Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari apa itu Lakeflow Spark Declarative Pipelines (SDP), konsep inti (seperti alur, tabel streaming, dan tampilan materialisasi) yang menentukannya, hubungan antara konsep tersebut, dan manfaat menggunakannya dalam alur kerja pemrosesan data Anda.
Nota
Alur Deklaratif Lakeflow Spark memerlukan paket Premium. Hubungi tim akun Databricks Anda untuk informasi selengkapnya.
Apa itu SDP?
Lakeflow Spark Declarative Pipelines adalah kerangka kerja deklaratif untuk mengembangkan dan menjalankan alur data batch dan streaming di SQL dan Python. Lakeflow SDP memperluas jangkauan dan berinteroperasi dengan Aliran Deklaratif Apache Spark, saat berjalan pada Databricks Runtime yang dioptimalkan untuk kinerja, dan Lakeflow Spark Declarative Pipelines flows API memanfaatkan API DataFrame yang sama seperti Apache Spark dan Streaming Terstruktur. Kasus penggunaan umum untuk SDP mencakup penyerapan data bertahap dari sumber seperti penyimpanan cloud (termasuk Amazon S3, Azure ADLS Gen2, dan Google Cloud Storage) dan bus pesan (seperti Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure EventHub, dan Apache Pulsar), transformasi batch dan streaming bertahap dengan operator stateless dan stateful, dan pemrosesan aliran real time antara penyimpanan transaksional seperti bus pesan dan database.
Untuk detail selengkapnya tentang pemrosesan data deklaratif, lihat Pemrosesan data prosedural vs. deklaratif di Databricks.
Apa manfaat SDP?
Sifat deklaratif dari SDP memberikan manfaat berikut dibandingkan dengan mengembangkan proses data dengan API Apache Spark dan Spark Structured Streaming serta menjalankannya menggunakan Databricks Runtime dengan orkestrasi manual melalui Lakeflow Jobs.
- Orkestrasi otomatis: SDP mengatur langkah-langkah pemrosesan (disebut "alur") secara otomatis untuk memastikan urutan eksekusi yang benar dan tingkat paralelisme maksimum untuk performa optimal. Selain itu, alur secara otomatis dan efisien mencoba kembali kegagalan sementara. Proses coba lagi dimulai dengan unit yang paling terperinci dan hemat biaya: tugas Spark. Jika upaya ulang tingkat tugas gagal, SDP melanjutkan untuk mengulang proses, dan kemudian seluruh pipeline jika perlu.
- Pemrosesan deklaratif: SDP menyediakan fungsi deklaratif yang dapat mengurangi ratusan atau bahkan ribuan baris kode Spark manual dan Streaming Terstruktur menjadi hanya beberapa baris. SDP AUTO CDC API menyederhanakan pemrosesan peristiwa Change Data Capture (CDC) dengan dukungan untuk SCD Tipe 1 dan SCD Tipe 2. Ini menghilangkan kebutuhan kode manual untuk menangani peristiwa yang tidak berurutan, dan tidak memerlukan pemahaman tentang semantik pemrosesan streaming atau konsep seperti penanda waktu.
- Pemrosesan bertahap: SDP menyediakan mesin pemrosesan bertahap untuk tampilan materialisasi. Untuk menggunakannya, Anda menulis logika transformasi Anda dengan semantik batch, dan mesin hanya akan memproses data baru dan perubahan dalam sumber data jika memungkinkan. Pemrosesan bertahap mengurangi pemrosesan ulang yang tidak efisien ketika data baru atau perubahan terjadi di sumber dan menghilangkan kebutuhan kode manual untuk menangani pemrosesan bertahap.
Konsep Utama
Diagram di bawah ini menggambarkan konsep paling penting dari Alur Deklaratif Lakeflow Spark.
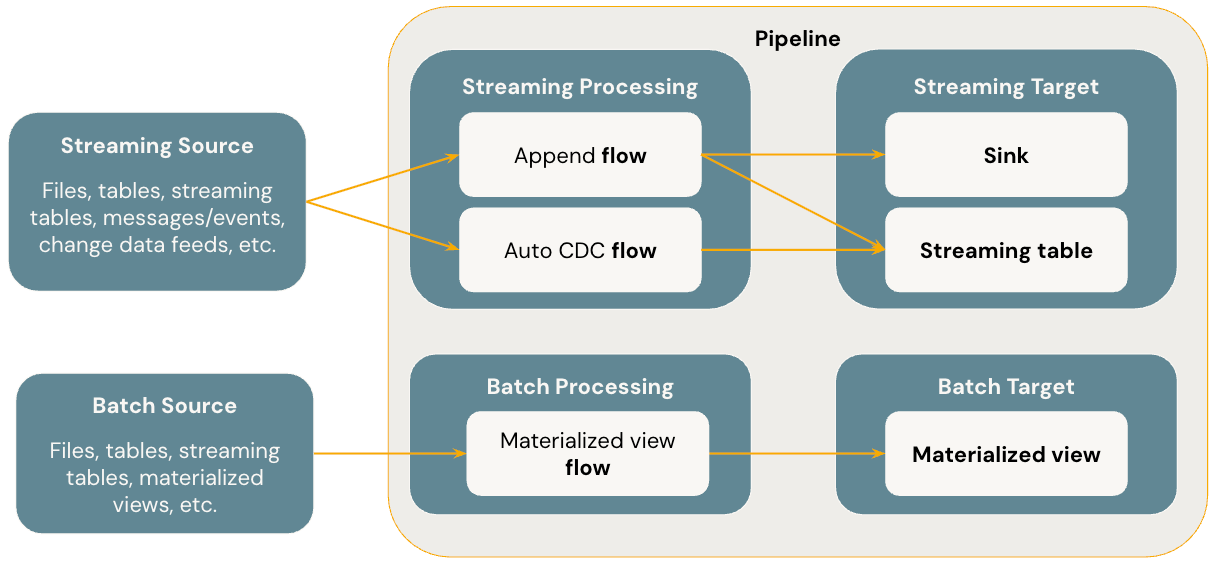
Flows
Alur adalah konsep pemrosesan data dasar dalam SDP yang mendukung semantik streaming dan batch. Alur membaca data dari sumber, menerapkan logika pemrosesan yang ditentukan pengguna, dan menulis hasilnya ke dalam target. SDP berbagi jenis alur streaming yang sama (Tambahkan, Perbarui, Selesai) sebagai Streaming Terstruktur Spark. (Saat ini, hanya alur Tambahkan yang terekspos.) Untuk detail selengkapnya, lihat mode output di Streaming Terstruktur.
Alur Deklaratif Lakeflow Spark juga menyediakan jenis alur tambahan:
- AUTO CDC adalah aliran streaming unik di Lakeflow SDP yang menangani peristiwa CDC yang tidak berurutan dan mendukung SCD Tipe 1 dan SCD Tipe 2. CDC Otomatis tidak tersedia di Alur Deklaratif Apache Spark.
- Materialized view adalah alur batch di SDP yang hanya memproses data baru dan perubahan dalam tabel sumber sejauh mungkin.
Untuk detail selengkapnya, lihat:
Tabel aliran data
Tabel streaming adalah bentuk tabel terkelola Unity Catalog yang juga merupakan target streaming untuk Lakeflow SDP. Tabel streaming dapat memiliki satu atau beberapa alur streaming (Tambahkan, CDC OTOMATIS) yang ditulis ke dalamnya. AUTO CDC adalah aliran streaming unik yang hanya tersedia untuk streaming tabel di Databricks. Anda dapat menentukan alur streaming secara eksplisit dan terpisah dari tabel streaming targetnya. Anda juga dapat menentukan alur streaming secara implisit sebagai bagian dari definisi tabel streaming.
Untuk detail selengkapnya, lihat:
Pandangan termaterialisasi
Materialized view juga merupakan bentuk tabel dikelola oleh Katalog Unity dan merupakan target batch. Tampilan materialisasi dapat memiliki satu atau beberapa alur tampilan materialisasi yang ditulis ke dalamnya. Tampilan materialisasi berbeda dari tabel streaming karena Anda selalu menentukan alur secara implisit sebagai bagian dari definisi tampilan materialisasi.
Untuk detail selengkapnya, lihat:
Sinks
Sink adalah target streaming untuk alur dan mendukung tabel Delta, topik Apache Kafka, topik Azure EventHubs, dan sumber data Python kustom. Sink dapat memiliki satu atau beberapa alur streaming (Tambah) ditulis ke dalamnya.
Untuk detail selengkapnya, lihat:
Rantai Pengolahan
Pipeline adalah unit pengembangan dan eksekusi dalam Lakeflow Spark Declarative Pipelines. Saluran dapat berisi satu atau beberapa aliran, tabel aliran data, tampilan materialisasi, dan tujuan akhir. Anda menggunakan SDP dengan menentukan alur, tabel streaming, tampilan materialisasi, dan sink dalam kode sumber alur Anda lalu menjalankan alur. Saat pipeline Anda berjalan, pipeline menganalisis dependensi dari aliran yang Anda tentukan, tabel streaming, tampilan materialisasi, dan sink, dan menjalankan urutan eksekusi serta paralelisasinya secara otomatis.
Untuk detail selengkapnya, lihat:
Pipeline Databricks SQL
Tabel streaming dan tampilan materialisasi adalah dua kemampuan dasar di Databricks SQL. Anda dapat menggunakan SQL standar untuk membuat dan me-refresh tabel streaming dan tampilan materialisasi di Databricks SQL. Tabel streaming dan tampilan materialisasi di Databricks SQL berjalan pada infrastruktur Azure Databricks yang sama dan memiliki semantik pemrosesan yang sama seperti yang mereka lakukan di Lakeflow Spark Declarative Pipelines. Saat Anda menggunakan tabel streaming dan tampilan materialisasi di Databricks SQL, alur didefinisikan secara implisit sebagai bagian dari tabel streaming dan definisi tampilan materialisasi.
Untuk detail selengkapnya, lihat: