Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come usare l'attività di copia nelle pipeline di Azure Data Factory e Synapse Analytics per copiare dati da Amazon Redshift. Si basa sull'articolo di panoramica dell'attività di copia che presenta una panoramica generale sull'attività di copia.
Importante
Il connettore Amazon Redshift versione 2.0 offre un supporto amazon redshift nativo migliorato. Se stai usando il connettore Amazon Redshift versione 1.0 nella tua soluzione, aggiorna il connettore Amazon Redshift poiché la versione 1.0 è alla fase di fine supporto. La pipeline avrà esito negativo dopo il 30 aprile 2026. Per informazioni dettagliate sulla differenza tra la versione 2.0 e la versione 1.0, vedere questa sezione .
Funzionalità supportate
Questo connettore Amazon Redshift è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (fonte/-) | 1 2 |
| Attività Lookup | 1 2 |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini o sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
Il servizio fornisce un driver predefinito per abilitare la connettività, pertanto non è necessario installare manualmente alcun driver.
Il connettore Amazon Redshift supporta il recupero di dati da Redshift utilizzando query o il supporto UNLOAD incorporato di Redshift.
Il connettore supporta le versioni di Windows in questo article.
Suggerimento
Per ottenere prestazioni ottimali quando si copiano grandi quantità di dati da Redshift, è possibile usare lo strumento UNLOAD Redshift predefinito tramite Amazon S3. Per informazioni dettagliate, vedere la sezione Usare UNLOAD per copiare i dati da Amazon Redshift.
Prerequisiti
Se si copiano dati in un archivio dati locale usando il runtime di integrazione self-hosted, concedere al runtime di integrazione (usare l'indirizzo IP del computer) l'accesso al cluster Amazon Redshift. Vedere Autorizzare l'accesso al cluster per le istruzioni. Per la versione 2.0, la versione del runtime di integrazione auto-ospitato deve essere 5.60 o successiva.
Se si copiano dati in un archivio dati Azure, vedere gli intervalli IP del data center Azure per l'indirizzo IP della macchina e gli intervalli SQL usati dai data center Azure.
Se l'archivio dati è un servizio dati cloud gestito, è possibile usare il Azure Integration Runtime. Se l'accesso è limitato agli indirizzi IP approvati nelle regole del firewall, è possibile aggiungere Azure Integration Runtime IP all'elenco elementi consentiti.
È anche possibile usare la funzionalità managed virtual network integration runtime in Azure Data Factory per accedere alla rete locale senza installare e configurare un runtime di integrazione self-hosted.
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o degli SDK seguenti:
- Strumento Copia Dati
- portale Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- API REST
- modello Azure Resource Manager
Creare un servizio collegato ad Amazon Redshift utilizzando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato ad Amazon Redshift nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Amazon e selezionare il connettore Amazon Redshift.
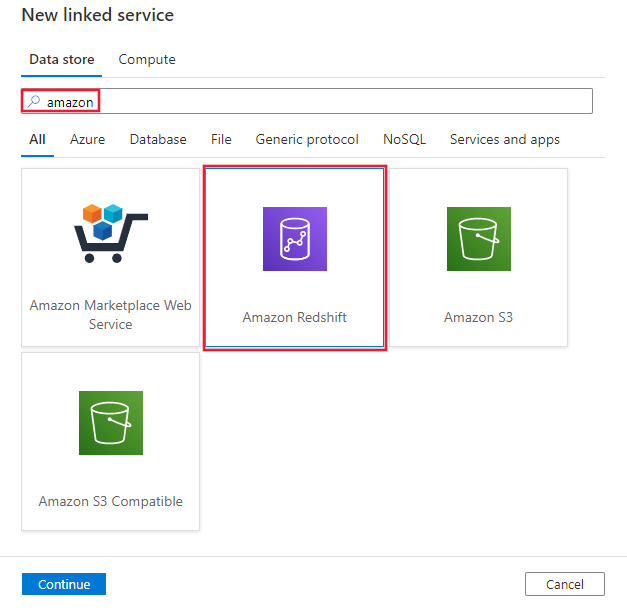
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
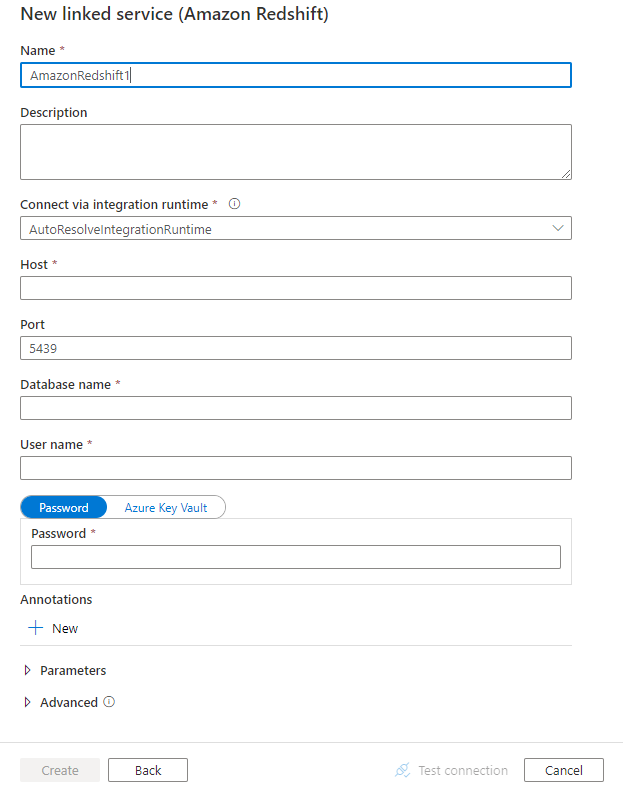
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà che vengono usate per definire entità di Data Factory specifiche per il connettore Amazon Redshift.
Proprietà del servizio collegato
Per il servizio collegato di Amazon Redshift sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type deve essere impostata su: AmazonRedshift | Sì |
| version | Versione specificata. | Sì per la versione 2.0. |
| server | Indirizzo IP o nome host del server Amazon Redshift. | Sì |
| porto | Il numero della porta TCP che il server Amazon Redshift usa per ascoltare le connessioni client. | No, il valore predefinito è 5439 |
| banca dati | Nome del database Amazon Redshift. | Sì |
| nome utente | Nome dell'utente che ha accesso al database. | Sì |
| parola d’ordine | La password per l'account utente. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro o referenziare un segreto archiviato in Azure Key Vault. | Sì |
| sslmode | Modalità di verifica del certificato SSL da usare per la connessione ad Amazon Redshift. Questa proprietà è supportata solo nella versione 2.0. - Verify_full: connettersi solo tramite SSL, un'autorità di certificazione attendibile e un nome del server corrispondente al certificato. - Verify_ca: connettersi solo usando SSL e un'autorità di certificazione attendibile. - Obbligatorio: connettersi solo tramite SSL. - Preferito: connettersi usando SSL, se disponibile. In caso contrario, connettersi senza usare SSL. - Consentito: per impostazione predefinita, connettersi senza usare SSL. Se il server richiede connessioni SSL, usare SSL. - Disabilitato: connettersi senza usare SSL. Opzioni: verify-full (impostazione predefinita) / verify-ca / require / prefer / allow / disable |
No, il valore predefinito è verify-full |
| connectVia | Integration Runtime da usare per connettersi all'archivio dati. È possibile usare Azure Integration Runtime o Integration Runtime self-hosted (se l'archivio dati si trova nella rete privata). Se non specificato, usa il Azure Integration Runtime predefinito. | NO |
Annotazioni
La versione 2.0 supporta Azure Integration Runtime e Integration Runtime Self-hosted versione 5.60 o successiva. L'installazione del driver non è più necessaria con Integration Runtime self-hosted versione 5.60 o successiva.
Esempio: versione 2.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"version": "2.0",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: versione 1.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione di set di dati, vedere l'articolo sui set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati Amazon Redshift.
Per copiare dati da Amazon Redshift, sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type del set di dati deve essere impostata su: AmazonRedshiftTable | Sì |
| schema | Nome dello schema. | No (se nell'origine dell'attività è specificato "query") |
| tabella | Nome della tabella. | No (se nell'origine dell'attività è specificato "query") |
| tableName | Nome della tabella con schema. Questa proprietà è supportata per garantire la compatibilità con le versioni precedenti. Per i nuovi carichi di lavoro, usare schema e table. |
No (se nell'origine dell'attività è specificato "query") |
Esempio
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Il set di dati tipizzato RelationalTable è ancora supportato senza modifiche, ma è consigliato l'uso del nuovo per il futuro.
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine Amazon Redshift.
Amazon Redshift come origine
Per copiare dati da Amazon Redshift, impostare il tipo di origine nell'attività di copia su AmazonRedshiftSource. Nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type dell'origine dell'attività di copia deve essere impostata su: AmazonRedshiftSource | Sì |
| quesito | Usare la query personalizzata per leggere i dati. Ad esempio: selezionare * da MyTable. | No (se nel set di dati è specificato "tableName") |
| redshiftUnloadSettings | Gruppo di proprietà quando si usa lo strumento UNLOAD di Amazon Redshift. | NO |
| s3LinkedServiceName | Fa riferimento a un'istanza di Amazon S3 da usare come archivio provvisorio specificando un nome di servizio collegato di tipo "AmazonS3". | Sì, se si usa UNLOAD |
| bucketName | Indicare il bucket S3 per archiviare i dati provvisori. Se non viene specificato, il servizio lo genera automaticamente. | Sì, se si usa UNLOAD |
Esempio: origine Amazon Redshift nell'attività di copia usando UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Per altre informazioni su come usare UNLOAD per copiare in modo efficiente dati da Amazon Redshift, vedere la sezione successiva.
Usare UNLOAD per copiare i dati da Amazon Redshift
UNLOAD è un meccanismo fornito da Amazon Redshift, che consente di scaricare i risultati di una query in uno o più file in Amazon Simple Storage Service (Amazon S3). Si tratta del metodo consigliato da Amazon per la copia di set di dati di grandi dimensioni da Redshift.
Example: copiare dati da Amazon Redshift a Azure Synapse Analytics usando UNLOAD, copia temporanea e PolyBase
Per questo caso d'uso di esempio, l'attività di copia scarica i dati da Amazon Redshift ad Amazon S3 come configurato in "redshiftUnloadSettings" e quindi copia i dati da Amazon S3 a Azure BLOB come specificato in "stagingSettings", infine usare PolyBase per caricare i dati in Azure Synapse Analytics. Tutto il formato provvisorio viene gestito correttamente dall'attività di copia.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Mapping del tipo di dati di Amazon Redshift
Quando si copiano dati da Amazon Redshift, i mapping seguenti si applicano ai tipi di dati di Amazon Redshift ai tipi di dati interni usati dal servizio. Per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink, vedere Mapping dello schema e del tipo di dati.
| Tipo di dati di Amazon Redshift | Tipo di dati del servizio provvisorio (per la versione 2.0) | Tipo di dati del servizio provvisorio (per la versione 1.0) |
|---|---|---|
| bigint | Int64 | Int64 |
| BOOLEAN | Boolean | string |
| CHAR | string | string |
| DATTERO | Datetime | Datetime |
| DECIMAL (precisione <= 28) | Decimal | Decimal |
| DECIMAL (precisione > 28) | string | string |
| PRECISIONE DOPPIA | Double | Double |
| INTEGER | Int32 | Int32 |
| real | Single | Single |
| SMALLINT | Int16 | Int16 |
| TEXT | string | string |
| TIMESTAMP | Datetime | Datetime |
| VARCHAR | string | string |
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Ciclo di vita e aggiornamento del connettore Amazon Redshift
La tabella seguente illustra la fase di rilascio e i log delle modifiche per diverse versioni del connettore Amazon Redshift:
| Versione | Fase di rilascio | Log delle modifiche |
|---|---|---|
| Versione 1.0 | Annunciata fine del supporto | / |
| Versione 2.0 | Versione GA disponibile | • Supporta Azure Integration Runtime e Self-hosted Integration Runtime di versione 5.60 o successiva. L'installazione del driver non è più necessaria con Integration Runtime self-hosted versione 5.60 o successiva. • BOOLEAN viene letto come tipo di dati booleano. • Supportare sslmode nel servizio collegato. |
Aggiornare il connettore Amazon Redshift dalla versione 1.0 alla versione 2.0
Nella pagina Modifica servizio collegato selezionare la versione 2.0 e configurare il servizio collegato facendo riferimento alle proprietà del servizio collegato.
Il mapping dei tipi di dati per il servizio collegato Amazon Redshift versione 2.0 è diverso da quello per la versione 1.0. Per informazioni sul mapping dei tipi di dati più recente, vedere Mapping dei tipi di dati per Amazon Redshift.
Applicare un runtime di integrazione self-hosted con la versione 5.60 o successiva. L'installazione del driver non è più necessaria con Integration Runtime self-hosted versione 5.60 o successiva.
Contenuti correlati
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, vedere Archivi dati supportati.