Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Important
Ini bukan Java SDK terbaru untuk Azure Cosmos DB! Anda harus meningkatkan proyek Anda ke Azure Cosmos DB Java SDK v4 lalu membaca panduan tips performa Azure Cosmos DB Java SDK v4. Ikuti instruksi dalam panduan Migrasi ke Azure Cosmos DB Java SDK v4 dan panduan Reactor vs RxJava untuk meningkatkan.
Tips performa ini hanya untuk Azure Cosmos DB Sync Java SDK v2. Silakan lihat repositori Maven untuk informasi lebih lanjut.
Important
Pada 29 Februari 2024, Azure Cosmos DB Sync Java SDK v2.x akan dihentikan; SDK dan semua aplikasi yang menggunakan SDK akan terus berfungsi; Azure Cosmos DB hanya akan berhenti memberikan pemeliharaan dan dukungan lebih lanjut untuk SDK ini. Sebaiknya ikuti petunjuk di atas untuk bermigrasi ke Azure Cosmos DB Java SDK v4.
Azure Cosmos DB merupakan database terdistribusi yang cepat dan fleksibel yang menskalakan secara lancar dengan tingkat latensi dan throughput terjamin. Anda tidak perlu membuat perubahan arsitektur besar atau menulis kode kompleks untuk menskalakan database dengan Azure Cosmos DB. Peningkatan atau penurunan skala semudah menjalankan satu panggilan API. Untuk mempelajari lebih lanjut, lihat cara menyediakan throughput kontainer atau cara menyediakan throughput database. Namun, karena Azure Cosmos DB diakses melalui panggilan jaringan ada pengoptimalan sisi klien yang dapat Anda lakukan untuk mencapai performa puncak saat menggunakan Azure Cosmos DB Sync Java SDK v2.
Jadi, jika Anda bertanya "Bagaimana cara meningkatkan kinerja database saya?" pertimbangkan opsi berikut ini:
Jaringan
Mode koneksi: Gunakan DirectHttps
Bagaimana klien terhubung ke Azure Cosmos DB memiliki implikasi penting pada performa, terutama dalam hal latensi sisi klien yang diamati. Ada satu pengaturan konfigurasi utama yang tersedia untuk mengonfigurasi ConnectionPolicy klien – ConnectionMode. Dua ConnectionModes yang tersedia adalah:
-
Mode gateway didukung pada semua platform SDK dan merupakan default yang dikonfigurasi. Jika aplikasi Anda berjalan dalam jaringan perusahaan dengan pembatasan firewall yang ketat, Gateway adalah pilihan terbaik karena menggunakan port HTTPS standar dan satu titik akhir. Namun, kompromi kinerja dari mode Gateway adalah melibatkan tambahan hop jaringan setiap kali data dibaca atau ditulis ke Azure Cosmos DB. Karena itu, mode DirectHttps menawarkan performa yang lebih baik karena lebih sedikit hop jaringan.
Azure Cosmos DB Sync Java SDK v2 menggunakan HTTPS sebagai protokol transportasi. HTTPS menggunakan TLS untuk autentikasi awal dan mengenkripsi lalu lintas. Saat menggunakan Azure Cosmos DB Sync Java SDK v2, hanya port HTTPS 443 yang perlu dibuka.
ConnectionMode dikonfigurasi selama pembangunan instans DocumentClient dengan parameter ConnectionPolicy.
Sinkronkan Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);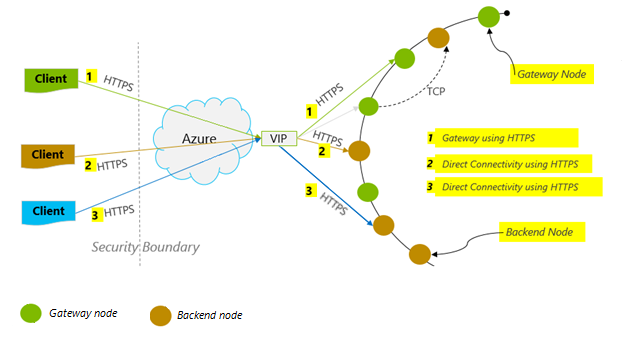
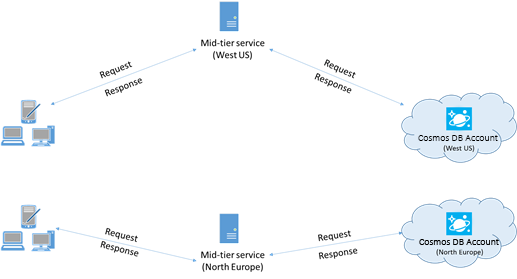
Kolokasikan klien di wilayah Azure yang sama untuk performa
Jika memungkinkan, tempatkan aplikasi apa pun yang memanggil Azure Cosmos DB di wilayah yang sama dengan database Azure Cosmos DB. Sebagai perkiraan perbandingan, panggilan ke Azure Cosmos DB dalam wilayah yang sama selesai dalam 1-2 ms, tetapi latensi antara pantai Barat AS dan pantai Timur AS adalah >50 ms. Latensi ini dapat bervariasi dari permintaan ke permintaan tergantung pada rute yang diambil oleh permintaan saat melewati dari klien ke batas pusat data Azure. Latensi serendah mungkin dicapai dengan memastikan aplikasi panggilan berada di wilayah Azure yang sama dengan titik akhir Azure Cosmos DB yang tersedia. Untuk daftar wilayah yang tersedia, lihat Wilayah Azure.
