Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività Copy nelle pipeline di Azure Data Factory e Synapse Analytics per copiare i dati da un database SAP HANA. Si basa sull'articolo di panoramica dell'attività di copia che presenta una panoramica generale sull'attività di copia.
Suggerimento
Per informazioni sul supporto generale sullo scenario di integrazione dei dati SAP, vedere il white paper sull'integrazione dei dati SAP con sezioni di introduzione, confronto e istruzioni dettagliate su ogni connettore SAP.
Funzionalità supportate
Questo connettore SAP HANA è supportato per le attività seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (origine/sink) | 1 |
| Attività Lookup | 1 |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini/sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
In particolare, il connettore SAP HANA supporta:
- La copia di dati da qualsiasi versione del database SAP HANA.
- La copia di dati da modelli di informazioni HANA (ad esempio, dalle viste di analisi e calcolo) e da tabelle Riga/Colonna.
- La copia di dati usando l'autenticazione Di base o Windows.
- Copia parallela da un'origine SAP HANA. Per informazioni dettagliate, vedere la sezione Copia parallela da SAP HANA.
Suggerimento
Per copiare dati in un archivio dati SAP HANA, usare il connettore ODBC generico. Per i dettagli, vedere la sezione Sink SAP HANA. Si noti che i servizi collegati per i connettori SAP HANA e ODBC sono associati a tipi diversi e pertanto non possono essere riusati.
Prerequisiti
Per usare questo connettore SAP HANA, è necessario:
- Configurare un runtime di integrazione self-hosted. Per i dettagli, vedere l'articolo Runtime di integrazione self-hosted.
- Installare il driver ODBC di SAP HANA nel computer del runtime di integrazione. È possibile scaricare il driver ODBC di SAP HANA dall'area per il download di software SAP. Per cercare il driver, usare la parola chiave SAP HANA CLIENT for Windows.
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
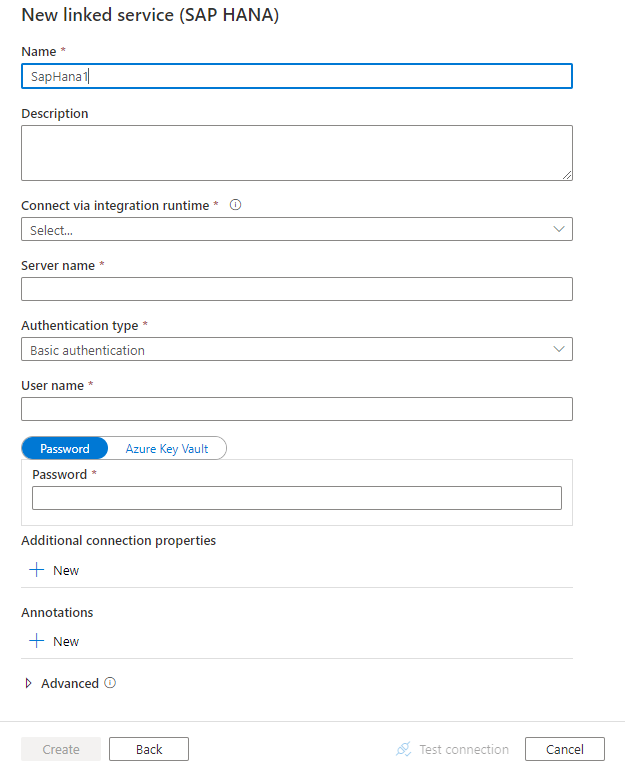
Creare un servizio collegato a SAP HANA usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a SAP HANA nell'interfaccia utente del portale di Azure.
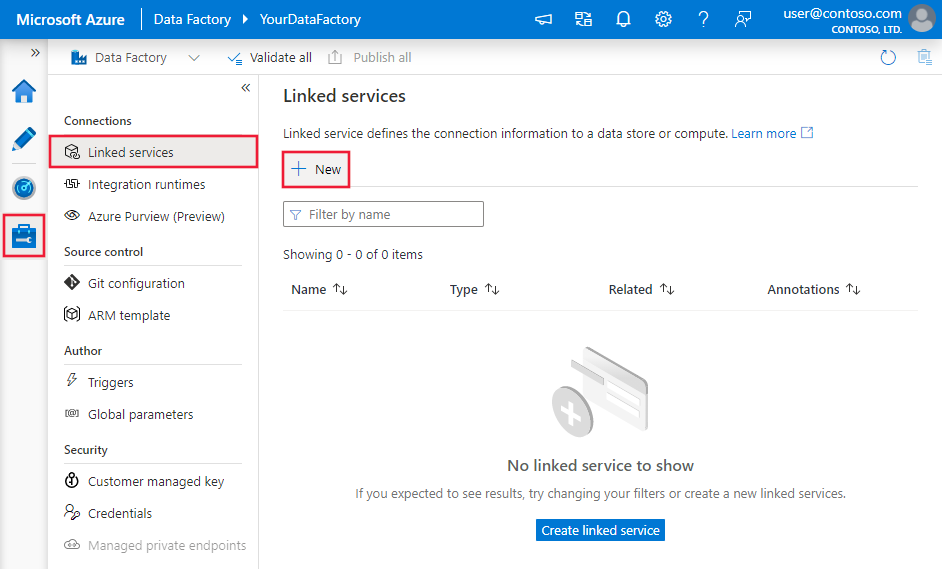
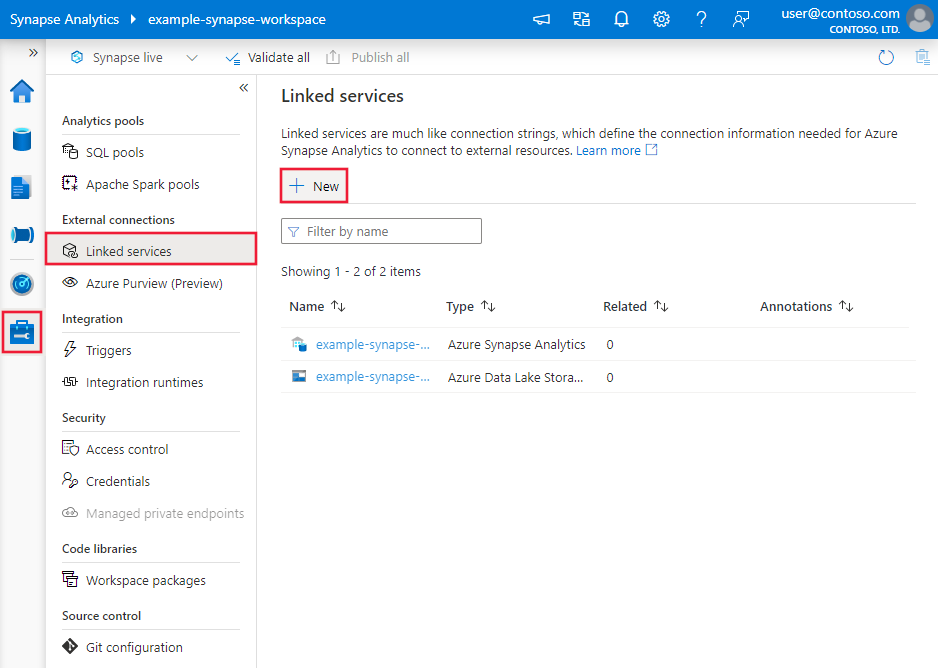
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare SAP e selezionare il connettore SAP HANA.

Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà che vengono usate per definire entità di Data Factory specifiche per il connettore SAP HANA.
Proprietà del servizio collegato
Per il servizio collegato di SAP HANA sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su: SapHana | Sì |
| connectionString | Specificare le informazioni necessarie per connettersi a SAP HANA usando l'autenticazione di base o l'autenticazione di Windows. Vedere gli esempi seguenti. Nella stringa di connessione, server/porta è obbligatorio (la porta predefinita è 30015) e il nome utente e la password sono obbligatori quando si usa l'autenticazione di base. Per altre impostazioni avanzate, vedere Proprietà di connessione ODBC di SAP HANA È anche possibile inserire la password in Azure Key Vault ed eseguire il pull dei dati della configurazione della password all'esterno della stringa di connessione. Vedere l'articolo Archiviare le credenziali in Azure Key Vault con altri dettagli. |
Sì |
| userName | Specificare il nome utente quando si usa l'autenticazione di Windows. Esempio: user@domain.com |
No |
| password | Specifica la password per l'account utente. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. | No |
| connectVia | Il runtime di integrazione da usare per la connessione all'archivio dati. È necessario un runtime di integrazione self-hosted come indicato in Prerequisiti. | Sì |
Esempio: usare l'autenticazione di base
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: usare l'autenticazione di Windows
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Il servizio collegato SAP HANA con il payload seguente è ancora supportato senza modifiche, ma è consigliato l'uso del nuovo per il futuro.
Esempio:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione di set di dati, vedere l'articolo sui set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati SAP HANA.
Per copiare dati da SAP HANA, sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su: SapHanaTable | Sì |
| schema | Nome dello schema nel database SAP HANA. | No (se nell'origine dell'attività è specificato "query") |
| table | Nome della tabella nel database SAP HANA. | No (se nell'origine dell'attività è specificato "query") |
Esempio:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
Il set di dati tipizzato RelationalTable è ancora supportato senza modifiche, ma è consigliato l'uso del nuovo per il futuro.
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine SAP HANA.
SAP HANA come origine
Suggerimento
Per inserire i dati da SAP HANA in modo efficiente usando il partizionamento dei dati, vedere la sezione Copia parallela da SAP HANA.
Per copiare i dati da SAP HANA, nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su: SapHanaSource | Sì |
| query | Specifica la query SQL che consente di leggere i dati dall'istanza di SAP HANA. | Sì |
| partitionOptions | Specifica le opzioni di partizionamento dei dati usate per inserire dati dall'istanza gestita di SAP HANA. Altre informazioni sono disponibili nella sezione Copia parallela da SAP HANA. I valori consentiti sono: None (predefinito), PhysicalPartitionsOfTable e SapHanaDynamicRange. Altre informazioni sono disponibili nella sezione Copia parallela da SAP HANA. PhysicalPartitionsOfTable può essere usato solo quando si copiano dati da una tabella ma non si esegue una query. Quando un'opzione di partizione è abilitata (ovvero, non è None), il grado di parallelismo per il caricamento simultaneo di dati dall'istanza gestita di SAP HANA è controllato dall'impostazione parallelCopies sull'attività di copia. |
False |
| partitionSettings | Specifica il gruppo di impostazioni per il partizionamento dei dati. Si applica quando l'opzione di partizione è SapHanaDynamicRange. |
False |
| partitionColumnName | Specificare il nome della colonna di origine che verrà usata dalla partizione per la copia parallela. Se non specificato, la chiave primaria della tabella viene rilevata automaticamente e usata come colonna di partizione. Si applica quando l'opzione di partizione è SapHanaDynamicRange. Se si usa una query per recuperare i dati di origine, associare ?AdfHanaDynamicRangePartitionCondition nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da SAP HANA. |
Sì quando si usa la partizione SapHanaDynamicRange. |
| packetSize | Specifica le dimensioni dei pacchetti di rete (in Kilobyte) per suddividere i dati in più blocchi. Se si dispone di grandi quantità di dati da copiare, nella maggior parte dei casi l'aumento delle dimensioni dei pacchetti può aumentare la velocità di lettura da SAP HANA. Quando si modificano le dimensioni del pacchetto, è consigliabile eseguire test delle prestazioni. | No. Il valore predefinito è 2048 (2MB). |
Esempio:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
L'origine della copia tipizzata RelationalSource è ancora supportata senza modifiche, ma è consigliato l'uso della nuova per il futuro.
Copia parallela dall'istanza gestita di SAP HANA
Il connettore SAP HANA fornisce il partizionamento dei dati predefinito per copiare dati da SAP HANA in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività di copia.
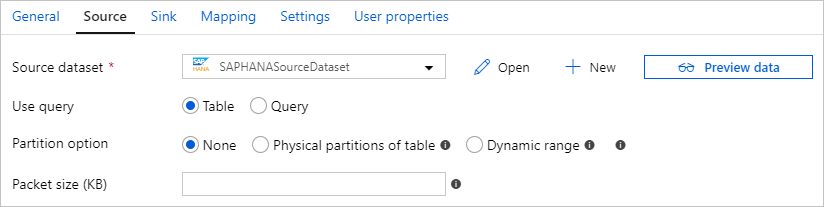
Quando si abilita la copia partizionata, il servizio esegue query parallele sull'origine SAP HANA per recuperare i dati in base alle partizioni. Il grado di parallelismo è controllato dall'impostazione parallelCopies sull'attività di copia. Se, ad esempio, si imposta parallelCopies su quattro, il servizi genera ed esegue simultaneamente quattro query in base all'opzione partizione e alle impostazioni specificate, e ogni query recupera una porzione di dati dal database dell'Istanza gestita di database SAP HANA.
È consigliabile abilitare la copia parallela con partizionamento dei dati, soprattutto quando si inseriscono grandi quantità di dati dall'istanza gestita di SAP HANA. Di seguito sono riportate le configurazioni consigliate per i diversi scenari. Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come file multipli (specificare solo il nome della cartella); in tal caso, le prestazioni risultano migliori rispetto alla scrittura in un singolo file.
| Scenario | Impostazioni consigliate |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni. | Opzione di partizione: partizioni fisiche della tabella. Durante l'esecuzione, il servizio rileva automaticamente il tipo di partizione fisica della tabella SAP HANA specificata e sceglie la strategia di partizione corrispondente: - Partizionamento per intervalli: ottenere la colonna di partizione e gli intervalli di partizione definiti per la tabella, quindi copiare i dati in base all'intervallo. - Partizionamento hash: usare la chiave di partizione hash come colonna di partizione, quindi partizionare e copiare i dati in base agli intervalli calcolati dal servizio. - Partizionamento Round Robin o Nessuna partizione: usare la chiave primaria come colonna di partizione, quindi partizionare e copiare i dati in base agli intervalli calcolati dal servizio. |
| Caricare grandi quantità di dati tramite una query personalizzata. | Opzione di partizione: partizione a intervalli dinamici. Query: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>.Colonna di partizione: specificare la colonna usata per applicare la partizione dell'intervallo dinamico. Durante l'esecuzione, il servizio calcola innanzitutto gli intervalli di valori della colonna di partizione specificata, distribuendo uniformemente le righe in un numero di contenitori in base al numero di valori distinti della colonna di partizione nell'impostazione di copia parallela, quindi sostituisce ?AdfHanaDynamicRangePartitionCondition con il filtro dell'intervallo di valori della colonna di partizione per ogni partizione e invia a SAP HANA.Se si desidera usare più colonne come colonna di partizione, è possibile concatenare i valori di ogni colonna come una colonna nella query e specificarla come colonna di partizione, ad esempio SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition. |
Esempio: eseguire una query con partizione fisica di una tabella
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Esempio: query con partizione a intervalli dinamici
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
Mapping dei tipi di dati per SAP HANA
Quando si copiano dati da SAP HANA, vengono usati i mapping seguenti tra i tipi di dati di SAP HANA e i tipi di dati provvisori usati internamente al servizio. Vedere Mapping dello schema e del tipo di dati per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink.
| Tipo di dati di SAP HANA | Tipo di dati del servizio provvisorio |
|---|---|
| ALPHANUM | String |
| bigint | Int64 |
| BINARY | Byte[] |
| BINTEXT | String |
| BLOB | Byte[] |
| BOOL | Byte |
| CLOB | String |
| DATE | Data/Ora |
| DECIMAL | Decimale |
| DOUBLE | Double |
| FLOAT | Double |
| INTEGER | Int32 |
| NCLOB | String |
| NVARCHAR | String |
| REAL | Singola |
| SECONDDATE | Data/Ora |
| SHORTTEXT | String |
| SMALLDECIMAL | Decimale |
| SMALLINT | Int16 |
| STGEOMETRYTYPE | Byte[] |
| STPOINTTYPE | Byte[] |
| TEXT | String |
| ORA | TimeSpan |
| TINYINT | Byte |
| VARCHAR | String |
| TIMESTAMP | Data/Ora |
| VARBINARY | Byte[] |
Sink SAP HANA
Attualmente, il connettore SAP HANA non è supportato come sink, mentre è possibile usare il connettore ODBC generico con il driver SAP HANA per scrivere dati in SAP HANA.
Seguire i Prerequisiti per configurare dapprima il Runtime di integrazione self-hosted e installare il driver ODBC di SAP HANA. Creare un servizio collegato ODBC per connettersi all'archivio dati SAP HANA, come illustrato nell'esempio seguente, quindi creare il set di dati e il sink dell'attività di copia con il tipo ODBC come pertinente. Altre informazioni sono disponibili nell'articolo Connettore ODBC.
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, vedere Archivi dati supportati.