Questo articolo presenta una soluzione e linee guida per lo sviluppo di operazioni di dati offline e gestione dei dati (DataOps) per un sistema di guida automatizzato. La soluzione DataOps si basa sul framework descritto in Guida alla progettazione delle operazioni dei veicoli autonomi (AVOps). DataOps è uno dei blocchi predefiniti di AVOps. Altri blocchi predefiniti includono le operazioni di Machine Learning (MLOps), le operazioni di convalida (ValOps), DevOps e le funzioni AVOps centralizzate.
Apache, Apache® Spark e Apache Parquet sono marchi o marchi registrati di Apache Software Foundation nei Stati Uniti e/o in altri paesi. Nessuna approvazione da parte di Apache Software Foundation è implicita dall'uso di questi marchi.
Architettura

Scaricare un file di Visio contenente i diagrammi dell'architettura in questo articolo.
Flusso di dati
I dati di misurazione hanno origine nei flussi di dati di un veicolo. Le fonti includono telecamere, telemetria dei veicoli e radar, ultrasuoni e sensori lidar. I logger di dati nel veicolo archiviano i dati di misurazione nei dispositivi di archiviazione del logger. I dati di archiviazione del logger vengono caricati in un data lake di destinazione. Un servizio come Azure Data Box o Azure Stack Edge o una connessione dedicata come Azure ExpressRoute inserisce i dati in Azure. I dati di misura nei formati seguenti vengono inseriti in Azure Data Lake Archiviazione: Measurement Data Format versione 4 (MDF4), sistemi di gestione dei dati tecnici (TDMS) e rosbag. I dati caricati entrano in un account di archiviazione dedicato denominato Landing designato per la ricezione e la convalida dei dati.
Una pipeline di Azure Data Factory viene attivata a intervalli pianificati per elaborare i dati nell'account di archiviazione di destinazione. La pipeline gestisce i passaggi seguenti:
- Esegue un controllo qualità dei dati, ad esempio un checksum. Questo passaggio rimuove i dati di bassa qualità in modo che solo i dati di alta qualità passino alla fase successiva. app Azure servizio viene usato per eseguire il codice di controllo qualità. I dati ritenuti incompleti vengono archiviati per un'elaborazione futura.
- Per il rilevamento della derivazione, chiama un'API di metadati usando servizio app. Questo passaggio aggiorna i metadati archiviati in Azure Cosmos DB per creare un nuovo flusso di dati. Per ogni misura è presente un flusso di dati non elaborato.
- Copia i dati in un account di archiviazione denominato Raw in Data Lake Archiviazione.
- Chiama l'API dei metadati per contrassegnare il flusso di dati come completo in modo che altri componenti e servizi possano utilizzare il flusso di dati.
- Archivia le misurazioni e le rimuove dall'account di archiviazione di destinazione.
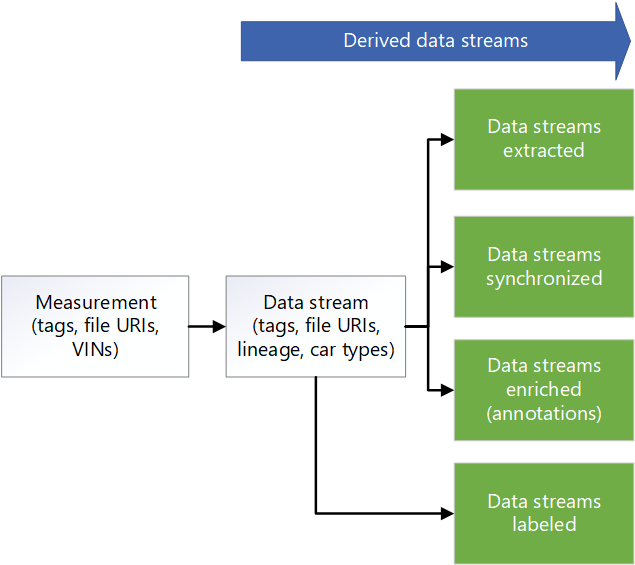
Data Factory e Azure Batch elaborano i dati nella zona non elaborata per estrarre informazioni che i sistemi downstream possono utilizzare:
- Batch legge i dati dagli argomenti nel file non elaborato e restituisce i dati in argomenti selezionati nelle rispettive cartelle.
- Poiché i file nella zona non elaborata possono essere di dimensioni superiori a 2 GB, le funzioni di estrazione di elaborazione parallele vengono eseguite in ogni file. Queste funzioni estraggono i dati di elaborazione delle immagini, lidar, radar e GPS. Eseguono anche l'elaborazione dei metadati. Data Factory e Batch consentono di eseguire il parallelismo in modo scalabile.
- I dati vengono sottocampionati per ridurre la quantità di dati che devono essere etichettati e annotati.
Se i dati del logger del veicolo non vengono sincronizzati tra i vari sensori, viene attivata una pipeline di Data Factory che sincronizza i dati per creare un set di dati valido. L'algoritmo di sincronizzazione viene eseguito in Batch.
Una pipeline di Data Factory viene eseguita per arricchire i dati. Esempi di miglioramenti includono dati di telemetria, dati del logger del veicolo e altri dati, ad esempio dati meteo, mappa o oggetto. I dati arricchiti consentono di fornire ai data scientist informazioni dettagliate che possono usare nello sviluppo di algoritmi, ad esempio. I dati generati vengono conservati in file Apache Parquet compatibili con i dati sincronizzati. I metadati relativi ai dati arricchiti vengono archiviati in un archivio di metadati in Azure Cosmos DB.
I partner di terze parti eseguono l'etichettatura manuale o automatica. I dati vengono condivisi con i partner di terze parti tramite Azure Condivisione dati ed è integrato in Microsoft Purview. Condivisione dati usa un account di archiviazione dedicato denominato Etichettata in Data Lake Archiviazione per restituire i dati etichettati all'organizzazione.
Una pipeline di Data Factory esegue il rilevamento della scena. I metadati della scena vengono mantenuti nell'archivio metadati. I dati della scena vengono archiviati come oggetti in file Parquet o Delta.
Oltre ai metadati per i dati di arricchimento e le scene rilevate, l'archivio metadati in Azure Cosmos DB archivia i metadati per le misurazioni, ad esempio i dati delle unità. Questo archivio contiene anche metadati per la derivazione dei dati durante l'esecuzione dei processi di estrazione, downcampionamento, sincronizzazione, arricchimento e rilevamento della scena. L'API dei metadati viene usata per accedere alle misurazioni, alla derivazione e ai dati della scena e per cercare dove vengono archiviati i dati. Di conseguenza, l'API dei metadati funge da gestore dei livelli di archiviazione. Distribuisce i dati tra gli account di archiviazione. Offre inoltre agli sviluppatori un modo per usare una ricerca basata su metadati per ottenere le posizioni dei dati. Per questo motivo, l'archivio metadati è un componente centralizzato che offre tracciabilità e derivazione nel flusso di dati della soluzione.
Azure Databricks e Azure Synapse Analytics vengono usati per connettersi all'API dei metadati e accedere a Data Lake Archiviazione ed eseguire ricerche sui dati.
Componenti
- Data Box consente di inviare terabyte di dati da e verso Azure in modo rapido, economico e affidabile. In questa soluzione, Data Box viene usato per trasferire i dati dei veicoli raccolti in Azure tramite un vettore regionale.
- I dispositivi Azure Stack Edge offrono funzionalità di Azure nelle posizioni perimetrali. Esempi di funzionalità di Azure includono calcolo, archiviazione, rete e Machine Learning con accelerazione hardware.
- ExpressRoute estende una rete locale nel cloud Microsoft tramite una connessione privata.
- Data Lake Archiviazione contiene una grande quantità di dati nel formato nativo e non elaborato. In questo caso, Data Lake Archiviazione archivia i dati in base alle fasi, ad esempio non elaborate o estratte.
- Data Factory è una soluzione completamente gestita e serverless per la creazione e la pianificazione di flussi di lavoro di estrazione, trasformazione, caricamento (ETL) ed estrazione, caricamento, trasformazione (ELT). In questo caso, Data Factory esegue ETL tramite calcolo batch e crea flussi di lavoro basati sui dati per orchestrare lo spostamento dei dati e trasformare i dati.
- Batch esegue processi batch paralleli e HPC (High Performance Computing) su larga scala in modo efficiente in Azure. Questa soluzione usa Batch per eseguire applicazioni su larga scala per attività quali data wrangling, filtro e preparazione dei dati ed estrazione dei metadati.
- Azure Cosmos DB è un database multimodello distribuito a livello globale. In questo caso vengono archiviati i risultati dei metadati, ad esempio le misurazioni archiviate.
- Condivisione dati condivide i dati con le organizzazioni partner con sicurezza avanzata. Usando la condivisione sul posto, i provider di dati possono condividere i dati in cui si trovano senza copiare i dati o creare snapshot. In questa soluzione, Condivisione dati condivide i dati con le aziende di etichettatura.
- Azure Databricks offre un set di strumenti per la gestione di soluzioni di dati di livello aziendale su larga scala. È necessario per operazioni a esecuzione prolungata su grandi quantità di dati del veicolo. I data engineer usano Azure Databricks come workbench di analisi.
- Azure Synapse Analytics riduce il tempo necessario per ottenere informazioni dettagliate tra data warehouse e sistemi Big Data.
- Ricerca cognitiva di Azure fornisce servizi di ricerca del catalogo dati.
- servizio app fornisce un servizio app Web basato su serverless. In questo caso, servizio app ospita l'API dei metadati.
- Microsoft Purview offre la governance dei dati tra le organizzazioni.
- Registro Azure Container è un servizio che crea un registro gestito di immagini del contenitore. Questa soluzione usa Registro Container per archiviare i contenitori per l'elaborazione di argomenti.
- Application Insights è un'estensione di Monitoraggio di Azure che fornisce la gestione delle prestazioni delle applicazioni. In questo scenario Application Insights consente di creare osservabilità per l'estrazione delle misurazioni: è possibile usare Application Insights per registrare eventi personalizzati, metriche personalizzate e altre informazioni mentre la soluzione elabora ogni misura per l'estrazione. È anche possibile compilare query su Log Analytics per ottenere informazioni dettagliate su ogni misura.
Dettagli dello scenario
La progettazione di un framework DataOps affidabile per i veicoli autonomi è fondamentale per l'uso dei dati, la traccia della derivazione e la sua disponibilità in tutta l'organizzazione. Senza un processo DataOps ben progettato, la grande quantità di dati generati dai veicoli autonomi può diventare rapidamente travolgente e difficile da gestire.
Quando si implementa una strategia DataOps efficace, è possibile assicurarsi che i dati vengano archiviati correttamente, facilmente accessibili e con una chiara derivazione. È anche facile gestire e analizzare i dati, portando a decisioni più informate e a migliorare le prestazioni dei veicoli.
Un processo DataOps efficiente consente di distribuire facilmente i dati in tutta l'organizzazione. Vari team possono quindi accedere alle informazioni necessarie per ottimizzare le operazioni. DataOps semplifica la collaborazione e la condivisione di informazioni dettagliate, che consentono di migliorare l'efficacia complessiva dell'organizzazione.
Le problematiche tipiche per le operazioni sui dati nel contesto dei veicoli autonomi includono:
- Gestione del volume giornaliero su scala terabyte o petabyte dei dati di misurazione provenienti da veicoli di ricerca e sviluppo.
- Condivisione e collaborazione dei dati tra più team e partner, ad esempio per l'etichettatura, le annotazioni e i controlli di qualità.
- Tracciabilità e derivazione per uno stack di percezione critico per la sicurezza che acquisisce il controllo delle versioni e la derivazione dei dati di misurazione.
- Metadati e individuazione dei dati per migliorare la segmentazione semantica, la classificazione delle immagini e i modelli di rilevamento oggetti.
Questa soluzione AVOps DataOps fornisce indicazioni su come affrontare queste sfide.
Potenziali casi d'uso
Questa soluzione offre vantaggi ai produttori di apparecchiature originali (OEM), ai fornitori di livello 1 e ai fornitori di software indipendenti (ISV) che sviluppano soluzioni per la guida automatizzata.
Operazioni di dati federati
In un'organizzazione che implementa AVOps, più team contribuiscono a DataOps a causa della complessità necessaria per AVOps. Ad esempio, un team potrebbe essere responsabile della raccolta dei dati e dell'inserimento dati. Un altro team potrebbe essere responsabile della gestione della qualità dei dati dei dati lidar. Per questo motivo, i principi seguenti di un'architettura mesh di dati sono importanti da considerare per DataOps:
- Decentramento orientato al dominio della proprietà e dell'architettura dei dati. Un team dedicato è responsabile di un dominio dati che fornisce prodotti dati per tale dominio, ad esempio set di dati etichettati.
- Dati come prodotto. Ogni dominio dati ha diverse zone nei contenitori di archiviazione implementati da Data Lake. Esistono zone per l'utilizzo interno. Esiste anche una zona che contiene prodotti dati pubblicati per altri domini dati o utilizzo esterno per evitare la duplicazione dei dati.
- I dati self-service sono una piattaforma per consentire team di dati autonomi e orientati al dominio.
- Governance federata per abilitare l'interoperabilità e l'accesso tra domini dati AVOps che richiedono un archivio di metadati centralizzato e un catalogo dati. Ad esempio, un dominio dati di etichettatura potrebbe dover accedere a un dominio di raccolta dati.
Per altre informazioni sulle implementazioni della mesh di dati, vedere Analisi su scala cloud.
Struttura di esempio per i domini dati AVOps
La tabella seguente fornisce alcune idee per strutturare i domini dati AVOps:
| Dominio dati | Prodotti dati pubblicati | Passaggio della soluzione |
|---|---|---|
| Raccolta dati | File di misurazione caricati e convalidati | Atterraggio e raw |
| Immagini estratte | Immagini o fotogrammi selezionati ed estratti, lidar e dati radar | Estratto |
| Radar estratto o lidar | Dati lidar e radar selezionati ed estratti | Estratto |
| Dati di telemetria estratti | Dati di telemetria dell'auto selezionati ed estratti | Estratto |
| Etichettato | Set di dati etichettati | Etichettato |
| Ricomputazione | Indicatori di prestazioni chiave generati (KPI) in base alle esecuzioni ripetute della simulazione | Ricomputazione |
Ogni dominio dati AVOps viene configurato in base a una struttura di progetto. Questa struttura include i runtime di Data Factory, Data Lake Archiviazione, database, Batch e Apache Spark tramite Azure Databricks o Azure Synapse Analytics.
Metadati e individuazione dei dati
Ogni dominio dati è decentralizzato e gestisce singolarmente i prodotti dati AVOps corrispondenti. Per l'individuazione dei dati centrale e per sapere dove si trovano i prodotti dati, sono necessari due componenti:
- Archivio metadati che rende persistenti i metadati relativi ai file di misurazione elaborati e ai flussi di dati, ad esempio sequenze video. Questo componente rende i dati individuabili e tracciabili con annotazioni che devono essere indicizzate, ad esempio per cercare i metadati di file senza etichetta. Ad esempio, è possibile che l'archivio dei metadati restituisca tutti i fotogrammi per numeri di identificazione del veicolo specifici (VIN) o frame con pedoni o altri oggetti basati sull'arricchimento.
- Catalogo dati che mostra la derivazione, le dipendenze tra domini dati AVOps e quali archivi dati sono coinvolti nel ciclo di dati AVOps. Un esempio di catalogo dati è Microsoft Purview.
È possibile usare Azure Esplora dati o Ricerca cognitiva di Azure per estendere un archivio metadati basato su Azure Cosmos DB. La selezione dipende dallo scenario finale necessario per l'individuazione dei dati. Usare Ricerca cognitiva di Azure per le funzionalità di ricerca semantica.
Il diagramma del modello di metadati seguente mostra un tipico modello di metadati unificato usato in diversi pilastri del ciclo di dati AVOps:
Condivisione dei dati
La condivisione dei dati è uno scenario comune in un ciclo di dati AVOps. Gli usi includono la condivisione dei dati tra domini dati e condivisione esterna, ad esempio per integrare i partner di etichettatura. Microsoft Purview offre le funzionalità seguenti per una condivisione efficiente dei dati in un ciclo di dati:
I formati consigliati per lo scambio di dati delle etichette includono oggetti comuni nei set di dati di contesto (COCO) e Association for Standardization of Automation and Measuring Systems (ASAM) OpenLABEL set di dati.
In questa soluzione, i set di dati etichettati vengono usati nei processi MLOps per creare algoritmi specializzati, ad esempio la percezione e i modelli di fusione dei sensori. Gli algoritmi possono rilevare scene e oggetti in un ambiente, ad esempio la modifica delle corsie, le strade bloccate, il traffico pedonale, i semafori e i segnali stradali.
Pipeline di dati
In questa soluzione DataOps lo spostamento dei dati tra diverse fasi della pipeline di dati è automatizzato. Grazie a questo approccio, il processo offre vantaggi di efficienza, scalabilità, coerenza, riproducibilità, adattabilità e gestione degli errori. Migliora il processo di sviluppo complessivo, accelera i progressi e supporta la distribuzione sicura ed efficace delle tecnologie di guida autonoma.
Le sezioni seguenti descrivono come implementare lo spostamento dei dati tra le fasi e come strutturare gli account di archiviazione.
Struttura gerarchica delle cartelle
Una struttura di cartelle ben organizzata è un componente essenziale di una pipeline di dati nello sviluppo autonomo. Tale struttura fornisce una disposizione sistematica e facilmente esplorabile dei file di dati, semplificando una gestione efficiente dei dati e il recupero.
In questa soluzione i dati nella cartella non elaborata hanno la struttura gerarchica seguente:
region/raw/<measurement-ID>/<data-stream-ID>/AAAA/MM/GG
I dati nell'account di archiviazione della zona estratta usano una struttura gerarchica simile:
region/extracted/<measurement-ID>/<data-stream-ID>/AAAA/MM/GG
Usando strutture gerarchie simili, è possibile sfruttare la funzionalità dello spazio dei nomi gerarchico di Data Lake Archiviazione. Le strutture gerarchica consentono di creare un archivio oggetti scalabile e conveniente. Queste strutture migliorano anche l'efficienza della ricerca e del recupero degli oggetti. Il partizionamento per anno e VIN semplifica la ricerca di immagini pertinenti da veicoli specifici. Nel data lake viene creato un contenitore di archiviazione per ogni sensore, ad esempio una fotocamera, un dispositivo GPS o un lidar o un sensore radar.
Destinazione dell'account di archiviazione nell'account di archiviazione non elaborato
Una pipeline di Data Factory viene attivata in base a una pianificazione. Dopo l'attivazione della pipeline, i dati vengono copiati dall'account di archiviazione di destinazione all'account di archiviazione non elaborato.

La pipeline recupera tutte le cartelle di misurazione e le scorre. Con ogni misura, la soluzione esegue le attività seguenti:
Una funzione convalida la misurazione. La funzione recupera il file manifesto dal manifesto di misurazione. La funzione controlla quindi se tutti i file di misurazione MDF4, TDMS e rosbag per la misurazione corrente esistono nella cartella di misurazione. Se la convalida ha esito positivo, la funzione procede con l'attività successiva. Se la convalida non riesce, la funzione ignora la misurazione corrente e passa alla cartella di misurazione successiva.
Viene eseguita una chiamata API Web a un'API che crea una misura e il payload JSON dal file JSON del manifesto di misurazione viene passato all'API. Se la chiamata ha esito positivo, la risposta viene analizzata per recuperare l'ID misura. Se la chiamata ha esito negativo, la misurazione viene spostata nell'attività di errore per la gestione degli errori.
Nota
Questa soluzione DataOps si basa sul presupposto che si limiti il numero di richieste al servizio app. Se la soluzione potrebbe creare un numero indeterminato di richieste, prendere in considerazione un modello di limitazione della frequenza.
Viene eseguita una chiamata API Web a un'API che crea un flusso di dati creando il payload JSON necessario. Se la chiamata ha esito positivo, la risposta viene analizzata per recuperare l'ID del flusso di dati e il percorso del flusso di dati. Se la chiamata ha esito negativo, la misurazione viene spostata nell'attività di errore.
Viene eseguita una chiamata API Web per aggiornare lo stato del flusso di dati a
Start Copy. Se la chiamata ha esito positivo, l'attività di copia copia i file di misurazione nel percorso del flusso di dati. Se la chiamata ha esito negativo, la misurazione viene spostata nell'attività di errore.Una pipeline di Data Factory richiama Batch per copiare i file di misura dall'account di archiviazione di destinazione all'account di archiviazione non elaborato. Un modulo di copia di un'app dell'agente di orchestrazione crea un processo con le attività seguenti per ogni misurazione:
- Copiare i file di misura nell'account di archiviazione non elaborato.
- Copiare i file di misura in un account di archiviazione di archiviazione.
- Rimuovere i file di misurazione dall'account di archiviazione di destinazione.
Nota
In queste attività Batch usa un pool di agenti di orchestrazione e lo strumento AzCopy per copiare e rimuovere i dati. AzCopy usa token di firma di accesso condiviso per eseguire attività di copia o rimozione. I token di firma di accesso condiviso vengono archiviati in un insieme di credenziali delle chiavi e fanno riferimento usando i termini
landingsaskey,archivesaskeyerawsaskey.Viene eseguita una chiamata API Web per aggiornare lo stato del flusso di dati a
Copy Complete. Se la chiamata ha esito positivo, la sequenza passa all'attività successiva. Se la chiamata ha esito negativo, la misurazione viene spostata nell'attività di errore.I file di misurazione vengono spostati dall'account di archiviazione di destinazione a un archivio di destinazione. Questa attività può rieseguire una determinata misurazione spostandola di nuovo nell'account di archiviazione di destinazione tramite una pipeline di copia idratata. La gestione del ciclo di vita è attivata per questa zona in modo che le misurazioni in questa zona vengano eliminate o archiviate automaticamente.
Se si verifica un errore con una misurazione, la misura viene spostata in una zona di errore. Da qui, può essere spostato nell'account di archiviazione di destinazione da eseguire di nuovo. In alternativa, la gestione del ciclo di vita può eliminare o archiviare automaticamente la misurazione.
Notare i punti seguenti:
- Queste pipeline vengono attivate in base a una pianificazione. Questo approccio consente di migliorare la tracciabilità delle esecuzioni della pipeline e di evitare esecuzioni non necessarie.
- Ogni pipeline è configurata con un valore di concorrenza pari a uno per assicurarsi che le esecuzioni precedenti vengano completate prima dell'avvio dell'esecuzione pianificata successiva.
- Ogni pipeline è configurata per copiare le misurazioni in parallelo. Ad esempio, se un'esecuzione pianificata preleva 10 misurazioni da copiare, i passaggi della pipeline possono essere eseguiti simultaneamente per tutte e dieci le misurazioni.
- Ogni pipeline è configurata per generare un avviso in Monitoraggio se la pipeline richiede più tempo del tempo previsto per il completamento.
- L'attività on-error viene implementata nelle storie di osservabilità successive.
- La gestione del ciclo di vita elimina automaticamente le misurazioni parziali, ad esempio le misurazioni con file rosbag mancanti.
Progettazione batch
Tutta la logica di estrazione viene inserita in pacchetti in immagini contenitore diverse, con un contenitore per ogni processo di estrazione. Batch esegue i carichi di lavoro del contenitore in parallelo quando estrae informazioni dai file di misurazione.

Batch usa un pool di agenti di orchestrazione e un pool di esecuzione per l'elaborazione dei carichi di lavoro:
- Un pool di agenti di orchestrazione include nodi Linux senza il supporto del runtime del contenitore. Il pool esegue codice Python che usa l'API Batch per creare processi e attività per il pool di esecuzione. Questo pool monitora anche tali attività. Data Factory richiama il pool di agenti di orchestrazione, che orchestra i carichi di lavoro del contenitore che estraggono i dati.
- Un pool di esecuzione include nodi Linux con runtime di contenitori per supportare l'esecuzione di carichi di lavoro del contenitore. Per questo pool, i processi e le attività vengono pianificati tramite il pool di agenti di orchestrazione. Tutte le immagini del contenitore necessarie per l'elaborazione nel pool di esecuzione vengono push in un registro contenitori usando JFrog. Il pool di esecuzione è configurato per connettersi al Registro di sistema ed eseguire il pull delle immagini necessarie.
Archiviazione gli account da cui i dati vengono letti e scritti vengono montati tramite NFS 3.0 nei nodi batch e nei contenitori eseguiti nei nodi. Questo approccio consente ai nodi batch e ai contenitori di elaborare rapidamente i dati senza la necessità di scaricare i file di dati in locale nei nodi batch.
Nota
Gli account batch e di archiviazione devono trovarsi nella stessa rete virtuale per il montaggio.
Richiamare Batch da Data Factory
Nella pipeline di estrazione il trigger passa il percorso del file di metadati e il percorso del flusso di dati non elaborato nei parametri della pipeline. Data Factory usa un'attività di ricerca per analizzare il codice JSON dal file manifesto. L'ID del flusso di dati non elaborato può essere estratto dal percorso del flusso di dati non elaborato analizzando la variabile della pipeline.
Data Factory chiama un'API per creare un flusso di dati. L'API restituisce il percorso per il flusso di dati estratto. Il percorso estratto viene aggiunto all'oggetto corrente e Data Factory richiama Batch tramite un'attività personalizzata passando l'oggetto corrente, dopo aver accodato il percorso del flusso di dati estratto:
{
"measurementId":"210b1ba7-9184-4840-a1c8-eb£397b7c686",
"rawDataStreamPath":"raw/2022/09/30/KA123456/210b1ba7-9184-4840-
alc8-ebf39767c68b/57472a44-0886-475-865a-ca32{c851207",
"extractedDatastreamPath":"extracted/2022/09/30/KA123456
/210bIba7-9184-4840-a1c8-ebf39767c68b/87404c9-0549-4a18-93ff-d1cc55£d8b78",
"extractedDataStreamId":"87404bc9-0549-4a18-93ff-d1cc55fd8b78"
}
Processo di estrazione passo per passo

Data Factory pianifica un processo con un'attività per il pool di agenti di orchestrazione per elaborare una misura per l'estrazione. Data Factory passa le informazioni seguenti al pool di agenti di orchestrazione:
- ID misura
- Posizione dei file di misura di tipo MDF4, TDMS o rosbag da estrarre
- Percorso di destinazione del percorso di archiviazione del contenuto estratto
- ID del flusso di dati estratto
Il pool di agenti di orchestrazione richiama un'API per aggiornare il flusso di dati e impostarne lo stato su
Processing.Il pool di agenti di orchestrazione crea un processo per ogni file di misurazione che fa parte della misurazione. Ogni processo contiene le attività seguenti:
Attività Scopo Nota Convalida Verifica che i dati possano essere estratti dal file di misurazione. Tutte le altre attività dipendono da questa attività. Elaborare i metadati Deriva i metadati dal file di misurazione e arricchisce i metadati del file usando un'API per aggiornare i metadati del file. Processo StructuredTopicsEstrae dati strutturati da un determinato file di misurazione. L'elenco di argomenti da cui estrarre dati strutturati viene passato come oggetto di configurazione. Processo CameraTopicsEstrae i dati dell'immagine da un determinato file di misurazione. L'elenco di argomenti da cui estrarre le immagini viene passato come oggetto di configurazione. Processo LidarTopicsEstrae i dati lidar da un determinato file di misurazione. L'elenco di argomenti da cui estrarre i dati lidar viene passato come oggetto di configurazione. Processo CANTopicsEstrae i dati della rete dell'area controller (CAN) da un determinato file di misurazione. L'elenco di argomenti da cui estrarre i dati viene passato come oggetto di configurazione. Il pool di agenti di orchestrazione monitora lo stato di avanzamento di ogni attività. Al termine di tutti i processi per tutti i file di misurazione, il pool richiama un'API per aggiornare il flusso di dati e impostarne lo stato su
Completed.L'agente di orchestrazione viene chiuso normalmente.
Nota
Ogni attività è un'immagine contenitore separata con logica definita in modo appropriato per lo scopo. Le attività accettano oggetti di configurazione come input. Ad esempio, l'input specifica dove scrivere l'output e il file di misurazione da elaborare. Una matrice di tipi di argomento, ad esempio
sensor_msgs/Image, è un altro esempio di input. Poiché tutte le altre attività dipendono dall'attività di convalida, viene creata un'attività dipendente. Tutte le altre attività possono essere elaborate in modo indipendente e possono essere eseguite in parallelo.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Affidabilità
L'affidabilità garantisce che l'applicazione possa soddisfare gli impegni che l'utente ha preso con i clienti. Per altre informazioni, vedere Panoramica del pilastro dell'affidabilità.
- Nella soluzione prendere in considerazione l'uso delle zone di disponibilità di Azure, che sono posizioni fisiche univoche all'interno della stessa area di Azure.
- Pianificare il ripristino di emergenza e il failover dell'account.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
È importante comprendere la divisione della responsabilità tra un OEM automobilistico e Microsoft. In un veicolo, l'OEM possiede l'intero stack, ma man mano che i dati passano al cloud, alcune responsabilità vengono trasferite a Microsoft. I livelli PaaS (Platform as a Service) di Azure offrono sicurezza incorporata nello stack fisico, incluso il sistema operativo. È possibile aggiungere le funzionalità seguenti ai componenti di sicurezza dell'infrastruttura esistenti:
- Gestione delle identità e degli accessi che utilizza le identità di Microsoft Entra e i criteri di accesso condizionale di Microsoft Entra.
- Governance dell'infrastruttura che usa Criteri di Azure.
- Governance dei dati che usa Microsoft Purview.
- Crittografia dei dati inattivi che usa servizi nativi di archiviazione e database di Azure. Per altre informazioni, vedere Considerazioni sulla protezione dei dati.
- La salvaguardia delle chiavi crittografiche e dei segreti. Usare Azure Key Vault a questo scopo.
Ottimizzazione dei costi
L'ottimizzazione dei costi esamina i modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Un problema fondamentale per gli OEM e i fornitori di livello 1 che gestiscono DataOps per i veicoli automatizzati è il costo del funzionamento. Questa soluzione usa le procedure seguenti per ottimizzare i costi:
- Sfruttare le varie opzioni offerte da Azure per l'hosting del codice dell'applicazione. Questa soluzione usa servizio app e Batch. Per indicazioni su come scegliere il servizio appropriato per la distribuzione, vedere Scegliere un servizio di calcolo di Azure.
- Uso di Archiviazione di Azure condivisione dei dati sul posto.
- Ottimizzazione dei costi tramite la gestione del ciclo di vita.
- Risparmio sui costi per servizio app tramite istanze riservate.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Ryan Matsumura | Senior Program Manager
- Jochen Schroeer | Lead Architect (Service Line Mobility)
- Brij Singh | Principal Software Engineer
- Ginette Vellera | Senior Software Engineering Lead
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Informazioni su Azure Batch
- Che cos'è Azure Data Factory?
- Introduzione ad Azure Data Lake Storage Gen2
- Introduzione ad Azure Cosmos DB
- Panoramica del Servizio app
- Che cos'è Condivisione dati di Azure?
- Che cos'è Azure Data Box?
- Documentazione di Azure Stack Edge
- Che cos'è Azure ExpressRoute?
- Cos'è Azure Machine Learning?
- Informazioni su Azure Databricks
- Che cos'è Azure Synapse Analytics?
- Panoramica di Monitoraggio di Azure
- File di log ROS (rosbags)
- Piattaforma di operazioni dati su larga scala per veicoli autonomi