggunakan setidaknya konsistensi Sesi dalam aplikasi yang bergantung pada pemroses Umpan Perubahan Azure Cosmos DB.
- Gunakan API Asinkron untuk memaksimalkan throughput yang tersedia
Azure Cosmos DB Java SDK v4 menggabungkan dua API, Sinkron dan Asinkron. Secara kasar, API Asinkron mengimplementasikan fungsionalitas SDK, sedangkan API Sinkron adalah pembungkus tipis yang membuat panggilan pemblokiran ke API Asinkron. Ini berbeda dengan Azure Cosmos DB Async Java SDK v2 yang lebih lama, yang hanya Asinkron, dan untuk Azure Cosmos DB Sync Java SDK v2 yang lebih lama, yang hanya sinkronisasi dan memiliki implementasi terpisah.
Pilihan API ditentukan selama inisialisasi klien; CosmosAsyncClient mendukung API Asinkron, sementara CosmosClient mendukung API Sinkron.
API Asinkron mengimplementasikan IO nonblocking dan merupakan pilihan optimal jika tujuan Anda adalah memaksimalkan throughput saat mengeluarkan permintaan ke Azure Cosmos DB.
Menggunakan Sync API dapat menjadi pilihan yang tepat jika Anda menginginkan atau memerlukan API, yang memblokir respons terhadap setiap permintaan, atau jika operasi sinkron adalah paradigma dominan dalam aplikasi Anda. Misalnya, Anda mungkin menginginkan API Sinkron saat Anda menyimpan data ke Azure Cosmos DB dalam aplikasi layanan mikro, asalkan throughput tidak penting.
Perhatikan bahwa throughput API sinkronisasi menurun seiring meningkatnya waktu respons permintaan, sedangkan API Asinkron dapat memanfaatkan kemampuan bandwidth penuh dari perangkat keras Anda.
Kolokasi geografis dapat memberi Anda throughput yang lebih tinggi dan lebih konsisten saat menggunakan API Sinkron (lihat Kolokasikan klien di wilayah Azure yang sama untuk performa), tetapi masih tidak diharapkan untuk melebihi throughput yang dapat dicapai API Asinkron.
Beberapa pengguna mungkin juga tidak terbiasa dengan Project Reactor, kerangka kerja Reactive Streams yang digunakan untuk mengimplementasikan Azure Cosmos DB Java SDK v4 Async API. Jika ini menjadi perhatian, kami sarankan Anda membaca pengantar Panduan Pola Reaktor kami, lalu lihat Pengantar Pemrograman Reaktif ini untuk membiasakan diri. Jika Anda telah menggunakan Azure Cosmos DB dengan antarmuka Asinkron, dan SDK yang Anda gunakan adalah Azure Cosmos DB Async Java SDK v2, maka Anda mungkin terbiasa dengan ReactiveX/RxJava tetapi tidak yakin apa yang telah berubah di Project Reactor. Dalam hal ini, lihat Panduan Reactor vs. RxJava kami untuk membiasakan diri.
Cuplikan kode berikut menunjukkan cara menginisialisasi klien Azure Cosmos DB Anda untuk API Asinkron atau operasi API Sinkron, masing-masing:
Java SDK V4 (Maven com.azure::azure-cosmos) API Asinkron
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Meluaskan skala beban kerja klien Anda
Jika Anda menguji pada tingkat throughput tinggi, aplikasi klien mungkin menjadi kendala karena mesin mencapai batas pada CPU atau penggunaan jaringan. Jika mencapai titik ini, Anda dapat terus mendorong akun Azure Cosmos DB lebih jauh dengan meluaskan skala aplikasi klien di beberapa server.
Aturan praktis yang baik adalah tidak melebihi >50% pemanfaatan CPU pada server tertentu untuk menjaga latensi tetap rendah.
- Gunakan Scheduler yang Sesuai (Hindari mencuri Event loop thread Netty IO)
Fungsionalitas asinkron dari Azure Cosmos DB Java SDK didasarkan pada IO non-blok netty. SDK menggunakan sejumlah tetap utas perulangan peristiwa Netty IO (sebanyak core CPU yang dimiliki mesin Anda) untuk menjalankan operasi IO. Flux yang dikembalikan oleh API mengirimkan hasil pada salah satu thread Netty dari loop event IO yang dibagikan. Jadi penting untuk tidak memblokir utas jelatang perulangan peristiwa IO bersama. Melakukan pekerjaan intensif CPU atau memblokir operasi pada utas netty perulangan peristiwa IO dapat menyebabkan kebuntuan atau mengurangi throughput SDK secara signifikan.
Misalnya, kode berikut menjalankan pekerjaan intensif CPU pada utas IO netty event loop:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Setelah hasilnya diterima, Anda harus menghindari melakukan pekerjaan yang membutuhkan CPU tinggi pada hasil pada utas event loop IO netty. Sebagai gantinya, Anda dapat memberikan Scheduler buatan Anda sendiri untuk menyediakan thread Anda sendiri untuk menjalankan tugas Anda, seperti yang ditunjukkan di bawah ini (memerlukan import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Berdasarkan jenis pekerjaan Anda, Anda harus menggunakan Penjadwal Reaktor yang sesuai untuk pekerjaan Anda. Baca di sini Schedulers.
Untuk lebih memahami model utas dan penjadwalan proyek Reactor, lihat posting blog ini oleh Project Reactor.
Untuk informasi selengkapnya tentang Azure Cosmos DB Java SDK v4, lihat direktori Azure Cosmos DB dari Monorepo Azure SDK for Java di GitHub.
- Mengoptimalkan pengaturan pengelogan di aplikasi Anda
Untuk berbagai alasan, Anda harus menambahkan pengelogan di utas yang menghasilkan throughput permintaan tinggi. Jika tujuan Anda adalah untuk sepenuhnya memaksimalkan throughput yang telah dialokasikan untuk kontainer dengan permintaan yang dibuat oleh utas ini, pengoptimalan pencatatan dapat sangat meningkatkan performansi.
- Mengonfigurasi pencatat asinkron
Latensi pencatat sinkron tentu menjadi faktor dalam perhitungan latensi keseluruhan dari utas pembuat permintaan Anda. Disarankan untuk menggunakan pencatat log asinkron seperti log4j2 untuk memisahkan beban kerja pengelogan dari utas aplikasi berkinerja tinggi milik Anda.
- Menonaktifkan pengelogan netty
Pengelogan pustaka Netty cerewet dan perlu dinonaktifkan (menekan masuk ke konfigurasi mungkin tidak cukup) untuk menghindari biaya CPU tambahan. Jika Anda tidak dalam mode penelusuran kesalahan, nonaktifkan pengelogan netty sama sekali. Jadi, jika Anda menggunakan Log4j untuk menghapus biaya CPU tambahan yang dikeluarkan oleh org.apache.log4j.Category.callAppenders() dari netty, tambahkan baris berikut ke basis kode Anda:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Batas Sumber Daya file Terbuka OS
Beberapa sistem Linux (seperti Red Hat) memiliki batas atas jumlah file yang terbuka dan juga jumlah koneksi. Jalankan yang berikut untuk melihat batas saat ini:
ulimit -a
Jumlah file terbuka (nofile) harus cukup besar untuk memiliki ruang yang cukup untuk ukuran kumpulan koneksi yang dikonfigurasi dan file terbuka lainnya oleh OS. Ini dapat dimodifikasi untuk memungkinkan ukuran kumpulan koneksi yang lebih besar.
Buka file limits.conf:
vim /etc/security/limits.conf
Tambahkan/modifikasi baris berikut:
* - nofile 100000
- Tentukan kunci partisi dalam penulisan titik
Untuk meningkatkan performa penulisan titik, tentukan kunci partisi item di panggilan API penulisan titik, seperti yang ditunjukkan di bawah ini:
Java SDK V4 (Maven com.azure::azure-cosmos) API Asinkron
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Daripada hanya menyediakan instans item, seperti yang ditunjukkan di bawah ini:
Java SDK V4 (Maven com.azure::azure-cosmos) API Asinkron
asyncContainer.createItem(item).block();
Yang terakhir ini didukung tetapi akan menambah latensi ke aplikasi Anda; SDK harus memilah item dan mengekstrak kunci partisi.
Operasi Query
Untuk operasi kueri, lihat tips performa untuk kueri.
Kebijakan pengindeksan
- Mengecualikan jalur yang tidak digunakan dari pengindeksan untuk penulisan yang lebih cepat
Kebijakan pengindeksan Azure Cosmos DB memungkinkan Anda menentukan jalur dokumen mana yang akan disertakan atau dikecualikan dari pengindeksan dengan menggunakan Jalur Pengindeksan (setIncludedPaths dan setExcludedPaths). Penggunaan jalur pengindeksan dapat menawarkan performa tulis yang lebih baik dan penyimpanan indeks yang lebih rendah untuk skenario di mana pola kueri diketahui sebelumnya karena biaya pengindeksan secara langsung berkorelasi dengan jumlah jalur unik yang diindeks. Misalnya, kode berikut menunjukkan cara menyertakan dan mengecualikan seluruh bagian dokumen (juga dikenal sebagai subtree) dari pengindeksan menggunakan kartu bebas "*".
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Untuk informasi selengkapnya, lihat kebijakan pengindeksan Azure Cosmos DB.
Kapasitas
- Ukur dan sesuaikan untuk penggunaan unit permintaan per detik yang lebih rendah
Azure Cosmos DB menawarkan set operasi database yang kaya termasuk kueri relasional dan hierarkis dengan UDF, prosedur tersimpan, dan pemicu – semuanya beroperasi pada dokumen dalam koleksi database. Biaya yang terkait dengan masing-masing operasi ini bervariasi berdasarkan CPU, IO, dan memori yang diperlukan untuk menyelesaikan operasi. Alih-alih memikirkan dan mengelola sumber daya perangkat keras, Anda dapat memikirkan unit permintaan (RU) sebagai ukuran tunggal untuk sumber daya yang diperlukan untuk melakukan berbagai operasi database dan melayani permintaan aplikasi.
Throughput disediakan berdasarkan jumlah unit permintaan yang diatur untuk setiap kontainer. Konsumsi unit permintaan dievaluasi sebagai tarif per detik. Aplikasi yang melebihi tarif unit permintaan yang disediakan untuk kontainernya akan dibatasi hingga tarifnya turun di bawah tingkat yang disediakan untuk kontainer tersebut. Jika aplikasi Anda memerlukan tingkat throughput yang lebih tinggi, Anda dapat meningkatkan throughput dengan provisi unit permintaan tambahan.
Kompleksitas suatu kueri memengaruhi jumlah unit permintaan yang digunakan dalam sebuah operasi. Jumlah predikat, sifat predikat, jumlah UDF, dan ukuran set data sumber semuanya memengaruhi biaya operasi kueri.
Untuk mengukur overhead operasi apa pun (buat, perbarui, atau hapus), periksa header x-ms-request-charge untuk mengukur jumlah unit permintaan yang dikonsumsi oleh operasi ini. Anda juga dapat melihat properti RequestCharge yang setara di ResourceResponse<T> atau FeedResponse<T>.
Java SDK V4 (Maven com.azure::azure-cosmos) API Asinkron
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
Biaya permintaan yang dikembalikan di header ini merupakan sebagian kecil dari kapasitas pemrosesan yang Anda tentukan. Misalnya, jika Anda memiliki 2000 RU/dtk yang sudah disediakan, dan jika kueri sebelumnya mengembalikan 1.000 dokumen berukuran 1KB, biaya operasi adalah 1000. Dengan demikian, dalam satu detik server hanya menerima dua permintaan seperti itu sebelum membatasi tarif permintaan selanjutnya. Untuk informasi selengkapnya, lihat Unit permintaan dan kalkulator unit permintaan.
- Tangani pembatasan laju/laju permintaan yang terlalu tinggi
Saat klien mencoba untuk melebihi throughput yang dicadangkan untuk sebuah akun, tidak ada penurunan kinerja di server dan tidak ada penggunaan kapasitas throughput di luar tingkat yang dicadangkan. Server akan terlebih dahulu mengakhiri permintaan dengan RequestRateTooLarge (kode status HTTP 429) dan mengembalikan header x-ms-retry-after-ms yang menunjukkan jumlah waktu, dalam milidetik, yang pengguna harus menunggu sebelum mencoba kembali permintaan tersebut.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK secara implisit menangkap respons ini, mengindahkan header coba-lagi yang ditentukan server, dan mengulang permintaan. Kecuali akun Anda diakses secara bersamaan oleh beberapa klien, percobaan berikutnya akan berhasil.
Jika Anda memiliki lebih dari satu klien yang secara kumulatif beroperasi secara konsisten di atas tingkat permintaan, jumlah coba lagi default yang saat ini diatur ke 9 secara internal oleh klien mungkin tidak cukup; dalam hal ini, klien melempar CosmosClientException dengan kode status 429 ke aplikasi. Jumlah coba lagi default dapat diubah dengan menggunakan setMaxRetryAttemptsOnThrottledRequests() pada ThrottlingRetryOptions instans. Secara default, CosmosClientException dengan kode status 429 dikembalikan setelah waktu tunggu kumulatif 30 detik jika permintaan terus beroperasi di atas tarif permintaan. Hal ini terjadi meskipun jumlah percobaan ulang saat ini kurang dari jumlah percobaan ulang maksimal, baik itu default 9 atau nilai yang ditentukan pengguna.
Meskipun perilaku percobaan ulang otomatis membantu meningkatkan ketahanan dan kegunaan untuk sebagian besar aplikasi, perilaku tersebut mungkin bertentangan saat melakukan tolok ukur performa, terutama saat mengukur latensi. Latensi yang diamati oleh klien akan melonjak jika eksperimen mencapai batas server dan menyebabkan SDK klien mencoba ulang secara otomatis dan diam-diam. Untuk menghindari lonjakan latensi selama eksperimen performa, ukur muatan yang dikembalikan oleh setiap operasi dan pastikan bahwa permintaan beroperasi di bawah tingkat permintaan yang telah dipesan. Untuk informasi selengkapnya, lihat Unit permintaan.
- Mendesain dokumen yang lebih kecil untuk throughput yang lebih tinggi
Biaya permintaan (biaya pemrosesan permintaan) dari operasi tertentu berkorelasi langsung dengan ukuran dokumen. Operasi pada dokumen besar lebih mahal daripada operasi untuk dokumen kecil. Idealnya, arsitek aplikasi dan alur kerja Anda agar ukuran item Anda menjadi ~1 KB, atau urutan atau besaran serupa. Untuk aplikasi sensitif latensi, item besar harus dihindari - dokumen multi-MB memperlambat aplikasi Anda.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang perancangan aplikasi Anda untuk skala dan kinerja tinggi, lihat Pemartisian dan penyekalaan di Azure Cosmos DB.
Mencoba melakukan perencanaan kapasitas untuk migrasi ke Azure Cosmos DB? Anda dapat menggunakan informasi tentang kluster database Anda yang ada saat ini untuk membuat perencanaan kapasitas.
- Jika Anda hanya mengetahui jumlah vCore dan server di kluster database yang ada, baca tentang memperkirakan unit permintaan menggunakan vCore atau vCPU
- Jika Anda mengetahui rasio permintaan umum untuk beban kerja database Anda saat ini, baca memperkirakan unit permintaan menggunakan perencana kapasitas Azure Cosmos DB