Format parquet di Azure Data Factory dan Azure Synapse Analytics
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Ikuti artikel ini saat Anda ingin memilah file Parquet atau menulis data ke dalam format Parquet.
Format parquet didukung untuk konektor berikut:
- Amazon S3
- Penyimpanan yang Kompatibel dengan Amazon S3
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Sistem File
- FTP
- Penyimpanan Cloud Google
- HDFS
- HTTP
- Penyimpanan Cloud Oracle
- SFTP
Untuk daftar fitur yang didukung untuk semua konektor yang tersedia, lihat artikel Gambaran Umum Konektor.
Menggunakan Integration Runtime yang Dihost Sendiri
Penting
Untuk salinan yang diberdayakan oleh Microsoft Integration Runtime yang Dihost Sendiri, misalnya antara penyimpanan data lokal dan cloud, jika Anda tidak menyalin file Parquet apa adanya, Anda perlu menginstal 64-bit JRE 8 (Java Runtime Environment) atau OpenJDK di mesin runtime integrasi Anda. Periksa paragraf berikut dengan detail selengkapnya.
Untuk penyalinan yang berjalan pada runtime integrasi yang Dihosting sendiri dengan serialisasi/deserialisasi file Parquet, layanan mencari runtime Java dengan terlebih dahulu memeriksa registri (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) untuk JRE, jika tidak ditemukan, kedua memeriksa variabel sistem JAVA_HOME untuk OpenJDK.
- Untuk menggunakan JRE: IR 64-bit membutuhkan JRE 64-bit. Anda dapat menemukannya dari sini.
- Untuk menggunakan OpenJDK: Ini didukung sejak Runtime integrasi versi 3.13. Paketkan jvm.dll dengan semua rakitan OpenJDK lain yang diperlukan ke dalam mesin IR yang dihost Sendiri, dan atur variabel lingkungan sistem JAVA_HOME yang sesuai, lalu mulai ulang IR yang di-host Sendiri agar segera berlaku.
Tip
Jika Anda menyalin data ke/dari format Parquet menggunakan Integration Runtime yang Dihost sendiri dan menekan kesalahan yang mengatakan "Kesalahan terjadi saat memanggil java, pesan: java.lang.OutOfMemoryError:Java heap space", Anda dapat menambahkan variabel lingkungan _JAVA_OPTIONS di mesin yang meng-host IR yang dihost sendiri untuk menyesuaikan ukuran timbunan min/maks agar JVM memberdayakan salinan tersebut, lalu eksekusi ulang alur.
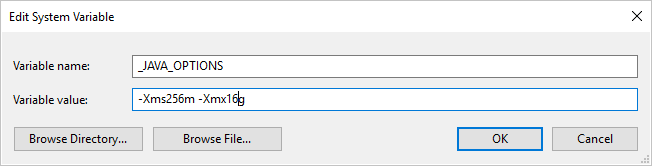
Contoh: atur variabel _JAVA_OPTIONS dengan nilai -Xms256m -Xmx16g. Bendera Xms menentukan kumpulan alokasi memori awal untuk Java Virtual Machine (JVM), sedangkan Xmx menentukan kumpulan alokasi memori maksimum. Ini berarti bahwa JVM akan dimulai dengan jumlah memori Xms dan akan dapat menggunakan jumlah memori maksimum Xmx. Secara default, layanan menggunakan min 64 MB dan maks 1G.
Properti himpunan data
Untuk daftar lengkap bagian dan properti yang tersedia untuk menentukan himpunan data, lihat artikel Himpunan Data. Bagian ini menyediakan daftar properti yang didukung oleh himpunan data Parquet.
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis himpunan data harus diatur ke Parquet. | Ya |
| lokasi | Pengaturan lokasi file. Tiap konektor berbasis file memiliki jenis lokasinya sendiri dan properti yang didukung di location. Lihat detail di artikel konektor -> Bagian properti himpunan data. |
Ya |
| compressionCodec | Codec pemadatan yang digunakan saat menulis ke file Parquet. Saat membaca dari file Parquet, Data Factory secara otomatis menentukan codec pemadatan berdasarkan metadata file. Jenis yang didukung adalah "none", "gzip", "snappy" (default), dan "lzo". Saat ini aktivitas Salin tidak mendukung LZO ketika membaca/menulis file Parquet. |
No |
Catatan
Spasi kosong dalam nama kolom tidak didukung untuk file Parquet.
Di bawah ini adalah contoh himpunan data Parquet di Azure Blob Storage:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Properti aktivitas salin
Untuk daftar lengkap bagian dan properti yang tersedia untuk menentukan aktivitas, lihat artikel Alur. Bagian ini menyediakan daftar properti yang didukung oleh sumber dan sink Parquet.
Parquet sebagai sumber
Properti berikut didukung di bagian *sumber* aktivitas salin.
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis sumber aktivitas salin harus diatur ke ParquetSource. | Ya |
| storeSettings | Grup berbagai properti tentang cara membaca data dari penyimpanan data. Setiap konektor berbasis file memiliki pengaturan baca yang didukung sendiri di bagian storeSettings. Lihat detail di artikel konektor -> Bagian properti aktivitas salin. |
No |
Parquet sebagai sink
Properti berikut ini didukung di bagian sink aktivitas salin.
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis sink aktivitas salin harus diatur ke ParquetSink. | Ya |
| formatSettings | Grup properti. Lihat tabel pengaturan tulis Parquet di bawah ini. | No |
| storeSettings | Grup properti tentang cara menulis data ke penyimpanan data. Setiap konektor berbasis file memiliki pengaturan tulis tersendiri yang didukung pada storeSettings. Lihat detail di artikel konektor -> Bagian properti aktivitas salin. |
No |
Pengaturan tulis Parquet yang didukung di bawah formatSettings:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Jenis formatSettings harus diatur ke ParquetWriteSettings. | Ya |
| maxRowsPerFile | Saat menulis data ke dalam folder, Anda dapat memilih untuk menulis ke beberapa file dan menentukan baris maksimal per file. | No |
| fileNamePrefix | Berlaku ketika maxRowsPerFile dikonfigurasi.Menentukan awalan nama file saat menulis data ke beberapa file, menghasilkan pola ini: <fileNamePrefix>_00000.<fileExtension>. Jika tidak ditentukan, awalan nama file akan dibuat secara otomatis. Properti ini tidak berlaku ketika sumber adalah penyimpanan berbasis file atau penyimpanan data dengan dukungan opsi partisi. |
No |
Properti pemetaan aliran data
Dalam memetakan aliran data, Anda dapat membaca dan menulis ke format parquet di penyimpanan data berikut: Azure Blob Storage, Azure Data Lake Storage Gen1, dan Azure Data Lake Storage Gen2 dan SFTP. Anda dapat membaca format parquet di Amazon S3.
Properti sumber
Tabel di bawah ini mencantumkan properti yang didukung oleh sumber parquet. Anda bisa mengedit properti ini di tab opsi Sumber.
| Nama | Deskripsi | Wajib diisi | Nilai yang diizinkan | Properti skrip aliran data |
|---|---|---|---|---|
| Format | Format harus berupa parquet |
yes | parquet |
format |
| Jalur wild card | Semua file yang cocok dengan jalur kartubebas akan diproses. Mengambil alih jalur folder dan file yang diatur dalam himpunan data. | no | Tali[] | wildcardPaths |
| Jalur akar partisi | Untuk data file yang dipartisi, Anda dapat memasukkan jalur akar partisi untuk membaca folder yang dipartisi sebagai kolom | no | String | partitionRootPath |
| Daftar file | Apakah sumber Anda mengarah ke file teks yang mencantumkan file untuk diproses | no | true atau false |
fileList |
| Kolom untuk menyimpan nama file | Membuat kolom baru dengan jalur dan nama file sumber | no | String | rowUrlColumn |
| Setelah selesai | Hapus atau pindahkan file setelah diproses. Jalur file dimulai dari akar kontainer | no | Hapus: true atau false Pindah: [<from>, <to>] |
purgeFiles moveFiles |
| Filter menurut terakhir diubah | Pilih untuk memfilter file berdasarkan waktu terakhir file tersebut diubah | no | Tanda Waktu | modifiedAfter modifiedBefore |
| Izinkan file tidak ditemukan | Jika true, kesalahan tidak akan ditampilkan jika tidak ditemukan file | no | true atau false |
ignoreNoFilesFound |
Contoh sumber
Gambar di bawah ini adalah contoh konfigurasi sumber parquet dalam pemetaan aliran data.
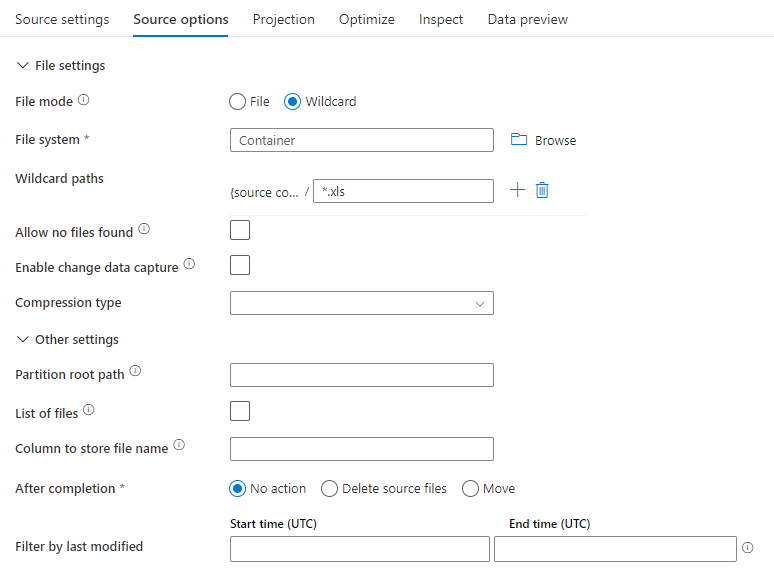
Skrip aliran data terkait adalah:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Properti sink
Tabel di bawah ini mencantumkan properti yang didukung oleh sink parquet. Anda dapat mengedit properti ini di tab Pengaturan.
| Nama | Deskripsi | Wajib diisi | Nilai yang diizinkan | Properti skrip aliran data |
|---|---|---|---|---|
| Format | Format harus berupa parquet |
yes | parquet |
format |
| Menghapus folder | Jika folder tujuan dibersihkan sebelum menulis | no | true atau false |
Memotong |
| Opsi nama file | Format penamaan data yang ditulis. Secara default, satu file per partisi dalam format part-#####-tid-<guid> |
no | Pola: String Per partisi: String[] Sebagai data dalam kolom: String Output ke satu file: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Contoh sink
Gambar di bawah ini adalah contoh konfigurasi sink parquet dalam pemetaan aliran data.
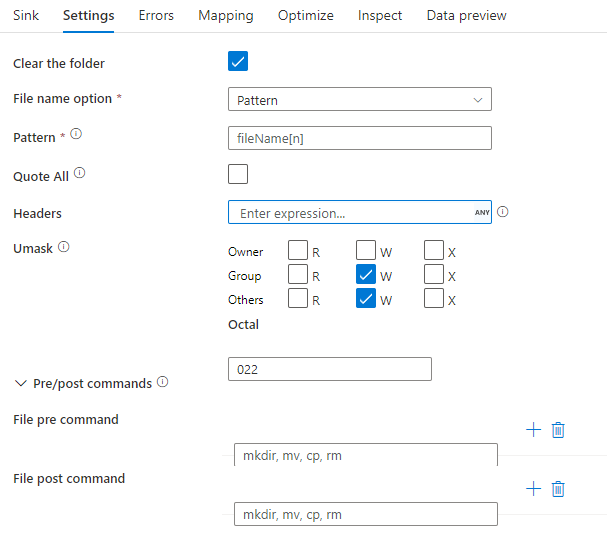
Skrip aliran data terkait adalah:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Dukungan jenis data
Jenis data kompleks parquet (misalnya MAP, LIST, STRUCT) saat ini hanya didukung di Aliran Data, bukan di Aktivitas Salin. Untuk menggunakan jenis kompleks dalam aliran data, jangan impor skema file dalam himpunan data, biarkan skema kosong di himpunan data. Kemudian, dalam transformasi Sumber, impor proyeksi.
Konten terkait
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk