Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Azure Cosmos DB for PostgreSQL tidak lagi didukung untuk proyek baru. Jangan gunakan layanan ini untuk proyek baru. Sebagai gantinya, gunakan salah satu dari dua layanan ini:
Gunakan Azure Cosmos DB for NoSQL untuk solusi database terdistribusi yang dirancang untuk skenario skala tinggi dengan perjanjian tingkat layanan ketersediaan (SLA) 99,999%, skala otomatis instan, dan failover otomatis di beberapa wilayah.
Gunakan fitur Elastic Clusters dari Azure Database For PostgreSQL untuk PostgreSQL yang dipecah menggunakan ekstensi Citus sumber terbuka.
Memilih kolom distribusi setiap tabel adalah salah satu keputusan pemodelan yang paling penting yang Anda akan buat. Azure Cosmos DB for PostgreSQL menyimpan baris dalam pecahan berdasarkan nilai kolom distribusi baris.
Pilihan yang benar mengelompokkan data terkait bersama-sama pada simpul fisik yang sama, yang membuat kueri menjadi cepat dan menambahkan dukungan untuk semua fitur SQL. Pilihan yang salah membuat sistem berjalan lambat.
Tips umum
Berikut adalah empat kriteria untuk memilih kolom distribusi yang ideal untuk tabel terdistribusi Anda.
Pilih kolom yang merupakan bagian utama dalam beban kerja aplikasi.
Anda mungkin menganggap kolom ini sebagai "hati", "bagian tengah", atau "dimensi alami" untuk mempartisi data.
Contoh:
-
device_iddalam beban kerja IoT -
security_iduntuk aplikasi keuangan yang melacak sekuritas -
user_iddalam analitik pengguna -
tenant_iduntuk aplikasi SaaS multi-penyewa
-
Pilih kolom dengan kardinalitas yang layak, dan distribusi statistik yang merata.
Kolom harus memiliki banyak nilai, dan didistribusikan secara menyeluruh dan merata di antara semua pecahan.
Contoh:
- Kardinalitas lebih dari 1000
- Jangan memilih kolom yang memiliki nilai yang sama pada sebagian besar baris (kemiringan data)
- Dalam beban kerja SaaS, memiliki satu penyewa yang jauh lebih besar dari yang lain dapat menyebabkan kemiringan data. Untuk situasi ini, Anda dapat menggunakan isolasi penyewa untuk membuat pecahan khusus guna menangani penyewa.
Pilih kolom yang menguntungkan kueri Anda yang ada.
Untuk beban kerja transaksional atau operasional (di mana sebagian besar kueri hanya membutuhkan beberapa milidetik), pilih kolom yang muncul sebagai filter dalam klausa
WHEREuntuk setidaknya 80% kueri. Misalnya, kolomdevice_iddiSELECT * FROM events WHERE device_id=1.Untuk beban kerja analitis (di mana sebagian besar kueri membutuhkan waktu 1-2 detik), pilih kolom yang memungkinkan kueri diparalelkan di seluruh node pekerja. Misalnya, kolom yang sering muncul dalam klausa GROUP BY, atau mengkueri beberapa nilai sekaligus.
Pilih kolom yang ada di sebagian besar tabel besar.
Tabel yang lebih dari 50 GB harus didistribusikan. Memilih kolom distribusi yang sama untuk semuanya memungkinkan Anda menempatkan data bersama-sama untuk kolom tersebut pada simpul pekerja. Co-location membuatnya efisien untuk menjalankan JOIN dan rollup, serta menerapkan kunci asing.
Tabel lain (lebih kecil) dapat berupa tabel lokal atau referensi. Jika tabel yang lebih kecil perlu JOIN dengan tabel terdistribusi, buat tabel referensi.
Contoh kasus penggunaan
Kami telah melihat kriteria umum untuk memilih kolom distribusi. Sekarang mari kita lihat bagaimana penerapannya pada kasus penggunaan umum.
Aplikasi multipenyewa
Arsitektur multi-pengguna menggunakan bentuk pemodelan database hierarkis untuk mendistribusikan kueri melalui simpul dalam kluster. Bagian atas hierarki data dikenal sebagai ID penyewa dan perlu disimpan dalam kolom pada setiap tabel.
Azure Cosmos DB untuk PostgreSQL menginspeksi kueri untuk melihat tenant ID mana yang terlibat dan menemukan pecahan tabel yang sesuai. Ini merutekan kueri ke satu simpul pekerja yang berisi shard. Menjalankan kueri dengan semua data yang relevan ditempatkan pada simpul yang sama disebut kolokasi.
Diagram berikut ini mengilustrasikan kolokasi dalam model data multipenyewa. Diagram ini berisi dua tabel, Akun dan Kampanye, yang masing-masing didistribusikan oleh account_id. Kotak berbayang mewakili shard. Pecahan hijau disimpan bersama pada satu simpul pekerja, dan pecahan biru disimpan di simpul pekerja lain. Perhatikan bagaimana kueri gabungan antara Akun dan Campaigns memiliki semua data yang diperlukan bersama-sama pada satu simpul saat kedua tabel dibatasi ke id_akun yang sama.
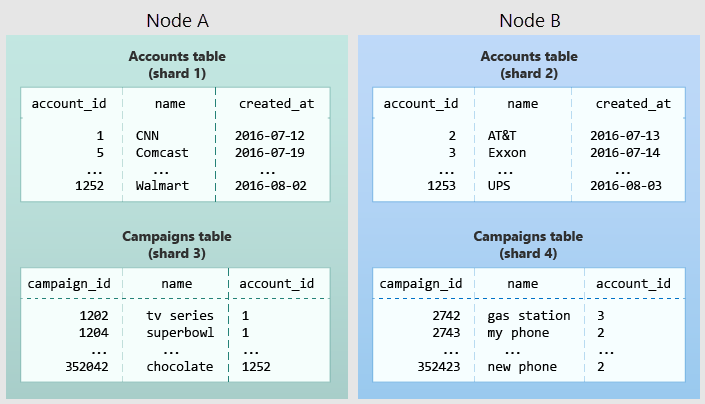
Untuk menerapkan desain ini dalam skema Anda sendiri, identifikasi apa yang merupakan penyewa dalam aplikasi Anda. Instans umum termasuk perusahaan, akun, organisasi, atau pelanggan. Nama kolom akan seperti company_id atau customer_id. Periksa setiap kueri Anda dan tanyakan pada diri Anda, apakah akan berhasil jika memiliki lebih banyak klausa WHERE untuk membatasi semua tabel yang terlibat ke baris dengan ID penyewa yang sama? Kueri dalam model multipenyewa dicakup ke penyewa. Misalnya, kueri tentang penjualan atau inventaris tercakup dalam toko tertentu.
Praktik terbaik
- Distribusikan tabel menurut kolom tenant_id yang umum. Misalnya, dalam aplikasi SaaS yang mana penyewa adalah perusahaan, tenant_id kemungkinan adalah company_id.
- Konversi tabel lintas penyewa kecil menjadi tabel referensi. Saat beberapa penyewa berbagi tabel informasi kecil, distribusikan sebagai tabel referensi.
- Batasi filter semua kueri aplikasi menurut tenant_id. Setiap kueri harus meminta informasi untuk satu penyewa sekaligus.
Baca tutorial multipenyewa untuk contoh cara membangun aplikasi semacam ini.
Aplikasi waktu nyata
Arsitektur multipenyewa memperkenalkan struktur hierarki dan menggunakan kolokasi data untuk merutekan kueri per penyewa. Sebaliknya, arsitektur real-time bergantung pada properti distribusi tertentu dari data mereka untuk mencapai pemrosesan yang sangat paralel.
Kami menggunakan "ID entitas" sebagai istilah untuk kolom distribusi dalam model real-time. Entitas umum adalah pengguna, host, atau perangkat.
Kueri real-time biasanya meminta agregat numerik yang dikelompokkan menurut tanggal atau kategori. Azure Cosmos DB for PostgreSQL mengirimkan kueri ini ke setiap shard untuk hasil parsial dan menyusun jawaban akhir pada simpul koordinator. Kueri berjalan paling cepat ketika sebanyak mungkin node berkontribusi, dan saat tidak ada satu node pun yang harus menanggung beban pekerjaan yang tidak seimbang.
Praktik terbaik
- Pilih kolom dengan kardinalitas tinggi sebagai kolom distribusi. Sebagai perbandingan, bidang Status pada tabel pesanan dengan nilai Baru, Berbayar, dan Dikirim adalah pilihan kolom distribusi yang buruk. Ini hanya mengasumsikan beberapa nilai, yang membatasi jumlah shard yang dapat menyimpan data, dan jumlah simpul yang dapat memprosesnya. Di antara kolom dengan kardinalitas tinggi, ada baiknya juga memilih kolom-kolom yang sering digunakan dalam klausa kelompok demi atau sebagai kunci gabungan.
- Pilih kolom dengan distribusi merata. Jika Anda mendistribusikan tabel pada kolom yang condong ke nilai umum tertentu, data dalam tabel cenderung terakumulasi dalam shard tertentu. Simpul yang menahan shard tersebut akhirnya melakukan lebih banyak pekerjaan daripada simpul lainnya.
- Distribusikan tabel fakta dan dimensi pada kolom umumnya. Tabel fakta Anda hanya dapat memiliki satu kunci distribusi. Tabel yang menggunakan kunci lain tidak akan ditempatkan bersama dengan tabel fakta. Pilih satu dimensi untuk dikolokasi berdasarkan seberapa sering digabungkan dan ukuran baris gabungan.
- Ubah beberapa tabel dimensi menjadi tabel referensi. Jika tabel dimensi tidak dapat dikolokasi dengan tabel fakta, Anda dapat meningkatkan kinerja kueri dengan mendistribusikan salinan tabel dimensi ke semua node dalam bentuk tabel referensi.
Baca tutorial dasbor real-time untuk contoh cara membangun aplikasi semacam ini.
Data rangkaian waktu
Dalam beban kerja rangkaian waktu, aplikasi meminta informasi terbaru saat mereka mengarsipkan informasi lama.
Kesalahan paling umum dalam pemodelan informasi rangkaian waktu di Azure Cosmos DB for PostgreSQL adalah menggunakan tanda waktu itu sendiri sebagai kolom distribusi. Distribusi hash berdasarkan waktu mendistribusikan waktu secara acak ke dalam shard-shard berbeda, bukannya menjaga rentang waktu tetap bersama dalam satu shard. Kueri yang melibatkan rentang waktu umumnya referensi waktu, misalnya, data terbaru. Jenis distribusi hash ini menyebabkan overhead jaringan.
Praktik terbaik
- Jangan pilih tanda waktu sebagai kolom distribusi. Pilih kolom distribusi yang berbeda. Di aplikasi multipenyewa, gunakan ID penyewa, atau dalam aplikasi real-time gunakan ID entitas.
- Gunakan partisi tabel PostgreSQL untuk waktu sebagai gantinya. Gunakan partisi tabel untuk memecah tabel besar data yang diurutkan waktu menjadi beberapa tabel yang diwariskan dengan setiap tabel yang berisi rentang waktu yang berbeda. Mendistribusikan tabel yang dipartisi Postgres membuat pecahan untuk tabel yang diwariskan.
Langkah berikutnya
- Pelajari bagaimana kolokasi antara data terdistribusi membantu kueri berjalan cepat.
- Temukan kolom distribusi tabel terdistribusi, dan kueri diagnostik berguna lainnya.