Tutorial: Membuat aplikasi Apache Spark dengan IntelliJ menggunakan ruang kerja Synapse
Tutorial ini menunjukkan kepada Anda cara menggunakan Toolkit Azure untuk plug-in IntelliJ guna mengembangkan aplikasi Apache Spark, yang ditulis di Scala, dan kemudian mengirimkannya ke kumpulan Apache Spark tanpa server langsung dari IDE IntelliJ. Anda dapat menggunakan plug-in dalam beberapa cara:
- Mengembangkan dan mengirim aplikasi Scala Spark di kumpulan Spark.
- Mengakses sumber daya kumpulan Spark Anda.
- Mengembangkan dan menjalankan aplikasi Scala Spark secara lokal.
Dalam tutorial ini, Anda akan mempelajari cara:
- Menggunakan Toolkit Azure untuk plug-in IntelliJ
- Kembangkan aplikasi Apache Spark
- Mengirim aplikasi ke kumpulan Spark
Prasyarat
Plugin toolkit Azure 3.27.0-2019.2 – Pasang dari repositori Plugin IntelliJ
Plugin Scala - Pasang dari repositori Plugin IntelliJ.
Prasyarat berikut ini hanya untuk pengguna Windows:
Saat Anda menjalankan aplikasi Scala Spark lokal di komputer Windows, Anda mungkin mendapatkan pengecualian, seperti yang dijelaskan dalam SPARK-2356. Pengecualian terjadi karena WinUtils.exe hilang pada Windows. Untuk mengatasi kesalahan ini, unduh Winutils yang dapat dieksekusi ke lokasi seperti C:\WinUtils\bin. Kemudian, tambahkan variabel lingkungan HADOOP_HOME, dan atur nilai variabel ke C\WinUtils.
Membuat aplikasi Spark Scala untuk kumpulan Spark
Buka IntelliJ IDEA, dan pilih Buat Proyek Baru untuk membuka jendela Proyek Baru.
Pilih Apache Spark/Azure HDInsight dari panel sebelah kiri.
Pilih Proyek Spark dengan Sampel(Scala) dari jendela utama.
Dari daftar menurun Alat build, pilih salah satu jenis berikut ini:
- Maven untuk dukungan wizard pembuatan proyek Scala.
- SBT untuk mengelola dependensi dan pembangunan proyek Scala.

Pilih Selanjutnya.
Di jendela Proyek Baru, berikan informasi berikut ini:
Properti Deskripsi Nama proyek Masukkan nama. Tutorial ini menggunakan myApp.Lokasi proyek Masukkan lokasi yang diinginkan untuk menyimpan proyek Anda. SDK Proyek Mungkin kosong pada penggunaan IDEA pertama Anda. Pilih Baru... dan navigasi ke JDK Anda. Versi Spark Wizard pembuatan mengintegrasikan versi yang tepat untuk SDK Spark dan SDK Scala. Di sini Anda dapat memilih versi Spark yang Anda butuhkan. 
Pilih Selesai. Hal ini memerlukan waktu beberapa menit sebelum proyek tersedia.
Proyek Spark secara otomatis membuat artefak untuk Anda. Untuk melihat artefak, lakukan operasi berikut:
a. Dari bilah menu, navigasikan ke File>Struktur Proyek....
b. Dari jendela Struktur Proyek, pilih Artefak.
c. Pilih Batal setelah melihat artefak.

Temukan LogQuery dari myApp>src>sampel>scala>utama>LogQuery. Tutorial ini menggunakan LogQuery untuk menjalankannya.

Menyambungkan ke kumpulan Spark Anda
Masuk ke langganan Azure untuk tersambung ke kumpulan Spark Anda.
Masuk ke langganan Azure Anda
Dari bilah menu, navigasi ke Tampilkan>Alat WindowsAzure >Explorer.

Dari Explorer Azure, klik kanan simpul Azure, lalu pilih Masuk.

Dalam kotak dialog Masuk Azure, pilih Masuk Perangkat, lalu pilih Masuk.

Dalam kotak dialog Masuk Perangkat Azure, pilih Copy&Open.

Di antarmuka browser, tempel kode, lalu pilih Berikutnya.

Masukkan kredensial Azure Anda, lalu tutup browser.

Setelah Anda masuk, kotak dialog Langganan Anda mencantumkan semua langganan Azure yang terkait dengan info masuk. Pilih langganan Anda lalu klik Pilih.
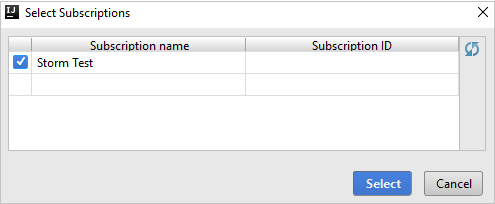
Dari Explorer Azure, luaskan Apache Spark di Synapse untuk melihat Ruang Kerja yang ada di langganan Anda.

Untuk melihat kumpulan Spark, Anda dapat meluaskan ruang kerja lebih lanjut.

Jalankan Jarak jauh aplikasi Scala Spark di kumpulan Spark
Setelah membuat aplikasi Scala, Anda dapat menjalankan aplikasi dari jarak jauh.
Buka jendela Konfigurasi Eksekusi/Debug dengan memilih ikon.

Di jendela dialog Konfigurasi Eksekusi/Debug, pilih +, lalu pilih Apache Spark di Synapse.

Di jendela Konfigurasi Eksekusi/Debug, berikan nilai berikut, lalu pilih OK:
Properti Nilai Kumpulan Spark Pilih kumpulan Spark tempat Anda ingin menjalankan aplikasi. Pilih Artefak untuk dikirim Biarkan pengaturan default. Nama kelas utama Nilai default adalah kelas utama dari file yang dipilih. Anda dapat mengubah kelas dengan memilih elipsis(...) dan memilih kelas lain. Konfigurasi pekerjaan Anda dapat mengubah kunci dan nilai default. Untuk mengetahui informasi selengkapnya, lihat REST API Apache Livy. Argumen baris perintah Anda dapat memasukkan argumen yang dipisahkan oleh spasi untuk kelas utama jika diperlukan. Jars yang Direferensikan dan File yang Direferensikan Anda dapat memasukkan jalur untuk Jar dan file yang direferensikan jika ada. Anda juga dapat menelusuri file di sistem file virtual Azure, yang saat ini hanya mendukung kluster ADLS Gen2. Untuk informasi selengkapnya: Konfigurasi Apache Spark dan Cara mengunggah sumber daya ke kluster. Penyimpanan Pengunggahan Pekerjaan Luaskan untuk menampilkan opsi tambahan. Jenis Penyimpanan Pilih Gunakan Blob Azure untuk mengunggah atau Gunakan akun penyimpanan default kluster untuk mengunggah dari daftar menurun. Akun Penyimpanan Masukkan akun penyimpanan Anda. Kunci Penyimpanan Masukkan kunci penyimpanan Anda. Kontainer Penyimpanan Pilih kontainer penyimpanan Anda dari daftar menurun setelah Akun Penyimpanan dan Kunci Penyimpanan dimasukkan. 
Pilih ikon SparkJobRun untuk mengirim proyek Anda ke kumpulan Spark yang dipilih. Tab Pekerjaan Spark Jarak Jauh di Kluster menampilkan kemajuan eksekusi pekerjaan di bagian bawah. Anda dapat menghentikan aplikasi dengan memilih tombol merah.


Aplikasi Eksekusi Lokal/Debug Apache Spark
Anda dapat mengikuti instruksi di bawah ini guna menyiapkan eksekusi lokal dan debug lokal untuk pekerjaan Apache Spark Anda.
Skenario 1: Lakukan eksekusi lokal
Buka dialog Konfigurasi Eksekusi/Debug, pilih tanda plus (+). Kemudian pilih opsi Apache Spark pada Synapse. Masukkan informasi untuk Nama, Nama kelas utama untuk disimpan.

- Variabel lingkungan dan Lokasi WinUtils.exe hanya untuk pengguna windows.
- Variabel lingkungan: Variabel lingkungan sistem dapat dideteksi secara otomatis jika Anda telah mengatur variabel lingkungan sebelumnya dan tidak perlu menambahkan secara manual.
- Lokasi WinUtils.exe: Anda dapat menetapkan lokasi WinUtils dengan memilih ikon folder di sebelah kanan.
Kemudian pilih tombol putar lokal.

Saat eksekusi lokal selesai, jika skrip mencakup output, Anda dapat memerikas file output dari data>default.

Skenario 2: Lakukan penelusuran kesalahan lokal
Buka skrip LogQuery, atur titik henti.
Pilih ikon Debug lokal untuk melakukan penelusuran kesalahan lokal.

Mengakses dan mengelola Ruang Kerja Synapse
Anda dapat melakukan berbagai operasi di Explorer Azure dalam Toolkit Azure untuk IntelliJ. Dari bilah menu, navigasi ke Tampilkan>Alat WindowsAzure >Explorer.
Luncurkan ruang kerja
Dari Explorer Azure, navigasikan ke Apache Spark di Synapse, lalu perluas Apache Spark.
Klik kanan ruang kerja, lalu pilih Luncurkan ruang kerja, situs web akan dibuka.


Konsol Spark
Anda dapat menjalankan Spark Local Console(Scala) atau menjalankan Spark Livy Interactive Session Console(Scala).
Konsol lokal Spark (Scala)
Pastikan Anda telah memenuhi prasyarat WINUTILS.EXE.
Dari bilah menu, navigasikan ke Jalankan>Edit Konfigurasi....
Dari jendela Konfigurasi Eksekusi/Debug, di panel sebelah kiri, navigasikan ke Apache Spark di Synapse>[Spark di Synapse] myApp.
Dari jendela utama, pilih tab Jalankan Secara Lokal.
Berikan nilai berikut, lalu pilih OK:
Properti Nilai Variabel lingkungan Pastikan nilai untuk HADOOP_HOME sudah benar. Lokasi WINUTILS.exe Pastikan jalurnya benar. 
Dari Proyek, navigasikan ke myApp>src>myApp>scala>utama.
Dari bilah menu, navigasikan ke Alat>Konsol Spark>Jalankan Konsol Lokal Spark(Scala).
Kemudian dua dialog dapat ditampilkan untuk menanyakan apakah Anda ingin memperbaiki dependensi secara otomatis. Jika demikian, pilih Perbaiki Otomatis.


Konsol harus terlihat mirip dengan gambar di bawah ini. Di jenis jendela konsol
sc.appName, lalu tekan ctrl+Enter. Hasilnya akan ditampilkan. Anda dapat menghentikan konsol lokal dengan memilih tombol merah.
Konsol sesi interaktif Livy Spark (Scala)
Konsol hanya didukung pada IntelliJ 2018.2 dan 2018.3.
Dari bilah menu, navigasikan ke Jalankan>Edit Konfigurasi....
Dari jendela Konfigurasi Eksekusi/Debug, di panel sebelah kiri, navigasikan ke Apache Spark di synapse>[Spark di synapse] myApp.
Dari jendela utama, pilih tab Jalankan secara Jarak Jauh di Kluster.
Berikan nilai berikut, lalu pilih OK:
Properti Nilai Nama kelas utama Pilih nama kelas Utama. Kumpulan Spark Pilih kumpulan Spark tempat Anda ingin menjalankan aplikasi. 
Dari Proyek, navigasikan ke myApp>src>myApp>scala>utama.
Dari bilah menu, navigasikan ke Alat>Konsol Spark>Jalankan Konsol Sesi Interaktif Livy Spark(Scala).
Konsol harus terlihat mirip dengan gambar di bawah ini. Di jenis jendela konsol
sc.appName, lalu tekan ctrl+Enter. Hasilnya akan ditampilkan. Anda dapat menghentikan konsol lokal dengan memilih tombol merah.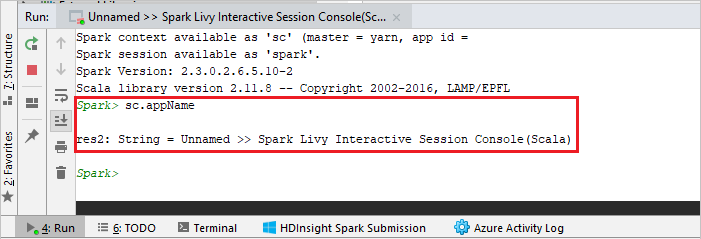
Kirim pilihan ke konsol Spark
Anda mungkin ingin melihat hasil skrip dengan mengirim beberapa kode ke konsol lokal atau Konsol Sesi Interaktif Livy(Scala). Untuk melakukannya hal tersebut, Anda dapat menyorot beberapa kode dalam file Scala, lalu klik kanan Kirim Pilihan Ke konsol Spark. Kode yang dipilih akan dikirim ke konsol dan dilakukan. Hasilnya akan ditampilkan setelah kode di konsol. Konsol akan memeriksa kesalahan yang ada.