Penggunaan SDK
Menginstal SDK terbaru
Azure Cosmos DB SDK terus ditingkatkan untuk memberikan performa terbaik. Untuk menentukan peningkatan SDK terbaru, kunjungi Azure Cosmos DB SDK.
Menggunakan klien database tunggal Azure Cosmos DB sepanjang siklus hidup aplikasi Anda
Setiap instans DocumentClient aman untuk utas dan mengelola koneksi serta menyimpan cache alamat secara efisien saat beroperasi dalam Direct Mode. Untuk memungkinkan manajemen koneksi yang efisien dan performa yang lebih baik oleh DocumentClient, disarankan untuk menggunakan satu instans DocumentClient per AppDomain untuk masa pakai aplikasi.
Meningkatkan MaxPoolSize per host saat menggunakan mode Gateway
Permintaan Azure Cosmos DB dibuat melalui HTTPS/REST saat menggunakan mode Gateway, dan tunduk pada batas koneksi default per nama host atau alamat IP. Anda mungkin perlu mengatur MaxPoolSize ke nilai yang lebih tinggi (200-1000) sehingga pustaka klien dapat menggunakan beberapa koneksi simultan ke Azure Cosmos DB. Di Azure Cosmos DB Sync Java SDK v2, nilai default untuk ConnectionPolicy.getMaxPoolSize adalah 100. Gunakan setMaxPoolSize untuk mengubah nilai.
Menyetel kueri paralel pada koleksi yang telah dipartisi
Azure Cosmos DB Sync Java SDK versi 1.9.0 ke atas mendukung kueri paralel, yang memungkinkan Anda mengkueri koleksi yang dipartisi secara paralel. Untuk informasi selengkapnya, lihat sampel kode yang terkait dengan bekerja dengan SDK. Kueri paralel dirancang untuk meningkatkan latensi dan throughput dibandingkan versi serialnya.
(a) Menyetel setMaxDegreeOfParallelism: Kueri paralel berfungsi dengan melakukan kueri pada beberapa partisi secara paralel. Namun, data dari koleksi yang dipartisi individu diambil secara serial sehubungan dengan kueri. Jadi, gunakan setMaxDegreeOfParallelism untuk mengatur jumlah partisi yang memiliki peluang maksimum untuk mencapai kueri yang paling berkinerja, asalkan semua kondisi sistem lainnya tetap sama. Jika Anda tidak tahu jumlah partisi, Anda dapat menggunakan setMaxDegreeOfParallelism untuk mengatur angka tinggi, dan sistem memilih minimum (jumlah partisi, input yang disediakan pengguna) sebagai tingkat paralelisme maksimum.
Penting untuk dicatat bahwa kueri paralel menghasilkan manfaat terbaik jika data didistribusikan secara merata di semua partisi sehubungan dengan kueri. Jika koleksi yang dipartisi dipartisi sedemikian sehingga semua atau sebagian besar data yang dikembalikan oleh kueri terkonsentrasi dalam beberapa partisi (satu partisi dalam kasus terburuk), maka performa kueri akan terhambat oleh partisi-partisi tersebut.
(b) Menyetel setMaxBufferedItemCount: Kueri paralel dirancang untuk melakukan prefetch hasil saat batch hasil saat ini sedang diproses oleh klien. Prefetching membantu dalam pengurangan latensi kueri secara keseluruhan. setMaxBufferedItemCount membatasi jumlah hasil yang telah diambil sebelumnya. Dengan mengatur setMaxBufferedItemCount ke jumlah hasil yang diharapkan yang dikembalikan (atau angka yang lebih tinggi), ini memungkinkan kueri untuk menerima manfaat maksimum dari prefetching.
Prefetching bekerja dengan cara yang sama terlepas dari MaxDegreeOfParallelism, dan ada satu buffer untuk data dari semua partisi.
Menerapkan backoff pada interval yang ditentukan oleh getRetryAfterInMilliseconds
Selama pengujian performa, Anda harus meningkatkan beban hingga sejumlah kecil permintaan dibatasi lajunya. Jika dibatasi, aplikasi klien harus menahan diri dari pembatasan untuk jangka waktu penundaan yang ditentukan server. Menghormati konsep "backoff" memastikan bahwa Anda menghabiskan waktu seminimal mungkin menunggu di antara percobaan ulang. Dukungan kebijakan coba lagi disertakan dalam Versi 1.8.0 ke atas Azure Cosmos DB Sync Java SDK. Untuk informasi selengkapnya, lihat getRetryAfterInMilliseconds.
Meluaskan skala beban kerja klien Anda
Jika Anda menguji pada tingkat throughput tinggi (>50.000 RU/dtk), aplikasi klien mungkin menjadi hambatan karena mesin mencapai batas maksimum pada pemakaian CPU atau jaringan. Jika mencapai titik ini, Anda dapat terus mendorong akun Azure Cosmos DB lebih jauh dengan meluaskan skala aplikasi klien di beberapa server.
Menggunakan alamat berbasis nama
Gunakan alamat berbasis nama, di mana tautan memiliki format
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, alih-alih SelfLinks (_self), yang memiliki formatdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>untuk menghindari pengambilan ResourceId dari semua sumber daya yang digunakan untuk membuat tautan. Selain itu, karena sumber daya ini dapat dibuat ulang (mungkin dengan nama yang sama), penyimpanan sementara ini mungkin tidak efektif.Menyetel ukuran halaman untuk kueri/umpan baca untuk performa yang lebih baik
Saat melakukan pembacaan massal dokumen dengan menggunakan fungsionalitas umpan baca (misalnya, readDocuments) atau saat mengeluarkan kueri SQL, hasilnya dikembalikan dengan cara tersegmentasi jika tataan hasil terlalu besar. Secara default, hasil dikembalikan dalam potongan 100 item atau 1 MB, tergantung batas mana yang terpenuhi lebih dulu.
Untuk mengurangi jumlah perjalanan pulang pergi jaringan yang diperlukan untuk mengambil semua hasil yang berlaku, Anda dapat meningkatkan ukuran halaman menggunakan header permintaan x-ms-max-item-count hingga 1000. Dalam kasus di mana Anda hanya perlu menampilkan beberapa hasil, misalnya, jika antarmuka pengguna atau API aplikasi Anda hanya mengembalikan 10 hasil sekali waktu, Anda juga dapat mengurangi ukuran halaman menjadi 10 untuk mengurangi throughput yang digunakan untuk baca dan kueri.
Anda juga dapat mengatur ukuran halaman menggunakan metode setPageSize.
Kebijakan Pengindeksan
Mengecualikan jalur yang tidak digunakan dari pengindeksan untuk penulisan yang lebih cepat
Kebijakan pengindeksan Azure Cosmos DB memungkinkan Anda menentukan jalur dokumen mana yang akan disertakan atau dikecualikan dari pengindeksan dengan menggunakan Jalur Pengindeksan (setIncludedPaths dan setExcludedPaths). Penggunaan jalur pengindeksan dapat menawarkan performa tulis yang lebih baik dan penyimpanan indeks yang lebih rendah untuk skenario di mana pola kueri diketahui sebelumnya karena biaya pengindeksan secara langsung berkorelasi dengan jumlah jalur unik yang diindeks. Misalnya, kode berikut menunjukkan cara mengecualikan seluruh bagian (subtree) dokumen dari pengindeksan menggunakan kartubebas "*".
Sinkronkan Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Untuk informasi selengkapnya, lihat kebijakan pengindeksan Azure Cosmos DB.
Daya Tampung
Ukur dan sesuaikan untuk penggunaan unit permintaan per detik yang lebih rendah
Azure Cosmos DB menawarkan set operasi database yang kaya termasuk kueri relasional dan hierarkis dengan UDF, prosedur tersimpan, dan pemicu – semuanya beroperasi pada dokumen dalam koleksi database. Biaya yang terkait dengan masing-masing operasi ini bervariasi berdasarkan CPU, IO, dan memori yang diperlukan untuk menyelesaikan operasi. Alih-alih memikirkan dan mengelola sumber daya perangkat keras, Anda dapat memikirkan unit permintaan (RU) sebagai ukuran tunggal untuk sumber daya yang diperlukan untuk melakukan berbagai operasi database dan melayani permintaan aplikasi.
Throughput disediakan berdasarkan jumlah unit permintaan yang ditetapkan untuk setiap kontainer. Konsumsi unit permintaan dievaluasi sebagai tarif per detik. Aplikasi yang melebihi tarif unit permintaan yang disediakan untuk kontainernya akan dibatasi hingga tarifnya turun di bawah tingkat yang disediakan untuk kontainer tersebut. Jika aplikasi Anda memerlukan tingkat throughput yang lebih tinggi, Anda dapat meningkatkan throughput dengan provisi unit permintaan tambahan.
Kompleksitas suatu kueri memengaruhi jumlah unit permintaan yang digunakan dalam sebuah operasi. Jumlah predikat, sifat predikat, jumlah UDF, dan ukuran set data sumber semuanya memengaruhi biaya operasi kueri.
Untuk mengukur overhead operasi apa pun (membuat, memperbarui, atau menghapus), periksa header x-ms-request-charge (atau properti RequestCharge yang setara di ResourceResponse<T> atau FeedResponse<T> untuk mengukur jumlah unit permintaan yang digunakan oleh operasi ini.
Sinkronkan Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();Biaya permintaan yang dikembalikan di header ini merupakan sebagian kecil dari kapasitas pemrosesan yang Anda tentukan. Misalnya, jika Anda memiliki 2000 RU/dtk yang disediakan, dan jika kueri sebelumnya mengembalikan 1.000 dokumen 1KB, biaya operasi adalah 1000. Dengan demikian, dalam satu detik server hanya menerima dua permintaan seperti itu sebelum membatasi tarif permintaan selanjutnya. Untuk informasi selengkapnya, lihat Unit permintaan dan kalkulator unit permintaan.
Tangani pembatasan laju/laju permintaan yang terlalu tinggi
Saat klien mencoba untuk melebihi throughput yang dicadangkan untuk sebuah akun, tidak ada penurunan kinerja di server dan tidak ada penggunaan kapasitas throughput di luar tingkat yang dicadangkan. Server akan terlebih dahulu mengakhiri permintaan dengan RequestRateTooLarge (kode status HTTP 429) dan mengembalikan header x-ms-retry-after-ms yang menunjukkan jumlah waktu, dalam milidetik, yang pengguna harus menunggu sebelum mencoba kembali permintaan tersebut.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100SDK-SDK tersebut secara implisit menangani respons ini, mematuhi header coba-lagi yang ditentukan server, dan mengirim ulang permintaan. Kecuali akun Anda diakses secara bersamaan oleh beberapa klien, percobaan berikutnya akan berhasil.
Jika Anda memiliki lebih dari satu klien yang secara kumulatif beroperasi secara konsisten di atas tingkat permintaan, jumlah coba lagi default yang saat ini diatur ke 9 secara internal oleh klien mungkin tidak cukup; dalam hal ini, klien melempar DocumentClientException dengan kode status 429 ke aplikasi. Jumlah pengulangan default dapat diubah dengan menggunakan setRetryOptions pada instans ConnectionPolicy. Secara default, DocumentClientException dengan kode status 429 dikembalikan setelah waktu tunggu kumulatif 30 detik jika permintaan terus beroperasi di atas tingkat permintaan. Hal ini terjadi meskipun jumlah percobaan ulang saat ini kurang dari jumlah percobaan ulang maksimal, baik itu default 9 atau nilai yang ditentukan pengguna.
Meskipun perilaku percobaan ulang otomatis membantu meningkatkan ketahanan dan kegunaan untuk sebagian besar aplikasi, perilaku tersebut mungkin bertentangan saat melakukan tolok ukur performa, terutama saat mengukur latensi. Latensi yang diamati oleh klien akan melonjak jika eksperimen mencapai batas server dan menyebabkan SDK klien melakukan percobaan ulang tanpa pemberitahuan. Untuk menghindari lonjakan latensi selama eksperimen performa, ukur muatan yang dikembalikan oleh setiap operasi dan pastikan bahwa permintaan beroperasi di bawah tingkat permintaan yang telah dipesan. Untuk informasi selengkapnya, lihat Unit permintaan.
Mendesain dokumen yang lebih kecil untuk throughput yang lebih tinggi
Biaya permintaan (biaya pemrosesan permintaan) dari operasi tertentu berkorelasi langsung dengan ukuran dokumen. Operasi pada dokumen besar lebih mahal daripada operasi untuk dokumen kecil.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang perancangan aplikasi Anda untuk skala dan kinerja tinggi, lihat Pemartisian dan penyekalaan di Azure Cosmos DB.