Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam tutorial ini, Anda akan belajar melatih beberapa model pembelajaran mesin untuk memilih yang terbaik untuk memprediksi pelanggan bank mana yang kemungkinan akan pergi.
Dalam tutorial ini, Anda akan:
- Melatih model Hutan Acak dan LightGBM.
- Gunakan integrasi asli Microsoft Fabric dengan kerangka kerja MLflow untuk mencatat model pembelajaran mesin terlatih, hyperaparameter yang digunakan, dan metrik evaluasi.
- Daftarkan model pembelajaran mesin terlatih.
- Menilai performa model pembelajaran mesin terlatih pada himpunan data validasi.
MLflow adalah platform sumber terbuka untuk mengelola siklus hidup pembelajaran mesin dengan fitur seperti Pelacakan, Model, dan Registri Model. MLflow terintegrasi secara asli dengan pengalaman Fabric Ilmu Data.
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Beralih ke Fabric dengan menggunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda.

Ini adalah bagian 3 dari 5 dalam seri tutorial. Untuk menyelesaikan tutorial ini, pertama-tama selesai:
- Bagian 1: Menyerap data ke microsoft Fabric lakehouse menggunakan Apache Spark.
- Bagian 2: Menjelajahi dan memvisualisasikan data menggunakan notebook Microsoft Fabric untuk mempelajari selengkapnya tentang data.
Ikuti di buku catatan
3-train-evaluate.ipynb adalah notebook yang menyertai tutorial ini.
Untuk membuka buku catatan yang menyertai tutorial ini, ikuti instruksi di Menyiapkan sistem Anda untuk tutorial ilmu data mengimpor buku catatan ke ruang kerja Anda.
Jika Anda lebih suka menyalin dan menempelkan kode dari halaman ini, Anda bisa membuat buku catatan baru.
Pastikan untuk melampirkan lakehouse ke buku catatan sebelum Anda mulai menjalankan kode.
Penting
Pasang lakehouse yang sama dengan yang Anda gunakan di bagian 1 dan bagian 2.
Menginstal pustaka kustom
Untuk buku catatan ini, Anda akan menginstal pembelajaran yang tidak seimbang (diimpor sebagai imblearn) menggunakan %pip install. Imbalanced-learn adalah pustaka untuk Synthetic Minority Oversampling Technique (SMOTE) yang digunakan saat berhadapan dengan himpunan data yang tidak seimbang. Kernel PySpark akan dimulai ulang setelah %pip install, jadi Anda harus menginstal pustaka sebelum menjalankan sel lain.
Anda akan mengakses SMOTE menggunakan imblearn pustaka. Instal sekarang menggunakan kemampuan penginstalan in-line (misalnya, %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Penting
Jalankan penginstalan ini setiap kali Anda menghidupkan ulang buku catatan.
Saat Anda menginstal pustaka di buku catatan, pustaka hanya tersedia selama durasi sesi buku catatan dan bukan di ruang kerja. Jika Anda menghidupkan ulang buku catatan, Anda harus menginstal pustaka lagi.
Jika Anda memiliki pustaka yang sering Anda gunakan, dan Anda ingin membuatnya tersedia untuk semua buku catatan di ruang kerja Anda, Anda dapat menggunakan lingkungan Fabric untuk tujuan tersebut. Anda dapat membuat lingkungan, menginstal pustaka di dalamnya, lalu admin ruang kerja Anda dapat melampirkan lingkungan ke ruang kerja sebagai lingkungan defaultnya. Untuk informasi selengkapnya tentang mengatur lingkungan sebagai default ruang kerja, lihat Admin mengatur pustaka default untuk ruang kerja.
Untuk informasi tentang memigrasikan pustaka ruang kerja yang ada dan properti Spark ke lingkungan, lihat Memigrasikan pustaka ruang kerja dan properti Spark ke lingkungan default.
Muat data
Sebelum melatih model pembelajaran mesin apa pun, Anda perlu memuat tabel delta dari lakehouse untuk membaca data yang dibersihkan yang Anda buat di buku catatan sebelumnya.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Hasilkan eksperimen untuk melacak dan mencatat model menggunakan MLflow
Bagian ini menunjukkan cara menghasilkan eksperimen, menentukan model pembelajaran mesin dan parameter pelatihan serta metrik penilaian, melatih model pembelajaran mesin, mencatatnya, dan menyimpan model terlatih untuk digunakan nanti.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
Memperluas kemampuan autologging MLflow, autologging bekerja dengan secara otomatis menangkap nilai parameter input dan metrik output model pembelajaran mesin saat sedang dilatih. Informasi ini kemudian dicatat ke ruang kerja Anda, di mana informasi ini dapat diakses dan divisualisasikan menggunakan API MLflow atau eksperimen yang sesuai di ruang kerja Anda.
Semua eksperimen dengan nama masing-masing dicatat dan Anda akan dapat melacak parameter dan metrik performanya. Untuk mempelajari selengkapnya tentang autologging, lihat Autologging di Microsoft Fabric.
Mengatur spesifikasi eksperimen dan autologging
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Impor scikit-learn dan LightGBM
Dengan data Anda di tempat, Anda sekarang dapat menentukan model pembelajaran mesin. Anda akan menerapkan model Hutan Acak dan LightGBM di notebook ini. Gunakan scikit-learn dan lightgbm untuk mengimplementasikan model dalam beberapa baris kode.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Menyiapkan pelatihan, validasi, dan menguji himpunan data
train_test_split Gunakan fungsi dari scikit-learn untuk membagi data menjadi pelatihan, validasi, dan set pengujian.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Menyimpan data pengujian ke tabel delta
Simpan data pengujian ke tabel delta untuk digunakan di buku catatan berikutnya.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Terapkan SMOTE ke data pelatihan untuk mensintesis sampel baru untuk kelas minoritas
Eksplorasi data di bagian 2 menunjukkan bahwa dari 10.000 poin data yang sesuai dengan 10.000 pelanggan, hanya 2.037 pelanggan (sekitar 20%) yang meninggalkan bank. Ini menunjukkan bahwa himpunan data sangat tidak seimbang. Masalah dengan klasifikasi yang tidak seimbang adalah bahwa ada terlalu sedikit contoh kelas minoritas bagi model untuk mempelajari batas keputusan secara efektif. SMOTE adalah pendekatan yang paling banyak digunakan untuk mensintesis sampel baru untuk kelas minoritas. Pelajari selengkapnya tentang SMOTE di sini dan di sini.
Tip
Perhatikan bahwa SMOTE hanya boleh diterapkan ke himpunan data pelatihan. Anda harus meninggalkan himpunan data pengujian dalam distribusi aslinya yang tidak seimbang untuk mendapatkan perkiraan yang valid tentang performa model pembelajaran mesin pada data asli, yang mewakili situasi dalam produksi.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Tip
Anda dapat dengan aman mengabaikan pesan peringatan MLflow yang muncul saat Anda menjalankan sel ini.
Jika Anda melihat pesan ModuleNotFoundError , Anda tidak dapat menjalankan sel pertama dalam buku catatan ini, yang menginstal imblearn pustaka. Anda perlu menginstal pustaka ini setiap kali Anda menghidupkan ulang buku catatan. Kembali dan jalankan kembali semua sel yang dimulai dengan sel pertama dalam buku catatan ini.
Pelatihan model
- Latih model menggunakan Hutan Acak dengan kedalaman maksimum 4 dan 4 fitur
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Latih model menggunakan Hutan Acak dengan kedalaman maksimum 8 dan 6 fitur
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Melatih model menggunakan LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Artefak eksperimen untuk melacak performa model
Eksekusi eksperimen secara otomatis disimpan dalam artefak eksperimen yang dapat ditemukan dari ruang kerja. Mereka diberi nama berdasarkan nama yang digunakan untuk mengatur eksperimen. Semua model pembelajaran mesin terlatih, eksekusinya, metrik performa, dan parameter model dicatat.
Untuk melihat eksperimen Anda:
Di panel kiri, pilih ruang kerja Anda.
Di kanan atas, filter untuk hanya menampilkan eksperimen, untuk mempermudah menemukan eksperimen yang Anda cari.
Temukan dan pilih nama eksperimen, dalam hal ini bank-churn-experiment. Jika Anda tidak melihat eksperimen di ruang kerja Anda, refresh browser Anda.



Menilai performa model terlatih pada himpunan data validasi
Setelah selesai dengan pelatihan model pembelajaran mesin, Anda dapat menilai performa model terlatih dengan dua cara.
Buka eksperimen yang disimpan dari ruang kerja, muat model pembelajaran mesin, lalu nilai performa model yang dimuat pada himpunan data validasi.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMSecara langsung menilai performa model pembelajaran mesin terlatih pada himpunan data validasi.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Tergantung pada preferensi Anda, salah satu pendekatan baik-baik saja dan harus menawarkan performa yang identik. Dalam notebook ini, Anda akan memilih pendekatan pertama untuk menunjukkan kemampuan autologging MLflow dengan lebih baik di Microsoft Fabric.
Tampilkan Positif Benar/Salah/Negatif menggunakan Matriks Kebingungan
Selanjutnya, Anda akan mengembangkan skrip untuk memplot matriks kebingungan untuk mengevaluasi akurasi klasifikasi menggunakan himpunan data validasi. Matriks kebingungan juga dapat diplot menggunakan alat SynapseML, yang ditampilkan dalam sampel Deteksi Penipuan yang tersedia di sini.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
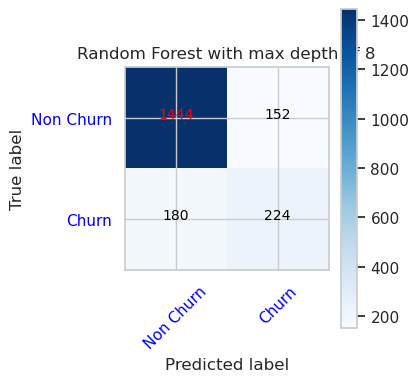
- Matriks Kebingungan untuk Pengklasifikasi Hutan Acak dengan kedalaman maksimum 4 dan 4 fitur
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
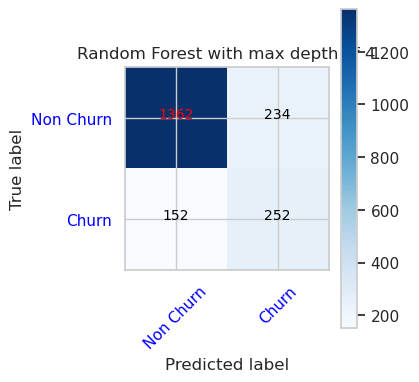
- Matriks Kebingungan untuk Pengklasifikasi Hutan Acak dengan kedalaman maksimum 8 dan 6 fitur
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
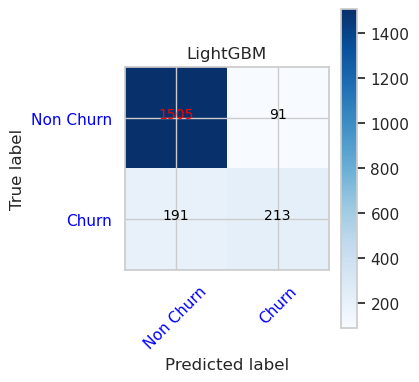
- Matriks Kebingungan untuk LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()