Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Con l'uso di Power Fx, le formule low-code open source, puoi aggiungere integrazioni più potenti e flessibili dei modelli di intelligenza artificiale nella tua Power App. Le formule di previsione del modello di intelligenza artificiale possono essere integrate con qualsiasi controllo nell'app canvas. Ad esempio, puoi rilevare la lingua del testo in un controllo di input di testo e inviare i risultati a un controllo etichetta, come si può vedere nella sezione Usare un modello con controlli sottostante.
Requisiti
Per usare Power Fx nei modelli di AI Builder devi avere:
Accesso a un ambiente Microsoft Power Platform con un database.
Licenza di AI Builder (di prova o a pagamento). Per altre informazioni, vedi Licenze di AI Builder.
Selezionare un modello nelle app canvas
Per utilizzare un modello IA con Power Fx, dovrai creare un'app canvas, scegliere un controllo e assegnare espressioni alle proprietà del controllo.
Nota
Per un elenco di modelli di AI Builder che puoi usare, vedi Modelli di intelligenza artificiale e scenari aziendali. Puoi anche usare modelli integrati in Microsoft Azure Machine Learning con la funzionalità Importa il tuo modello.
Crea un'app. Altre informazioni: Creare un'app canvas da zero.
Seleziona Dati>Aggiungi dati>Modelli di intelligenza artificiale.
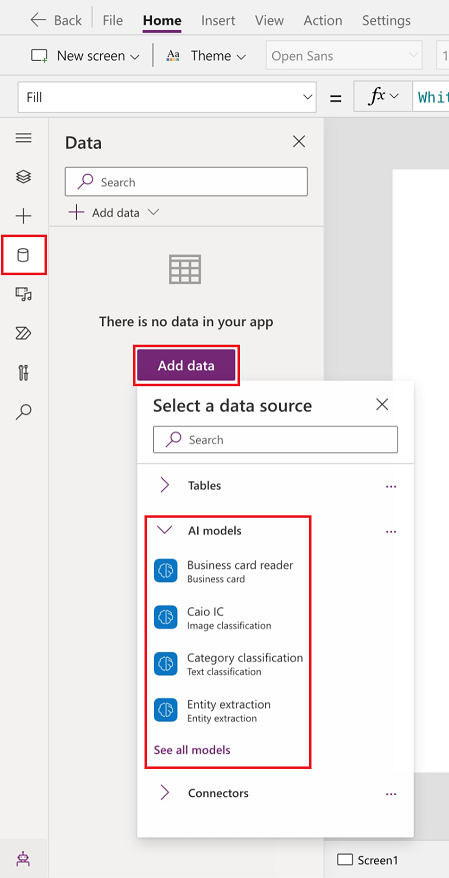
Seleziona uno o più modelli da aggiungere.
Se non vedi il tuo modello in questo elenco, potresti non avere le autorizzazioni per usarlo in Power Apps. Per correggere il problema, contatta l'amministratore.
Utilizzare un modello con controlli
Ora che hai aggiunto il modello di intelligenza artificiale alla tua app canvas, vediamo come si chiama un modello AI Builder da un controllo.
Nell'esempio seguente creeremo un'app in grado di rilevare la lingua immessa da un utente nell'app.
Crea un'app. Altre informazioni: Creare un'app canvas da zero.
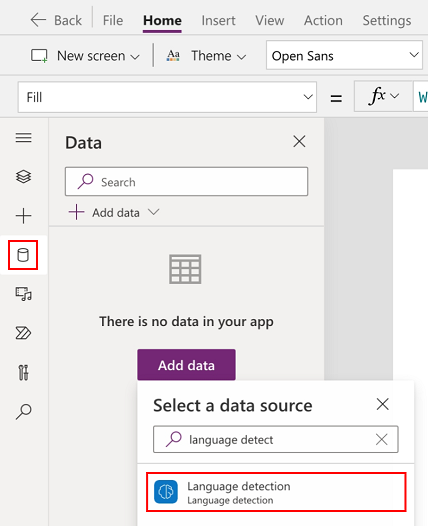
Seleziona Dati>Aggiungi dati>Modelli di intelligenza artificiale.
Cerca e seleziona il modello di intelligenza artificiale Rilevamento della lingua.
Nota
Dovrai aggiungere di nuovo manualmente il modello all'app nel nuovo ambiente dopo aver spostato l'app tra gli ambienti.
Seleziona + nel riquadro a sinistra e seleziona il controllo Input di testo.
Ripeti il passaggio precedente per aggiungere un controllo Etichetta di testo.
Rinomina l'etichetta di testo in Lingua.
Aggiungi un'altra etichetta di testo accanto all'etichetta "Lingua".
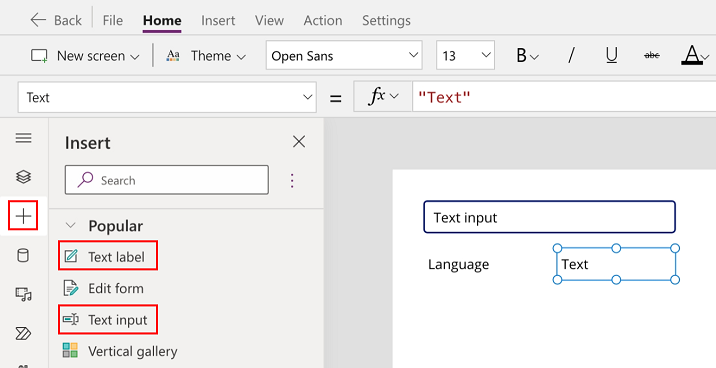
Seleziona l'etichetta di testo aggiunta nel passaggio precedente.
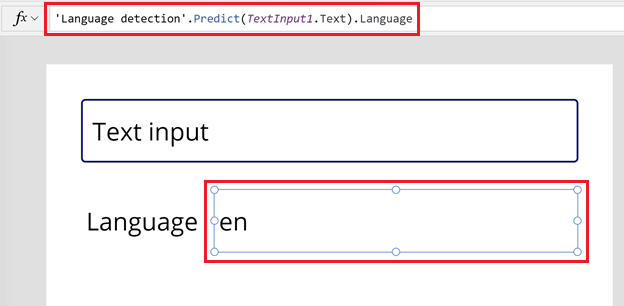
Immetti la seguente formula nella barra della formula per la proprietà Testo dell'etichetta di testo.
'Language detection'.Predict(TextInput1.Text).LanguageL'etichetta cambia nel codice lingua della tua lingua. In questo esempio, en (inglese).
Vedi l'anteprima dell'app selezionando il pulsante Esegui nell'angolo in alto a destra dello schermo.
Nella casella di testo immetti
bonjour. Nota che la lingua per la Francia (fr) viene visualizzata sotto la casella di testo.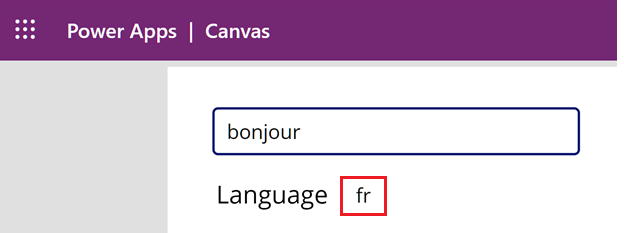
Allo stesso modo, prova un testo in un'altra lingua. Ad esempio, immettendo
guten tagcambia la lingua rilevata in de per la lingua tedesca.
Procedure consigliate
Prova ad attivare il modello previsione da azioni singole come OnClick utilizzando un pulsante anziché l'azione OnChange su un input di testo per garantire un uso efficiente dei crediti di AI Builder.
Per risparmiare tempo e risorse, salva il risultato di una chiamata modello in modo da poterlo utilizzare in più posizioni. È possibile salvare un output in una variabile globale. Dopo aver salvato il risultato del modello, puoi usare la lingua altrove nell'app per mostrare la lingua identificata e il relativo punteggio di affidabilità in due etichette diverse.
Set(lang, 'Language detection'.Predict("bonjour").Language)
Input e output per tipo di modello
Questa sezione fornisce input e output per modelli personalizzati e predefiniti per tipo di modello.
Modelli personalizzati
| Tipo di modello | Sintassi | Output |
|---|---|---|
| Classificazione categoria | 'Custom text classification model name'.Predict(Text: String, Language?: Optional String) |
{AllClasses: {Name: String, Confidence: Number}[],TopClass: {Name: String,Confidence: Number}} |
| Estrazione entità | 'Custom entity extraction model name’.Predict(Text: String,Language?:String(Optional)) |
{Entities:[{Type: "name",Value: "Bill", StartIndex: 22, Length: 4, Confidence: .996, }, { Type: "name", Value: "Gwen", StartIndex: 6, Length: 4, Confidence: .821, }]} |
| Rilevamento oggetti | 'Custom object detection model name'.Predict(Image: Image) |
{ Objects: { Name: String, Confidence: Number, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }}[]} |
Modelli predefiniti
Nota
I nomi dei modelli predefiniti vengono visualizzati nelle impostazioni locali dell'ambiente. Gli esempi seguenti mostrano i nomi dei modelli per la lingua inglese (en).
| Tipo di modello | Sintassi | Output |
|---|---|---|
| Business card reader | ‘Business card reader’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text", Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| Classificazione categoria | 'Category classification'.Predict( Text: String,Language?: Optional String, ) |
{ AllClasses: { Name: String, Confidence: Number }[], TopClass: { Name: String, Confidence: Number }} |
| Lettore documenti di identità | ‘Identity document reader’.Predict( Document: Base64 encoded image ) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text", Confidence: Number, Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| Elaborazione fattura | ‘Invoice processing’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number,Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: { Items: { Rows: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } }} |
| Estrazione frasi chiave | 'Key phrase extraction'.Predict(Text: String, Language?: Optional String)) |
{ Phrases: String[]} |
| Rilevamento lingua | 'Language Detection'.Predict(Text: String) |
{ Language: String, Confidence: Number} |
| Elaborazione ricevute | ‘Receipt processing’.Predict( Document: Base64 encoded image) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: {Items: {Rows: {FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } } } |
| Analisi valutazione | 'Sentiment analysis'.Predict( Text: String, Language?: Optional String ) |
{ Document: { AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } } Sentences: { StartIndex: Number, Length: Number, AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } }[]} |
| Riconoscimento del testo | 'Text recognition'.Predict( Document: Base64 encoded image) |
{Pages: {Page: Number,Lines: { Text: String, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }, Confidence: Number }[] }[]} |
| Traduzione testo | 'Text translation'.Predict( Text: String, TranslateTo?: String, TranslateFrom?: String) |
{ Text: String, // Translated text DetectedLanguage?: String, DetectedLanguageConfidence: Number} } |
Esempi
Ogni modello viene invocato usando il verbo prevedere. Ad esempio, un modello di rilevamento della lingua accetta il testo come input e restituisce una tabella di possibili lingue, ordinate in base al punteggio di quella lingua. Il punteggio indica quanto è sicuro il modello con la previsione.
| Input | Output |
|---|---|
'Language detection'.Predict("bonjour") |
{ Language: “fr”, Confidence: 1} |
‘Text Recognition’.Predict(Image1.Image) |
{ Pages: [ {Page: 1, Lines: [ { Text: "Contoso account", BoundingBox: { Left: .15, Top: .05, Width: .8, Height: .10 }, Confidence: .97 }, { Text: "Premium service", BoundingBox: { Left: .15, Top: .20, Width: .8, Height: .10 }, Confidence: .96 }, { Text: "Paid in full", BoundingBox: { Left: .15, Top: .35, Width: .8, Height: .10 }, Confidence: .99 } } ] } |