Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini adalah bagian pertama dari tujuh seri bagian yang memberikan panduan tentang cara bermigrasi dari Netezza ke Azure Synapse Analytics. Fokus artikel ini adalah praktik terbaik untuk desain dan performa.
Gambaran Umum
Karena akhir dukungan dari IBM, banyak pengguna sistem gudang data Netezza yang ada yang ingin memanfaatkan inovasi yang disediakan oleh lingkungan cloud modern. Lingkungan cloud Infrastruktur sebagai layanan (IaaS) dan platform as a service (PaaS) memungkinkan Anda mendelegasikan tugas seperti pemeliharaan infrastruktur dan pengembangan platform ke penyedia cloud.
Tips
Lebih dari sekadar database—lingkungan Azure mencakup serangkaian kemampuan dan alat yang komprehensif.
Meskipun Netezza dan Azure Synapse Analytics merupakan database SQL yang menggunakan teknik pemrosesan paralel masif (MPP) untuk mencapai performa kueri yang tinggi pada volume data yang sangat besar, ada beberapa perbedaan mendasar dalam pendekatan:
Sistem Netezza lama sering diinstal secara lokal dan menggunakan perangkat keras eksklusif, sementara Azure Synapse berbasis cloud dan menggunakan penyimpanan Azure dan sumber daya komputasi.
Memutakhirkan konfigurasi Netezza adalah tugas utama yang melibatkan perangkat keras fisik tambahan dan kemungkinan konfigurasi ulang database yang panjang, atau cadangan dan isi ulang. Karena sumber daya penyimpanan dan komputasi terpisah di lingkungan Azure serta memiliki kemampuan penskalaan elastis, sumber daya tersebut dapat ditingkatkan atau diturunkan secara independen.
Anda dapat menjeda atau mengubah ukuran Azure Synapse sesuai kebutuhan untuk mengurangi pemanfaatan sumber daya dan biaya.
Microsoft Azure adalah lingkungan cloud yang tersedia secara global, sangat aman, serta dapat diskalakan, yang mencakup Azure Synapse dan ekosistem alat dan kemampuan pendukung. Diagram berikutnya meringkas ekosistem Azure Synapse.
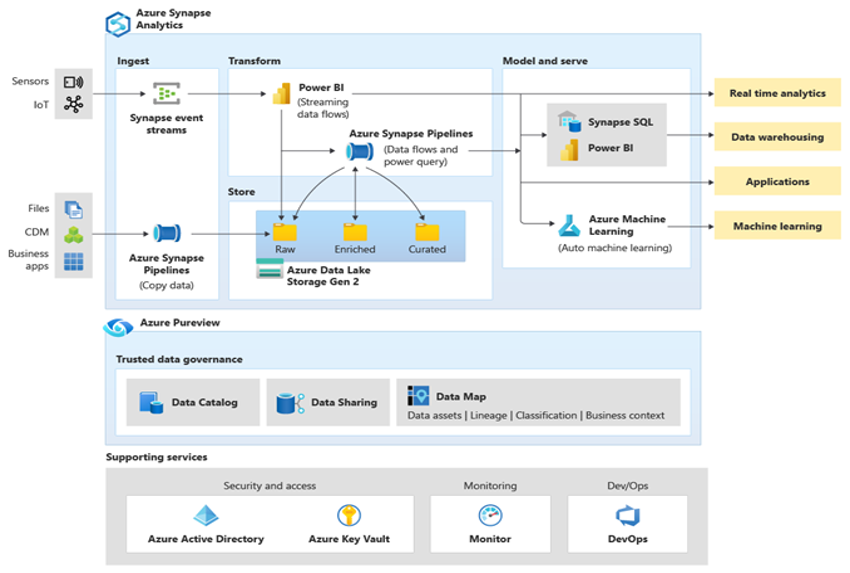
Azure Synapse memberikan performa database relasional terbaik menggunakan teknik seperti MPP dan berbagai tingkat cache otomatis untuk data yang sering digunakan. Anda dapat melihat hasil teknik ini dalam tolok ukur independen seperti yang dijalankan baru-baru ini oleh GigaOm, yang membandingkan Azure Synapse dengan penawaran gudang data cloud populer lainnya. Pelanggan yang bermigrasi ke lingkungan Azure Synapse melihat banyak keuntungan, meliputi:
Peningkatan kinerja dan rasio harga/kinerja.
Peningkatan kelincahan dan waktu yang lebih singkat untuk mencapai nilai.
Penyebaran server yang lebih cepat dan pengembangan aplikasi.
Skalabilitas elastis—hanya membayar penggunaan sebenarnya.
Peningkatan keamanan/kepatuhan.
Mengurangi biaya penyimpanan dan pemulihan bencana.
TCO keseluruhan yang lebih rendah, kontrol biaya yang lebih baik, dan pengeluaran operasional yang efisien (OPEX).
Untuk memaksimalkan manfaat ini, migrasi data dan aplikasi baru atau yang sudah ada ke platform Azure Synapse. Di banyak organisasi, migrasi mencakup pemindahan gudang data yang ada dari platform lokal lama, seperti Netezza, ke Azure Synapse. Pada tingkat tinggi, proses migrasi mencakup langkah-langkah ini:
Persiapan 🡆
Tentukan cakupan—apa yang akan dimigrasikan.
Bangun inventaris data dan proses untuk migrasi.
Tentukan perubahan model data (jika ada).
Tentukan mekanisme ekstrak data sumber.
Identifikasi alat dan fitur Azure serta pihak ketiga yang sesuai untuk digunakan.
Latih staf lebih awal di platform baru.
Siapkan platform target Azure.
Migrasi 🡆
Mulai dari yang kecil dan sederhana.
Otomatiskan jika memungkinkan.
Manfaatkan alat dan fitur bawaan Azure untuk mengurangi upaya migrasi.
Migrasikan metadata untuk tabel dan tampilan.
Migrasikan data historis yang akan dipertahankan.
Lakukan migrasi atau menata ulang prosedur tersimpan dan proses bisnis.
Migrasikan atau refaktor proses pemuatan inkremental ETL/ELT.
Pascamigrasi
Pantau dan dokumentasikan semua tahapan proses.
Gunakan pengalaman yang diperoleh untuk membuat templat untuk migrasi mendatang.
Rekayasa ulang model data jika diperlukan (menggunakan performa dan skalabilitas platform baru).
Uji aplikasi dan alat kueri.
Tolok ukur dan optimalkan performa kueri.
Artikel ini menyediakan informasi umum dan panduan optimasi performa saat memigrasikan gudang data dari lingkungan Netezza yang ada ke Azure Synapse. Tujuan optimasi performa adalah untuk mencapai performa gudang data yang sama atau lebih baik dalam Azure Synapse setelah migrasi skema.
Pertimbangan Desain
Cakupan migrasi
Saat Anda bersiap untuk bermigrasi dari lingkungan Netezza, pertimbangkan pilihan migrasi berikut.
Pilih beban kerja untuk migrasi awal
Biasanya, lingkungan Netezza lama berevolusi dari waktu ke waktu untuk mencakup beberapa bidang subjek dan beban kerja campuran. Saat Anda memutuskan dari mana memulai proyek migrasi, pilih area yang akan dapat:
Membuktikan kelayakan migrasi ke Azure Synapse dengan memberikan manfaat lingkungan baru dengan cepat.
Memungkinkan staf teknis internal Anda untuk mendapatkan pengalaman yang sesuai dengan proses dan alat yang akan mereka gunakan saat mereka memigrasikan area lain.
Membuat templat untuk migrasi lebih lanjut khusus untuk lingkungan Netezza sumber serta alat dan proses saat ini yang sudah ada.
Seorang kandidat yang baik untuk migrasi awal dari lingkungan Netezza mendukung poin-poin sebelumnya, dan:
Menerapkan beban kerja BI/Analitik daripada beban kerja pemrosesan transaksi online (OLTP).
Memiliki model data, seperti bintang atau skema snowflake, yang dapat dimigrasikan dengan modifikasi minimal.
Tips
Buat inventaris objek yang perlu dimigrasikan, dan dokumentasikan proses migrasi.
Volume data yang dimigrasikan dalam migrasi awal harus cukup besar untuk menunjukkan kemampuan dan keuntungan lingkungan Azure Synapse tetapi tidak terlalu besar untuk menunjukkan nilai dengan cepat. Ukuran dalam rentang 1-10 terabyte merupakan ukuran umum.
Untuk proyek migrasi awal Anda, minimalkan risiko, upaya, dan waktu migrasi sehingga Anda dapat dengan cepat melihat manfaat lingkungan cloud Azure. Pendekatan migrasi lift-and-shift dan bertahap membatasi cakupan migrasi awal hanya pada pusat data dan tidak menyinggung aspek migrasi yang lebih luas, seperti migrasi ETL dan migrasi data historis. Namun, Anda dapat mengatasi aspek-aspek tersebut di fase proyek selanjutnya setelah lapisan data mart yang dimigrasikan diisi ulang dengan data dan proses build yang diperlukan.
Migrasi 'lift and shift' vs. pendekatan bertahap
Secara umum, ada dua jenis migrasi, apa pun tujuan dan cakupan migrasi yang direncanakan: lift and shift apa adanya dan pendekatan bertahap yang menggabungkan perubahan.
Angkat dan pindahkan
Dalam migrasi lift and shift, model data yang ada, seperti skema bintang, dimigrasikan tanpa perubahan ke platform Azure Synapse baru. Pendekatan ini meminimalkan risiko dan waktu migrasi dengan mengurangi pekerjaan yang diperlukan untuk mewujudkan menfaat berpindah ke lingkungan cloud Azure. Migrasi angkat dan pindah sangat sesuai untuk skenario berikut:
- Anda memiliki lingkungan Netezza yang ada dengan data mart tunggal untuk dimigrasikan, atau
- Anda memiliki lingkungan Netezza yang sudah ada dengan data yang sudah berada dalam skema bintang atau skema snowflake yang dirancang dengan baik, atau
- Anda berada di bawah tekanan waktu dan biaya untuk berpindah ke lingkungan cloud modern.
Tips
Lift and shift adalah langkah awal yang baik, meskipun pada tahap berikutnya menerapkan perubahan pada model data.
Pendekatan bertahap yang menggabungkan perubahan
Jika gudang data lama telah berevolusi dalam jangka waktu yang lama, Anda mungkin perlu merekayasa ulang untuk mempertahankan tingkat performa yang diperlukan. Anda mungkin juga harus merekayasa ulang untuk mendukung data baru seperti aliran Internet of Things (IoT). Sebagai bagian dari proses rekayasa ulang, migrasikan ke Azure Synapse untuk mendapatkan manfaat dari lingkungan cloud yang dapat diskalakan. Migrasi juga dapat mencakup perubahan dalam model data yang mendasarinya, seperti perpindahan dari model Inmon ke brankas data.
Microsoft merekomendasikan untuk memindahkan model data yang ada apa adanya ke Azure dan menggunakan performa serta fleksibilitas lingkungan Azure untuk menerapkan perubahan rekayasa ulang. Dengan demikian, Anda dapat menggunakan kemampuan Azure untuk membuat perubahan tanpa memengaruhi sistem sumber yang ada.
Menggunakan Azure Data Factory untuk menerapkan migrasi berbasis metadata
Anda dapat mengotomatiskan dan mengatur proses migrasi menggunakan kemampuan lingkungan Azure. Pendekatan ini meminimalkan dampak kinerja pada lingkungan Netezza yang sudah ada, yang mungkin sudah beroperasi mendekati kapasitas.
Azure Data Factory adalah layanan integrasi data berbasis cloud yang mendukung pembuatan alur kerja berbasis data di cloud yang mengatur serta mengotomatiskan pergerakan data dan transformasi data. Anda dapat menggunakan Data Factory untuk membuat dan menjadwalkan alur kerja berbasis data (pipeline) yang mengambil data dari sumber data berbeda. Data Factory dapat memproses dan mengubah data dengan menggunakan layanan komputasi seperti Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics, dan Azure Machine Learning.
Saat Anda berencana menggunakan fasilitas Data Factory untuk mengelola proses migrasi, buat metadata yang mencantumkan semua tabel data yang akan dimigrasikan serta lokasinya.
Perbedaan desain antara Netezza dan Azure Synapse
Seperti disebutkan sebelumnya, ada beberapa perbedaan dasar dalam pendekatan antara database Netezza dan Azure Synapse Analytics dan perbedaan ini dibahas berikutnya.
Beberapa database versus satu database dan skema
Lingkungan Netezza sering memuat beberapa database terpisah. Misalnya, mungkin ada database terpisah untuk: tabel penyerapan dan staging data, tabel gudang inti, dan mart data (terkadang disebut sebagai lapisan semantik). Proses alur ETL atau ELT mungkin menerapkan gabungan lintas database dan memindahkan data di antara database terpisah.
Sebaliknya, lingkungan Azure Synapse berisi database tunggal dan menggunakan skema untuk memisahkan tabel ke dalam grup yang terpisah secara logis. Kami menyarankan agar Anda menggunakan serangkaian skema dalam database Azure Synapse tujuan untuk meniru database terpisah yang dimigrasikan dari lingkungan Netezza. Jika lingkungan Netezza sudah menggunakan skema, Anda mungkin perlu menggunakan konvensi penamaan baru saat memindahkan tabel dan tampilan Netezza yang ada ke lingkungan baru. Misalnya, Anda dapat menggabungkan skema Netezza dan nama tabel yang ada ke dalam nama tabel Azure Synapse yang baru, dan menggunakan nama skema di lingkungan baru untuk mempertahankan nama database terpisah yang asli. Jika penamaan konsolidasi skema memiliki titik, Azure Synapse Spark mungkin mengalami masalah. Meskipun Anda dapat menggunakan tampilan SQL di atas tabel yang mendasarinya untuk mempertahankan struktur logis, ada potensi kerugian untuk pendekatan itu:
Tampilan di Azure Synapse bersifat baca-saja, jadi setiap pembaruan data harus dilakukan di tabel dasar yang mendasarinya.
Mungkin sudah ada satu atau beberapa lapisan tampilan yang ada serta menambahkan lapisan tampilan tambahan dapat memengaruhi performa dan dukungan karena tampilan berlapis sulit untuk dipecahkan masalahnya.
Tips
Gabungkan beberapa database menjadi satu database dalam Azure Synapse dan gunakan nama skema untuk memisahkan tabel secara logis.
Pertimbangan tabel
Saat Anda memigrasikan tabel antara lingkungan yang berbeda, biasanya hanya data mentah dan metadata yang menjelaskannya yang dimigrasikan secara fisik. Elemen database lain dari sistem sumber, seperti indeks, biasanya tidak dimigrasikan karena mungkin tidak perlu atau diimplementasikan secara berbeda di lingkungan baru.
Optimasi performa di lingkungan sumber, seperti indeks, menunjukkan tempat Anda dapat menambahkan optimasi performa di lingkungan baru. Misalnya, jika kueri di lingkungan Netezza sumber sering menggunakan peta zona, ini menunjukkan bahwa indeks non-kluster harus dibuat dalam Azure Synapse. Teknik pengoptimalan performa native lainnya seperti replikasi tabel mungkin lebih dapat diterapkan daripada pembuatan indeks like-for-like langsung.
Tips
Indeks yang ada menunjukkan kandidat untuk pengindeksan di gudang yang dimigrasikan.
Tipe objek database Netezza yang tidak didukung
Fitur khusus Netezza sering kali dapat diganti dengan fitur Azure Synapse. Namun, beberapa objek database Netezza tidak didukung langsung di Azure Synapse. Daftar objek database Netezza yang tidak didukung berikut ini menjelaskan bagaimana Anda bisa mencapai fungsionalitas yang setara dalam Azure Synapse.
Peta Zona: Di Netezza, peta zona dibuat dan dipelihara secara otomatis untuk jenis kolom berikut dan digunakan pada waktu kueri untuk membatasi jumlah data yang akan dipindai.
-
INTEGERkolom dengan panjang 8 byte atau kurang. - Kolom temporal, seperti
DATE,TIME, danTIMESTAMP. - Kolom
CHARjika merupakan bagian dari tampilan yang terwujud dan disebutkan dalam klausaORDER BY.
Anda dapat mengetahui kolom mana yang memiliki peta zona dengan menggunakan utilitas
nz_zonemap, yang merupakan bagian dari NZ Toolkit. Azure Synapse tidak menyertakan peta zona, tetapi Anda dapat mencapai hasil yang serupa dengan menggunakan tipe dan/atau partisi indeks yang ditentukan pengguna lainnya.-
Tabel dasar terkluster (CBT): di Netezza, CBT biasanya digunakan untuk tabel fakta, yang dapat memiliki miliaran rekaman. Memindai tabel sebesar itu membutuhkan waktu pemrosesan yang lama karena pemindaian tabel penuh mungkin diperlukan untuk mendapatkan catatan yang relevan. Mengatur catatan pada CBT terbatas memungkinkan Netezza untuk mengelompokkan catatan dalam cakupan yang sama atau berdekatan. Proses ini juga membuat peta zona yang meningkatkan performa dengan mengurangi jumlah data yang perlu dipindai.
Di Azure Synapse, Anda dapat mencapai efek yang sama dengan pemartisian dan/atau menggunakan indeks lainnya.
View materialisasi: Netezza mendukung view materialisasi dan merekomendasikan penggunaan satu atau lebih view materialisasi untuk tabel besar dengan banyak kolom jika hanya beberapa kolom yang digunakan secara teratur dalam kueri. Tampilan materialisasi diperbarui secara otomatis oleh sistem ketika data dalam tabel dasar diubah.
Azure Synapse mendukung tampilan terwujud, dengan fungsi yang sama seperti Netezza.
Pemetaan tipe data Netezza
Sebagian besar jenis data Netezza memiliki padanan langsung di Azure Synapse. Tabel berikut menunjukkan pendekatan yang direkomendasikan untuk memetakan jenis data Netezza ke Azure Synapse.
| Jenis Data Netezza | Jenis Data Azure Synapse |
|---|---|
| BIGINT | BIGINT |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT (dalam konteks teknis, sering digunakan tanpa terjemahan) | TINYINT |
| CHARACTER VARYING(n) (varian karakter dengan panjang maksimal) | VARCHAR(n) |
| KARAKTER(n) | CHAR(n) |
| TANGGAL | TANGGAL(tanggal) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| PRESISI GANDA | Mengapung |
| FLOAT(n) | FLOAT(n) |
| Integer | INT |
| selang | Tipe data INTERVAL saat ini tidak secara langsung didukung di Azure Synapse, tetapi dapat dihitung menggunakan fungsi temporal seperti DATEDIFF. |
| UANG | UANG |
| KARAKTER NASIONAL YANG BERVARIASI(n) | NVARCHAR(n) |
| KARAKTER NASIONAL | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| Nyata | Nyata |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Tipe data spasial seperti ST_GEOMETRY saat ini tidak didukung di Azure Synapse, tetapi data dapat disimpan sebagai VARCHAR atau VARBINARY. |
| WAKTU | WAKTU |
| WAKTU DENGAN ZONA WAKTU | DATETIMEOFFSET (penanda waktu dengan zona waktu) |
| TANDA WAKTU | Tanggal dan Waktu |
Tips
Menilai jumlah dan jenis jenis data yang tidak didukung selama fase persiapan migrasi.
Vendor pihak ketiga menawarkan alat dan layanan untuk mengotomatiskan migrasi, termasuk pemetaan jenis data. Jika alat ETL pihak ketiga sudah digunakan di lingkungan Netezza, gunakan alat tersebut untuk mengimplementasikan transformasi data yang diperlukan.
Perbedaan sintaks SQL DML
Perbedaan sintaks SQL DML ada antara Netezza SQL dan Azure Synapse T-SQL. Perbedaan tersebut dibahas secara rinci dalam Meminimalkan masalah SQL untuk migrasi Netezza.
STRPOS: di Netezza, fungsiSTRPOSmenampilkan posisi substring dalam string. Fungsi yang setara di Azure Synapse adalahCHARINDEXdengan urutan argumen dibalik. Misalnya,SELECT STRPOS('abcdef','def')...di Netezza sama denganSELECT CHARINDEX('def','abcdef')...di Azure Synapse.AGE: Netezza mendukung operatorAGEuntuk memberikan interval antara dua nilai sementara, seperti stempel waktu atau tanggal, contoh:SELECT AGE('23-03-1956','01-01-2019') FROM...Di Azure Synapse, gunakanDATEDIFFuntuk mendapatkan interval, misalnya:SELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM.... Perhatikan urutan representasi tanggal.NOW(): Netezza menggunakanNOW()untuk mewakiliCURRENT_TIMESTAMPdi Azure Synapse.
Fungsi, prosedur tersimpan, dan urutan
Saat memigrasi gudang data dari lingkungan yang matang seperti Netezza, Anda mungkin perlu memigrasikan elemen selain tabel dan tampilan sederhana. Periksa apakah alat dalam lingkungan Azure dapat menggantikan fungsionalitas fungsi, prosedur tersimpan, dan urutan karena biasanya lebih efisien untuk menggunakan alat Azure bawaan daripada mengodekan ulang elemen tersebut untuk Azure Synapse.
Sebagai bagian dari tahap persiapan Anda, buat inventaris objek yang perlu dimigrasikan, tentukan metode untuk menanganinya, dan alokasikan sumber daya yang sesuai dalam rencana migrasi.
Mitra integrasi data menawarkan alat dan layanan yang dapat mengotomatiskan migrasi fungsi, prosedur tersimpan, dan urutan.
Bagian berikut membahas lebih lanjut migrasi fungsi, prosedur tersimpan, dan urutan.
Fungsi
Seperti kebanyakan produk database, Netezza mendukung sistem dan fungsi yang ditentukan pengguna dalam implementasi SQL. Saat Anda memigrasikan platform database lama ke Azure Synapse, fungsi sistem umum biasanya dapat dimigrasikan tanpa perubahan. Beberapa fungsi sistem mungkin memiliki sintaks yang sedikit berbeda, tetapi setiap perubahan yang diperlukan dapat diotomatiskan.
Untuk fungsi sistem Netezza atau fungsi yang ditentukan pengguna arbitrer yang tidak memiliki fungsi yang setara dalam Azure Synapse, kodekan ulang fungsi tersebut menggunakan bahasa lingkungan target. Fungsi yang ditentukan pengguna Netezza dikodekan dalam bahasa nzlua atau C++. Azure Synapse menggunakan bahasa T-SQL untuk menerapkan fungsi yang ditentukan pengguna.
Prosedur tersimpan
Sebagian besar produk database modern memungkinkan prosedur penyimpanan di dalam database. Netezza menyediakan bahasa NZPLSQL, yang didasarkan pada Postgres PL/pgSQL, untuk tujuan ini. Prosedur tersimpan biasanya berisi pernyataan SQL dan logika prosedural, serta mengembalikan data atau status.
Azure Synapse mendukung prosedur tersimpan menggunakan T-SQL, jadi Anda perlu mengodekan ulang prosedur tersimpan yang dimigrasikan dalam bahasa tersebut.
Urutan-urutan
Di Netezza, urutan adalah objek database bernama yang dibuat dengan CREATE SEQUENCE. Urutan menyediakan nilai numerik unik melalui metode NEXT VALUE FOR. Anda dapat menggunakan angka unik yang dihasilkan sebagai nilai kunci pengganti untuk kunci primer.
Azure Synapse tidak menerapkan CREATE SEQUENCE, tetapi Anda dapat menerapkan urutan menggunakan kolom IDENTITY atau kode SQL yang menghasilkan nomor urutan berikutnya dalam seri.
Ekstrak metadata dan data dari lingkungan Netezza
Generasi Bahasa Definisi Data (DDL)
Standar ANSI SQL menentukan sintaks dasar untuk perintah Bahasa Definisi Data (DDL). Beberapa perintah DDL, seperti CREATE TABLE dan CREATE VIEW, umum untuk Netezza dan Azure Synapse tetapi telah diperluas untuk menyediakan fitur khusus implementasi.
Anda dapat mengedit skrip CREATE TABLE dan CREATE VIEW Netezza yang ada untuk mencapai definisi yang setara di Azure Synapse. Untuk melakukannya, Anda mungkin perlu menggunakan jenis data yang dimodifikasi dan menghapus atau memodifikasi klausul khusus Netezza seperti ORGANIZE ON.
Dalam lingkungan Netezza, tabel katalog sistem menentukan tabel saat ini dan definisi tampilan. Tidak seperti dokumentasi yang dikelola pengguna, informasi katalog sistem selalu lengkap dan sinkron dengan definisi tabel saat ini. Dengan utilitas seperti nz_ddl_table, Anda dapat mengakses informasi katalog sistem untuk menghasilkan pernyataan DDL CREATE TABLE yang membuat tabel yang setara di Azure Synapse.
Anda juga dapat menggunakan migrasi pihak ketiga dan alat ETL yang memproses informasi katalog sistem untuk mencapai hasil yang sama.
Ekstraksi data dari Netezza
Anda dapat mengekstrak data tabel mentah dari tabel Netezza ke file datar yang dibatasi, seperti file CSV, menggunakan utilitas Netezza standar seperti nzsql dan nzunload, atau melalui tabel eksternal. Kemudian, Anda dapat mengompresi file berbatas datar menggunakan gzip, dan mengunggah file terkompresi ke Azure Blob Storage menggunakan alat transportasi data AzCopy atau Azure seperti Azure Data Box.
Keluarkan data tabel seefektif mungkin. Gunakan pendekatan tabel eksternal karena ini adalah metode ekstrak tercepat. Lakukan beberapa ekstrak secara paralel untuk memaksimalkan throughput ekstraksi data. Pernyataan SQL berikut melakukan ekstraksi tabel eksternal:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
Jika bandwidth jaringan yang cukup tersedia, Anda dapat mengekstrak data dari sistem Netezza lokal langsung ke tabel Azure Synapse atau Azure Blob Data Storage. Untuk melakukannya, gunakan proses Data Factory atau migrasi data pihak ketiga atau produk ETL.
Tips
Gunakan tabel eksternal Netezza untuk ekstraksi data paling efisien.
File data yang diekstrak harus berisi teks yang dibatasi dalam format CSV, Optimized Row Columnar (ORC), atau Parquet.
Untuk informasi selengkapnya tentang memigrasikan data dan ETL dari lingkungan Netezza, lihat Migrasi data, ETL, dan pemuatan untuk migrasi Netezza.
Rekomendasi kinerja untuk proses migrasi Netezza
Tujuan optimasi performa adalah performa gudang data yang sama atau yang lebih baik setelah migrasi ke Azure Synapse.
Kesamaan dalam konsep pendekatan pengaturan performa
Banyak konsep penyetelan performa untuk database Netezza berlaku untuk database Azure Synapse. Contohnya:
Menggunakan distribusi data untuk mengkolokasikan data yang akan digabungkan ke node pemrosesan yang sama.
Menggunakan jenis data terkecil untuk kolom tertentu akan menghemat ruang penyimpanan dan mempercepat pemrosesan kueri.
Pastikan bahwa kolom yang akan digabungkan memiliki jenis data yang sama untuk mengoptimalkan pemrosesan gabungan dan mengurangi kebutuhan akan transformasi data.
Untuk membantu pengoptimal menghasilkan rencana eksekusi terbaik, pastikan statistik selalu terkini.
Pantau performa menggunakan kemampuan database bawaan untuk memastikan bahwa sumber daya digunakan secara efisien.
Tips
Prioritaskan pengenalan dengan opsi penyetelan di Azure Synapse pada awal migrasi.
Perbedaan dalam pendekatan pengaturan kinerja
Bagian ini menyoroti perbedaan implementasi penyetelan performa tingkat rendah antara Netezza dan Azure Synapse.
Opsi distribusi data
Untuk performa, Azure Synapse dirancang dengan arsitektur multi-node dan menggunakan pemrosesan paralel. Untuk mengoptimalkan performa tabel, Anda dapat menentukan opsi distribusi data dalam pernyataan CREATE TABLE menggunakan DISTRIBUTION di Azure Synapse dan DISTRIBUTE ON di Netezza.
Tidak seperti Netezza, Azure Synapse mendukung gabungan lokal antara tabel kecil dan tabel besar melalui replikasi tabel kecil. Misalnya, pertimbangkan tabel dimensi kecil dan tabel fakta besar dalam model skema bintang. Azure Synapse dapat mereplikasi tabel dimensi yang lebih kecil di semua node untuk memastikan bahwa nilai kunci gabungan apa pun untuk tabel besar memiliki baris dimensi yang cocok dan tersedia secara lokal. Beban kerja replikasi tabel dimensi relatif rendah untuk tabel dimensi kecil. Untuk tabel dimensi besar, pendekatan distribusi hash lebih tepat. Untuk informasi selengkapnya tentang opsi distribusi data, lihat Panduan desain untuk menggunakan tabel yang direplikasi dan Panduan untuk merancang tabel terdistribusi.
Pengindeksan data
Azure Synapse mendukung beberapa opsi pengindeksan yang dapat ditentukan pengguna yang memiliki operasi dan penggunaan yang berbeda dibandingkan dengan peta zona yang dikelola sistem di Netezza. Untuk informasi selengkapnya tentang opsi pengindeksan yang berbeda di Azure Synapse, lihat Indeks pada tabel kumpulan SQL khusus.
Pemetaan zona terkelola sistem yang ada dalam lingkungan Netezza sumber memberikan indikasi yang berguna tentang penggunaan data dan kolom kandidat untuk pengindeksan di lingkungan Azure Synapse.
Pemartisian data
Di gudang data perusahaan, tabel fakta dapat berisi miliaran baris. Partisi mengoptimalkan pemeliharaan dan performa kueri tabel ini dengan membaginya menjadi beberapa bagian terpisah untuk mengurangi jumlah data yang diproses. Di Azure Synapse, pernyataan CREATE TABLE mendefinisikan spesifikasi pemartisian untuk tabel.
Anda hanya dapat menggunakan satu bidang per tabel untuk pembuatan partisi. Bidang itu sering kali merupakan bidang tanggal karena banyak kueri yang difilter menurut tanggal atau rentang tanggal. Dimungkinkan untuk mengubah pembuatan partisi tabel setelah pemuatan awal menggunakan pernyataan CREATE TABLE AS (CTAS) untuk membuat ulang tabel dengan distribusi baru. Untuk diskusi terperinci tentang pemartisian di Azure Synapse, lihat Tabel pemartisian di kumpulan SQL khusus.
Statistik tabel data
Anda harus memastikan bahwa statistik pada tabel data selalu mutakhir dengan menyertakan langkah statistik ke dalam pekerjaan ETL/ELT.
PolyBase atau COPY INTO untuk pemuatan data
PolyBase mendukung pemuatan data dalam jumlah besar yang efisien ke gudang data menggunakan aliran pemuatan paralel. Untuk informasi selengkapnya, lihat Strategi pemuatan data PolyBase.
COPY INTO juga mendukung pengambilan data berkecepatan tinggi.
Pengambilan data dari semua file dalam folder dan subfolder.
Pengambilan data dari beberapa lokasi di akun penyimpanan yang sama. Anda dapat menentukan beberapa lokasi menggunakan jalur yang dipisahkan koma.
Azure Data Lake Storage (ADLS) dan Azure Blob Storage.
Format file CSV, PARQUET, dan ORC.
Manajemen beban kerja
Menjalankan beban kerja campuran dapat menimbulkan tantangan sumber daya pada sistem yang sibuk. Skema pengelolaan beban kerja yang sukses secara efektif mengelola sumber daya, memastikan penggunaan sumber daya yang sangat efisien, dan memaksimalkan laba atas investasi (ROI). Klasifikasi beban kerja, kepentingan beban kerja, dan isolasi beban kerja memberikan kontrol lebih atas cara beban kerja menggunakan sumber daya sistem.
Panduan manajemen beban kerja menjelaskan teknik untuk menganalisis beban kerja, mengelola, dan memantau kepentingan beban kerja, dan langkah-langkah untuk mengonversi kelas sumber daya menjadi grup beban kerja. Gunakan kueri portal Azure dan T-SQL pada DMV untuk memantau beban kerja guna memastikan bahwa sumber daya yang berlaku digunakan secara efisien.
Langkah berikutnya
Untuk mempelajari ETL dan pemuatan migrasi Netezza, lihat artikel berikutnya dalam seri ini: Migrasi data, ETL, dan pemuatan migrasi Netezza.