Mengindeks data dari file dan pintasan OneLake
Dalam artikel ini, pelajari cara mengonfigurasi pengindeks file OneLake untuk mengekstrak data dan data metadata yang dapat dicari dari lakehouse di atas OneLake.
Gunakan pengindeks ini untuk tugas-tugas berikut:
- Pengindeksan data dan pengindeksan bertahap: Pengindeks dapat mengindeks file dan metadata terkait dari jalur data dalam lakehouse. Ini mendeteksi file dan metadata baru dan diperbarui melalui deteksi perubahan bawaan. Anda dapat mengonfigurasi refresh data sesuai jadwal atau sesuai permintaan.
- Deteksi penghapusan: Pengindeks dapat mendeteksi penghapusan melalui metadata kustom untuk sebagian besar file dan pintasan. Ini mengharuskan penambahan metadata ke file untuk menandakan bahwa metadata tersebut telah "dihapus sementara", memungkinkan penghapusannya dari indeks pencarian. Saat ini, tidak dimungkinkan untuk mendeteksi penghapusan di file pintasan Google Cloud Storage atau Amazon S3 karena metadata kustom tidak didukung untuk sumber data tersebut.
- Applied AI melalui skillset: Skillsets didukung sepenuhnya oleh pengindeks file OneLake. Ini termasuk fitur utama seperti vektorisasi terintegrasi yang menambahkan langkah-langkah pemotongan dan penyematan data.
- Mode penguraian: Pengindeks mendukung mode penguraian JSON jika Anda ingin mengurai array atau baris JSON ke dalam dokumen pencarian individual.
- Kompatibilitas dengan fitur lain: Pengindeks OneLake dirancang untuk bekerja dengan mulus dengan fitur pengindeks lainnya, seperti sesi debug, cache pengindeks untuk pengayaan bertahap, dan penyimpanan pengetahuan.
Gunakan REST API pratinjau 2024-05-01, paket Azure SDK beta, atau Impor dan vektorisasi data di portal Azure untuk mengindeks dari OneLake.
Artikel ini menggunakan REST API untuk mengilustrasikan setiap langkah.
Prasyarat
Ruang kerja Fabric. Ikuti tutorial ini untuk membuat ruang kerja Fabric.
Sebuah lakehouse di ruang kerja Fabric. Ikuti tutorial ini untuk membuat lakehouse.
Data tekstual. Jika Anda memiliki data biner, Anda dapat menggunakan analisis gambar pengayaan AI untuk mengekstrak teks atau menghasilkan deskripsi gambar. Konten file tidak boleh melebihi batas pengindeks untuk tingkat layanan pencarian Anda.
Konten di lokasi File lakehouse Anda. Anda dapat menambahkan data dengan:
- Mengunggah ke lakehouse secara langsung
- Menggunakan alur data dari Microsoft Fabric
- Tambahkan pintasan dari sumber data eksternal seperti Amazon S3 atau Google Cloud Storage.
AI layanan Pencarian dikonfigurasi untuk identitas terkelola sistem atau identitas terkelola yang ditetapkan pengguna. Layanan Pencarian AI harus berada dalam penyewa yang sama dengan ruang kerja Microsoft Fabric.
Penetapan peran Kontributor di ruang kerja Microsoft Fabric tempat lakehouse berada. Langkah-langkah diuraikan di bagian Berikan izin di artikel ini.
Klien REST untuk merumuskan panggilan REST yang mirip dengan yang diperlihatkan dalam artikel ini.
Format dokumen yang didukung
Pengindeks file OneLake dapat mengekstrak teks dari format dokumen berikut:
- CSV (lihat Mengindeks blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (lihat Mengindeks blob JSON)
- KML (XML untuk representasi geografis)
- Format Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (email Outlook), XML (XML WORD 2003 dan 2006)
- Format Dokumen Terbuka: ODT, ODS, ODP
- File teks biasa (lihat juga Mengindeks teks biasa)
- RTF
- XML
- ZIP
Pintasan yang didukung
Pintasan OneLake berikut didukung oleh pengindeks file OneLake:
Pintasan OneLake (pintasan ke instans OneLake lainnya)
Batasan dalam pratinjau ini
Jenis file parquet (termasuk parquet delta) saat ini tidak didukung.
Penghapusan file tidak didukung untuk pintasan Amazon S3 dan Google Cloud Storage.
Pengindeks ini tidak mendukung konten lokasi Tabel ruang kerja OneLake.
Pengindeks ini tidak mendukung kueri SQL, tetapi kueri yang digunakan dalam konfigurasi sumber data secara eksklusif untuk menambahkan folder atau pintasan untuk diakses secara opsional.
Tidak ada dukungan untuk menyerap file dari ruang kerja Ruang Kerja Saya di OneLake karena ini adalah repositori pribadi per pengguna.
Menyiapkan data untuk pengindeksan
Sebelum Anda menyiapkan pengindeksan, tinjau data sumber Anda untuk menentukan apakah ada perubahan yang harus dibuat di muka. Pengindeks dapat mengindeks konten dari satu kontainer pada satu waktu. Secara default, semua file dalam kontainer diproses. Anda memiliki beberapa opsi untuk pemrosesan yang lebih selektif:
Tempatkan file dalam folder virtual. Definisi sumber data pengindeks menyertakan parameter "kueri" yang dapat berupa subfolder atau pintasan lakehouse. Jika nilai ini ditentukan, hanya file-file tersebut di subfolder atau pintasan dalam lakehouse yang diindeks.
Sertakan atau kecualikan file menurut jenis file. Daftar format dokumen yang didukung dapat membantu Anda menentukan file mana yang akan dikecualikan. Misalnya, Anda mungkin ingin mengecualikan file gambar atau audio yang tidak menyediakan teks yang dapat dicari. Kemampuan ini dikontrol melalui pengaturan konfigurasi di pengindeks.
Sertakan atau kecualikan file arbitrer. Jika Anda ingin melewati file tertentu karena alasan apa pun, Anda dapat menambahkan properti metadata dan nilai ke file di lakehouse OneLake Anda. Ketika pengindeks menemukan properti ini, pengindeks melompati file atau kontennya dalam pengindeksan berjalan.
Penyertaan dan pengecualian file tercakup dalam langkah konfigurasi pengindeks. Jika Anda tidak menetapkan kriteria, pengindeks melaporkan file yang tidak memenuhi syarat sebagai kesalahan dan melanjutkan. Jika terjadi kesalahan yang cukup, pemrosesan mungkin berhenti. Anda dapat menentukan toleransi kesalahan dalam pengaturan konfigurasi pengindeks.
Pengindeks biasanya membuat satu dokumen pencarian per file, di mana konten teks dan metadata diambil sebagai bidang yang dapat dicari dalam indeks. Jika file adalah seluruh file, Anda berpotensi mengurainya ke dalam beberapa dokumen pencarian. Misalnya, Anda dapat mengurai baris dalam file CSV untuk membuat satu dokumen pencarian per baris. Jika Anda perlu memotong satu dokumen menjadi bagian yang lebih kecil untuk mem-vektorisasi data, pertimbangkan untuk menggunakan vektorisasi terintegrasi.
Pengindeksan metadata file
Metadata file juga dapat diindeks, dan itu berguna jika Anda menganggap salah satu properti metadata standar atau kustom berguna dalam filter dan kueri.
Properti metadata yang ditentukan pengguna diekstrak verbatim. Untuk menerima nilai, Anda harus menentukan bidang dalam indeks pencarian jenis Edm.String, dengan nama yang sama dengan kunci metadata blob. Misalnya, jika blob memiliki kunci metadataPriority dengan nilai High, Anda harus menentukan bidang bernama Priority dalam indeks pencarian Anda dan itu akan diisi dengan nilai High.
Properti metadata file standar dapat diekstrak ke bidang bernama dan ditik yang sama, seperti yang tercantum di bawah ini. Pengindeks file OneLake secara otomatis membuat pemetaan bidang internal untuk properti metadata ini, mengonversi nama hiphenated asli ("metadata-storage-name") menjadi nama yang setara dengan garis bawah ("metadata_storage_name").
Anda masih harus menambahkan bidang garis bawah ke definisi indeks, tetapi Anda dapat menghilangkan pemetaan bidang pengindeks karena pengindeks membuat asosiasi secara otomatis.
metadata_storage_name (
Edm.String) - nama file. Misalnya, jika Anda memiliki file /mydatalake/my-folder/subfolder/resume.pdf, nilai bidang ini adalahresume.pdf.metadata_storage_path (
Edm.String) - URI penuh blob, termasuk akun penyimpanan. Misalnya:https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) - jenis konten seperti yang ditentukan oleh kode yang Anda gunakan untuk mengunggah blob. Contohnya,application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset) - tanda waktu terakhir yang dimodifikasi untuk blob. Azure AI Search menggunakan tanda waktu ini untuk mengidentifikasi blob yang diubah, untuk menghindari pengindeksan ulang semuanya setelah pengindeksan awal.metadata_storage_size (
Edm.Int64) - ukuran blob dalam byte.metadata_storage_content_md5 (
Edm.String) - MD5 hash dari konten blob, jika tersedia.
Terakhir, properti metadata apa pun khusus untuk format dokumen file yang Anda indeks juga dapat diwakili dalam skema indeks. Untuk informasi selengkapnya tentang metadata khusus konten, lihat Properti metadata konten.
Penting untuk menunjukkan bahwa Anda tidak perlu menentukan bidang untuk semua properti di atas dalam indeks pencarian Anda - cukup tangkap properti yang Anda butuhkan untuk aplikasi Anda.
Memberikan izin
Pengindeks OneLake menggunakan autentikasi token dan akses berbasis peran untuk koneksi ke OneLake. Izin ditetapkan di OneLake. Tidak ada persyaratan izin pada penyimpanan data fisik yang mendukung pintasan. Misalnya, jika Anda mengindeks dari AWS, Anda tidak perlu memberikan izin layanan pencarian di AWS.
Penetapan peran minimum untuk identitas layanan pencarian Anda adalah Kontributor.
Konfigurasikan sistem atau identitas yang dikelola pengguna untuk layanan Pencarian AI Anda.
Cuplikan layar berikut menunjukkan identitas terkelola sistem untuk layanan pencarian bernama "onelake-demo".
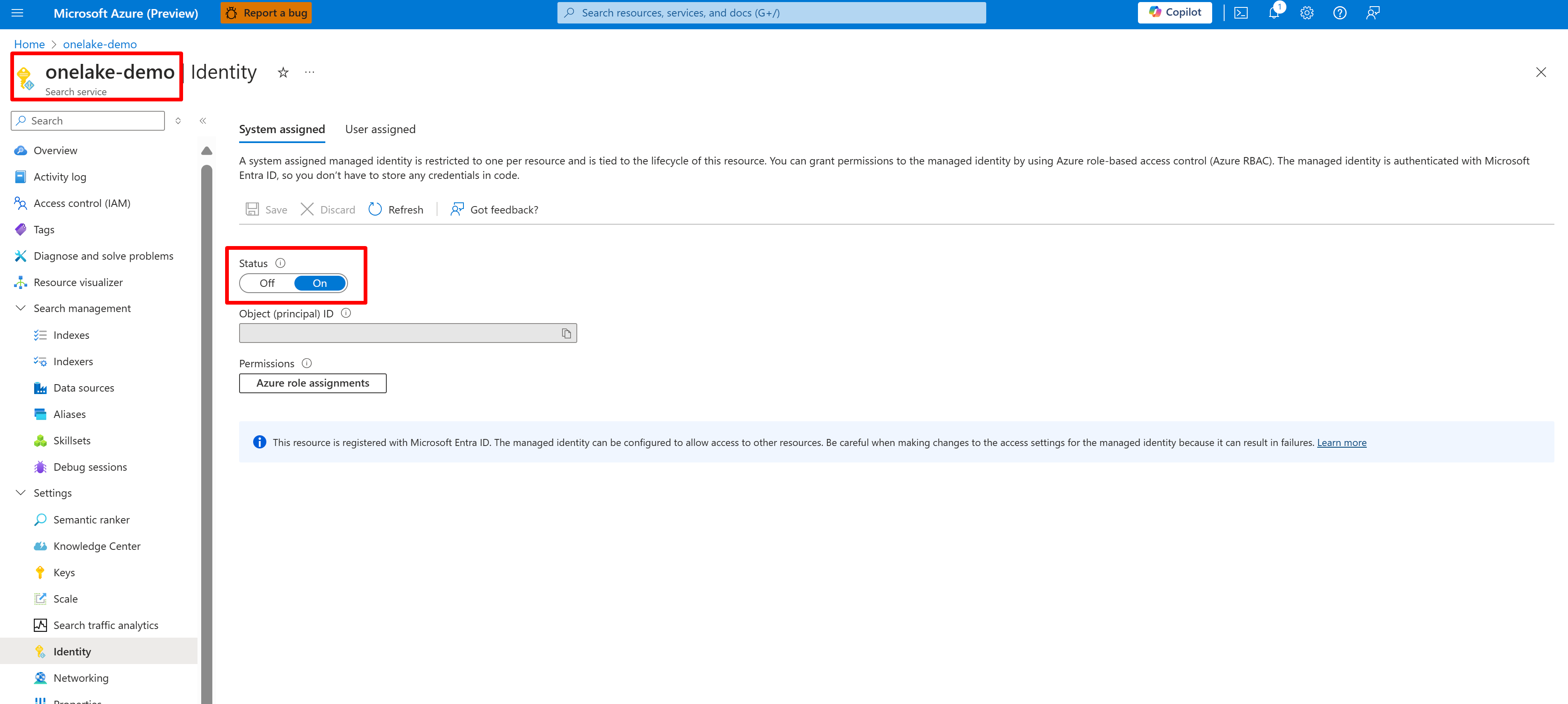
Cuplikan layar ini memperlihatkan identitas yang dikelola pengguna untuk layanan pencarian yang sama.
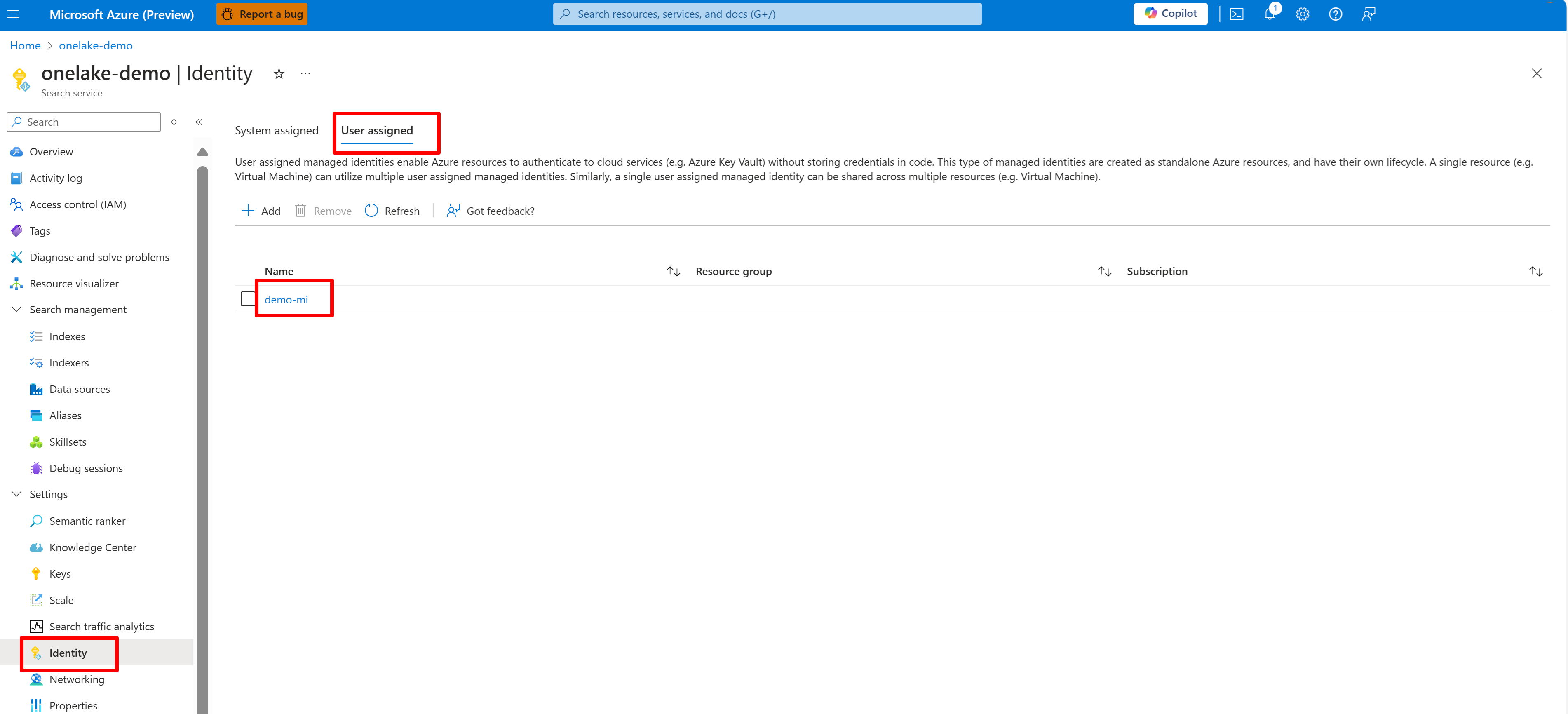
Berikan izin untuk akses layanan pencarian ke ruang kerja Fabric. Layanan pencarian membuat koneksi atas nama pengindeks.
Jika Anda menggunakan identitas terkelola yang ditetapkan sistem, cari nama layanan Pencarian AI. Untuk identitas terkelola yang ditetapkan pengguna, cari nama sumber daya identitas.
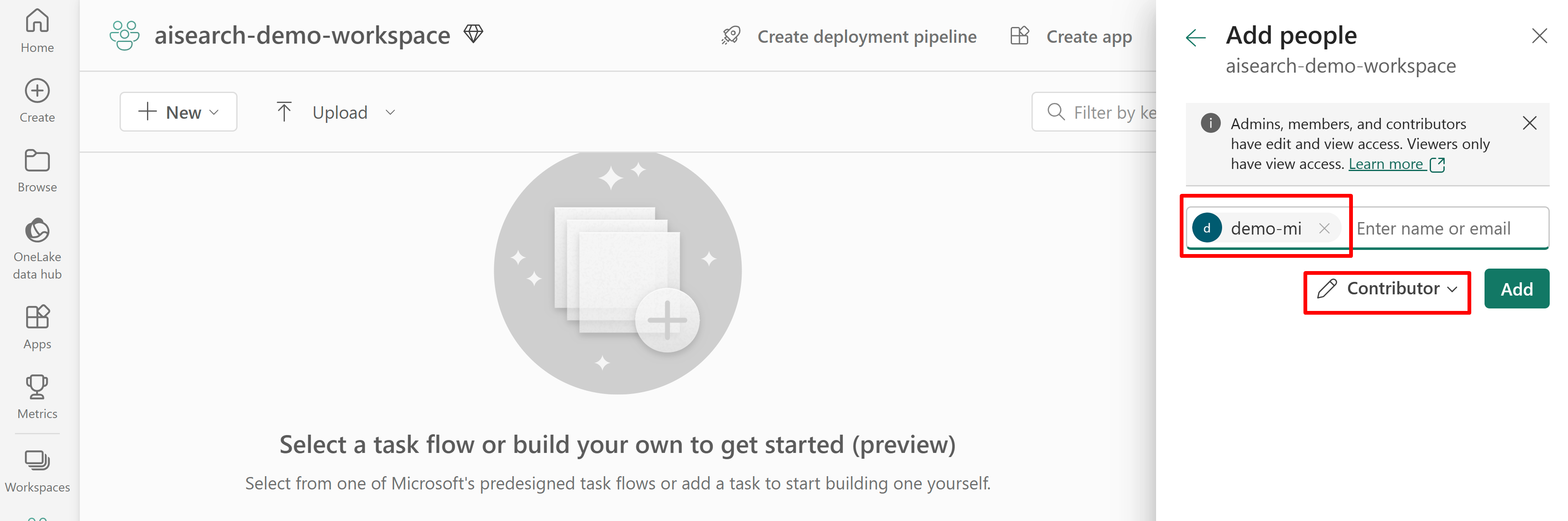
Cuplikan layar berikut menunjukkan penetapan peran Kontributor menggunakan identitas terkelola sistem.

Cuplikan layar ini memperlihatkan penetapan peran Kontributor menggunakan identitas terkelola sistem:




Menentukan sumber data
Sumber data didefinisikan sebagai sumber daya independen sehingga dapat digunakan oleh beberapa pengindeks. Anda harus menggunakan REST API pratinjau 2024-05-01 untuk membuat sumber data.
Gunakan REST API Buat atau perbarui sumber data untuk mengatur definisinya. Ini adalah langkah-langkah definisi yang paling signifikan.
Atur
"type"ke"onelake"(diperlukan).Dapatkan GUID ruang kerja Microsoft Fabric dan GUID lakehouse:
Buka lakehouse yang ingin Anda impor datanya dari URL-nya. Ini akan terlihat mirip dengan contoh ini: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Salin nilai berikut yang digunakan dalam definisi sumber data:
Salin GUID ruang kerja, yang akan kita panggil
{FabricWorkspaceGuid}, yang tercantum tepat setelah "grup" di URL. Dalam contoh ini, akan menjadi 000000000-0000-0000-0000-0000000000000.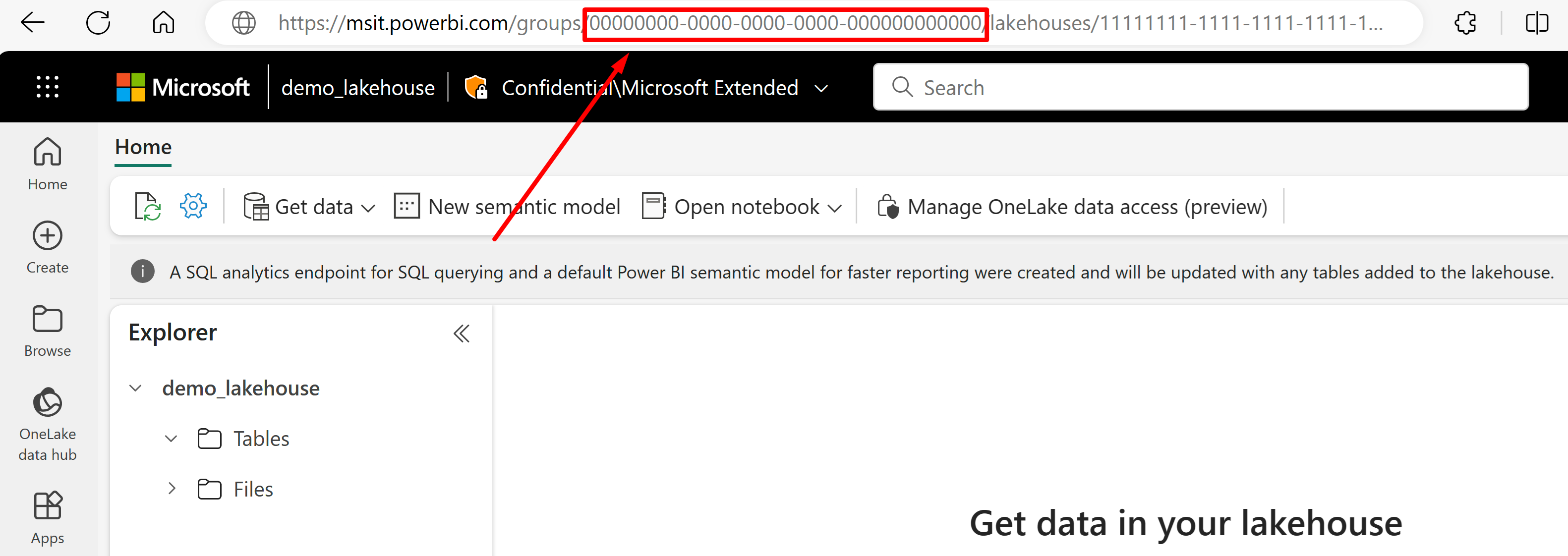
Salin GUID lakehouse yang akan kami panggil
{lakehouseGuid}, yang tercantum tepat setelah "lakehouses" di URL. Dalam contoh ini, akan menjadi 111111111-1111-1111-1111-11111111111111.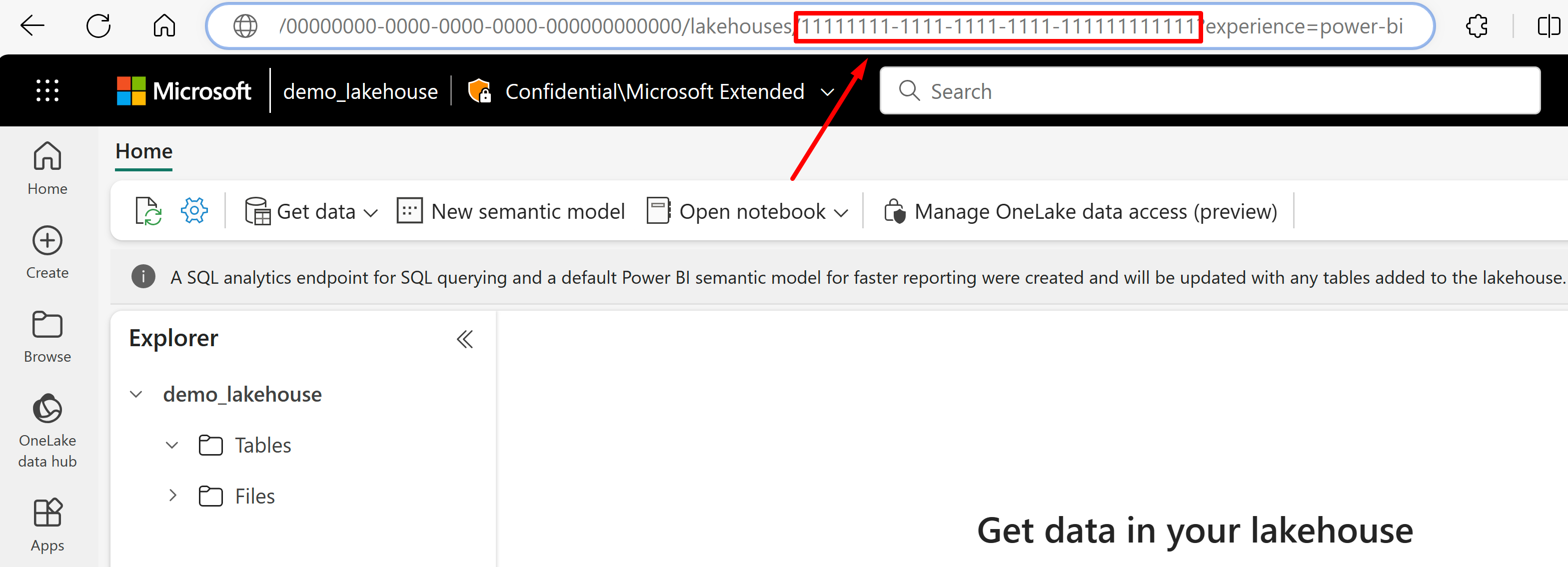
Atur
"credentials"ke GUID ruang kerja Microsoft Fabric dengan mengganti{FabricWorkspaceGuid}dengan nilai yang Anda salin di langkah sebelumnya. Ini adalah OneLake untuk diakses dengan identitas terkelola yang akan Anda siapkan nanti dalam panduan ini."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Atur
"container.name"ke GUID lakehouse, ganti{lakehouseGuid}dengan nilai yang Anda salin di langkah sebelumnya. Gunakan"query"untuk menentukan subfolder atau pintasan lakehouse secara opsional."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Atur metode autentikasi menggunakan identitas terkelola yang ditetapkan pengguna, atau lewati ke langkah berikutnya untuk identitas yang dikelola sistem.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Nilai
userAssignedIdentitydapat ditemukan dengan mengakses{userAssignedManagedIdentity}sumber daya, di bawah Properti dan disebutId.
Contoh:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=00000000-0000-0000-0000-000000000000" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Secara opsional, gunakan identitas terkelola yang ditetapkan sistem sebagai gantinya. "Identitas" dihapus dari definisi jika menggunakan identitas terkelola yang ditetapkan sistem.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Contoh:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=00000000-0000-0000-0000-000000000000" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Mendeteksi penghapusan melalui metadata kustom
Definisi sumber data pengindeks file OneLake dapat menyertakan kebijakan penghapusan sementara jika Anda ingin pengindeks menghapus dokumen pencarian saat dokumen sumber ditandai untuk dihapus.
Untuk mengaktifkan penghapusan file otomatis, gunakan metadata kustom untuk menunjukkan apakah dokumen pencarian harus dihapus dari indeks.
Alur kerja memerlukan tiga tindakan terpisah:
- "Soft-delete" file di OneLake
- Pengindeks menghapus dokumen pencarian dalam indeks
- "Hard delete" file di OneLake
"Penghapusan sementara" memberi tahu pengindeks apa yang harus dilakukan (menghapus dokumen pencarian). Jika Anda menghapus file fisik di OneLake terlebih dahulu, tidak ada yang dapat dibaca oleh pengindeks dan dokumen pencarian yang sesuai dalam indeks tidak memiliki intim.
Ada langkah-langkah yang harus diikuti di OneLake dan Azure AI Search, tetapi tidak ada dependensi fitur lainnya.
Dalam file lakehouse, tambahkan pasangan kunci-nilai metadata kustom ke file untuk menunjukkan bahwa file ditandai untuk dihapus. Misalnya, Anda dapat memberi nama properti "IsDeleted", diatur ke false. Ketika Anda ingin menghapus file, ubah ke true.
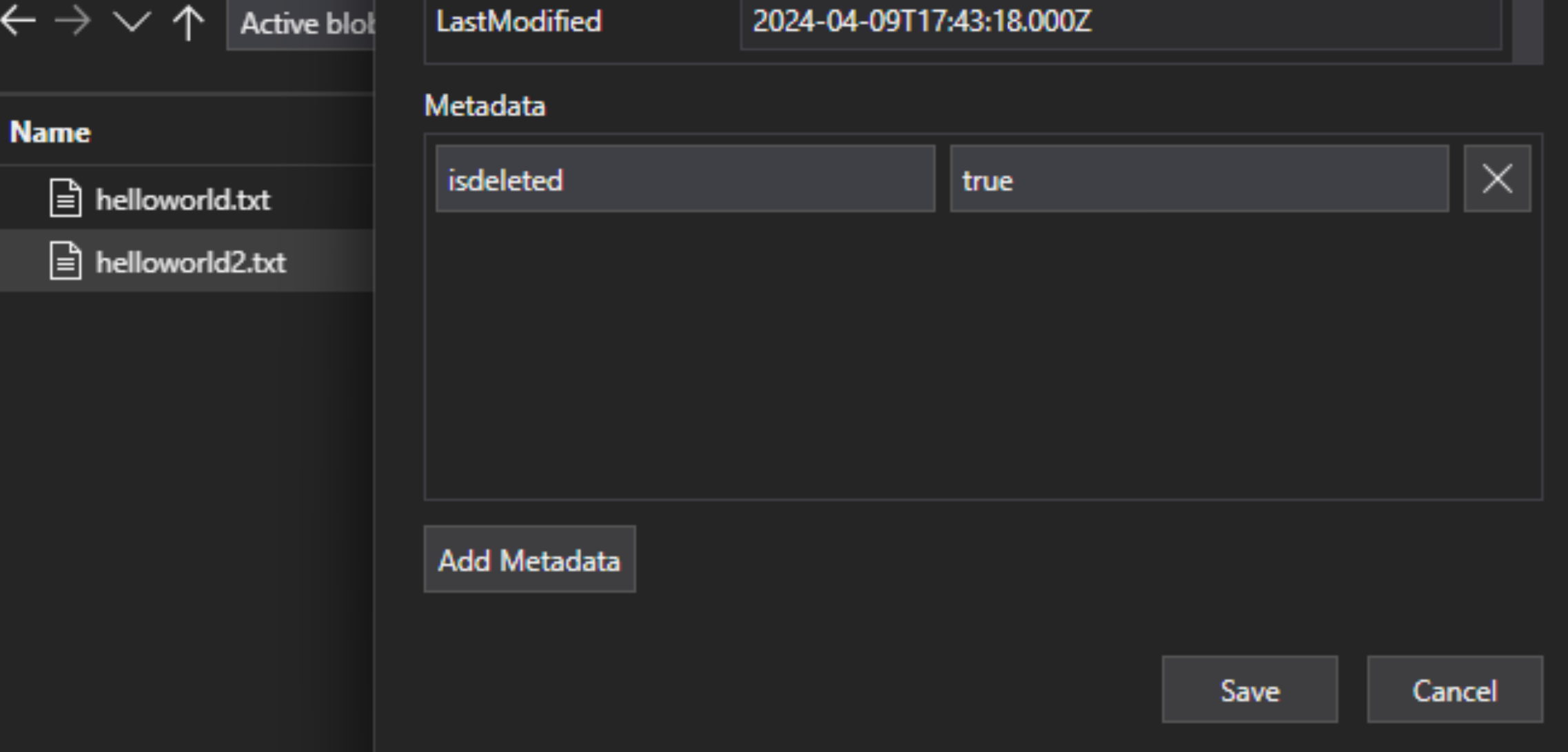
Di Azure AI Search, edit definisi sumber data untuk menyertakan properti "dataDeletionDetectionPolicy". Misalnya, kebijakan berikut mempertimbangkan file untuk dihapus jika memiliki properti metadata "IsDeleted" dengan nilai true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Setelah pengindeks menjalankan dan menghapus dokumen dari indeks pencarian, Anda kemudian dapat menghapus file fisik di data lake.
Beberapa poin utama meliputi:
Menjadwalkan eksekusi pengindeks membantu mengotomatiskan proses ini. Kami merekomendasikan jadwal untuk semua skenario pengindeksan bertahap.
Jika kebijakan deteksi penghapusan tidak diatur pada pengindeks pertama yang dijalankan, Anda harus mengatur ulang pengindeks sehingga membaca konfigurasi yang diperbarui.
Ingat bahwa deteksi penghapusan tidak didukung untuk pintasan Amazon S3 dan Google Cloud Storage karena dependensi pada metadata kustom.
Menambahkan bidang pencarian ke indeks
Dalam indeks pencarian, tambahkan bidang untuk menerima konten dan metadata file data lake OneLake Anda.
Buat atau perbarui indeks untuk menentukan bidang pencarian yang menyimpan konten file dan metadata:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Buat bidang kunci dokumen ("key": true). Untuk konten file, kandidat terbaik adalah properti metadata.
metadata_storage_path(default) jalur lengkap ke objek atau file. Bidang kunci ("ID" dalam contoh ini) diisi dengan nilai dari metadata_storage_path karena merupakan default.metadata_storage_name, hanya dapat digunakan jika nama unik. Jika Anda ingin bidang ini sebagai kunci, pindahkan"key": trueke definisi bidang ini.Properti metadata kustom yang Anda tambahkan ke file Anda. Opsi ini mengharuskan proses pengunggahan file Anda menambahkan properti metadata tersebut ke semua blob. Karena kunci adalah properti yang diperlukan, file apa pun yang kehilangan nilai gagal diindeks. Jika Anda menggunakan properti metadata kustom sebagai kunci, hindari membuat perubahan pada properti tersebut. Pengindeks menambahkan dokumen duplikat untuk file yang sama jika properti kunci berubah.
Properti metadata sering menyertakan karakter, seperti
/dan-, yang tidak valid untuk kunci dokumen. Karena pengindeks memiliki properti "base64EncodeKeys" (true secara default), pengindeks secara otomatis mengodekan properti metadata, tanpa memerlukan konfigurasi atau pemetaan bidang.Tambahkan bidang "konten" untuk menyimpan teks yang diekstrak dari setiap file melalui properti "konten" file. Anda tidak diharuskan menggunakan nama ini, tetapi melakukannya memungkinkan Anda memanfaatkan pemetaan bidang implisit.
Tambahkan bidang untuk properti metadata standar. Pengindeks dapat membaca properti metadata kustom, properti metadata standar, dan properti metadata khusus konten.
Mengonfigurasi dan menjalankan pengindeks file OneLake
Setelah indeks dan sumber data dibuat, Anda siap untuk membuat pengindeks. Konfigurasi pengindeks menentukan input, parameter, dan properti yang mengontrol perilaku run time. Anda juga dapat menentukan bagian mana dari blob yang akan diindeks.
Buat atau perbarui pengindeks dengan memberinya nama dan mereferensikan sumber data dan indeks target:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Atur "batchSize" jika default (10 dokumen) sedang menggunakan atau membangi sumber daya yang tersedia. Ukuran batch default berukuran spesifik sumber data. Pengindeksan file menetapkan ukuran batch pada 10 dokumen sebagai pengenalan ukuran dokumen rata-rata yang lebih besar.
Di bagian "konfigurasi", kontrol file mana yang diindeks berdasarkan jenis file, atau biarkan tidak ditentukan untuk mengambil semua file.
Untuk
"indexedFileNameExtensions", berikan daftar ekstensi file yang dipisahkan koma (dengan titik terdepan). Lakukan hal yang sama untuk"excludedFileNameExtensions"menunjukkan ekstensi mana yang harus dilewati. Jika ekstensi yang sama ada di kedua daftar, ekstensi tersebut dikecualikan dari pengindeksan.Di bagian "konfigurasi", atur "dataToExtract" untuk mengontrol bagian file mana yang diindeks:
"contentAndMetadata" adalah default. Ini menentukan bahwa semua metadata dan konten tekstual yang diekstrak dari file diindeks.
"storageMetadata" menentukan bahwa hanya properti file standar dan metadata yang ditentukan pengguna yang diindeks. Meskipun properti didokumenkan untuk blob Azure, properti file sama untuk OneLkae, kecuali untuk metadata terkait SAS.
"allMetadata" menentukan bahwa properti file standar dan metadata apa pun untuk jenis konten yang ditemukan diekstrak dari konten file dan diindeks.
Di bagian "konfigurasi", atur "parsingMode" jika file harus dipetakan ke beberapa dokumen pencarian, atau jika terdiri dari teks biasa, dokumen JSON, atau file CSV.
Tentukan pemetaan bidang jika ada perbedaan dalam nama atau jenis bidang, atau jika Anda memerlukan beberapa versi bidang sumber dalam indeks pencarian.
Dalam pengindeksan file, Anda sering dapat menghilangkan pemetaan bidang karena pengindeks memiliki dukungan bawaan untuk memetakan properti "konten" dan metadata ke bidang bernama dan ditik yang sama dalam indeks. Untuk properti metadata, pengindeks secara otomatis mengganti tanda hubung
-dengan garis bawah dalam indeks pencarian.
Untuk informasi selengkapnya tentang properti lain, Buat pengindeks. Untuk daftar lengkap deskripsi parameter, lihat Parameter konfigurasi blob di REST API. Parameternya sama untuk OneLake.
Secara default, pengindeks berjalan secara otomatis saat Anda membuatnya. Anda dapat mengubah perilaku ini dengan mengatur "dinonaktifkan" ke true. Untuk mengontrol eksekusi pengindeks, jalankan pengindeks sesuai permintaan atau letakkan sesuai jadwal.
Periksa status pengindeks
Pelajari beberapa pendekatan untuk memantau status pengindeks dan riwayat eksekusi di sini.
Menangani kesalahan
Kesalahan yang umumnya terjadi selama pengindeksan mencakup jenis konten yang tidak didukung, konten yang hilang, atau file yang terlalu besar. Secara default, pengindeks file OneLake berhenti segera setelah menemukan file dengan tipe konten yang tidak didukung. Namun, Anda mungkin ingin pengindeksan dilanjutkan meskipun terjadi kesalahan, lalu debug dokumen individual nanti.
Kesalahan sementara umum untuk solusi yang melibatkan beberapa platform dan produk. Namun, jika Anda menjaga pengindeks tetap sesuai jadwal (misalnya setiap 5 menit), pengindeks harus dapat memulihkan dari kesalahan tersebut dalam eksekusi berikut.
Ada lima properti pengindeks yang mengontrol respons pengindeks saat kesalahan terjadi.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parameter | Nilai yang valid | Deskripsi |
|---|---|---|
| "maxFailedItems" | -1, null atau 0, bilangan bulat positif | Lanjutkan pengindeksan jika terjadi kesalahan pada titik pemrosesan apa pun, baik saat mengurai blob atau saat menambahkan dokumen ke indeks. Atur properti ini ke jumlah kegagalan yang dapat diterima. Nilai -1 memungkinkan pemrosesan tidak peduli berapa banyak kesalahan yang terjadi. Jika tidak, nilainya adalah bilangan bulat positif. |
| "maxFailedItemsPerBatch" | -1, null atau 0, bilangan bulat positif | Sama seperti di atas, tetapi digunakan untuk pengindeksan batch. |
| "failOnUnsupportedContentType" | BENAR atau SALAH | Jika pengindeks tidak dapat menentukan tipe konten, tentukan apakah akan melanjutkan atau gagal pekerjaan. |
| "failOnUnprocessableDocument" | BENAR atau SALAH | Jika pengindeks tidak dapat memproses dokumen dari jenis konten yang didukung, tentukan apakah akan melanjutkan atau gagal pekerjaan. |
| "indexStorageMetadataOnlyForOversizedDocuments" | BENAR atau SALAH | Blob yang terlalu besar diperlakukan sebagai kesalahan secara default. Jika Anda mengatur parameter ini ke true, pengindeks mencoba mengindeks metadatanya meskipun konten tidak dapat diindeks. Untuk batasan ukuran blob, lihat Batas layanan. |
Langkah berikutnya
Tinjau cara kerja wizard Impor dan vektorisasi data dan cobalah untuk pengindeks ini. Anda dapat menggunakan vektorisasi terintegrasi untuk memotong dan membuat penyematan untuk pencarian vektor atau hibrid menggunakan skema default.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk