Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Managed Instance for Apache Cassandra adalah layanan terkelola penuh untuk kluster Apache Cassandra sumber terbuka murni. Layanan ini juga memungkinkan konfigurasi untuk diubah, tergantung pada kebutuhan spesifik setiap beban kerja, yang memungkinkan fleksibilitas dan kontrol maksimum di mana diperlukan.
Artikel ini mendefinisikan operasi manajemen dan fitur yang disediakan oleh layanan. Ini juga menjelaskan pemisahan tanggung jawab antara tim dukungan Azure dan pelanggan saat memelihara kluster hibrid .
Pemadatan
Terdapat berbagai jenis pemadatan. Layanan ini saat ini melakukan pemadatan kecil dengan menggunakan perbaikan, Untuk informasi selengkapnya, lihat Pemeliharaan. Operasi ini melakukan pemadatan pohon Merkle, yang merupakan jenis pemadatan khusus.
Bergantung pada strategi pemadatan yang diatur pada tabel menggunakan CQL, misalnya
WITH compaction = { 'class' : 'LeveledCompactionStrategy' }, Cassandra secara otomatis memadatkan ketika tabel mencapai ukuran tertentu. Kami menyarankan agar Anda memilih strategi pemadatan dengan hati-hati untuk beban kerja Anda. Jangan melakukan pemadatan manual di luar strategi.
Penambalan
Patch tingkat Sistem Operasi dilakukan secara otomatis pada irama dua minggu.
Patch tingkat perangkat lunak Apache Cassandra dilakukan ketika kerentanan keamanan diidentifikasi. Ritme penambalan mungkin bervariasi.
Selama patching, mesin di-reboot satu rak pada satu waktu. Anda tidak boleh mengalami degradasi di sisi aplikasi selama pengaturan kuorum ALL tidak digunakan, dan faktor replikasi adalah 3 atau lebih tinggi.
Versi di Apache Cassandra ada dalam format
X.Y.Z. Anda dapat mengontrol penyebaran versi utama (X) dan minor (Y) secara manual dengan menggunakan alat layanan. Patch Cassandra (Z) yang mungkin diperlukan untuk kombinasi versi utama/minor tersebut dilakukan secara otomatis.
Catatan
Layanan saat ini mendukung versi Cassandra hingga v5.0. Untuk menentukan versi Cassandra saat Anda men-deploy kluster, lihat Azure CLI Quickstart.
Pemeliharaan
Layanan menjalankan nodetool repair dengan menggunakan reaper. Alat ini dijalankan setiap minggu sekali. Jika Anda menggunakan layanan Anda sendiri untuk penyebaran hibrid, Anda mungkin ingin menonaktifkan reaper.
Pemantauan kesehatan node terdiri dari:
- Secara aktif memantau keanggotaan masing-masing node di ring Cassandra.
- Mendeteksi secara otomatis dan memitigasi masalah infrastruktur seperti mesin virtual, jaringan, penyimpanan, Linux, dan kegagalan perangkat lunak pendukung.
- Memantau CPU, disk, kehilangan kuorum, dan masalah sumber daya lainnya secara proaktif.
- Mengaktifkan simpul yang gagal secara otomatis jika memungkinkan, dan mengaktifkan simpul secara manual sebagai respons terhadap peringatan otomatis.
Dukungan
Azure Managed Instance for Apache Cassandra menyediakan SLA untuk ketersediaan pusat data dalam kluster terkelola. Jika Anda mengalami masalah saat menggunakan layanan, ajukan permintaan dukungan di portal Azure.
Manfaat dukungan kami meliputi:
- Titik kontak tunggal untuk masalah infrastruktur Cassandra. Tidak perlu mengajukan kasus dukungan dengan tim IaaS seperti tim disk, tim komputasi, dan tim jaringan secara terpisah.
- Saran proaktif melalui email tentang hambatan performa, ukuran, dan kendala sumber daya lainnya.
- Cakupan dukungan 24x7, termasuk insiden yang dihasilkan secara otomatis untuk masalah pemadaman yang parah.
- Dukungan patch yang disetujui komunitas. Lihat Patching.
- Dukungan tim rekayasa Java JDK/JVM internal.
- Dukungan Sistem Operasi Linux dengan keamanan rantai pasokan perangkat lunak.
Penting
Microsoft menyelidiki dan mendiagnosis masalah apa pun yang dilaporkan dengan menggunakan kasus dukungan. Dukungan menyelesaikan atau mengurangi jika memungkinkan. Anda pada akhirnya bertanggung jawab atas penggunaan tingkat konfigurasi Apache Cassandra yang menyebabkan masalah CPU, disk, atau jaringan.
Contoh masalah tersebut meliputi:
- Operasi kueri yang tidak efisien.
- Throughput yang melebihi kapasitas.
- Menelan data yang melebihi kapasitas penyimpanan.
- Pengaturan konfigurasi keyspace yang salah.
- Model data yang buruk atau strategi kunci partisi.
Microsoft mungkin menyelidiki kasus dukungan dan menemukan bahwa penyebab masalah ada di tingkat konfigurasi Apache Cassandra. Masalah seperti itu tidak berasal dari aspek mendasar tingkat platform yang dikelola oleh Azure. Dukungan masih memberikan rekomendasi dan panduan tentang remediasi, atau mitigasi jika memungkinkan, sebelum mereka menutup kasus.
Kami menyarankan agar Anda mengaktifkan metrik dan terbiasa dengan integrasi monitor Azure kami untuk mencegah masalah tingkat aplikasi/konfigurasi umum di Apache Cassandra, seperti yang dijelaskan sebelumnya.
Peringatan
Azure Managed Instance for Apache Cassandra juga memungkinkan Anda menjalankan perintah nodetool dan sstable untuk administrasi DBA rutin. Untuk informasi selengkapnya, lihat perintah DBA untuk Azure Managed Instance for Apache Cassandra.
Beberapa perintah ini dapat mendesstabilisasi kluster Cassandra. Anda harus menjalankan perintah ini dengan hati-hati dan setelah diuji di lingkungan nonproduksi. Jika memungkinkan, terlebih dahulu gunakan opsi --dry-run. Microsoft tidak menawarkan SLA atau dukungan apa pun tentang masalah dengan menjalankan perintah yang mengubah konfigurasi atau tabel database default.
Pencadangan dan pemulihan
Pencadangan rekam jepret diaktifkan secara default dan diambil setiap 24 jam. Cadangan disimpan di akun Azure Blob Storage internal dan dipertahankan hingga dua hari (48 jam). Tidak ada biaya untuk dua cadangan awal. Pencadangan tambahan dikenakan biaya. Lihat harga. Untuk mengubah interval cadangan atau periode retensi, Anda dapat mengedit kebijakan di portal Microsoft Azure:

Untuk memulihkan dari cadangan yang ada, ajukan permintaan dukungan di portal Azure. Saat mengajukan kasus dukungan, Anda perlu:
Berikan ID cadangan dari portal untuk cadangan yang ingin Anda pulihkan. Anda dapat menemukan ID ini di portal Microsoft Azure:
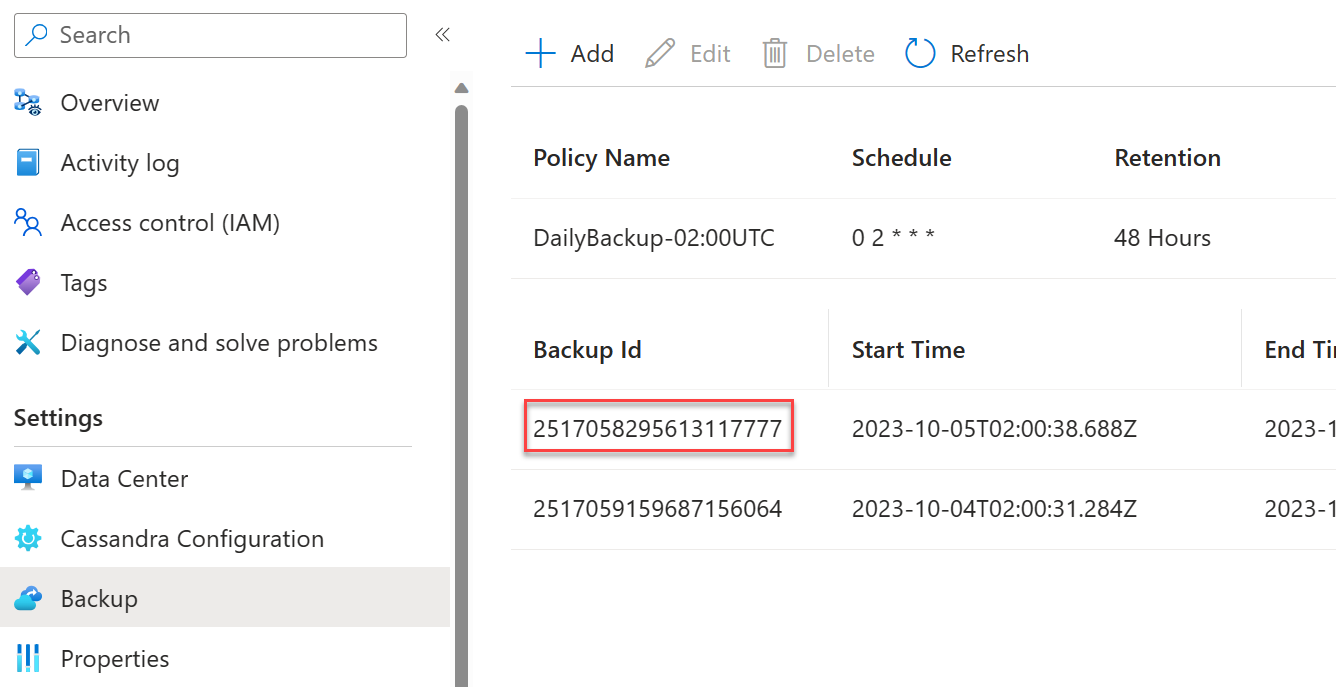
Beri tahu kami jika pusat data sumber dihapus. Fakta ini penting untuk mengidentifikasi akun cadangan yang benar untuk dipulihkan.
Jika Anda tidak perlu memulihkan seluruh kluster, berikan ruang kunci dan, jika berlaku, tabel yang perlu dipulihkan.
Sarankan apakah Anda ingin cadangan dipulihkan di kluster yang ada, atau di kluster baru.
Jika Anda ingin memulihkan ke kluster baru, Anda perlu membuat kluster baru terlebih dahulu. Pastikan bahwa kluster target cocok dengan kluster sumber dalam hal jumlah pusat data. Verifikasi bahwa pusat data yang sesuai memiliki jumlah simpul yang sama. Anda juga dapat memutuskan apakah akan menyimpan kredensial di kluster target baru. Izinkan pemulihan untuk menggantikan nama pengguna dan kata sandi menggunakan data yang awalnya dibuat.
Anda juga dapat memutuskan apakah akan menyimpan
system_authkeyspace di kluster target baru atau mengizinkan pemulihan untuk menimpanya dengan data dari cadangan. Ruangsystem_authkunci di Cassandra berisi data otorisasi dan autentikasi internal, termasuk peran, izin peran, dan kata sandi. Proses pemulihan default menimpasystem_authkeyspace.
Catatan
Waktu yang diperlukan untuk menanggapi permintaan untuk memulihkan dari cadangan tergantung pada tingkat keparahan kasus dukungan yang Anda naikkan, SLA untuk waktu respons, dan jumlah data yang akan dipulihkan. Kami tidak menyediakan SLA untuk waktu menyelesaikan pemulihan. Nilai tersebut tergantung pada waktu dan volume data yang dipulihkan.
Peringatan
Cadangan ditujukan untuk skenario penghapusan yang tidak disengaja dan tidak memiliki redundansi geografis. Kami tidak merekomendasikan pencadangan sebagai strategi pemulihan darurat (DR) untuk pemadaman regional. Untuk melindungi dari pemadaman di seluruh wilayah, kami merekomendasikan penyebaran beberapa wilayah. Untuk informasi selengkapnya, lihat panduan cepat untuk penyebaran di berbagai wilayah.
Keamanan
Azure Managed Instance for Apache Cassandra menyediakan banyak kontrol dan fitur keamanan eksplisit bawaan:
- Gambar mesin virtual Linux yang diperkokoh dengan rantai pasok yang terkendali.
- Pemantauan Kerentanan & Paparan Umum (CVE) di tingkat sistem operasi.
- Rotasi sertifikat untuk perangkat lunak Apache Cassandra dan Prometheus yang dihosting di Virtual Machines yang dikelola.
- Pemindaian kerentanan aktif.
- Pemindaian virus aktif.
- Praktik pengodean yang aman.
Untuk informasi selengkapnya tentang fitur keamanan, lihat Keamanan di Azure Managed Instance for Apache Cassandra.
Dukungan hibrida
Ketika kluster hibrid dikonfigurasi, operasi reaper otomatis yang dijalankan dalam layanan memberikan manfaat bagi seluruh kluster. Aspek ini mencakup pusat data yang tidak disediakan oleh layanan. Anda bertanggung jawab untuk mempertahankan pusat data lokal atau yang dihosting secara eksternal.