Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Important
Tips performa dalam artikel ini hanya untuk Azure Cosmos DB Python SDK. Silakan lihat catatan Rilis Readme Azure Cosmos DB Python SDK, Paket (PyPI), Paket (Conda), dan panduan pemecahan masalah untuk informasi selengkapnya.
Azure Cosmos DB merupakan database terdistribusi yang cepat dan fleksibel yang menskalakan secara lancar dengan tingkat latensi dan throughput terjamin. Anda tidak perlu membuat perubahan arsitektur besar atau menulis kode kompleks untuk menskalakan database dengan Azure Cosmos DB. Meningkatkan dan menurunkan skala semudah membuat satu panggilan API atau panggilan metode SDK. Namun, karena Azure Cosmos DB diakses melalui panggilan jaringan ada pengoptimalan sisi klien yang dapat Anda lakukan untuk mencapai performa puncak saat menggunakan Azure Cosmos DB Python SDK.
Jadi, jika Anda bertanya "Bagaimana cara meningkatkan kinerja database saya?" pertimbangkan opsi berikut ini:
Jaringan
- Kolokasikan klien di wilayah Azure yang sama untuk performa
Jika memungkinkan, tempatkan aplikasi apa pun yang memanggil Azure Cosmos DB di wilayah yang sama dengan database Azure Cosmos DB. Sebagai perkiraan perbandingan, panggilan ke Azure Cosmos DB dalam wilayah yang sama selesai dalam 1-2 ms, tetapi latensi antara pantai Barat AS dan pantai Timur AS adalah >50 ms. Latensi ini dapat bervariasi dari permintaan ke permintaan tergantung pada rute yang diambil oleh permintaan saat melewati dari klien ke batas pusat data Azure. Latensi serendah mungkin dicapai dengan memastikan aplikasi panggilan berada di wilayah Azure yang sama dengan titik akhir Azure Cosmos DB yang tersedia. Untuk daftar wilayah yang tersedia, lihat Wilayah Azure.
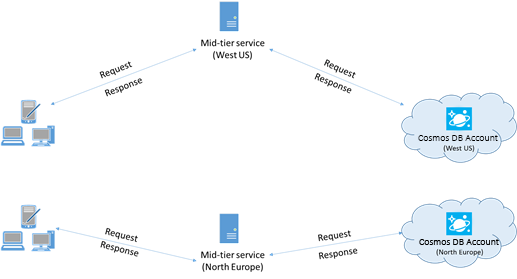
Aplikasi yang berinteraksi dengan akun Azure Cosmos DB multiwilayah perlu mengonfigurasi lokasi pilihan untuk memastikan bahwa permintaan menuju ke wilayah yang dikolokasikan.
Mengaktifkan jaringan yang dipercepat untuk mengurangi latensi dan jitter CPU
Disarankan agar Anda mengikuti instruksi untuk mengaktifkan Jaringan Terakselerasi di Windows Anda (pilih untuk instruksi) atau Linux (pilih untuk instruksi) Azure VM, untuk memaksimalkan performa (mengurangi latensi dan jitter CPU).
Tanpa networking yang dipercepat, IO yang transit antara Azure VM Anda dan sumber daya Azure lainnya mungkin dirutekan tanpa perlu melalui host dan sakelar virtual yang terletak antara VM dan kartu jaringannya. Memiliki host dan switch virtual terhubung langsung dalam jalur data tidak hanya meningkatkan latensi dan jitter di saluran komunikasi, tetapi juga mengurangi siklus CPU yang tersedia untuk VM. Dengan jaringan yang dipercepat, VM berinteraksi langsung dengan NIC (Network Interface Card) tanpa perantara; detail kebijakan jaringan apa pun yang sebelumnya ditangani oleh host dan switch virtual sekarang ditangani melalui perangkat keras pada NIC; host dan switch virtual dilewati. Umumnya Anda dapat mengharapkan latensi yang lebih rendah dan throughput yang lebih tinggi, serta latensi yang lebih konsisten dan pemanfaatan CPU yang menurun saat Anda mengaktifkan jaringan yang dipercepat.
Batasan: jaringan dipercepat harus didukung pada OS VM, dan hanya dapat diaktifkan ketika VM dihentikan dan dialokasikan ulang. VM tidak dapat diterapkan dengan Azure Resource Manager. App Service tidak mengaktifkan jaringan yang dipercepat.
Silakan lihat instruksi Windows dan Linux untuk lebih jelasnya.
Ketersediaan tinggi
Untuk panduan umum tentang mengonfigurasi ketersediaan tinggi di Azure Cosmos DB, lihat Ketersediaan tinggi di Azure Cosmos DB.
Selain pengaturan dasar yang baik di platform database, pemutus sirkuit tingkat partisi dapat diimplementasikan di Python SDK, yang dapat membantu dalam skenario pemadaman. Fitur ini menyediakan mekanisme lanjutan untuk menghadapi tantangan ketersediaan, dengan meningkatkan kemampuan coba ulang lintas wilayah yang telah terintegrasi dalam SDK secara default. Ini dapat secara signifikan meningkatkan ketahanan dan performa aplikasi Anda, terutama dalam kondisi beban tinggi atau terdegradasi.
Pemutus sirkuit tingkat partisi
Pemutus arus tingkat partisi (PPCB) di Python SDK meningkatkan ketersediaan dan ketahanan dengan melacak kesehatan partisi fisik individu dan mengarahkan permintaan menjauh dari partisi yang bermasalah. Fitur ini sangat berguna untuk menangani masalah sementara dan terminal seperti masalah jaringan, peningkatan partisi, atau migrasi.
PPCB berlaku dalam skenario berikut:
- Tingkat konsistensi apa pun
- Operasi dengan kunci partisi (baca/tulis titik data)
- Akun wilayah tulis tunggal dengan beberapa wilayah baca
- Beberapa akun wilayah tulis
Cara kerjanya
Transisi partisi melalui empat status - Sehat, Tidak Sehat Tentatif, Tidak Sehat, dan Sehat Tentatif - berdasarkan keberhasilan atau kegagalan permintaan:
- Pelacakan Kegagalan: SDK memantau tingkat kesalahan (misalnya, 5xx, 408) per partisi selama jendela satu menit. Kegagalan berturut-turut per partisi dilacak tanpa batas waktu oleh SDK.
- Menandai sebagai Tidak Tersedia: Jika partisi melebihi ambang batas yang dikonfigurasi, partisi ditandai sebagai Tentatif Tidak Sehat dan dikecualikan dari perutean selama 1 menit.
- Promosi ke Tidak Sehat atau Pemulihan: Jika upaya pemulihan gagal, partisi beralih ke Tidak Sehat. Setelah interval backoff, pemeriksaan Tentatif Sehat dibuat dengan permintaan waktu terbatas untuk menentukan pemulihan.
- Pemulihan: Jika pemeriksaan tentatif berhasil, partisi kembali ke Sehat. Jika tidak, itu tetap Tidak Sehat sampai pemeriksaan berikutnya.
Failover ini dikelola secara internal oleh SDK dan memastikan permintaan menghindari partisi bermasalah yang sudah diketahui sampai dipastikan sehat kembali.
Konfigurasi melalui variabel lingkungan
Anda dapat mengontrol perilaku PPCB menggunakan variabel lingkungan ini:
| Variabel | Description | Default |
|---|---|---|
AZURE_COSMOS_ENABLE_CIRCUIT_BREAKER |
Mengaktifkan/menonaktifkan PPCB | false |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_READ |
Kegagalan baca berturut-turut maksimum sebelum menandai partisi tidak tersedia | 10 |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_WRITE |
Jumlah kegagalan penulisan berturut-turut maksimum sebelum menandai partisi sebagai tidak tersedia | 5 |
AZURE_COSMOS_FAILURE_PERCENTAGE_TOLERATED |
Ambang persentase kegagalan sebelum menandai partisi tidak tersedia | 90 |
Tip
Opsi konfigurasi tambahan dapat tersedia dalam rilis mendatang untuk penyesuaian durasi waktu tunggu dan strategi mundur pemulihan.
Wilayah yang dikecualikan
Fitur wilayah yang dikecualikan memungkinkan kontrol terperinci atas perutean permintaan dengan memungkinkan Anda mengecualikan wilayah tertentu dari lokasi pilihan Anda berdasarkan per permintaan. Fitur ini tersedia di Azure Cosmos DB Python SDK versi 4.14.0 dan yang lebih tinggi.
Manfaat utama:
- Menangani pembatasan laju: Saat mengalami respons 429 (Terlalu Banyak Permintaan), secara otomatis merutekan permintaan ke wilayah alternatif dengan throughput yang tersedia
- Perutean yang ditargetkan: Pastikan permintaan dilayani dari wilayah tertentu dengan mengecualikan semua yang lain
- Melewati urutan pilihan: Mengambil alih daftar wilayah pilihan default untuk permintaan individual tanpa membuat klien terpisah
Configuration:
Wilayah yang dikecualikan dapat dikonfigurasi pada tingkat klien dan tingkat permintaan:
from azure.cosmos import CosmosClient
from azure.cosmos.partition_key import PartitionKey
# Configure preferred locations and excluded locations at client level
preferred_locations = ['West US 3', 'West US', 'East US 2']
excluded_locations_on_client = ['West US 3', 'West US']
client = CosmosClient(
url=HOST,
credential=MASTER_KEY,
preferred_locations=preferred_locations,
excluded_locations=excluded_locations_on_client
)
database = client.create_database('TestDB')
container = database.create_container(
id='TestContainer',
partition_key=PartitionKey(path="/pk")
)
# Create an item (writes ignore excluded_locations in single-region write accounts)
test_item = {
'id': 'Item_1',
'pk': 'PartitionKey_1',
'test_object': True,
'lastName': 'Smith'
}
created_item = container.create_item(test_item)
# Read operations will use preferred_locations minus excluded_locations
# In this example: ['West US 3', 'West US', 'East US 2'] - ['West US 3', 'West US'] = ['East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk']
)
Wilayah dikecualikan pada tingkat permintaan:
Wilayah yang dikecualikan pada tingkat permintaan mendapatkan prioritas tertinggi dan menggantikan pengaturan tingkat klien.
# Excluded locations can be specified per request, overriding client settings
excluded_locations_on_request = ['West US 3']
# Create item with request-level excluded regions
created_item = container.create_item(
test_item,
excluded_locations=excluded_locations_on_request
)
# Read with request-level excluded regions
# This will use: ['West US 3', 'West US', 'East US 2'] - ['West US 3'] = ['West US', 'East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk'],
excluded_locations=excluded_locations_on_request
)
Menyempurnakan konsistensi vs ketersediaan
Fitur wilayah yang dikecualikan menyediakan mekanisme tambahan untuk menyeimbangkan konsistensi dan trade-off ketersediaan dalam aplikasi Anda. Kemampuan ini sangat berharga dalam skenario dinamis di mana persyaratan dapat bergeser berdasarkan kondisi operasional:
Penanganan pemadaman dinamis: Ketika wilayah utama mengalami pemadaman dan ambang batas pemutus sirkuit tingkat partisi terbukti tidak mencukupi, wilayah yang dikecualikan memungkinkan failover segera tanpa perubahan kode atau mulai ulang aplikasi. Ini memberikan respons yang lebih cepat terhadap masalah regional dibandingkan dengan menunggu aktivasi pemutus sirkuit otomatis.
Preferensi konsistensi kondisional: Aplikasi dapat menerapkan strategi konsistensi yang berbeda berdasarkan status operasional:
- Status stabil: Prioritaskan bacaan yang konsisten dengan mengecualikan semua wilayah kecuali yang utama, memastikan konsistensi data dengan biaya potensial ketersediaan
- Skenario pemadaman: Mengutamakan ketersediaan daripada konsistensi yang ketat dengan memungkinkan perutean lintas wilayah, dengan menerima potensi keterlambatan data demi ketersediaan layanan berkelanjutan
Pendekatan ini memungkinkan mekanisme eksternal (seperti manajer lalu lintas atau load balancer) untuk mengatur keputusan failover sementara aplikasi mempertahankan kontrol atas persyaratan konsistensi melalui pola pengecualian wilayah.
Ketika semua wilayah dikecualikan, permintaan akan dirutekan ke wilayah utama/hub. Fitur ini berfungsi dengan semua jenis permintaan termasuk kueri dan sangat berguna untuk mempertahankan instans klien singleton sambil mencapai perilaku perutean yang fleksibel.
Penggunaan SDK
- Menginstal SDK terbaru
Azure Cosmos DB SDK terus ditingkatkan untuk memberikan performa terbaik. Lihat catatan rilis Azure Cosmos DB SDK untuk menentukan SDK terbaru dan meninjau peningkatan.
- Menggunakan klien database tunggal Azure Cosmos DB sepanjang siklus hidup aplikasi Anda
Setiap instans klien Azure Cosmos DB aman secara utas dan melakukan manajemen koneksi serta penyimpanan cache alamat yang efisien. Untuk memungkinkan manajemen koneksi yang efisien dan performa yang lebih baik oleh klien Azure Cosmos DB, disarankan untuk menggunakan satu instans klien Azure Cosmos DB selama masa pakai aplikasi.
- Menyetel konfigurasi batas waktu dan coba lagi
Konfigurasi waktu habis dan kebijakan coba lagi dapat disesuaikan berdasarkan kebutuhan aplikasi. Lihat dokumen konfigurasi timeout dan pengulangan untuk mendapatkan daftar lengkap konfigurasi yang dapat disesuaikan.
- Gunakan tingkat konsistensi terendah yang diperlukan untuk aplikasi Anda
Saat Anda membuat CosmosClient, konsistensi tingkat akun digunakan jika tidak ada yang ditentukan dalam pembuatan klien. Untuk informasi selengkapnya tentang tingkat konsistensi, lihat dokumen tingkat konsistensi .
- Meluaskan skala beban kerja klien Anda
Jika Anda menguji pada tingkat throughput yang tinggi, aplikasi klien mungkin menjadi hambatan karena mesin mencapai batas maksimum pada pemanfaatan CPU atau jaringan. Jika mencapai titik ini, Anda dapat terus mendorong akun Azure Cosmos DB lebih jauh dengan meluaskan skala aplikasi klien di beberapa server.
Aturan praktis yang baik adalah tidak melebihi >50% pemanfaatan CPU pada server tertentu untuk menjaga latensi tetap rendah.
- Batas Sumber Daya file Terbuka OS
Beberapa sistem Linux (seperti Red Hat) memiliki batas atas jumlah file yang terbuka dan juga jumlah koneksi. Jalankan yang berikut untuk melihat batas saat ini:
ulimit -a
Jumlah file terbuka (nofile) harus cukup besar untuk memiliki ruang yang cukup untuk ukuran kumpulan koneksi yang dikonfigurasi dan file terbuka lainnya oleh OS. Ini dapat dimodifikasi untuk memungkinkan ukuran kumpulan koneksi yang lebih besar.
Buka file limits.conf:
vim /etc/security/limits.conf
Tambahkan/modifikasi baris berikut:
* - nofile 100000
Operasi Query
Untuk operasi kueri, buka tips performa untuk kueri.
Kebijakan pengindeksan
- Mengecualikan jalur yang tidak digunakan dari pengindeksan untuk penulisan yang lebih cepat
Kebijakan pengindeksan Azure Cosmos DB memungkinkan Anda menentukan jalur dokumen mana yang akan disertakan atau dikecualikan dari pengindeksan dengan memanfaatkan Jalur Pengindeksan (setIncludedPaths dan setExcludedPaths). Penggunaan jalur pengindeksan dapat menawarkan performa tulis yang lebih baik dan penyimpanan indeks yang lebih rendah untuk skenario di mana pola kueri diketahui sebelumnya karena biaya pengindeksan secara langsung berkorelasi dengan jumlah jalur unik yang diindeks. Misalnya, kode berikut menunjukkan cara menyertakan dan mengecualikan seluruh bagian dokumen (juga dikenal sebagai subtree) dari pengindeksan menggunakan kartu bebas "*".
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Untuk informasi selengkapnya, lihat kebijakan pengindeksan Azure Cosmos DB.
Daya Tampung
- Ukur dan sesuaikan untuk penggunaan unit permintaan per detik yang lebih rendah
Azure Cosmos DB menawarkan set operasi database yang kaya termasuk kueri relasional dan hierarkis dengan UDF, prosedur tersimpan, dan pemicu – semuanya beroperasi pada dokumen dalam koleksi database. Biaya yang terkait dengan masing-masing operasi ini bervariasi berdasarkan CPU, IO, dan memori yang diperlukan untuk menyelesaikan operasi. Alih-alih memikirkan dan mengelola sumber daya perangkat keras, Anda dapat memikirkan unit permintaan (RU) sebagai ukuran tunggal untuk sumber daya yang diperlukan untuk melakukan berbagai operasi database dan melayani permintaan aplikasi.
Throughput disediakan berdasarkan jumlah unit permintaan yang ditetapkan untuk setiap kontainer. Konsumsi unit permintaan dievaluasi sebagai tarif per detik. Aplikasi yang melebihi tarif unit permintaan yang disediakan untuk kontainernya akan dibatasi hingga tarifnya turun di bawah tingkat yang disediakan untuk kontainer tersebut. Jika aplikasi Anda memerlukan tingkat throughput yang lebih tinggi, Anda dapat meningkatkan throughput dengan provisi unit permintaan tambahan.
Kompleksitas suatu kueri memengaruhi jumlah unit permintaan yang digunakan dalam sebuah operasi. Jumlah predikat, sifat predikat, jumlah UDF, dan ukuran set data sumber semuanya memengaruhi biaya operasi kueri.
Untuk mengukur overhead operasi apa pun (buat, perbarui, atau hapus), periksa header x-ms-request-charge untuk mengukur jumlah unit permintaan yang dikonsumsi oleh operasi ini.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
Biaya permintaan yang dikembalikan di header ini merupakan sebagian kecil dari kapasitas pemrosesan yang Anda tentukan. Misalnya, jika Anda memiliki 2000 RU/s yang disediakan dan jika kueri sebelumnya mengembalikan 1000 dokumen 1KB, biaya operasinya adalah 1000. Dengan demikian, dalam satu detik server hanya menerima dua permintaan seperti itu sebelum membatasi tarif permintaan selanjutnya. Untuk informasi selengkapnya, lihat Unit permintaan dan kalkulator unit permintaan.
- Tangani pembatasan laju/laju permintaan yang terlalu tinggi
Saat klien mencoba untuk melebihi throughput yang dicadangkan untuk sebuah akun, tidak ada penurunan kinerja di server dan tidak ada penggunaan kapasitas throughput di luar tingkat yang dicadangkan. Server akan terlebih dahulu mengakhiri permintaan dengan RequestRateTooLarge (kode status HTTP 429) dan mengembalikan header x-ms-retry-after-ms yang menunjukkan jumlah waktu, dalam milidetik, yang pengguna harus menunggu sebelum mencoba kembali permintaan tersebut.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK-SDK tersebut secara implisit menangani respons ini, mematuhi header coba-lagi yang ditentukan server, dan mengirim ulang permintaan. Kecuali akun Anda diakses secara bersamaan oleh beberapa klien, percobaan berikutnya akan berhasil.
Jika Anda memiliki lebih dari satu klien yang secara kumulatif beroperasi secara konsisten di atas tingkat permintaan, jumlah coba lagi default yang saat ini diatur ke 9 secara internal oleh klien mungkin tidak cukup; dalam hal ini, klien melempar CosmosHttpResponseError dengan kode status 429 ke aplikasi. Jumlah coba lagi default dapat diubah dengan meneruskan retry_total konfigurasi ke klien. Secara default, CosmosHttpResponseError dengan kode status 429 dikembalikan setelah waktu tunggu kumulatif 30 detik jika permintaan terus beroperasi di atas tingkat permintaan. Hal ini terjadi meskipun jumlah percobaan ulang saat ini kurang dari jumlah percobaan ulang maksimal, baik itu default 9 atau nilai yang ditentukan pengguna.
Meskipun perilaku percobaan ulang otomatis membantu meningkatkan ketahanan dan kegunaan untuk sebagian besar aplikasi, perilaku tersebut mungkin bertentangan saat melakukan tolok ukur performa, terutama saat mengukur latensi. Latensi yang diamati oleh klien akan melonjak jika eksperimen mencapai batas server dan menyebabkan SDK klien melakukan percobaan ulang tanpa pemberitahuan. Untuk menghindari lonjakan latensi selama eksperimen performa, ukur muatan yang dikembalikan oleh setiap operasi dan pastikan bahwa permintaan beroperasi di bawah tingkat permintaan yang telah dipesan. Untuk informasi selengkapnya, lihat Unit permintaan.
- Mendesain dokumen yang lebih kecil untuk throughput yang lebih tinggi
Biaya permintaan (biaya pemrosesan permintaan) dari operasi tertentu berkorelasi langsung dengan ukuran dokumen. Operasi pada dokumen besar lebih mahal daripada operasi untuk dokumen kecil. Idealnya, rancang aplikasi dan alur kerja Anda agar ukuran item Anda ~ 1KB, atau urutan atau besaran yang serupa. Untuk aplikasi yang sensitif terhadap latensi, item besar harus dihindari - dokumen multi-MB akan memperlambat aplikasi Anda.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang perancangan aplikasi Anda untuk skala dan kinerja tinggi, lihat Pemartisian dan penyekalaan di Azure Cosmos DB.
Mencoba melakukan perencanaan kapasitas untuk migrasi ke Azure Cosmos DB? Anda dapat menggunakan informasi tentang kluster database Anda yang ada saat ini untuk membuat perencanaan kapasitas.
- Jika Anda hanya mengetahui jumlah vCore dan server di kluster database yang ada, baca tentang memperkirakan unit permintaan menggunakan vCore atau vCPU
- Jika Anda mengetahui tingkat permintaan umum untuk beban kerja database Anda saat ini, baca tentang memperkirakan unit permintaan menggunakan perencana kapasitas Azure Cosmos DB