Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() Database SQL di Azure
Database SQL di Azure
Questo articolo offre una panoramica sulle risorse del database SQL di Azure. Fornisce informazioni su cosa accade quando vengono raggiunti i limiti delle risorse e descrive i meccanismi di governance delle risorse usati per applicare questi limiti.
Per limiti di risorse specifici per piano tariffario per database singoli, vedere:
- Limiti risorse basati su DTU - Database singolo
- Limiti delle risorse basate su vCore - database singoli
Per i limiti delle risorse del pool elastico, vedere:
Per i limiti di capacità per il pool SQL dedicato in Azure Synapse Analytics, fare riferimento a:
Limiti vCore della sottoscrizione per area
A partire da marzo 2024, le sottoscrizioni hanno i seguenti limiti vCore per area per sottoscrizione:
| Tipo di sottoscrizione | Limiti vCore predefiniti |
|---|---|
| Contratto Enterprise Agreement (EA) | 2000 |
| Versioni di valutazione gratuite | 10 |
| Microsoft per le startup | 100 |
| MSDN/MPN/Imagine/AzurePass/Azure for Students | 40 |
| Pagamento in base al consumo | 150 |
Considerare quanto segue:
- Questi limiti sono applicabili alle sottoscrizioni nuove ed esistenti.
- I database e i pool elastici di cui è stato effettuato il provisioning con il modello di acquisto DTU vengono conteggiati anche rispetto alla quota vCore e viceversa. Ogni vCore utilizzato è considerato equivalente a 100 DTU utilizzate per la quota a livello di server.
- I limiti predefiniti includono sia i vCore configurati per i database di calcolo di cui è stato effettuato il provisioning sia per i pool elastici che per i max vCore configurati per i database server less.
- È possibile usare la chiamata API REST Utilizzo delle sottoscrizioni - Get per determinare l'utilizzo di vCore corrente per la sottoscrizione.
- Per richiedere una quota vCore superiore rispetto all'impostazione predefinita, inviare una nuova richiesta di supporto nella portale di Azure. Per altre informazioni, vedere Aumento della quota di richieste per il database SQL di Azure e Istanza gestita di SQL.
Limiti del server logico
| Conto risorse | Limite |
|---|---|
| Database per server logico | 5.000 |
| Numero predefinito di server logici per sottoscrizione in ogni area | 250 |
| Numero massimo di server logici per sottoscrizione in ogni area | 250 |
| Numero massimo di pool elastici per server logico | Limitato dal numero di DTU o vCore. Se ad esempio ogni pool è da 1000 DTU, un server può supportare 54 pool. |
Importante
Poiché il numero di database si avvicina al limite per ogni server logico, può verificarsi quanto segue:
- Latenza in aumento nelle query in esecuzione nel database
master. Ciò include le visualizzazioni delle statistiche di utilizzo delle risorse, ad esempiosys.resource_stats. - Latenza in aumento nelle operazioni di gestione e nel portale di esecuzione del rendering dei punti di visualizzazione che coinvolgono l'enumerazione dei database nel server.
Cosa accade quando vengono raggiunti i limiti delle risorse?
Calcolo: CPU
Quando l'utilizzo della CPU di calcolo del database diventa elevato, la latenza delle query aumenta e si può persino verificare un time out delle query. In queste condizioni, le query potrebbero essere accodate dal servizio e vengono fornite risorse per l'esecuzione man mano che le risorse diventano gratuite.
Se si riscontra un uso elevato di risorse di elaborazione, le opzioni di mitigazione includono:
- Aumento delle dimensioni di calcolo del database o del pool elastico per mettere a disposizione del database un numero maggiore di risorse del computer. Vedere Ridimensionare le risorse del database singolo e Ridimensionare le risorse del pool elastico.
- Ottimizzazione delle query per ridurre l'uso delle risorse della CPU di ogni query. Per altre informazioni, vedere la sezione Hint/ottimizzazione di query.
Immagazzinamento
Quando lo spazio dati usato raggiunge il limite massimo di dimensioni dei dati, a livello di database o a livello di pool elastico, inserisce e aggiorna che aumentano le dimensioni dei dati ha esito negativo e i client ricevono un messaggio di errore . Le istruzioni edizione SELECT e DELETE rimangono invariate.
Nei livelli di servizio Premium e Business Critical, i client ricevono anche un messaggio di errore se il consumo combinato di archiviazione per dati, log delle transazioni e tempdb per un singolo database o un pool elastico supera le dimensioni massime di archiviazione locale. Per altre informazioni, vedere Governance degli spazi di archiviazione.
Se si osserva un utilizzo elevato dello spazio di archiviazione, le opzioni di mitigazione includono:
- Aumentare le dimensioni massime dei dati del database o del pool elastico o aumentare le prestazioni fino a un obiettivo di servizio con un limite massimo di dimensioni dei dati. Vedere Ridimensionare le risorse del database singolo e Ridimensionare le risorse del pool elastico.
- Se il database è in un pool elastico, in alternativa può essere spostato all'esterno del pool in modo che lo spazio di archiviazione non venga condiviso con altri database.
- Compattare un database per recuperare spazio inutilizzato. Per altre informazioni, vedere Gestire lo spazio file per i database.
- Nei pool elastici la compattazione di un database offre più spazio di archiviazione per altri database nel pool.
- Controllare se l'utilizzo dello spazio elevato è dovuto a un picco delle dimensioni dell'archivio versioni persistenti (PVS). PVS fa parte di ogni database e viene usato per implementare ripristino accelerato del database. Per determinare le dimensioni correnti del servizio pvs, vedere Risolvere i problemi relativi al ripristino accelerato del database. Un motivo comune per le dimensioni PVS di grandi dimensioni è una transazione aperta per molto tempo (ore), impedendo la pulizia delle versioni precedenti delle righe in PVS.
- Per i database e i pool elastici nei livelli di servizio Premium e Business Critical che utilizzano grandi quantità di spazio di archiviazione, è possibile che venga visualizzato un errore di spazio insufficiente anche se lo spazio usato nel database o nel pool elastico è inferiore al limite massimo di dimensioni dei dati. Ciò può verificarsi se
tempdbo i file di log delle transazioni utilizzano una grande quantità di spazio di archiviazione verso il limite massimo di archiviazione locale. Eseguire il failover del database o del pool elastico per ripristinaretempdballe dimensioni iniziali minori oppure ridurre il log delle transazioni per ridurre il consumo di archiviazione locale.
Sessioni, ruoli di lavoro e richieste
Le sessioni, i ruoli di lavoro e le richieste sono definiti come segue:
- Una sessione rappresenta un processo connesso al motore di database.
- Una richiesta è la rappresentazione logica di una query o un batch. Una richiesta viene eseguita da un client connesso a una sessione. Nel corso del tempo, è possibile eseguire più richieste nella stessa sessione.
- Un thread di lavoro, definito anche ruolo di lavoro o semplicemente thread, è una rappresentazione logica di un thread del sistema operativo. Una richiesta può avere molti ruoli di lavoro quando vengono eseguiti con un piano di esecuzione di query parallela o un singolo ruolo di lavoro quando viene eseguito con un piano di esecuzione seriale (a thread singolo). I ruoli di lavoro sono inoltre necessari per supportare attività esterne alle richieste: ad esempio, un ruolo di lavoro deve elaborare una richiesta di accesso come sessione si connette.
Per altre informazioni su questi concetti, vedere la guida all'architettura thread e attività.
Il numero massimo di ruoli di lavoro è determinato dal livello di servizio e dalle dimensioni di calcolo. Le nuove richieste vengono rifiutate quando vengono raggiunti i limiti delle sessioni o dei ruoli di lavoro e i clienti ricevono un messaggio di errore. Mentre il numero di connessioni può essere controllato dall'applicazione, il numero di ruoli di lavoro simultanei è spesso più difficile da stimare e da controllare. Ciò vale soprattutto durante i picchi di periodi di carico quando vengono raggiunti i limiti di risorse del database e i ruoli di lavoro si accumulano per via di query a esecuzione prolungata, catene di blocco di grandi dimensioni e parallelismo delle query eccessivo.
Nota
L'offerta iniziale di database SQL di Azure supporta solo query a thread singolo. In quel momento, il numero di richieste era sempre equivalente al numero di ruoli di lavoro. Il messaggio di errore 10928 in database SQL di Azure contiene solo la formulazione The request limit for the database is *N* and has been reached per motivi di compatibilità con le versioni precedenti. Il limite raggiunto è in realtà il numero di ruoli di lavoro.
Se l'impostazione max degree of parallelism (MAXDOP) è uguale a zero o è maggiore di una, il numero di ruoli di lavoro può essere molto superiore al numero di richieste e il limite può essere raggiunto molto prima di quando MAXDOP è uguale a uno.
- Altre informazioni sull'errore 10928 sono disponibili in Errori di governance delle risorse.
- Altre informazioni sull'esaurimento dei limiti di richiesta sono disponibili negli Errori 10928 e 10936.
È possibile attenuare l'avvicinamento o il raggiungimento dei limiti di lavoro o sessione in base a:
- Aumento del livello di servizio o delle dimensioni di calcolo del database o del pool elastico. Vedere Ridimensionare le risorse del database singolo e Ridimensionare le risorse del pool elastico.
- Ottimizzare le query per ridurre l'uso delle risorse se la causa di un aumento dei ruoli di lavoro è la contesa di risorse di calcolo. Per altre informazioni, vedere la sezione Hint/ottimizzazione di query.
- Ottimizzare il carico di lavoro delle query per ridurre il numero di occorrenze e la durata del blocco di query. Per altre informazioni, vedere Informazioni e risoluzione dei problemi di blocco.
- La riduzione dell'impostazione MAXDOP, laddove appropriato.
Trovare i limiti delle sessioni e dei ruoli di lavoro per database SQL di Azure in base al livello di servizio e alle dimensioni di calcolo:
- Limiti di risorse per i database singoli usando il modello di acquisto vCore
- Limiti delle risorse per i pool elastici secondo il modello di acquisto vCore
- Limiti di risorse per i database singoli usando il modello di acquisto DTU
- Limiti delle risorse per i pool elastici usando il modello di acquisto DTU
Altre informazioni sulla risoluzione di errori specifici per i limiti di sessione o di lavoro in Errori di governance delle risorse.
Connessioni esterne
Il numero di connessioni simultanee agli endpoint esterni eseguite tramite sp_invoke_external_rest_endpoint è limitato al 10% dei thread di lavoro, con un limite massimo di 150 ruoli di lavoro.
Memoria
A differenza di altre risorse (CPU, ruoli di lavoro, archiviazione), il raggiungimento del limite di memoria non influisce negativamente sulle prestazioni delle query e non causa errori e errori. Come descritto in dettaglio in guida all'architettura di gestione della memoria, il motore di database usa spesso tutta la memoria disponibile, per impostazione predefinita. La memoria viene usata principalmente per la memorizzazione dei dati nella cache in modo da evitare un accesso più lento alla risorsa di archiviazione. Di conseguenza, un utilizzo più elevato della memoria migliora in genere le prestazioni delle query grazie a operazioni di lettura più veloci dalla memoria, anziché operazioni di lettura più lente dalla risorsa di archiviazione.
Dopo l'avvio del motore di database, quando il carico di lavoro inizia a leggere i dati dall'archiviazione, il motore di database memorizza nella cache i dati in memoria in modo aggressivo. Dopo questo periodo iniziale di ramp-up, è comune e si prevede di visualizzare le colonne avg_memory_usage_percent e avg_instance_memory_percent in sys.dm_db_resource_stats e la metrica sql_instance_memory_percent di Monitoraggio di Azure deve essere vicina al 100%, in particolare per i database che non sono inattive e non sono completamente in memoria.
Nota
La metrica sql_instance_memory_percent riflette il consumo totale di memoria del motore di database. Questa metrica potrebbe non raggiungere il 100% anche quando i carichi di lavoro ad alta intensità sono in esecuzione. Ciò è dovuto al fatto che una piccola parte della memoria disponibile è riservata alle allocazioni di memoria critiche diverse dalla cache dei dati, ad esempio stack di thread e moduli eseguibili.
Oltre alla cache dei dati, la memoria viene usata in altri componenti del motore di database. Se occorre più memoria, ma tutta la memoria disponibile è stata usata dalla cache dei dati, il motore di database riduce le dimensioni della cache dei dati per rendere disponibile la memoria per altri componenti e aumenta dinamicamente la cache dei dati quando altri componenti rilasciano la memoria.
In rari casi, un carico di lavoro abbastanza impegnativo può causare una condizione di memoria insufficiente, dando origine a errori di memoria insufficiente. Gli errori di memoria insufficiente possono verificarsi a qualsiasi livello di utilizzo della memoria compreso tra 0% e 100%. È più probabile che gli errori di memoria insufficiente si verifichino in dimensioni di calcolo più piccole con limiti di memoria proporzionalmente inferiori e/o con carichi di lavoro che usano più memoria per l'elaborazione delle query, ad esempio nei pool elastici densi.
Se si verificano errori di memoria insufficiente, le opzioni di mitigazione includono:
- Esaminare i dettagli della condizione OOM in sys.dm_os_out_of_memory_events.
- Aumento del livello di servizio o delle dimensioni di calcolo del database o del pool elastico. Vedere Ridimensionare le risorse del database singolo e Ridimensionare le risorse del pool elastico.
- Ottimizzare le query e le impostazioni di configurazione. Le soluzioni comuni sono descritte nella tabella seguente.
| Soluzione | Descrizione |
|---|---|
| Ridurre le dimensioni delle concessioni di memoria | Per altre informazioni sulle concessioni di memoria, vedere il post di blog Informazioni sulla concessione di memoria di SQL Server. Una soluzione comune per evitare concessioni di memoria eccessivamente elevate consiste nel mantenere aggiornate statistiche. Ciò comporta stime più accurate dell'utilizzo di memoria da parte del motore di query, al fine di evitare concessioni di memoria grandi. Per impostazione predefinita, nei database che usano il livello di compatibilità 140 e superiori, il motore di database può modificare automaticamente le dimensioni delle concessioni di memoria usando il feedback delle concessioni di memoria in modalità batch. Analogamente, nei database che usano il livello di compatibilità 150 e superiori, il motore di database usa anche il feedback delle concessioni di memoria in modalità riga per query in modalità riga più comuni. Questa funzionalità predefinita consente di evitare errori di memoria insufficiente a causa di concessioni di memoria grandi. |
| Ridurre le dimensioni della cache dei piani di query | Il motore di database memorizza nella cache i piani di query in memoria, per evitare di compilare un piano di query per ogni esecuzione di query. Per evitare il bloat della cache del piano di query causato da piani di memorizzazione nella cache usati una sola volta, assicurarsi di usare query con parametri e valutare la possibilità di abilitare la configurazione con ambito database OPTIMIZE_FOR_AD_HOC_WORKLOADS. |
| Ridurre le dimensioni della memoria di blocco | Il motore di database usa la memoria per i blocchi. Quando possibile, evitare transazioni di grandi dimensioni che possono acquisire un numero elevato di blocchi e determinare un utilizzo elevato della memoria di blocco. |
Utilizzo delle risorse per carichi di lavoro utente e processi interni
database SQL di Azure richiede risorse di calcolo per implementare funzionalità di base del servizio, ad esempio disponibilità elevata e ripristino di emergenza, backup e ripristino del database, monitoraggio, Query Store, Ottimizzazione automatica e così via. Il sistema riserva una parte limitata delle risorse complessive per questi processi interni usando meccanismi di governance delle risorse, rendendo disponibile il resto delle risorse per i carichi di lavoro degli utenti. In alcuni casi in cui i processi interni non usano risorse di calcolo, il sistema li rende disponibili per i carichi di lavoro degli utenti.
L'utilizzo totale di CPU e memoria da parte dei carichi di lavoro degli utenti e dei processi interni viene segnalato nelle viste sys.dm_db_resource_stats e sys.resource_stats nelle colonne avg_instance_cpu_percent e avg_instance_memory_percent. Questi dati vengono anche segnalati tramite le metriche di Monitoraggio di Azure sql_instance_cpu_percent e sql_instance_memory_percent per database singoli e pool elastici a livello di pool.
Nota
Le metriche di Monitoraggio di Azure sql_instance_cpu_percent e sql_instance_memory_percent sono disponibili a partire da luglio 2023. Sono completamente equivalenti alle metriche sqlserver_process_core_percent e sqlserver_process_memory_percent disponibili in precedenza, rispettivamente. Le ultime due metriche rimangono disponibili, ma verranno rimosse in futuro. Per evitare un'interruzione del monitoraggio del database, non usare le metriche meno recenti.
Queste metriche non sono disponibili per i database che usano obiettivi di servizio Basic, S1 e S2. Gli stessi dati sono disponibili nelle seguenti viste a gestione dinamica.
L'utilizzo di CPU e memoria da parte dei carichi di lavoro degli utenti in ogni database viene segnalato nelle viste sys.dm_db_resource_stats e sys.resource_stats, nelle colonne avg_cpu_percent e avg_memory_usage_percent. Per i pool elastici, l'utilizzo delle risorse a livello di pool viene segnalato nella vista sys.elastic_pool_resource_stats (per gli scenari di creazione di report cronologici) e in sys.dm_elastic_pool_resource_stats per il monitoraggio in tempo reale. L'utilizzo della CPU del carico di lavoro utente viene segnalato anche tramite la metrica di monitoraggio di Azure cpu_percent per database singoli e pool elastici a livello di pool.
Nelle visualizzazioni sys.dm_resource_governor_resource_pools_history_ex e sys.dm_resource_governor_workload_groups_history_ex viene segnalata una suddivisione più dettagliata del consumo di risorse recenti da parte dei carichi di lavoro degli utenti e dei processi interni. Per informazioni dettagliate sui pool di risorse e sui gruppi di carico di lavoro a cui si fa riferimento in queste viste, vedere Governance delle risorse. Queste visualizzazioni segnalano l'utilizzo delle risorse da parte dei carichi di lavoro utente e processi interni specifici nei pool di risorse e nei gruppi di carico di lavoro associati.
Suggerimento
Quando si esegue il monitoraggio o la risoluzione dei problemi relativi alle prestazioni del carico di lavoro, è importante considerare sia l'utilizzo della CPU dell'utente (avg_cpu_percent, cpu_percent) sia il consumo totale della CPU da parte dei carichi di lavoro degli utenti e dei processi interni (avg_instance_cpu_percent,sql_instance_cpu_percent). Le prestazioni potrebbero essere notevolmente influenzate se una di queste metriche si trova nell'intervallo del 70-100%.
L'utilizzo della CPU utente viene definito come percentuale rispetto al limite di CPU del carico di lavoro dell'utente in ogni obiettivo di servizio. Analogamente, il consumo totale della CPU viene definito come percentuale verso il limite di CPU per tutti i carichi di lavoro. Poiché i due limiti sono diversi, l'utente e il consumo totale della CPU vengono misurati su scale diverse e non sono direttamente confrontabili tra loro.
Se l'utilizzo della CPU dell'utente raggiunge il 100%, significa che il carico di lavoro dell'utente usa completamente la capacità della CPU disponibile nell'obiettivo di servizio selezionato, anche se il consumo totale della CPU rimane inferiore al 100%.
Quando il consumo totale della CPU raggiunge l'intervallo del 70-100%, è possibile visualizzare l'aumento della velocità effettiva del carico di lavoro utente e la latenza delle query, anche se l'utilizzo della CPU dell'utente rimane significativamente inferiore al 100%. Ciò è più probabile quando si usano obiettivi di servizio più piccoli con un'allocazione moderata di risorse di calcolo, ma carichi di lavoro utente relativamente intensi, ad esempio in pool elastici densi. Ciò può verificarsi anche con obiettivi di servizio più piccoli quando i processi interni richiedono temporaneamente più risorse, ad esempio quando si crea una nuova replica del database o si esegue il backup del database.
Analogamente, quando consumo di CPU utente raggiunge l'intervallo di 70-100%, la velocità effettiva del carico di lavoro utente aumenta e la latenza delle query aumenta, anche se consumo totale di CPU è ben al di sotto del limite.
Quando l'utilizzo della CPU dell'utente o il consumo totale della CPU è elevato, le opzioni di mitigazione sono le stesse indicate nella sezione CPU di calcolo e includono l'aumento dell'obiettivo di servizio e/o l'ottimizzazione del carico di lavoro dell'utente.
Nota
Anche in un database completamente inattiva o in un pool elastico, il consumo totale della CPU non è mai a zero a causa delle attività del motore di database in background. Può variare in un'ampia gamma a seconda delle attività in background, delle dimensioni di calcolo e del carico di lavoro utente precedente.
Governance delle risorse
Per applicare i limiti delle risorse, database SQL di Azure usa un'implementazione di governance delle risorse basata su SQL Server Resource Governor, modificata ed estesa per l'esecuzione nel cloud. In database SQL, più pool di risorse e gruppi di carico di lavoro, con limiti di risorse impostati sia a livello di pool che di gruppo, forniscono un database distribuito come servizio bilanciato. I carichi di lavoro utente e i carichi di lavoro interni vengono classificati in pool di risorse e gruppi di carico di lavoro separati. Il carico di lavoro dell'utente nelle repliche primarie e secondarie leggibili, incluse le repliche geografiche, viene classificato nel pool di risorse SloSharedPool1 e nel gruppo di carico di lavoro UserPrimaryGroup.DBId[N], dove [N] sta per il valore ID del database. Sono inoltre disponibili più pool di risorse e gruppi di carico di lavoro per vari carichi di lavoro interni.
Oltre a usare Resource Governor per gestire le risorse all'interno del motore di database, database SQL di Azure usa anche oggetti processo di Windows per la governance delle risorse a livello di processo e Gestione risorse file server di Windows per la gestione delle quote di archiviazione.
Database SQL di Azure governance delle risorse è gerarchica. Dall'alto verso il basso, i limiti vengono applicati a livello di sistema operativo e a livello di volume di archiviazione usando i meccanismi di governance delle risorse del sistema operativo e Resource Governor, quindi a livello di pool di risorse usando Resource Governor e quindi a livello di gruppo del carico di lavoro usando Resource Governor. I limiti di governance delle risorse applicati per il database corrente o il pool elastico vengono segnalati nella vista sys.dm_user_db_resource_governance.
Governance di I/O dei dati
La governance di I/O dei dati è un processo in database SQL di Azure usato per limitare le operazioni di I/O fisiche in lettura e scrittura rispetto ai file di dati di un database. I limiti delle operazioni di I/O al secondo vengono impostati per ogni livello di servizio per ridurre al minimo l'effetto "vicino rumoroso", per garantire l'equità di assegnazione delle risorse in un servizio multi-tenant e per rimanere entro le funzionalità dell'hardware e dell'archiviazione sottostanti.
Per i database singoli, i limiti dei gruppi di carico di lavoro vengono applicati a tutte le operazioni di I/O di archiviazione sul database. Per i pool elastici, i limiti dei gruppi di carico di lavoro si applicano a ogni database nel pool. Inoltre, il limite del pool di risorse si applica anche all'I/O cumulativo del pool elastico. In tempdb, le operazioni di I/O sono soggette ai limiti dei gruppi di carico di lavoro, ad eccezione del livello di servizio Basic, Standard e Utilizzo generico, in cui si applicano limiti di I/O più elevati tempdb. In generale, i limiti del pool di risorse potrebbero non essere raggiungibili dal carico di lavoro rispetto a un database (singolo o in pool), perché i limiti dei gruppi di carico di lavoro sono inferiori ai limiti del pool di risorse e limitano prima le operazioni di I/O al secondo/o la velocità effettiva. Tuttavia, i limiti del pool possono essere raggiunti dal carico di lavoro combinato rispetto a più database nello stesso pool.
Ad esempio, se una query genera 1000 operazioni di I/O al secondo senza governance delle risorse di I/O, ma il limite massimo di operazioni di I/O al secondo del gruppo di carico di lavoro è impostato su 900 operazioni di I/O al secondo, la query non può generare più di 900 operazioni di I/O al secondo. Tuttavia, se il limite massimo di operazioni di I/O al secondo del pool di risorse è impostato su 1500 operazioni di I/O e il totale di I/O di tutti i gruppi di carico di lavoro associati al pool di risorse supera 1500 operazioni di I/O al secondo, l'I/O della stessa query potrebbe essere ridotta al di sotto del limite di 900 operazioni di I/O al secondo del gruppo di lavoro.
I valori massimi di operazioni di I/O al secondo e velocità effettiva restituiti dalla vista sys.dm_user_db_resource_governance fungono da limiti/limiti, non come garanzie. Inoltre, la governance delle risorse non garantisce una latenza di archiviazione specifica. La latenza, le operazioni di I/O al secondo e la velocità effettiva ottimali per un determinato carico di lavoro utente dipendono non solo dai limiti di governance delle risorse di I/O, ma anche dalla combinazione di dimensioni di I/O usate e dalle funzionalità dell'archiviazione sottostante. Database SQL usa operazioni di I/O che variano in dimensioni comprese tra 512 byte e 4 MB. Ai fini dell'applicazione dei limiti delle operazioni di I/O al secondo, ogni I/O viene tenuto conto indipendentemente dalle dimensioni, ad eccezione dei database con file di dati in Archiviazione di Azure. In tal caso, le operazioni di I/O superiori a 256 KB vengono considerate come più operazioni di I/O da 256 KB per allinearsi alla contabilità di I/O Archiviazione di Azure.
Per i database Basic, Standard e Per utilizzo generico, che usano file di dati in Archiviazione di Azure, il valore primary_group_max_io potrebbe non essere raggiungibile se un database non dispone di file di dati sufficienti per fornire in modo cumulativo questo numero di operazioni di I/O al secondo o se i dati non vengono distribuiti uniformemente tra i file o se il livello di prestazioni dei BLOB sottostanti limita le operazioni di I/O al secondo/o la velocità effettiva al di sotto dei limiti di governance delle risorse. Analogamente, con operazioni di I/O di log di piccole dimensioni generate da commit frequenti di transazioni, il valore primary_max_log_rate potrebbe non essere raggiungibile da un carico di lavoro a causa del limite di operazioni di I/O al secondo sul BLOB di Archiviazione di Azure sottostante. Per i database che usano Azure Archiviazione Premium, database SQL di Azure usa BLOB di archiviazione sufficientemente grandi per ottenere le operazioni di I/O al secondo/o la velocità effettiva necessarie, indipendentemente dalle dimensioni del database. Per i database di dimensioni maggiori, vengono creati più file di dati per aumentare la capacità totale di IOPS/velocità effettiva.
I valori di utilizzo delle risorse, ad esempio avg_data_io_percent e avg_log_write_percent, segnalati nelle viste sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats e sys.elastic_pool_resource_stats , vengono calcolati come percentuali dei limiti massimi di governance delle risorse. Pertanto, quando i fattori diversi dal limite di governance delle risorse limitano le operazioni di I/O al secondo/o la velocità effettiva, è possibile visualizzare l'appiattimento delle operazioni di I/O al secondo e la velocità effettiva aumentano man mano che il carico di lavoro aumenta, anche se l'utilizzo delle risorse segnalato rimane inferiore al 100%.
Per monitorare le operazioni di I/O al secondo, velocità effettiva e latenza di lettura e scrittura per ogni file di database, usare la funzione sys.dm_io_virtual_file_stats(). Questa funzione espone tutte le operazioni di I/O sul database, incluse le operazioni di I/O in background non considerate verso avg_data_io_percent, ma usa operazioni di I/O al secondo e velocità effettiva dell'archiviazione sottostante e può influire sulla latenza di archiviazione osservata. La funzione segnala una latenza aggiuntiva che può essere introdotta dalla governance delle risorse di I/O per letture e scritture, rispettivamente nelle colonne io_stall_queued_read_ms e io_stall_queued_write_ms.
Governance della frequenza dei log delle transazioni
La governance della frequenza dei log delle transazioni è un processo in database SQL di Azure usato per limitare tassi di inserimento elevati per carichi di lavoro, ad esempio inserimento bulk, edizione SELECT INTO e compilazioni di indici. Questi limiti vengono rilevati e applicati a livello di sottosecondo alla velocità di generazione dei record del log, limitando la velocità effettiva indipendentemente dal numero di operazioni di I/O che possono essere rilasciate nei file di dati. Le frequenze di generazione del log delle transazioni attualmente aumentano in modo lineare fino a un punto dipendente dall'hardware e dipendente dal livello di servizio.
Le tariffe dei log vengono impostate in modo che possano essere ottenute e sostenute in vari scenari, mentre il sistema complessivo può mantenere le funzionalità con un impatto ridotto al minimo sul carico dell'utente. La governance della frequenza dei log garantisce che i backup del log delle transazioni rimangano entro i contratti di servizio di recuperabilità pubblicati. Questa governance impedisce inoltre un backlog eccessivo nelle repliche secondarie che altrimenti potrebbero causare tempi di inattività più lunghi del previsto durante i failover.
Le operazioni di I/O fisiche effettive per i file registro transazioni non sono regolate o limitate. Quando vengono generati record di log, ogni operazione viene valutata e valutata per determinare se deve essere ritardata per mantenere una velocità massima di log desiderata (MB/sec al secondo). I ritardi non vengono aggiunti quando i record di log vengono scaricati nell'archiviazione, ma la governance della frequenza dei log viene applicata durante la generazione della frequenza dei log stessa.
Le velocità di generazione dei log effettive imposte in fase di esecuzione sono influenzate anche dai meccanismi di feedback, riducendo temporaneamente i tassi di log consentiti in modo che il sistema possa stabilizzarsi. La gestione dello spazio dei file di log, evitando l'esaurimento delle condizioni di spazio dei log e i meccanismi di replica dei dati possono ridurre temporaneamente i limiti complessivi del sistema.
La modellazione del traffico di Log Rate Governor viene rilevata tramite i tipi di attesa seguenti (esposti nelle viste sys.dm_exec_requests e sys.dm_os_wait_stats):
| wait_type | Note |
|---|---|
LOG_RATE_GOVERNOR |
Limitazione del database |
POOL_LOG_RATE_GOVERNOR |
Limitazione del pool |
INSTANCE_LOG_RATE_GOVERNOR |
Limitazione a livello di istanza |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Controllo dei commenti e suggerimenti, replica fisica del gruppo di disponibilità in Premium/Business Critical non mantenendo |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Controllo dei commenti e suggerimenti, limitazione delle frequenze per evitare una condizione di spazio del log insufficiente |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Controllo del feedback della replica geografica, limitazione della frequenza dei log per evitare una latenza elevata dei dati e un'indisponibilità di repliche geografiche secondarie |
Quando si verifica un limite di frequenza dei log che ostacola la scalabilità desiderata, prendere in considerazione le opzioni seguenti:
- Aumentare fino a un livello di servizio superiore per ottenere la frequenza massima di log di un livello di servizio o passare a un livello di servizio diverso.
- Per l'hardware ottimizzato per la memoria premium e della serie Premium, il livello di servizio con provisioning hyperscale offre 150 frequenza di log MiB/s per database e 150 MiB/s per pool elastico.
- Per altre serie hardware, il livello di servizio Hyperscale offre 100 frequenza di log MiB/s per database e 125 MiB/s per pool elastico.
- Se i dati in fase di caricamento sono temporanei, ad esempio dati di staging in un processo ETL, è possibile caricarli in
tempdb, per cui è prevista la registrazione minima. - Per gli scenari analitici, eseguire il caricamento in una tabella columnstore in cluster o una tabella con indici che usano la compressione dei dati. Questo approccio consente di ridurre la frequenza di registrazione necessaria. Questa tecnica aumenta l'utilizzo della CPU ed è applicabile solo a set di dati che traggono vantaggio da indici columnstore in cluster o dalla compressione dei dati.
Governance dello spazio di archiviazione
Nei livelli di servizio Premium e Business Critical, i dati dei clienti, inclusi i file di dati, i file di log delle transazioni e i file tempdb, vengono archiviati nell'archiviazione SSD locale del computer che ospita il database o il pool elastico. L'archiviazione SSD locale offre operazioni di I/O al secondo e velocità effettiva elevate e bassa latenza di I/O. Oltre ai dati dei clienti, l'archiviazione locale viene usata per il sistema operativo, il software di gestione, i dati di monitoraggio e i log e altri file necessari per il funzionamento del sistema.
La dimensione dell'archiviazione locale è limitata e dipende dalle funzionalità hardware, che determinano il limite massimo di archiviazione locale o l'archiviazione locale messa da parte per i dati dei clienti. Questo limite è impostato per ottimizzare l'archiviazione dei dati dei clienti, garantendo al tempo stesso operazioni di sistema sicure e affidabili. Per trovare il valore massimo di archiviazione locale per ogni obiettivo di servizio, vedere la documentazione relativa ai limiti delle risorse per database singoli e pool elastici.
È anche possibile trovare questo valore e la quantità di archiviazione locale attualmente usata da un determinato database o pool elastico, usando la query seguente:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Colonna | Descrizione |
|---|---|
server_name |
Nome server logico |
database_name |
Nome database |
slo_name |
Nome dell'obiettivo del servizio, inclusa la generazione dell'hardware |
user_data_directory_space_quota_mb |
Spazio di archiviazione locale massimo, in MB |
user_data_directory_space_usage_mb |
Utilizzo corrente dell'archiviazione locale per file di dati, file di log delle transazioni e file tempdb, in MB. Aggiornato ogni cinque minuti. |
Questa query deve essere eseguita nel database dell’utente, non nel database master. Per i pool elastici, la query può essere eseguita in qualsiasi database nel pool. I valori segnalati si applicano all'intero pool.
Importante
Nei livelli di servizio Premium e Business Critical, se il carico di lavoro tenta di aumentare il consumo combinato di archiviazione locale per file di dati, file di log delle transazioni e file tempdb oltre il limite massimo di archiviazione locale, si verificherà un errore di spazio insufficiente. Ciò si verifica anche se lo spazio usato in un file di database non ha raggiunto le dimensioni massime del file.
L'archiviazione SSD locale viene usata anche dai database nei livelli di servizio diversi da Premium e Business Critical per il database tempdb e la cache RBPEX hyperscale. Man mano che i database vengono creati, eliminati e aumentati o diminuiscono le dimensioni, il consumo totale di risorse di archiviazione locali in un computer varia nel tempo. Se il sistema rileva che l'archiviazione locale disponibile in un computer è bassa e un database o un pool elastico rischia di esaurire lo spazio, il database o il pool elastico viene spostato in un computer diverso con spazio di archiviazione locale sufficiente disponibile.
Questo spostamento avviene in modo online, in modo analogo a un'operazione di ridimensionamento del database e ha un impatto simile, incluso un failover breve (secondi) alla fine dell'operazione. Questo failover termina le connessioni aperte ed esegue il rollback delle transazioni, che potrebbero influire sulle applicazioni che usano il database in quel momento.
Poiché tutti i dati vengono copiati in volumi di archiviazione locali in computer diversi, lo spostamento di database di dimensioni maggiori nei livelli di servizio Premium e Business Critical può richiedere una notevole quantità di tempo. Durante tale periodo, se il consumo di spazio locale da un database o da un pool elastico o dal database tempdb aumenta rapidamente, il rischio di esaurimento dello spazio aumenta. Il sistema avvia lo spostamento del database in modo bilanciato per ridurre al minimo gli errori di spazio insufficiente evitando failover non necessari.
Dimensioni tempdb
I limiti delle dimensioni per tempdb in database SQL di Azure dipendono dal modello di acquisto e distribuzione.
Per altre informazioni, vedere i limiti delle dimensioni di tempdb per:
- Modello di acquisto vCore: database singoli e database in pool
- Modello di acquisto DTU: database singoli, database in pool.
Hardware precedentemente disponibile
Questa sezione include informazioni dettagliate sull'hardware disponibile in precedenza.
- L'hardware Gen4 è stato ritirato e non è disponibile per il provisioning, l'upscaling o il downscaling. Per una maggiore scalabilità di vCore e archiviazione, una rete accelerata, migliori prestazioni delle operazioni di I/O e una latenza minima, esegui la migrazione del database a una generazione di hardware supportata. Per altre informazioni, vedi Supporto terminato per l'hardware Gen 4 nel database SQL di Azure.
È possibile usare Azure Resource Graph Explorer per identificare tutte le risorse database SQL di Azure che attualmente usano hardware Gen4 oppure controllare l'hardware usato dalle risorse per un server logico specifico nel portale di Azure.
Per visualizzare i risultati in Azure Resource Graph Explorer, è necessario disporre almeno delle autorizzazioni read per l'oggetto o il gruppo di oggetti di Azure.
Per usare Resource Graph Explorer per identificare le risorse SQL di Azure che usano ancora hardware Gen4, seguire questa procedura:
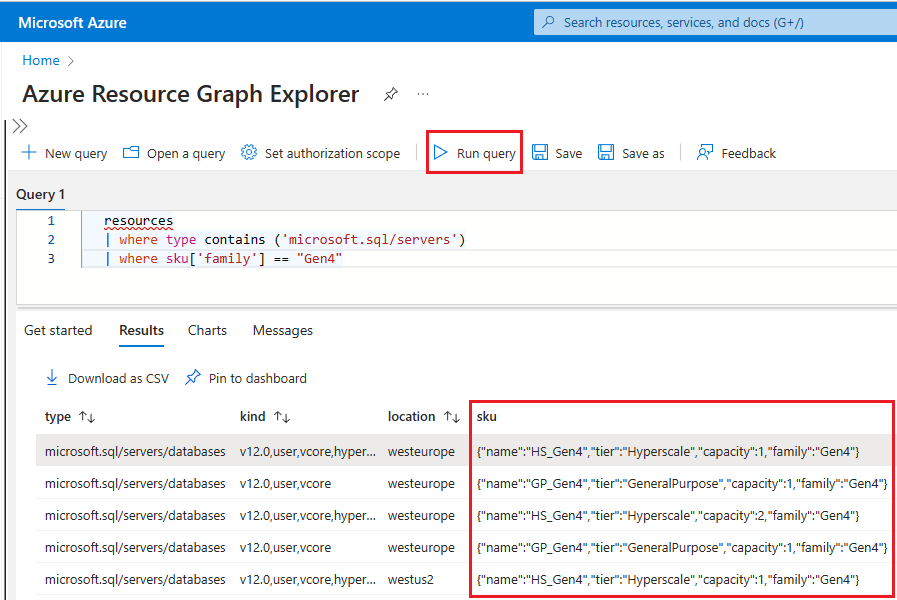
Vai al portale di Azure.
Cercare
Resource graphnella casella di ricerca e scegliere il servizio Resource Graph Explorer nei risultati della ricerca.Nella finestra di query, immettere la query seguente e quindi selezionare Esegui query:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"Il riquadro Risultati visualizza tutte le risorse attualmente distribuite in Azure che usano l'hardware Gen4.
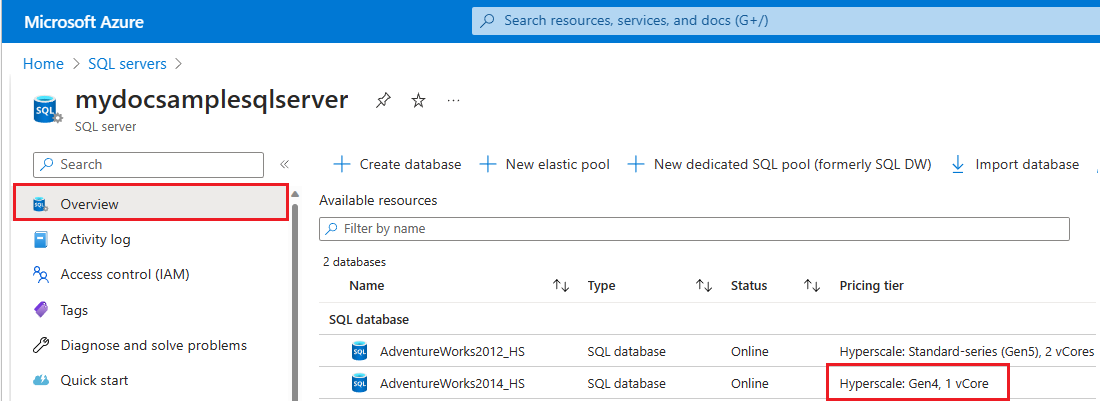
Per controllare l'hardware usato dalle risorse per un server logico specifico in Azure, seguire questa procedura:
- Vai al portale di Azure.
- Cercare
SQL serversnella casella di ricerca e scegliere SQL Server dai risultati della ricerca per aprire la pagina SQL Server e visualizzare tutti i server per le sottoscrizioni scelte. - Selezionare il server di interesse per aprire la pagina Panoramica per il server.
- Scorrere verso il basso fino alle risorse disponibili e controllare la colonna Piano tariffario per le risorse che usano hardware gen4.
Per eseguire la migrazione delle risorse all'hardware della serie standard, vedere Modificare l'hardware.
Contenuto correlato
- Per informazioni sui limiti generici di Azure, vedere Sottoscrizione di Azure e limiti, quote e vincoli dei servizi.
- Per informazioni su DTU ed eDTU, vedere DTU ed eDTU.
- Per informazioni sui limiti delle dimensioni di
tempdb, vedere Database vCore singoli, database vCore in pool, database DTU singoli e database DTU in pool.