Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk / Saran
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Jika Anda baru menggunakan Azure Data Factory, lihat Introduction ke Azure Data Factory.
Dalam tutorial ini, Anda menggunakan kanvas aliran data untuk membuat aliran data yang memungkinkan Anda menganalisis dan mengubah data di Azure Data Lake Storage (ADLS) Gen2 dan menyimpannya di Delta Lake.
Prasyarat
- langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun Azure free sebelum Memulai.
- akun penyimpanan Azure. Anda menggunakan penyimpanan ADLS sebagai penyimpanan data sumber dan penyimpanan data tujuan. Jika Anda tidak memiliki akun penyimpanan, lihat Buat akun penyimpanan Azure untuk langkah-langkah membuatnya.
File yang kita ubah dalam tutorial ini adalah MoviesDB.csv, yang dapat ditemukan di sini. Untuk mengambil file dari GitHub, salin konten ke editor teks pilihan Anda untuk disimpan secara lokal sebagai file .csv. Untuk mengunggah file ke akun penyimpanan Anda, lihat Muat blob dengan portal Azure. Contohnya adalah mereferensikan kontainer bernama 'sample-data'.
Membuat pabrik data
Dalam langkah ini, Anda membuat pabrik data dan membuka antarmuka pengguna Azure Data Factory untuk membuat alur kerja di pabrik data.
Buka Microsoft Edge atau Chrome. Saat ini, UI Data Factory hanya didukung di browser web Microsoft Edge dan Google Chrome.
Di menu sebelah kiri, pilih Buat sumber daya>Integration>Data Factory
Pada halaman Pabrik data baru , di bawah Nama, masukkan ADFTutorialDataFactory
Pilih Azure subscription tempat Anda ingin membuat pabrik data.
Untuk Grup Sumber Daya, lakukan salah satu langkah berikut:
sebuah. Pilih Gunakan yang sudah ada, dan pilih grup sumber daya yang sudah ada dari daftar drop-down.
b. Pilih Buat baru, dan masukkan nama grup sumber daya.
Untuk mempelajari tentang grup sumber daya, lihat Gunakan grup sumber daya untuk mengelola sumber daya Azure Anda.
Di bawah Versi, pilih V2.
Di bawah Lokasi, pilih lokasi untuk pabrik data. Hanya lokasi yang didukung yang ditampilkan di daftar drop-down. Penyimpanan data (misalnya, Azure Storage dan SQL Database) dan komputasi (misalnya, Azure HDInsight) yang digunakan oleh pabrik data dapat berada di wilayah lain.
Pilih Buat.
Setelah pembuatan selesai, Anda akan melihat pemberitahuan di pusat Pemberitahuan. Pilih Buka sumber daya untuk menavigasi ke halaman Pabrik data.
Pilih Penulis & Pantau untuk meluncurkan UI Data Factory di tab terpisah.
Buat alur dengan aktivitas aliran data
Dalam langkah ini, Anda membuat alur yang berisi aktivitas aliran data.
Pada beranda, pilih Orchestrate.
Di tab Umum untuk alur, masukkan DeltaLake untuk Nama alur.
Di panel Aktivitas , perluas akordion Pindahkan dan Transformasi . Seret dan letakkan aktifitas Data Flow dari panel tampilan ke kanvas alur.
Di bilah atas kanvas pipeline, geser penggeser Data Flow debug ke posisi aktif. Mode debug memungkinkan pengujian interaktif logika transformasi terhadap kluster Spark langsung. Data Flow kluster membutuhkan waktu 5-7 menit untuk pemanasan dan pengguna disarankan untuk mengaktifkan debug terlebih dahulu jika mereka berencana untuk melakukan pengembangan Data Flow. Untuk informasi selengkapnya, lihat Mode Debug.
Bangun logika transformasi di kanvas aliran data
Anda menghasilkan dua aliran data dalam tutorial ini. Aliran data pertama adalah sumber sederhana untuk tenggelam untuk menghasilkan Delta Lake baru dari file CSV film. Terakhir, Anda membuat desain alur yang mengikuti untuk memperbarui data di Delta Lake.

Tujuan tutorial
- Gunakan sumber himpunan data MoviesCSV dari prasyarat, dan bentuk Delta Lake baru darinya.
- Bangun logika untuk memperbarui peringkat film tahun 1988 menjadi '1'.
- Menghapus semua film dari tahun 1950.
- Menyisipkan film baru untuk 2021 dengan menduplikasi film dari tahun 1960.
Memulai dari kanvas aliran data kosong
Pilih transformasi sumber di bagian atas jendela editor aliran data, lalu pilih + Baru di samping properti Himpunan Data di jendela Pengaturan sumber :
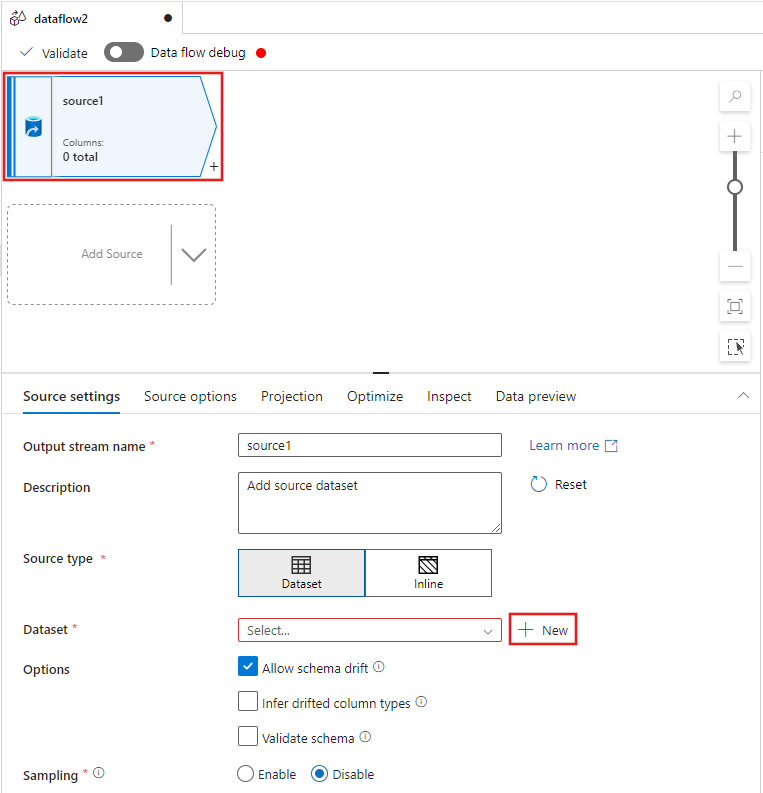
Pilih Azure Data Lake Storage Gen2 dari jendela Set data baru yang muncul, lalu pilih Kontinue.
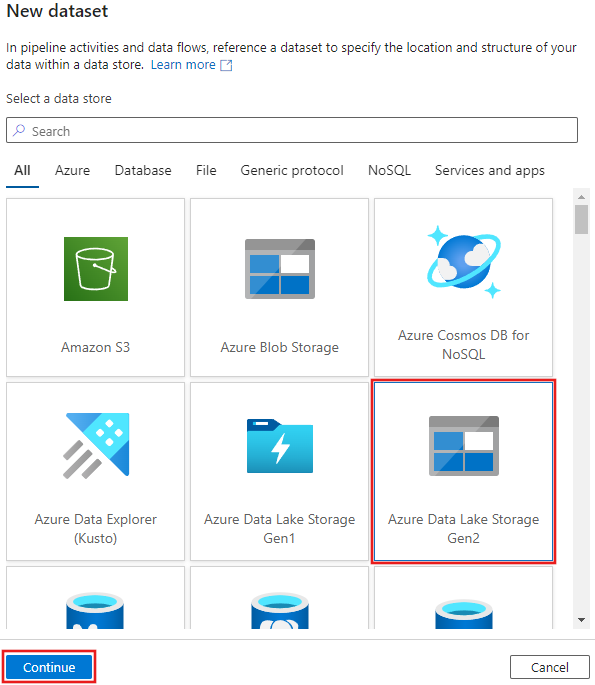
Pilih DelimitedText untuk jenis himpunan data, dan pilih Lanjutkan lagi.

Beri nama himpunan data "MoviesCSV", dan pilih + Baru di bawah Layanan tertaut untuk membuat layanan tertaut baru ke file.
Berikan detail untuk akun penyimpanan Anda yang dibuat sebelumnya di bagian Prasyarat, dan telusuri dan pilih file MoviesCSV yang Anda unggah di sana.
Setelah menambahkan layanan tertaut Anda, pilih kotak centang Baris pertama sebagai header , lalu pilih OK untuk menambahkan sumber.
Navigasi ke tab Proyeksi dari jendela pengaturan aliran data, lalu pilih Deteksi jenis data.
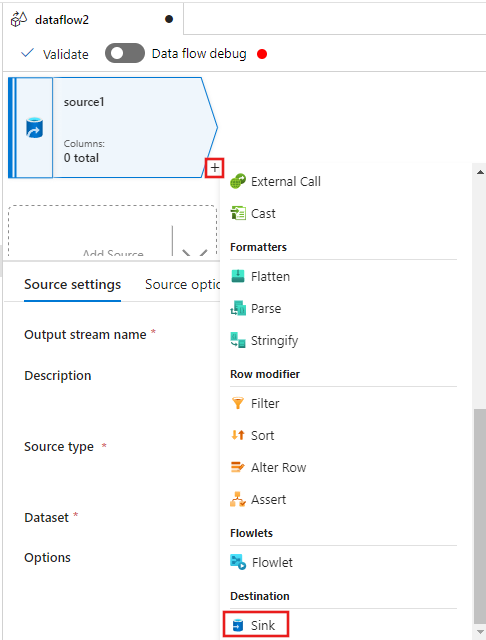
Sekarang pilih + setelah Sumber di jendela editor aliran data, dan gulir ke bawah untuk memilih Sink di bawah bagian Tujuan , menambahkan sink baru ke aliran data Anda.
Di tab Sink untuk pengaturan sink yang muncul setelah sink ditambahkan, pilih Sebaris untuk jenis Sink, lalu Delta untuk jenis himpunan data sebaris. Kemudian pilih Azure Data Lake Storage Gen2 Anda untuk layanan Linked.
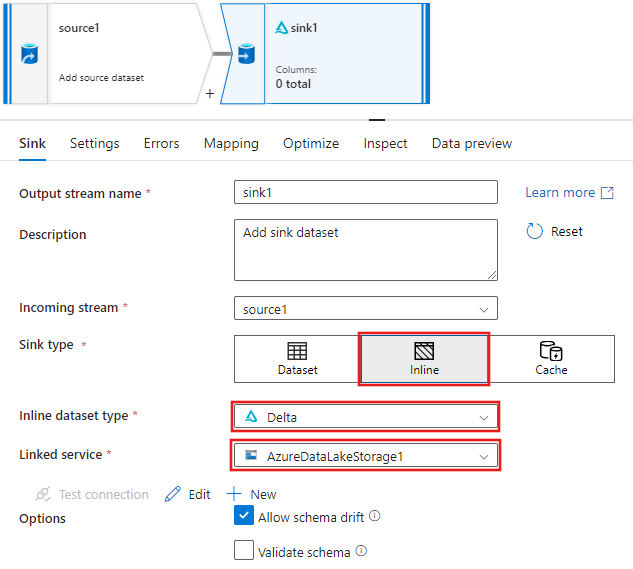
Pilih nama folder di kontainer penyimpanan tempat Anda ingin layanan membuat Delta Lake.
Terakhir, navigasikan kembali perancang alur dan pilih Debug untuk menjalankan alur dalam mode debug hanya dengan aktivitas aliran data ini di kanvas. Ini menghasilkan Delta Lake baru Anda di Azure Data Lake Storage Gen2.
Sekarang, dari menu Sumber Daya Pabrik di sebelah kiri layar, pilih + untuk menambahkan sumber daya baru, lalu pilih Aliran data.
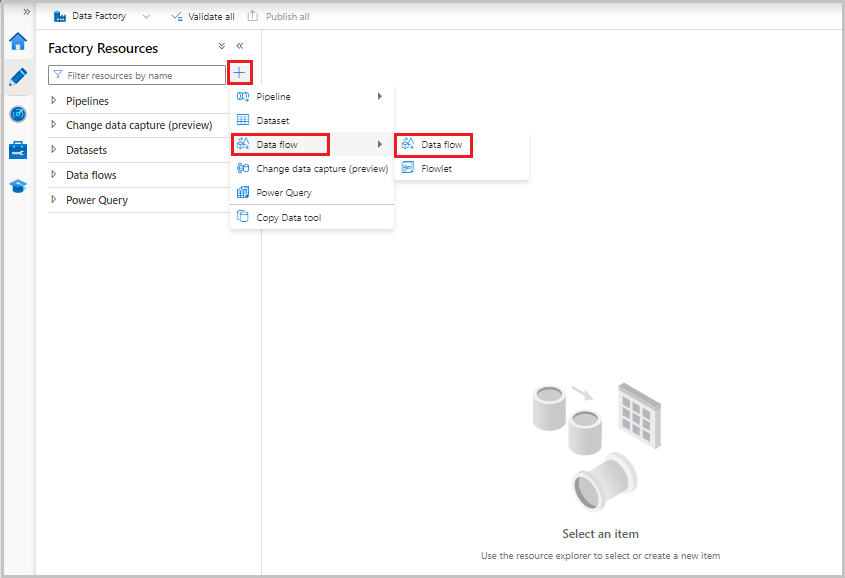
Seperti sebelumnya, pilih file MoviesCSV lagi sebagai sumber lalu pilih Deteksi jenis data lagi dari tab Proyeksi .
Kali ini, setelah membuat sumber, pilih + di jendela editor aliran data, dan tambahkan transformasi Filter ke sumber Anda.
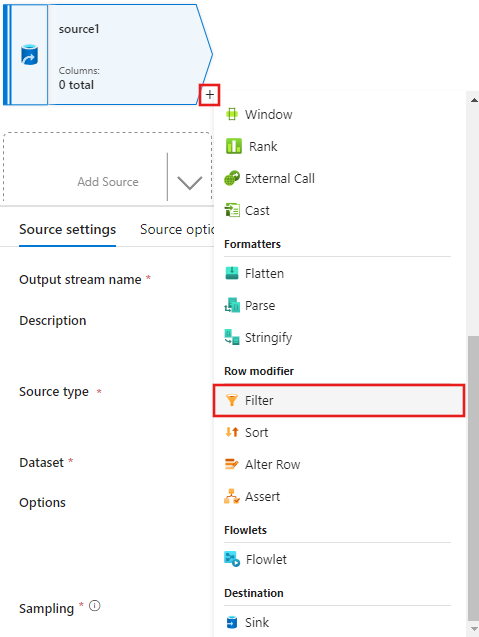
Tambahkan kondisi Filter pada di jendela Pengaturan filter yang hanya mengizinkan baris film yang sesuai dengan 1950, 1960, dan 1988.
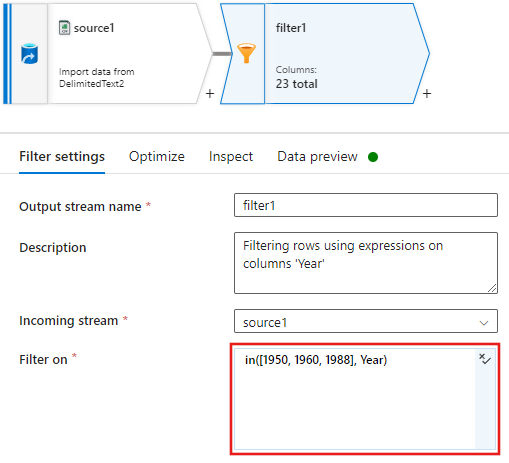
Sekarang tambahkan transformasi Kolom Turunan untuk memperbarui peringkat untuk setiap film tahun 1988 ke '1'.
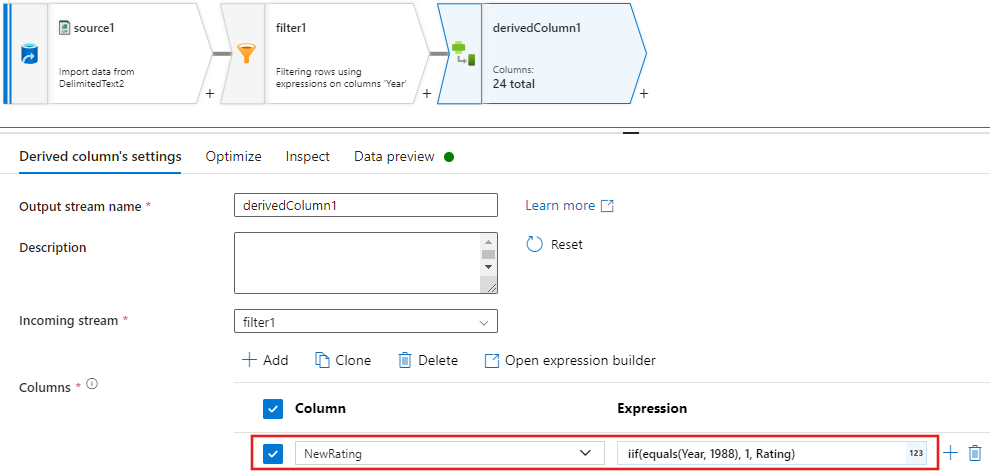
Kebijakan
Update, insert, delete, and upsertdibuat dalam transformasi Alter Row. Tambahkan transformasi pengubahan baris setelah kolom turunan Anda.Kebijakan perubahan baris Anda harus terlihat seperti ini.

Sekarang setelah Anda menetapkan kebijakan yang tepat untuk setiap jenis baris modifikasi, periksa apakah aturan pembaruan yang tepat telah ditetapkan pada transformasi sink.
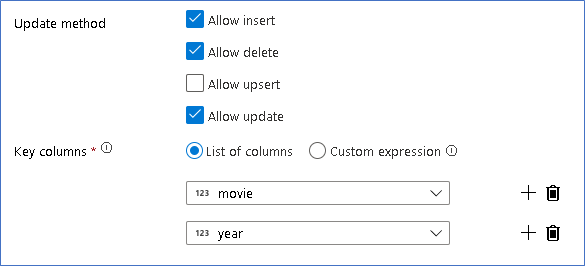
Di sini kita menggunakan sink Delta Lake ke data lake Azure Data Lake Storage Gen2 Anda dan memungkinkan penyisipan, pembaruan, penghapusan.
Perhatikan bahwa kolom kunci adalah kunci komposit yang terdiri dari kolom kunci primer film dan kolom tahun. Ini karena kami membuat film palsu tahun 2021 dengan menduplikasi baris dari tahun 1960. Hal ini untuk menghindari tabrakan ketika melihat ke barisan yang ada dengan memberikan keunikan.
Mengunduh sampel yang sudah selesai
Berikut adalah solusi sampel untuk pipa Delta dengan aliran data untuk memperbarui/menghapus baris data di danau.
Konten terkait
Pelajari selengkapnya tentang bahasa ekspresi aliran data.