Fitur optimalisasi performa aktivitas penyalinan
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Artikel ini menguraikan fitur pengoptimalan performa aktivitas penyalinan yang dapat Anda manfaatkan di alur Azure Data Factory dan Synapse.
Mengonfigurasi fitur performa dengan UI
Saat Anda memilih aktivitas Salin di kanvas editor alur dan pilih tab Pengaturan di area konfigurasi aktivitas di bawah kanvas, Anda akan melihat opsi untuk mengonfigurasi semua fitur performa yang dijelaskan di bawah ini.
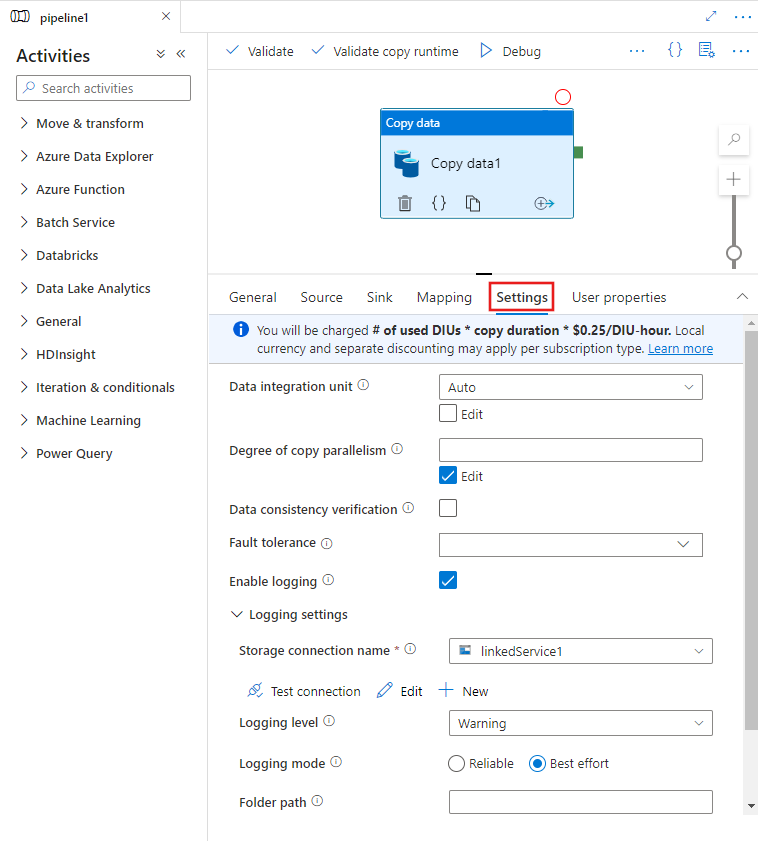
Unit Integrasi Data
Unit Integrasi Data adalah pengukuran yang mewakili daya (kombinasi CPU, memori, dan alokasi sumber daya jaringan) dari satu unit dalam layanan. Unit Integrasi Data hanya berlaku untuk runtime integrasi Azure, tetapi bukan runtime integrasi yang dihost sendiri.
DIU yang diizinkan untuk memberdayakan eksekusi aktivitas salin adalah antara 4 dan 256. Jika tidak ditentukan atau Anda memilih "Otomatis" pada antarmuka pengguna, secara dinamis layanan menerapkan pengaturan DIU optimal berdasarkan pasangan sink sumber dan pola data Anda. Tabel berikut ini mencantumkan rentang DIU yang didukung dan perilaku default dalam skenario salin yang berbeda:
| Skenario salin | Rentang DIU yang didukung | DMU default ditentukan oleh layanan |
|---|---|---|
| Di antara penyimpanan file | - Salin dari atau ke file tunggal: 4 - Salin dari dan ke beberapa file: 4-256 tergantung pada jumlah dan ukuran file Misalnya, jika Anda menyalin data dari folder dengan 4 file besar dan memilih untuk mempertahankan hierarki, DIU maksimum yang efektif adalah 16; ketika Anda memilih untuk menggabungkan file, DIU maksimum yang efektif adalah 4. |
Antara 4 dan 32 bergantung pada jumlah dan ukuran file |
| Dari penyimpanan file ke penyimpanan non-file | - Salin dari satu file: 4 - Salin dari beberapa file: 4-256 tergantung pada jumlah dan ukuran file Misalnya, jika Anda menyalin data dari folder dengan 4 file besar, DIU maksimum yang efektif adalah 16. |
- Salin ke Azure SQL Database atau Azure Cosmos DB: antara 4 dan 16 bergantung pada tingkat sink (DTU/RU) dan pola file sumber - Salin ke Azure Synapse Analytics menggunakan pernyataan PolyBase atau COPY: 2 - Skenario lain: 4 |
| Dari penyimpanan non-file ke penyimpanan file | - Salin dari penyimpanan data yang mendukung opsi partisi (termasuk Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server, dan Teradata): 4-256 saat menulis ke folder, dan 4 saat menulis ke satu file. Catatan per partisi data sumber dapat menggunakan hingga 4 DIU. - Skenario lain: 4 |
- Salin dari REST atau HTTP: 1 - Salin dari Amazon Redshift menggunakan UNLOAD: 4 - Skenario lain: 4 |
| Antara penyimpanan non-file | - Salin dari penyimpanan data yang mendukung opsi partisi (termasuk Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server, dan Teradata): 4-256 saat menulis ke folder, dan 4 saat menulis ke satu file. Catatan per partisi data sumber dapat menggunakan hingga 4 DIU. - Skenario lain: 4 |
- Salin dari REST atau HTTP: 1 - Skenario lain: 4 |
Anda dapat melihat DIU yang digunakan untuk setiap salinan yang dijalankan dalam tampilan pemantauan aktivitas salin atau output aktivitas. Untuk informasi selengkapnya, lihat Pemantauan aktivitas salin. Untuk mengambil alih default ini, tentukan nilai properti dataIntegrationUnits sebagai berikut. Jumlah aktual DIU yang digunakan operasi salin selama durasi sama dengan atau kurang dari nilai yang dikonfigurasi, bergantung pada pola data Anda.
Anda akan dikenakan biaya # dari DIU yang digunakan durasi salin harga satuan/DIU-jam. Lihat harga saat ini di sini. Mata uang lokal dan diskon terpisah mungkin berlaku per jenis langganan.
Contoh:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Skalabilitas runtime integrasi yang dihost sendiri
Jika Anda ingin mencapai throughput yang lebih tinggi, Anda dapat meningkatkan atau memeperluas skala runtime integrasi yang dihost sendiri:
- Jika CPU dan memori yang tersedia pada node runtime integrasi yang dihost sendiri tidak sepenuhnya digunakan, tetapi eksekusi pekerjaan bersamaan mencapai batas, Anda harus meningkatkan skala dengan meningkatkan jumlah pekerjaan bersamaan yang dapat berjalan pada node. Lihat di sini untuk instruksinya.
- Jika di sisi lain, CPU tinggi pada node runtime integrasi yang Dihost sendiri atau memori yang tersedia sedikit, Anda dapat menambahkan node baru untuk membantu peluasan skala beban di beberapa node. Lihat di sini untuk instruksinya.
Perhatikan dalam skenario berikut, eksekusi aktivitas salin tunggal dapat memanfaatkan beberapa node runtime integrasi yang Dihost sendiri:
- Salin data dari penyimpanan berbasis file, bergantung pada jumlah dan ukuran file.
- Salin data dari penyimpanan data yang mendukung opsi partisi (termasuk Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP Hana, SAP Open Hub, SAP Table, SQL Server, dan Teradata), bergantung pada jumlah partisi data.
Salinan paralel
Anda dapat menetapkan salinan paralel (properti parallelCopies dalam definisi JSON aktivitas Salin, atau pengaturan Degree of parallelism di tab Pengaturan properti aktivitas Salin dalam antarmuka pengguna) pada aktivitas salin untuk menunjukkan paralelisme yang Anda inginkan untuk digunakan oleh aktivitas salin. Anda dapat menganggap properti ini sebagai jumlah maksimum utas dalam aktivitas salin yang dapat membaca dari sumber Anda atau menulis ke penyimpanan data sink Anda secara paralel.
Salinan paralel bersifat ortogonal ke Unit Integrasi Data atau node runtime integrasi yang Dihost sendiri. Hal ini dihitung di semua DIU atau node runtime integrasi yang Dihost sendiri.
Untuk setiap eksekusi aktivitas penyalinan, secara default dan dinamis layanan akan menerapkan pengaturan salinan paralel yang optimal berdasarkan pasangan sink sumber dan pola data Anda.
Tip
Perilaku default salinan paralel biasanya memberi Anda throughput terbaik, yang ditentukan secara otomatis oleh layanan berdasarkan pasangan sink sumber, pola data, dan jumlah DIU atau jumlah CPU/memori/simpul runtime integrasi yang dihost sendiri. Lihat Memecahkan masalah kinerja aktivitas salin tentang kapan harus menyetel salinan paralel.
Tabel berikut ini mencantumkan perilaku salin paralel:
| Skenario salin | Perilaku salinan paralel |
|---|---|
| Di antara penyimpanan file | parallelCopies menentukan paralelisme di tingkat file. Potongan dalam setiap file terjadi di bawahnya secara otomatis dan transparan. Hal ini dirancang untuk menggunakan ukuran potongan yang paling cocok untuk jenis penyimpanan data tertentu untuk memuat data secara paralel. Jumlah aktual salinan paralel yang aktivitas salin gunakan pada waktu proses tidak lebih dari jumlah file yang Anda miliki. Jika perilaku salin mergeFile ke sink file, aktivitas salin tidak dapat memanfaatkan paralelisme tingkat file. |
| Dari penyimpanan file ke penyimpanan non-file | - Saat menyalin data ke Azure SQL Database atau Azure Cosmos DB, salinan paralel default juga bergantung pada tingkat sink (jumlah DTU/RU). - Saat menyalin data ke Tabel Azure, salinan paralel default adalah 4. |
| Dari penyimpanan non-file ke penyimpanan file | - Saat menyalin data dari penyimpanan data yang diaktifkan opsi partisi (termasuk Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP Hana, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server dan Teradata), salinan paralel default adalah 4. Jumlah aktual salinan paralel yang aktivitas salin gunakan selama durasi tidak lebih dari jumlah pastisi data yang Anda miliki. Saat menggunakan Integration Runtime yang dihost sendiri dan menyalin ke Azure Blob/ADLS Gen2, perhatikan salinan paralel maksimum yang efektif adalah 4 atau 5 per node runtime integrasi. - Untuk skenario lain, salinan paralel tidak berlaku. Bahkan jika paralelisme ditentukan, salinan parales tersebut tidak diterapkan. |
| Antara penyimpanan non-file | - Saat menyalin data ke Azure SQL Database atau Azure Cosmos DB, salinan paralel default juga bergantung pada tingkat sink (jumlah DTU/RU). - Saat menyalin data dari penyimpanan data yang diaktifkan opsi partisi (termasuk Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP Hana, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server dan Teradata), salinan paralel default adalah 4. - Saat menyalin data ke Tabel Azure, salinan paralel default adalah 4. |
Untuk mengontrol beban pada komputer yang menghosting penyimpanan data Anda, atau untuk menyelaraskan kinerja salin, Anda dapat memilih untuk mengambil alih nilai default dan menentukan nilai untuk properti parallelCopies. Nilai harus berupa bilangan bulat yang lebih besar atau sama dengan 1. Selama durasi, untuk kinerja terbaik, aktivitas salin menggunakan nilai yang kurang dari atau sama dengan nilai yang Anda tetapkan.
Saat Anda menentukan nilai untuk properti parallelCopies, perhitungkan peningkatan beban pada penyimpanan data sumber dan sink data Anda. Pertimbangkan juga peningkatan beban ke runtime integrasi yang dihost sendiri jika aktivitas salin diberdayakan oleh hal tersebut. Peningkatan beban terjadi terutama ketika Anda memiliki beberapa kegiatan atau menjalankan bersamaan dari aktivitas yang sama yang berjalan terhadap penyimpanan data yang sama. Jika Anda melihat bahwa penyimpanan data atau runtime integrasi yang dihost sendiri kewalahan dengan beban, kurangi nilai parallelCopies untuk meringankan beban.
Contoh:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Salinan yang dipentaskan
Saat Anda menyalin data dari penyimpanan data sumber ke penyimpanan data sink, Anda mungkin memilih untuk menggunakan penyimpanan Azure Blob atau Azure Data Lake Storage Gen2 sebagai penyimpanan penahapan sementara. Pementasan sangat berguna dalam kasus-kasus berikut:
- Anda ingin menyerap data dari berbagai penyimpanan data ke Azure Synapse Analytics melalui PolyBase, menyalin data dari/ke Snowflake, atau menyerap data dari Amazon Redshift/HDFS secara berkinerja. Pelajari detail selengkapnya dari:
- Anda tidak ingin membuka port selain port 80 dan port 443 di firewall Anda, karena kebijakan IT perusahaan. Misalnya, saat Anda menyalin data dari penyimpanan data lokal ke Azure SQL Database atau Azure Synapse Analytics, Anda perlu mengaktifkan komunikasi TCP keluar pada port 1433 untuk firewall Windows dan firewall perusahaan Anda. Dalam skenario ini, salinan bertahap dapat memanfaatkan runtime integrasi yang dihost sendiri untuk menyalin data terlebih dahulu ke penyimpanan penahapan melalui HTTP atau HTTPS pada port 443, lalu memuat data dari penahapan ke SQL Database atau Azure Synapse Analytics. Dalam aliran ini, Anda tidak perlu mengaktifkan port 1433.
- Terkadang perlu beberapa saat untuk melakukan permindahan data hibrid (yaitu, untuk menyalin antara penyimpanan data lokal dan penyimpanan data cloud) melalui koneksi jaringan yang lambat. Untuk meningkatkan kinerja, Anda dapat menggunakan salinan bertahap untuk mengkompresi data lokal sehingga membutuhkan lebih sedikit waktu untuk memindahkan data ke penyimpanan data penahapan di cloud. Kemudian Anda dapat mendekompresi data di penyimpanan penahapan sebelum Anda memuatnya ke penyimpanan data tujuan.
Cara kerja salin terpentaskan
Saat Anda mengaktifkan fitur penahapan, pertama data disalin dari penyimpanan data sumber ke penyimpanan penahapan (bawa Azure Blob atau Azure Data Lake Storage Gen2 Anda sendiri). Selanjutnya, data disalin dari penyimpanan data penahapan ke penyimpanan data sink. Aktivitas penyalinan secara otomatis mengelola alur dua tahap untuk Anda, dan juga membersihkan data sementara dari penyimpanan penahapan setelah pemindahan data selesai.

Anda perlu memberikan izin penghapusan ke Azure Data Factory di penyimpanan penahapan Anda, sehingga data sementara dapat dibersihkan setelah aktivitas salin berjalan.
Saat Anda mengaktifkan pemindahan data dengan menggunakan penyimpanan penahapan, Anda dapat menentukan apakah Anda ingin data dikompresi sebelum memindahkan data dari penyimpanan data sumber ke penyimpanan data sementara atau penahapan lalu didekompresi sebelum memindahkan data dari penyimpanan data sementara atau penahapan ke penyimpanan data sink.
Saat ini, Anda tidak dapat menyalin data antara dua penyimpanan data yang terhubung melalui IR yang dihost sendiri yang berbeda, baik dengan maupun tanpa salinan bertahap. Untuk skenario tersebut, Anda dapat mengonfigurasi dua aktivitas salin berantai secara eksplisit untuk disalin dari sumber ke penahapan kemudian dari penahapan ke sink.
Konfigurasi
Konfigurasikan pengaturan enableStaging di aktivitas salin untuk menentukan apakah Anda ingin data untuk dibuat tahapannya di penyimpanan Blob sebelum Anda memuatnya ke penyimpanan data tujuan. Saat Anda mengatur enableStaging ke TRUE, tentukan properti tambahan yang tercantum di tabel berikutnya.
| Properti | Deskripsi | Nilai default | Wajib |
|---|---|---|---|
| enableStaging | Tentukan apakah Anda ingin menyalin data melalui penyimpanan pementasan sementara. | Salah | No |
| linkedServiceName | Tentukan nama layanan tertaut penyimpanan Azure Blob atauAzure Data Lake Storage Gen2, yang mengacu pada instans Penyimpanan yang Anda gunakan sebagai penyimpanan penahapan sementara. | T/A | Ya, saat enableStaging diatur ke TRUE |
| jalan | Tentukan jalur yang Anda inginkan untuk menyimpan data bertahap. Jika Anda tidak menyediakan jalur, layanan akan membuat kontainer untuk menyimpan data sementara. | T/A | Tidak (Ya saat storageIntegration di konektor Snowflake ditentukan) |
| enableCompression | Tentukan apakah data harus dikompresi sebelum disalin ke tujuan. Pengaturan ini mengurangi volume data yang ditransfer. | Salah | No |
Catatan
Jika Anda menggunakan salinan bertahap dengan kompresi diaktifkan, autentikasi utama layanan atau MSI untuk layanan tertaut blob bertahap tidak didukung.
Berikut ini sampel definisi aktivitas salin dengan properti yang dijelaskan dalam tabel sebelumnya:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Dampak penagihan salinan bertahap
Anda dikenakan biaya berdasarkan dua langkah: durasi salin dan jenis salin.
- Saat Anda menggunakan penahapan selama salinan cloud, yaitu menyalin data dari penyimpanan data cloud ke penyimpanan data cloud lain, kedua tahap yang diberdayakan oleh runtime integrasi Azure, Anda dikenakan biaya [jumlah durasi salin untuk langkah 1 dan langkah 2] x [harga satuan salinan cloud].
- Saat Anda menggunakan penahapan selama salinan hibrid, yang menyalin data dari penyimpanan data lokal ke penyimpanan data cloud, satu tahap diberdayakan oleh runtime integrasi yang dihost sendiri, Anda dikenakan biaya untuk [durasi salinan hibrid] x [harga satuan salinan hibrid] + [durasi salinan cloud] x [harga satuan salinan cloud].
Konten terkait
Lihat artikel aktivitas salin lainnya:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk