Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam tutorial ini, Anda akan mempelajari cara melakukan analisis data eksploratif (EDA) untuk memeriksa dan menyelidiki data sambil meringkas karakteristik utamanya melalui penggunaan teknik visualisasi data.
Anda akan menggunakan seaborn, pustaka visualisasi data Python yang menyediakan antarmuka tingkat tinggi untuk membangun visual pada dataframe dan array. Untuk informasi selengkapnya tentang seaborn, lihat Seaborn: Visualisasi Data Statistik.
Anda juga akan menggunakan Data Wrangler, alat berbasis notebook yang memberi Anda pengalaman imersif untuk melakukan analisis dan pembersihan data eksploratif.
Langkah utama dalam tutorial ini adalah:
- Baca data yang disimpan dari tabel delta di lakehouse.
- Konversikan Spark DataFrame ke Pandas DataFrame, yang didukung pustaka visualisasi python.
- Gunakan Data Wrangler untuk melakukan pembersihan dan transformasi data awal.
- Lakukan analisis data eksploratif menggunakan
seaborn.
Prasyarat
Dapatkan langganan Microsoft Fabric . Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Beralih ke Fabric dengan menggunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda.

Ini adalah bagian 2 dari 5 dalam seri tutorial. Untuk menyelesaikan tutorial ini, selesaikan terlebih dahulu:
Ikuti di buku catatan ini
2-explore-cleanse-data.ipynb adalah notebook yang menyertai tutorial ini.
Untuk membuka buku catatan yang menyertai tutorial ini, ikuti instruksi di Menyiapkan sistem Anda untuk tutorial ilmu data mengimpor buku catatan ke ruang kerja Anda.
Jika Anda lebih suka menyalin dan menempelkan kode dari halaman ini, Anda bisa membuat buku catatan baru.
Pastikan untuk menghubungkan lakehouse dengan notebook sebelum Anda mulai menjalankan kode.
Penting
Pasang lakehouse yang sama dengan yang Anda gunakan di Bagian 1.
Membaca data mentah dari lakehouse
Baca data mentah dari bagian Files dari lakehouse. Anda mengunggah data ini di buku catatan sebelumnya. Pastikan Anda telah melampirkan lakehouse yang sama dengan yang Anda gunakan di Bagian 1 ke notebook ini sebelum Anda menjalankan kode ini.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Membuat DataFrame pandas dari himpunan data
Konversikan Spark DataFrame ke Pandas DataFrame untuk pemrosesan dan visualisasi yang lebih mudah.
df = df.toPandas()
Menampilkan data mentah
Jelajahi data mentah dengan display, lakukan beberapa statistik dasar dan tampilkan tampilan bagan. Perhatikan bahwa Anda harus terlebih dahulu mengimpor pustaka yang diperlukan seperti Numpy, Pnadas, Seaborn, dan Matplotlib untuk analisis dan visualisasi data.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
Menggunakan Data Wrangler untuk melakukan pembersihan data awal
Untuk menjelajahi dan mengubah DataFrame pandas apa pun di Notebook Anda, luncurkan Data Wrangler langsung dari Notebook.
Nota
Data Wrangler tidak dapat dibuka saat kernel notebook sibuk. Proses eksekusi sel harus selesai sebelum meluncurkan Data Wrangler.
- Di bawah pita buku catatan tab Data, pilih Luncurkan Data Wrangler. Anda akan melihat daftar DataFrames panda yang diaktifkan yang tersedia untuk diedit.
- Pilih DataFrame yang ingin Anda buka di Data Wrangler. Karena buku catatan ini hanya berisi satu DataFrame,
df, pilihdf.
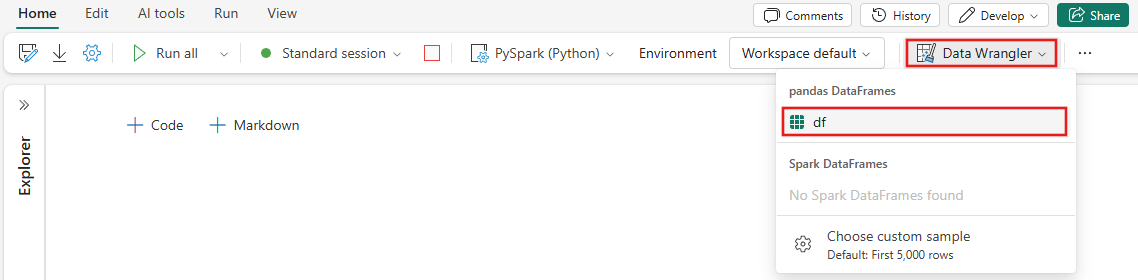
Data Wrangler meluncurkan dan menghasilkan gambaran umum deskriptif data Anda. Tabel di tengah memperlihatkan setiap kolom data. Panel Ringkasan di samping tabel memperlihatkan informasi tentang DataFrame. Saat Anda memilih kolom dalam tabel, ringkasan diperbarui dengan informasi tentang kolom yang dipilih. Dalam beberapa kasus, data yang ditampilkan dan dirangkum akan menjadi tampilan terpotong dari DataFrame Anda. Saat ini terjadi, Anda akan melihat gambar peringatan di panel ringkasan. Arahkan mouse ke atas peringatan ini untuk melihat teks yang menjelaskan situasinya.

Setiap operasi yang Anda lakukan dapat diterapkan dalam hitungan klik, memperbarui tampilan data secara real time dan menghasilkan kode yang dapat Anda simpan kembali ke buku catatan Anda sebagai fungsi yang dapat digunakan kembali.
Sisa dari bagian ini memandu Anda melalui langkah-langkah melakukan pembersihan data dengan Data Wrangler.
Jatuhkan baris duplikat
Di panel kiri adalah daftar operasi (seperti Temukan dan ganti, Format, Rumus , Numerik ) yang dapat Anda lakukan pada himpunan data.
Perluas Temukan dan ganti dan pilih Jatuhkan baris duplikat.
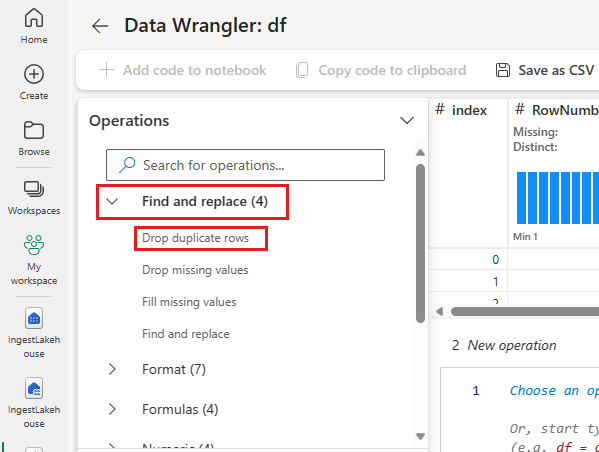
Panel muncul bagi Anda untuk memilih daftar kolom yang ingin Anda bandingkan untuk menentukan baris duplikat. Pilih RowNumber dan CustomerId.
Di panel tengah adalah pratinjau dari hasil operasi ini. Di bawah pratinjau adalah kode untuk melakukan operasi. Dalam hal ini, data tampaknya tidak berubah. Namun, karena Anda melihat tampilan yang terpotong, sebaiknya tetap menerapkan operasi tersebut.
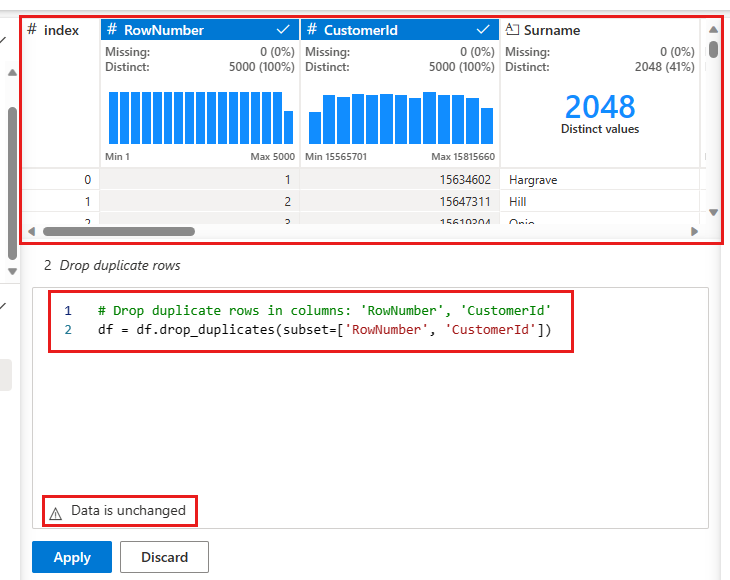
Pilih Terapkan (baik di samping atau di bagian bawah) untuk masuk ke langkah berikutnya.

Hapus baris dengan data yang hilang
Gunakan Data Wrangler untuk menghilangkan baris dengan data yang hilang di semua kolom.
Pilih Hilangkan nilai yang hilang dari Temukan dan ganti.
Pilih Pilih semua dari kolom Target .
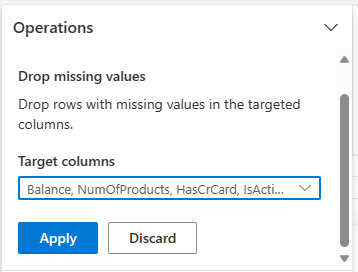
Pilih Terapkan untuk melanjutkan ke langkah berikutnya.

Hapus kolom
Gunakan Data Wrangler untuk menghilangkan kolom yang tidak Anda butuhkan.
Perluas Skema dan pilih Jatuhkan kolom.
Pilih RowNumber, CustomerId, Nama Belakang. Kolom-kolom ini muncul dalam warna merah pada pratinjau, untuk menunjukkan bahwa mereka telah diubah oleh kode (dalam hal ini, dihapus).
Pilih Terapkan untuk melanjutkan ke langkah berikutnya.

Menambahkan kode ke buku catatan
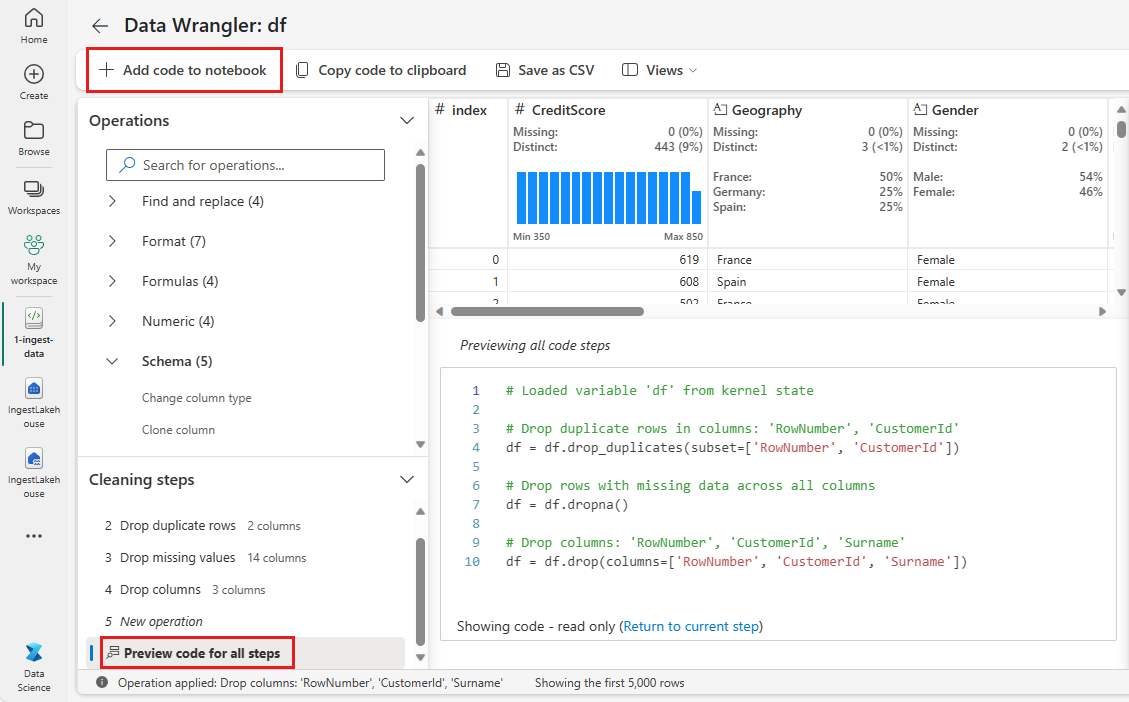
Setiap kali Anda memilih Terapkan, sebuah langkah baru dibuat di panel langkah-langkah pembersihan di kiri bawah. Di bagian bawah panel, pilih Kode pratinjau untuk semua langkah untuk melihat kombinasi semua langkah terpisah.
Pilih Tambahkan kode ke notebook di kiri atas untuk menutup Data Wrangler dan menambahkan kode secara otomatis. Menambahkan kode ke notebook membungkus kode dalam fungsi, lalu memanggil fungsi tersebut.
Tips
Kode yang dihasilkan oleh Data Wrangler tidak akan diterapkan sampai Anda menjalankan sel baru secara manual.
Jika Anda tidak menggunakan Data Wrangler, Anda dapat menggunakan sel kode berikutnya ini.
Kode ini mirip dengan kode yang dihasilkan oleh Data Wrangler, tetapi menambahkan argumen inplace=True ke setiap langkah yang dihasilkan. Dengan mengatur parameter inplace=True, pandas akan menimpa DataFrame asli alih-alih menghasilkan DataFrame baru sebagai output.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Menjelajahi data
Tampilkan beberapa ringkasan dan visualisasi data yang dibersihkan.
Menentukan atribut kategoris, numerik, dan target
Gunakan kode ini untuk menentukan atribut kategoris, numerik, dan target.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
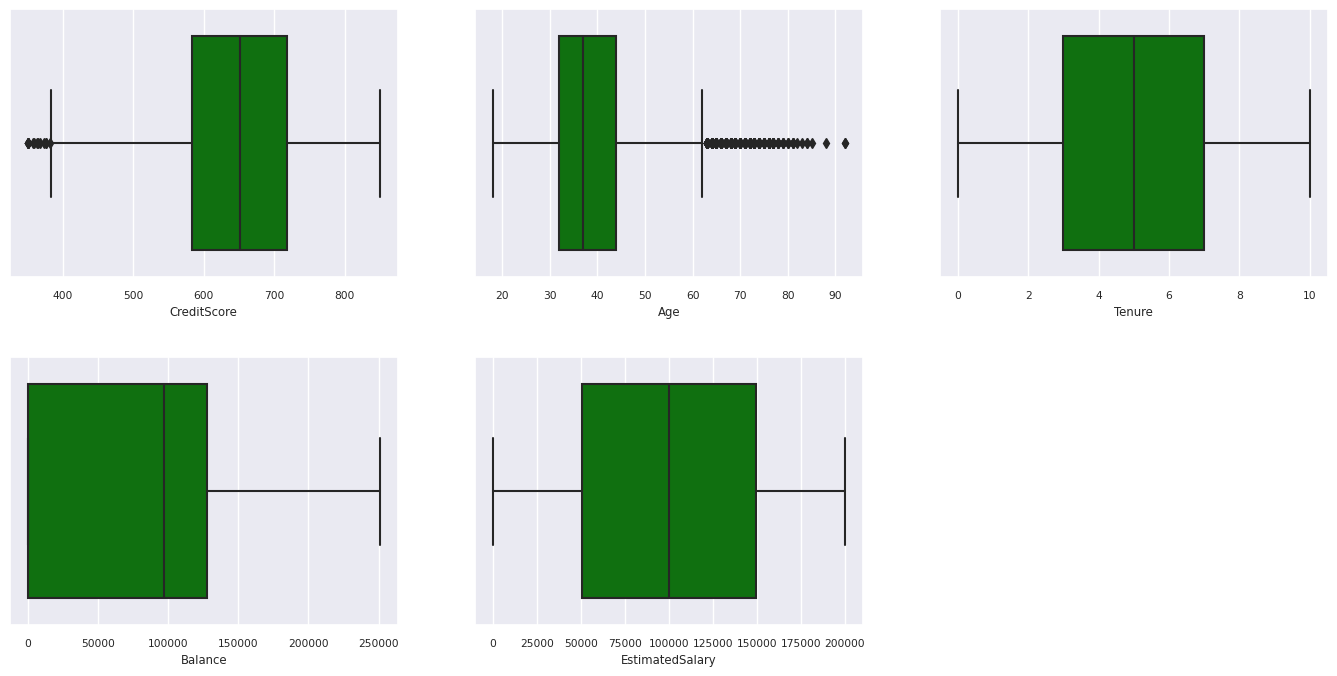
Ringkasan lima angka
Tampilkan ringkasan lima angka (skor minimum, kuartil pertama, median, kuartil ketiga, skor maksimum) untuk atribut numerik, menggunakan plot kotak.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
Distribusi pelanggan yang keluar dan yang tetap
Tampilkan distribusi pelanggan yang keluar versus pelanggan yang tetap berdasarkan atribut kategori.
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

Distribusi Atribut Angka
Tampilkan distribusi frekuensi atribut numerik menggunakan histogram.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Melakukan rekayasa fitur
Lakukan rekayasa fitur untuk menghasilkan atribut baru berdasarkan atribut saat ini:
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Gunakan Data Wrangler untuk melakukan one-hot encoding
Data Wrangler juga dapat digunakan untuk melakukan one-hot encoding. Untuk melakukannya, buka kembali Data Wrangler. Kali ini, pilih data df_clean.
- Perluas Rumus dan pilih penyandian satu-hot.
- Sebuah panel muncul untuk Anda memilih daftar kolom yang ingin Anda lakukan one-hot encoding. Pilih Geografi dan Gender.
Anda dapat menyalin kode yang dihasilkan, menutup Data Wrangler untuk kembali ke buku catatan, lalu menempelkan ke sel baru. Atau, pilih Tambahkan kode ke notebook di kiri atas untuk menutup Data Wrangler dan menambahkan kode secara otomatis.
Jika Anda tidak menggunakan Data Wrangler, Anda dapat menggunakan sel kode berikutnya ini:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Ringkasan pengamatan dari analisis data eksploratif
- Sebagian besar pelanggan berasal dari Prancis dibandingkan dengan Spanyol dan Jerman, sementara Spanyol memiliki tingkat churn terendah dibandingkan dengan Prancis dan Jerman.
- Sebagian besar pelanggan memiliki kartu kredit.
- Ada pelanggan yang usia dan skor kreditnya masing-masing di atas 60 dan di bawah 400, tetapi mereka tidak dapat dianggap sebagai outlier.
- Sangat sedikit nasabah yang memiliki lebih dari dua produk bank.
- Pelanggan yang tidak aktif memiliki tingkat churn yang lebih tinggi.
- Gender dan masa jabatan tampaknya tidak berdampak pada keputusan nasabah untuk menutup rekening bank.
Membuat tabel delta untuk data yang dibersihkan
Anda akan menggunakan data ini di buku catatan berikutnya dari seri ini.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Langkah berikutnya
Latih dan daftarkan model pembelajaran mesin dengan data ini: