Mengonfigurasi komputasi untuk pekerjaan
Artikel ini berisi rekomendasi dan sumber daya untuk mengonfigurasi komputasi untuk Pekerjaan Databricks.
Penting
Batasan untuk komputasi tanpa server untuk pekerjaan meliputi yang berikut ini:
- Tidak ada dukungan untuk Penjadwalan berkelanjutan .
- Tidak ada dukungan untuk pemicu interval default atau berbasis waktu di Streaming Terstruktur.
Untuk batasan lainnya, lihat Batasan komputasi tanpa server.
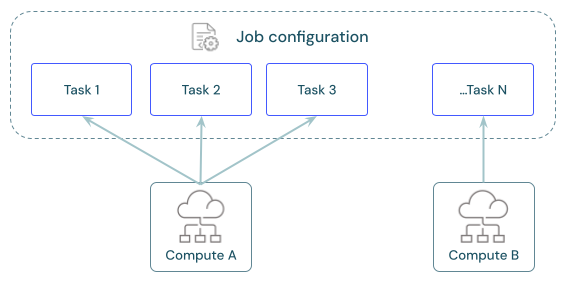
Setiap pekerjaan dapat memiliki satu atau beberapa tugas. Anda menentukan sumber daya komputasi untuk setiap tugas. Beberapa tugas yang ditentukan untuk pekerjaan yang sama dapat menggunakan sumber daya komputasi yang sama.
Apa komputasi yang direkomendasikan untuk setiap tugas?
Tabel berikut menunjukkan jenis komputasi yang direkomendasikan dan didukung untuk setiap jenis tugas.
Catatan
Komputasi tanpa server untuk pekerjaan memiliki batasan dan tidak mendukung semua beban kerja. Lihat Batasan komputasi tanpa server.
| Tugas | Komputasi yang direkomendasikan | Komputasi yang didukung |
|---|---|---|
| Notebook | Pekerjaan tanpa server | Pekerjaan tanpa server, pekerjaan klasik, semua tujuan klasik |
| "Hello world!" | Pekerjaan tanpa server | Pekerjaan tanpa server, pekerjaan klasik, semua tujuan klasik |
| Roda Python | Pekerjaan tanpa server | Pekerjaan tanpa server, pekerjaan klasik, semua tujuan klasik |
| SQL | Gudang SQL tanpa server | Gudang SQL tanpa server, gudang pro SQL |
| Alur Tabel Langsung Delta | Alur tanpa server | Alur tanpa server, alur klasik |
| dbt | Gudang SQL tanpa server | Gudang SQL tanpa server, gudang pro SQL |
| perintah dbt CLI | Pekerjaan tanpa server | Pekerjaan tanpa server, pekerjaan klasik, semua tujuan klasik |
| JAR | Pekerjaan klasik | Pekerjaan klasik, semua tujuan klasik |
| Spark Submit | Pekerjaan klasik | Pekerjaan klasik |
Harga untuk Pekerjaan terkait dengan komputasi yang digunakan untuk menjalankan tugas. Untuk detail selengkapnya, lihat Harga Databricks.
Bagaimana cara mengonfigurasi komputasi untuk Pekerjaan?
Komputasi pekerjaan klasik dikonfigurasi langsung dari UI Pekerjaan Databricks, dan konfigurasi ini adalah bagian dari definisi pekerjaan. Semua jenis komputasi lain yang tersedia menyimpan konfigurasinya dengan aset ruang kerja lainnya. Tabel berikut ini memiliki detail selengkapnya:
| Tipe komputasi | Detail |
|---|---|
| Komputasi pekerjaan klasik | Anda mengonfigurasi komputasi untuk pekerjaan klasik menggunakan UI dan pengaturan yang sama yang tersedia untuk komputasi tujuan semua. Lihat Referensi konfigurasi komputasi. |
| Komputasi tanpa server untuk pekerjaan | Komputasi tanpa server untuk pekerjaan adalah default untuk semua tugas yang mendukungnya. Databricks mengelola pengaturan komputasi untuk komputasi tanpa server. Lihat Menjalankan pekerjaan Azure Databricks Anda dengan komputasi tanpa server untuk alur kerja. Admin ruang kerja nn A harus mengaktifkan komputasi tanpa server agar opsi ini terlihat. Lihat Mengaktifkan komputasi tanpa server. |
| Gudang SQL | Gudang SQL tanpa server dan pro dikonfigurasi oleh admin ruang kerja atau pengguna dengan hak istimewa pembuatan kluster yang tidak dibatasi. Anda mengonfigurasi tugas untuk dijalankan terhadap gudang SQL yang ada. Lihat Menyambungkan ke gudang SQL. |
| Komputasi alur Tabel Langsung Delta | Anda mengonfigurasi pengaturan komputasi untuk alur Delta Live Tables selama konfigurasi alur. Lihat Mengonfigurasi pengaturan komputasi Anda. nn Azure Databricks mengelola sumber daya komputasi untuk alur Delta Live Tables tanpa server. Lihat Membuat alur yang dikelola sepenuhnya menggunakan Tabel Langsung Delta dengan komputasi tanpa server. |
| Komputasi tujuan semua | Anda dapat secara opsional mengonfigurasi tugas menggunakan komputasi klasik semua tujuan. Databricks tidak merekomendasikan konfigurasi ini untuk pekerjaan produksi. Lihat Referensi konfigurasi komputasi dan Haruskah komputasi serba guna pernah digunakan untuk pekerjaan?. |
Berbagi komputasi di seluruh tugas
Konfigurasikan tugas untuk menggunakan sumber daya komputasi pekerjaan yang sama untuk mengoptimalkan penggunaan sumber daya dengan pekerjaan yang mengatur beberapa tugas. Berbagi komputasi di seluruh tugas dapat mengurangi latensi yang terkait dengan waktu mulai.
Anda dapat menggunakan satu sumber daya komputasi pekerjaan untuk menjalankan semua tugas yang merupakan bagian dari pekerjaan atau beberapa sumber daya pekerjaan yang dioptimalkan untuk beban kerja tertentu. Komputasi pekerjaan apa pun yang dikonfigurasi sebagai bagian dari pekerjaan tersedia untuk semua tugas lain dalam pekerjaan.
Tabel berikut menyoroti perbedaan antara komputasi pekerjaan yang dikonfigurasi untuk satu tugas dan komputasi pekerjaan yang dibagikan antar tugas:
| Tugas tunggal | Dibagikan di seluruh tugas | |
|---|---|---|
| Mulai | Ketika tugas berjalan dimulai. | Saat tugas pertama dijalankan dikonfigurasi untuk menggunakan sumber daya komputasi dimulai. |
| Mengakhiri | Setelah tugas berjalan. | Setelah tugas akhir dikonfigurasi untuk menggunakan eksekusi sumber daya komputasi. |
| Komputasi diam | Tidak berlaku. | Komputasi tetap aktif dan menganggur saat tugas tidak menggunakan eksekusi sumber daya komputasi. |
Kluster pekerjaan bersama dilingkup ke satu pekerjaan yang dijalankan dan tidak dapat digunakan oleh pekerjaan lain atau menjalankan pekerjaan yang sama.
Pustaka tidak dapat dideklarasikan dalam konfigurasi kluster pekerjaan bersama. Anda harus menambahkan pustaka dependen dalam pengaturan tugas.
Meninjau, mengonfigurasi, dan menukar komputasi pekerjaan
Bagian Komputasi di panel Detail pekerjaan mencantumkan semua komputasi yang dikonfigurasi untuk tugas dalam pekerjaan saat ini.
Tugas yang dikonfigurasi untuk menggunakan sumber daya komputasi disorot dalam grafik tugas saat Anda mengarahkan mouse ke atas spesifikasi komputasi.
Gunakan tombol Tukar untuk mengubah komputasi untuk semua tugas yang terkait dengan sumber daya komputasi.
Sumber daya komputasi pekerjaan klasik memiliki opsi Konfigurasi . Sumber daya komputasi lainnya memberi Anda opsi untuk melihat dan memodifikasi detail konfigurasi komputasi.
Rekomendasi untuk mengonfigurasi komputasi pekerjaan klasik
Bagian ini berfokus pada rekomendasi umum tentang fitur dan konfigurasi yang dapat menguntungkan beberapa alur kerja. Rekomendasi khusus untuk mengonfigurasi ukuran dan jenis sumber daya komputasi bervariasi berdasarkan beban kerja.
Databricks merekomendasikan untuk mengaktifkan Photon Acceleration, menggunakan versi Databricks Runtime terbaru, dan menggunakan komputasi yang dikonfigurasi untuk Unity Catalog.
Komputasi tanpa server untuk pekerjaan mengelola semua infrastruktur, menghilangkan pertimbangan berikut. Lihat Menjalankan pekerjaan Azure Databricks Anda dengan komputasi tanpa server untuk alur kerja.
Catatan
Alur kerja Streaming Terstruktur memiliki rekomendasi khusus. Lihat Pertimbangan produksi untuk Streaming Terstruktur.
Menggunakan mode akses bersama
Databricks merekomendasikan penggunaan mode akses bersama untuk pekerjaan. Lihat Mode akses.
Catatan
Mode akses bersama tidak mendukung beberapa beban kerja dan fitur. Databricks merekomendasikan mode akses pengguna tunggal untuk beban kerja ini. Lihat Batasan mode akses komputasi untuk Katalog Unity.
Gunakan kebijakan kluster
Databricks merekomendasikan agar admin ruang kerja menentukan kebijakan kluster untuk pekerjaan dan menerapkan kebijakan ini untuk semua pengguna yang mengonfigurasi pekerjaan.
Kebijakan kluster memungkinkan admin ruang kerja untuk mengatur kontrol biaya dan membatasi opsi konfigurasi pengguna. Untuk detail tentang mengonfigurasi kebijakan kluster, lihat Membuat dan mengelola kebijakan komputasi.
Azure Databricks menyediakan kebijakan default yang dikonfigurasi untuk pekerjaan. Admin dapat membuat kebijakan ini tersedia untuk pengguna ruang kerja lainnya. Lihat Komputasi Pekerjaan.
Menggunakan penskalaan otomatis
Konfigurasikan autoscaling sehingga tugas yang berjalan lama dapat secara dinamis menambahkan dan menghapus simpul pekerja selama eksekusi pekerjaan. Lihat Mengaktifkan autoscaling.
Gunakan kumpulan untuk mengurangi waktu mulai kluster
Kumpulan komputasi memungkinkan Anda memesan sumber daya komputasi dari penyedia cloud Anda. Kumpulan bermanfaat untuk mengurangi waktu mulai kluster pekerjaan baru dan memastikan ketersediaan sumber daya komputasi. Lihat Referensi konfigurasi kumpulan.
Menggunakan instans spot
Konfigurasikan instans spot untuk beban kerja yang memiliki persyaratan latensi laks untuk mengoptimalkan biaya. Lihat Instans spot.
Haruskah komputasi serba guna pernah digunakan untuk pekerjaan?
Ada banyak alasan yang direkomendasikan Databricks untuk tidak menggunakan komputasi serba guna untuk pekerjaan, termasuk yang berikut ini:
- Tagihan Azure Databricks untuk komputasi serba guna dengan tarif yang berbeda dari komputasi pekerjaan.
- Komputasi pekerjaan berakhir secara otomatis setelah eksekusi pekerjaan selesai. Komputasi tujuan semua mendukung penghentian otomatis, yang terkait dengan tidak aktif daripada akhir eksekusi pekerjaan.
- Komputasi semua tujuan sering dibagikan di seluruh tim pengguna. Pekerjaan yang dijadwalkan terhadap komputasi serba guna sering kali memiliki latensi yang meningkat karena persaingan untuk sumber daya komputasi.
- Banyak rekomendasi untuk mengoptimalkan konfigurasi komputasi pekerjaan tidak sesuai untuk jenis kueri ad-hoc dan beban kerja interaktif yang dijalankan pada komputasi serba guna.
Berikut ini adalah kasus penggunaan di mana Anda mungkin memilih untuk menggunakan komputasi semua tujuan untuk pekerjaan:
- Anda secara berulang mengembangkan atau menguji pekerjaan baru. Waktu mulai untuk komputasi pekerjaan dapat membuat pengembangan berulang melelahkan. Komputasi semua tujuan memungkinkan Anda menerapkan perubahan dan menjalankan pekerjaan Anda dengan cepat.
- Anda memiliki pekerjaan berumur pendek yang harus sering dijalankan atau pada jadwal tertentu. Tidak ada waktu mulai yang terkait dengan komputasi semua tujuan yang sedang berjalan. Pertimbangkan biaya yang terkait dengan waktu diam jika menggunakan pola ini.
Komputasi tanpa server untuk pekerjaan adalah pengganti yang direkomendasikan untuk sebagian besar jenis tugas yang mungkin Anda pertimbangkan untuk berjalan terhadap komputasi serba guna.