Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Jika aplikasi pemrosesan data di kluster HDInsight berjalan lambat atau gagal dengan kode kesalahan, Anda memiliki beberapa opsi pemecahan masalah. Jika pekerjaan Anda membutuhkan waktu lebih lama untuk berjalan dari yang diharapkan, atau Anda melihat waktu respons yang lambat secara umum, mungkin ada kegagalan di hulu dari kluster Anda, seperti layanan di mana kluster berjalan. Namun, penyebab paling umum dari perlambatan ini adalah penskalaan yang tidak memadai. Saat Anda membuat kluster Microsoft Azure HDInsight baru, pilih ukuran mesin virtual yang sesuai.
Untuk mendiagnosis kluster yang lambat atau gagal, kumpulkan informasi tentang semua aspek lingkungan, seperti Layanan Azure terkait, konfigurasi kluster, dan informasi eksekusi pekerjaan. Diagnostik yang bermanfaat adalah mencoba mereproduksi status kesalahan di kluster lain.
- Langkah 1: Mengumpulkan data tentang masalah ini.
- Langkah 2: Memvalidasi lingkungan kluster Microsoft Azure HDInsight.
- Langkah 3: Menampilkan kesehatan kluster Anda.
- Langkah 4: Meninjau tumpukan dan versi lingkungan.
- Langkah 5: Memeriksa file log kluster.
- Langkah 6: Memeriksa pengaturan konfigurasi.
- Langkah 7: Mereproduksi kegagalan pada kluster yang berbeda.
Langkah 1: Mengumpulkan data tentang masalah ini
Microsoft Azure HDInsight menyediakan banyak alat yang dapat Anda gunakan untuk mengidentifikasi dan memecahkan masalah dengan kluster. Langkah-langkah berikut memandu Anda melalui alat-alat ini dan memberikan saran untuk menunjukkan masalah dengan tepat.
Mengidentifikasi masalah
Untuk membantu mengidentifikasi masalah, pertimbangkan pertanyaan berikut:
- Apa yang saya harapkan terjadi? Apa yang terjadi sebaliknya?
- Berapa lama proses berjalan? Berapa lama itu seharusnya berjalan?
- Apakah tugas saya selalu berjalan lambat pada kluster ini? Apakah mereka berjalan lebih cepat pada kluster yang berbeda?
- Kapan masalah ini pertama kali terjadi? Seberapa sering hal itu terjadi sejak itu?
- Apakah ada yang berubah dalam konfigurasi kluster saya?
Detail kluster
Informasi kluster penting meliputi:
- Nama kluster.
- Wilayah kluster - periksa penghentian wilayah.
- Jenis dan versi kluster Microsoft Azure HDInsight.
- Ketik dan jumlah instans Microsoft Azure HDInsight yang ditentukan untuk simpul kepala dan pekerja.
portal Microsoft Azure dapat memberikan informasi ini:

Anda juga dapat menggunakan Azure CLI:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Pilihan lain adalah menggunakan PowerShell. Untuk informasi lebih lanjut, lihat Mengelola kluster Apache Hadoop di HDInsight dengan Azure PowerShell.
Langkah 2: Memvalidasi lingkungan kluster Microsoft Azure HDInsight
Setiap kluster Microsoft Azure HDInsight bergantung pada berbagai layanan Azure, dan pada perangkat lunak sumber terbuka seperti Apache HBase dan Apache Spark. Kluster Microsoft Azure HDInsight juga dapat memanggil layanan Azure lainnya, seperti Azure Virtual Networks. Kegagalan kluster dapat disebabkan oleh salah satu layanan yang berjalan pada kluster Anda, atau oleh layanan eksternal. Perubahan konfigurasi layanan kluster juga dapat menyebabkan kluster gagal.
Detail layanan
- Memeriksa versi rilis pustaka sumber terbuka.
- Memeriksa Pemadaman Layanan Microsoft Azure.
- Memeriksa batas penggunaan Layanan Microsoft Azure.
- Memeriksa konfigurasi subnet Azure Virtual Network.
Menampilkan pengaturan konfigurasi kluster dengan UI Ambari
Apache Ambari menyediakan manajemen dan pemantauan kluster Microsoft Azure HDInsight dengan UI web dan REST API. Ambari termasuk dalam kluster Microsoft Azure HDInsight berbasis Linux. Pilih panel Dasbor Kluster pada halaman Microsoft Azure HDInsight portal Microsoft Azure. Pilih panel dasbor kluster HDInsight untuk membuka UI Ambari, dan masukkan informasi masuk login kluster.
Untuk membuka daftar tampilan layanan, pilih Tampilan Ambari di halaman portal Microsoft Azure. Daftar ini bergantung pada pustaka mana yang dipasang. Misalnya, Anda mungkin melihat Yarn Queue Manager, Apache Hive View, dan Tez View. Pilih link layanan untuk melihat konfigurasi dan informasi layanan.
Periksa pemadaman layanan Azure
Microsoft Azure HDInsight mengandalkan beberapa layanan Azure. Hal ini menjalankan server virtual di Microsoft Azure HDInsight, menyimpan data dan skrip di penyimpanan Azure Blob atau Azure Data Lake Storage, dan mengindeks file log di penyimpanan Azure Table. Gangguan pada layanan ini, meskipun jarang terjadi, dapat menyebabkan masalah dalam Microsoft Azure HDInsight. Jika Anda mengalami pelambatan atau kegagalan yang tidak terduga di kluster Anda, periksa Dasbor Status Azure. Status setiap layanan dicantumkan menurut wilayah. Periksa wilayah kluster Anda dan juga wilayah untuk layanan terkait apa pun.
Periksa batas penggunaan Layanan Microsoft Azure
Jika Anda meluncurkan kluster besar, atau meluncurkan banyak kluster secara bersamaan, kluster dapat gagal jika Anda telah melampaui batas layanan Azure. Batas layanan bervariasi, bergantung pada langganan Microsoft Azure Anda. Untuk informasi selengkapnya, lihat Batas, kuota, dan batasan langganan dan layanan Azure. Anda dapat meminta Microsoft meningkatkan jumlah sumber daya Microsoft Azure HDInsight yang tersedia (seperti inti VM dan instans VM) dengan permintaan peningkatan kuota inti Resource Manager.
Memeriksa versi rilis
Membandingkan versi kluster dengan rilis Microsoft Azure HDInsight terbaru. Setiap rilis HDInsight mencakup peningkatan seperti aplikasi baru, fitur, patch, dan perbaikan bug. Masalah yang memengaruhi kluster Anda mungkin telah diperbaiki dalam versi rilis terbaru. Jika memungkinkan, jalankan ulang kluster Anda menggunakan versi terbaru Microsoft Azure HDInsight dan pustaka terkait seperti Apache HBase, Apache Spark, dan lainnya.
Memulai ulang layanan kluster Anda
Jika Anda mengalami perlambatan dalam kluster, pertimbangkan untuk memulai ulang layanan melalui Ambari UI atau Microsoft Azure Classic CLI. Kluster mungkin mengalami kesalahan sementara, dan memulai ulang adalah cara tercepat untuk menstabilkan lingkungan Anda dan mungkin meningkatkan performa.
Langkah 3: Menampilkan kesehatan kluster Anda
Kluster Microsoft Azure HDInsight terdiri dari berbagai jenis simpul yang berjalan pada instans mesin virtual. Setiap simpul dapat dipantau untuk kelaparan sumber daya, masalah konektivitas jaringan, dan masalah lain yang dapat memperlambat kluster. Setiap kluster berisi dua simpul kepala, dan sebagian besar jenis kluster mengandung kombinasi simpul pekerja dan tepi.
Untuk deskripsi berbagai simpul yang digunakan setiap jenis kluster, lihat Siapkan kluster di Microsoft Azure HDInsight dengan Apache Hadoop, Apache Spark, Apache Kafka, dan banyak lagi.
Bagian berikut menjelaskan cara memeriksa kesehatan setiap node dan kluster secara keseluruhan.
Dapatkan rekam jepret kesehatan kluster menggunakan dasbor Ambari UI
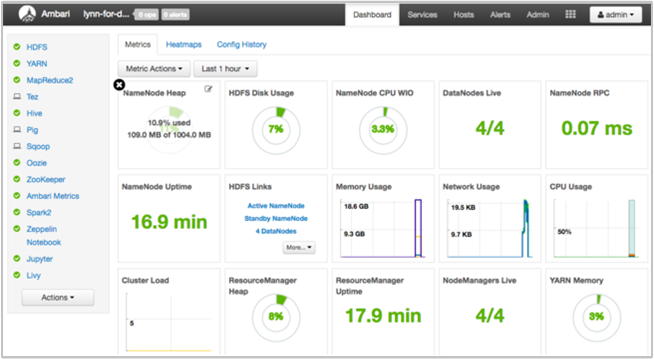
Dasbor Ambari UI (https://<clustername>.azurehdinsight.net) memberikan gambaran umum tentang kesehatan kluster, seperti waktu aktif, memori, penggunaan jaringan dan CPU, penggunaan disk HDFS, dan sebagainya. Gunakan bagian Host di Ambari untuk melihat sumber daya di tingkat host. Anda juga dapat menghentikan dan memulai ulang layanan.
Memeriksa layanan WebHCat Anda
Salah satu skenario umum untuk pekerjaan Apache Hive, Apache Pig, atau Apache Sqoop yang gagal adalah kegagalan dengan layanan WebHCat (atau Templeton). WebHCat adalah antarmuka REST untuk eksekusi pekerjaan jarak jauh, seperti Apache Hive, Apache Pig, Apache Scoop, dan MapReduce. WebHCat menerjemahkan permintaan pengiriman pekerjaan ke dalam aplikasi YARN Apache Hadoop, dan mengembalikan status yang berasal dari status aplikasi YARN. Bagian berikut menjelaskan kode status HTTP WebHCat yang umum.
BadGateway (kode status 502)
Kode ini adalah pesan generik dari simpul gateway, dan merupakan kode status kegagalan yang paling umum. Salah satu kemungkinan penyebabnya adalah layanan WebHCat sedang tidak berfungsi pada node utama aktif. Untuk memeriksa kemungkinan ini, gunakan perintah CURL berikut:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari menampilkan peringatan yang menunjukkan host yang layanan WebHCatnya tidak berfungsi. Anda dapat mencoba untuk membawa layanan WebHCat kembali dengan memulai ulang layanan pada host-nya.
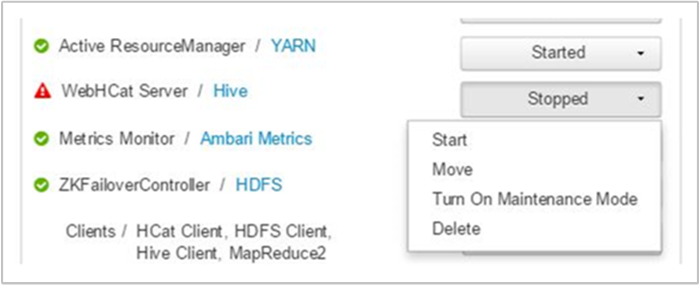
Jika server WebHCat masih tidak muncul, periksa log operasi untuk pesan kegagalan. Untuk informasi lebih rinci, periksa stderr dan stdout file yang direferensikan pada simpul.
WebHCat waktu habis
Gateway Microsoft Azure HDInsight mengeluarkan respons yang memakan waktu lebih dari dua menit, mengembalikan 502 BadGateway. WebHCat meminta layanan YARN untuk status pekerjaan, dan jika YARN membutuhkan waktu lebih dari dua menit untuk merespons, permintaan tersebut dapat menghabiskan waktu.
Dalam hal ini, tinjau log berikut di /var/log/webhcat direktori:
- webhcat.log adalah log Log4j tempat server menulis log
- webhcat-console.log adalah stdout server ketika dimulai
- webhcat-console-error.log ini adalah stderr dari proses server
Catatan
Masing-masing webhcat.log digulirkan setiap hari, menghasilkan file bernama webhcat.log.YYYY-MM-DD. Pilih file yang sesuai untuk rentang waktu yang Anda selidiki.
Bagian berikut ini menjelaskan beberapa kemungkinan penyebab waktu habis WebHCat.
Waktu habis tingkat WebHCat habis
Ketika WebHCat berada di bawah beban, dengan lebih dari 10 soket terbuka, dibutuhkan waktu lebih lama untuk membuat koneksi soket baru, yang dapat menghasilkan waktu habis. Untuk mencantumkan koneksi jaringan ke dan dari WebHCat, gunakan netstat pada headnode aktif saat ini:
netstat | grep 30111
30111 adalah port WebHCat dengarkan. Jumlah soket terbuka harus kurang dari 10.
Jika tidak ada soket terbuka, perintah sebelumnya tidak menghasilkan hasil. Untuk memeriksa apakah Templeton aktif dan mendengarkan di port 30111, gunakan:
netstat -l | grep 30111
Waktu habis tingkat YARN
Templeton memanggil YARN untuk menjalankan pekerjaan, dan komunikasi antara Templeton dan YARN dapat menyebabkan waktu habis.
Di tingkat YARN, ada dua jenis waktu habis:
Mengirimkan pekerjaan YARN dapat memakan waktu cukup lama untuk menyebabkan waktu habis.
Jika Anda membuka
/var/log/webhcat/webhcat.logfile log dan menelusuri "pekerjaan yang diantrekan", Anda mungkin melihat beberapa entri dengan waktu eksekusi yang terlalu lama (>2000 ms), dengan entri yang menunjukkan waktu tunggu yang meningkat.Waktu untuk pekerjaan yang diantrekan terus meningkat karena tingkat dimana pekerjaan baru diserahkan lebih tinggi daripada tingkat pekerjaan lama selesai. Setelah memori YARN 100% digunakan,
joblauncher queuetidak dapat lagi meminjam kapasitas dari antrean default. Oleh karena itu, tidak ada lagi pekerjaan baru yang dapat diterima ke dalam antrean peluncur pekerjaan. Perilaku ini dapat menyebabkan waktu tunggu menjadi lebih lama dan lebih lama, menyebabkan kesalahan waktu habis yang biasanya diikuti oleh banyak lainnya.Gambar berikut menunjukkan antrean peluncur pekerjaan pada 714,4% terlalu banyak digunakan. Hal ini dapat diterima selama masih ada kapasitas gratis dalam antrean default untuk meminjam dari. Namun, ketika kluster sepenuhnya digunakan dan memori YARN berada pada kapasitas 100%, pekerjaan baru harus menunggu, yang akhirnya menyebabkan waktu habis.

Ada dua cara untuk mengatasi masalah ini: kurangi kecepatan pekerjaan baru yang diajukan, atau tingkatkan kecepatan konsumsi pekerjaan lama dengan meningkatkan skala kluster.
Pemrosesan YARN dapat memakan waktu lama, yang dapat menyebabkan waktu habis.
Mencantumkan semua pekerjaan: Hal ini adalah panggilan yang memakan waktu. Panggilan ini menghitung aplikasi dari YARN Resource Manager, dan untuk setiap aplikasi yang selesai, mendapatkan status dari YARN JobHistoryServer. Dengan jumlah pekerjaan yang lebih tinggi, panggilan ini dapat menghabiskan waktu.
Mencantumkan pekerjaan yang lebih lama dari tujuh hari: Microsoft Azure HDInsight YARN JobHistoryServer dikonfigurasi untuk menyimpan informasi pekerjaan yang diselesaikan selama tujuh hari (
mapreduce.jobhistory.max-age-msnilai). Mencoba untuk menghitung pekerjaan yang dibersihkan menghasilkan waktu habis.
Untuk mendiagnosis masalah ini:
- Tentukan rentang waktu UTC untuk memecahkan masalah
- Memilih file yang sesuai
webhcat.log - Mencari pesan WARN dan ERROR selama waktu tersebut
Kegagalan WebHCat lainnya
Kode status HTTP 500
Dalam kebanyakan kasus di mana WebHCat mengembalikan 500, pesan kesalahan berisi detail tentang kegagalan tersebut. Jika tidak, cari melalui
webhcat.loguntuk pesan WARN dan ERROR.Kegagalan pekerjaan
Mungkin ada kasus di mana interaksi dengan WebHCat berhasil, tetapi pekerjaan gagal.
Templeton mengumpulkan output konsol pekerjaan seperti
stderrdalamstatusdir, yang sering berguna untuk pemecahan masalah.stderrberisi pengidentifikasi aplikasi YARN dari kueri aktual.
Langkah 4: Meninjau tumpukan dan versi lingkungan
Halaman Tumpukan dan Versi Ambari UI menyediakan informasi tentang konfigurasi layanan kluster dan riwayat versi layanan. Versi pustaka layanan Hadoop yang salah dapat menjadi penyebab kegagalan kluster. Di antarmuka pengguna Ambari, pilih menu Admin lalu Tumpukan dan Versi. Pilih tab Versi untuk melihat informasi versi layanan:
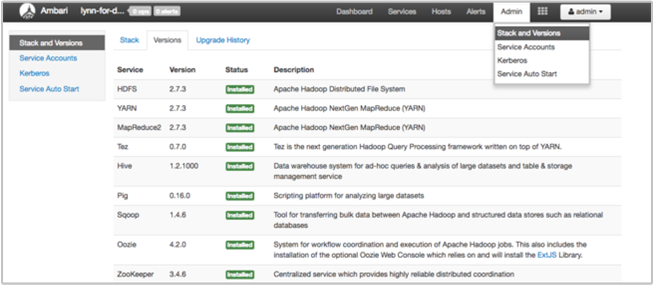
Langkah 5: Memeriksa file log
Ada banyak jenis log yang dihasilkan dari banyak layanan dan komponen yang terdiri dari kluster Microsoft Azure HDInsight. File log WebHCat dijelaskan sebelumnya. Ada beberapa file log berguna lainnya yang dapat Anda selidiki untuk mempersempit masalah dengan kluster Anda, seperti yang dijelaskan di bagian berikut.
Kluster Microsoft Azure HDInsight terdiri dari beberapa simpul, yang sebagian besar bertugas untuk menjalankan pekerjaan yang dikirimkan. Pekerjaan berjalan bersamaan, tetapi file log hanya dapat menampilkan hasil secara linear. Microsoft Azure HDInsight menjalankan tugas baru, mengakhiri tugas lain yang gagal diselesaikan terlebih dahulu. Semua aktivitas ini dicatat ke
stderrdansyslogfile.File log aksi skrip menampilkan galat atau perubahan konfigurasi tak terduga selama proses pembuatan kluster Anda.
Log langkah Apache Hadoop mengidentifikasi pekerjaan Hadoop yang diluncurkan sebagai bagian dari langkah yang berisi kesalahan.
Memeriksa log tindakan skrip
Tindakan skrip Microsoft Azure HDInsight jalankan skrip pada kluster, baik secara manual atau ketika ditentukan. Misalnya, tindakan skrip dapat digunakan untuk memasang perangkat lunak tambahan pada kluster atau untuk mengubah pengaturan konfigurasi dari nilai default. Memeriksa log tindakan skrip dapat memberikan wawasan tentang kesalahan yang terjadi selama pengaturan dan konfigurasi kluster. Anda dapat melihat status tindakan skrip dengan memilih tombol ops di UI Ambari, atau dengan mengakses log dari akun penyimpanan default.
Log tindakan skrip berada di \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE direktori.
Menampilkan log Microsoft Azure HDInsight menggunakan Tautan Cepat Ambari
UI Microsoft Azure HDInsight Ambari menyertakan sejumlah bagian Tautan Cepat. Untuk mengakses tautan log untuk layanan tertentu di kluster Microsoft Azure HDInsight Anda, buka Ambari UI untuk kluster Anda, lalu pilih tautan layanan dari daftar di sebelah kiri. Pilih menu dropdown Link Cepat, lalu node minat Microsoft Azure HDInsight, lalu pilih link untuk log terkait.
Misalnya, untuk log HDFS:
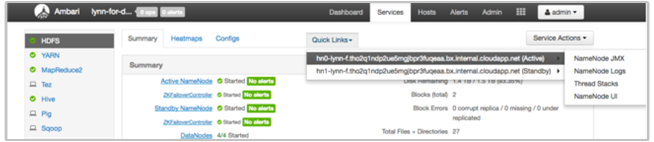
Tampilkan file log buatan Hadoop
Kluster Microsoft Azure HDInsight menghasilkan log yang ditulis ke tabel Azure dan penyimpanan Azure Blob. YARN membuat log eksekusinya sendiri. Untuk informasi selengkapnya, lihat Mengelola log untuk kluster Microsoft Azure HDInsight.
Meninjau cadangan tumpukan
Cadangan tumpukan berisi rekam jepret memori aplikasi, termasuk nilai variabel pada saat itu, yang berguna untuk mendiagnosis masalah yang terjadi pada waktu proses. Untuk informasi selengkapnya, lihat Aktifkan cadangan tumpukan untuk layanan Apache Hadoop pada Microsoft Azure HDInsight berbasis Linux.
Langkah 6: Memeriksa pengaturan konfigurasi
Kluster Microsoft Azure HDInsight telah dikonfigurasi sebelumnya dengan pengaturan default untuk layanan terkait, seperti Apache Hadoop, Apache Hive, Apache HBase, dan sebagainya. Tergantung pada jenis kluster, konfigurasi perangkat kerasnya, jumlah simpulnya, jenis pekerjaan yang Anda jalankan, dan data yang bekerja dengan Anda (dan bagaimana data tersebut diproses), Anda mungkin perlu mengoptimalkan konfigurasi Anda.
Untuk petunjuk terperinci tentang mengoptimalkan konfigurasi kinerja untuk sebagian besar skenario, lihat Mengoptimalkan konfigurasi kluster dengan Apache Ambari. Saat menggunakan Spark, lihat Optimalkan pekerjaan Apache Spark untuk performa.
Langkah 7: Mereproduksi kegagalan pada kluster yang berbeda
Untuk membantu mendiagnosa sumber kesalahan kluster, mulailah kluster baru dengan konfigurasi yang sama lalu keluarkan kembali langkah-langkah pekerjaan yang gagal satu per satu. Memeriksa hasil dari setiap langkah sebelum memproses langkah berikutnya. Metode ini memberi Anda kesempatan untuk memperbaiki dan menjalankan kembali satu langkah yang gagal. Metode ini juga memiliki keuntungan hanya memuat data input Anda sekali.
- Membuat kluster pengujian baru dengan konfigurasi yang sama dengan kluster yang gagal.
- Mengirimkan langkah pekerjaan pertama ke kluster pengujian.
- Ketika langkah selesai diproses, periksa kesalahan dalam file log langkah. Sambungkan ke simpul master kluster uji dan tampilkan file log di sana. File log langkah hanya muncul setelah langkah berjalan selama beberapa waktu, selesai, atau gagal.
- Jika langkah pertama berhasil, jalankan langkah berikutnya. Jika terdapat kesalahan, selidiki kesalahan dalam file log. Jika hal tersebut adalah kesalahan dalam kode Anda, buat koreksi dan jalankan ulang langkah.
- Lanjutkan hingga semua langkah berjalan tanpa kesalahan.
- Ketika Anda selesai melakukan penelusuran kesalahan kluster uji, hapuslah.
Langkah berikutnya
- Kelola klaster HDInsight dengan menggunakan Apache Ambari Web UI
- Mengalisa log Microsoft Azure HDInsight
- Mengakses log aplikasi Apache Hadoop YARN pada Microsoft Azure HDInsight berbasis Linux
- Mengaktifkan heap dump untuk layanan Apache Hadoop pada HDInsight berbasis Linux
- Masalah Umum untuk kluster Apache Spark pada Microsoft Azure HDInsight