Introduzione: migliorare e pulire i dati
Questo articolo introduttivo illustra in modo dettagliato l'uso di un Notebook di Azure Databricks per pulire e migliorare i dati dei nomi dei baby name dello Stato di New York caricati in precedenza in una tabella in Unity Catalog usando Python, Scala e R. In questo articolo si modificano i nomi delle colonne, si modificano le maiuscole e si specifica il sesso di ogni nome del bambino dalla tabella dati grezza, quindi si salva il DataFrame in una tabella silver. Quindi si filtrano i dati in modo da includere solo i dati per 2021, raggruppare i dati a livello di stato e quindi ordinare i dati in base al conteggio. Infine, salvare questo DataFrame in una tabella gold e visualizzare i dati in un grafico a barre. Per altre informazioni sulle tabelle silver e gold, vedere Architettura medallion.
Importante
Questo articolo introduttivo si basa su Introduzione: inserimento di dati aggiuntivi. Per seguire la procedura descritta in questo articolo, è necessario seguire i passaggi descritti. Per il Notebook completo per l'articolo introduttivo, vedere Inserire altri Notebook di dati.
Requisiti
Per completare queste attività, è necessario soddisfare i requisiti seguenti:
- L'area di lavoro deve avere lo Unity Catalog abilitato. Per informazioni su come iniziare a usare Unity Catalog, vedere Configurare e gestire Unity Catalog.
- L'utente deve inoltre disporre del privilegio
WRITE VOLUMEper il catalogo padre del volume, il privilegioUSE SCHEMAper lo schema padre e del privilegioUSE CATALOGper il catalogo padre. - È necessario disporre dell'autorizzazione per usare una risorsa di calcolo esistente o creare una nuova risorsa di calcolo. Consulta Introduzione ad Azure Databricks oppure contatta l'amministratore di Databricks.
Suggerimento
Per un Notebook completo per questo articolo, vedere Pulire e migliorare i Notebook dei dati.
Passaggio 1: creare un nuovo Notebook:
Per creare un Notebook nell'area di lavoro, fare clic su ![]() Nuovo nella barra laterale e quindi su Notebook. Viene aperto un Notebook vuoto nell'area di lavoro.
Nuovo nella barra laterale e quindi su Notebook. Viene aperto un Notebook vuoto nell'area di lavoro.
Per altre informazioni sulla creazione e la gestione dei Notebook, vedere Gestire i Notebook.
Passaggio 2: definire le variabili
In questo passaggio si definiscono le variabili da usare nel Notebook di esempio creato in questo articolo.
Copiare e incollare il codice seguente nella nuova cella vuota del Notebook. Sostituire
<catalog-name>,<schema-name>e<volume-name>con i nomi del catalogo, dello schema e del volume per un volume di Unity Catalog. Opzionalmente, sostituire il valoretable_namecon il nome desiderato per la tabella. I dati relativi ai nomi dei bambini verranno salvati in questa tabella più avanti in questo articolo.Premere
Shift+Enterper eseguire la cella e creare una nuova cella vuota.Python
catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
Passaggio 3: caricare i dati non elaborati in un nuovo DataFrame
Questo passaggio carica i dati non elaborati salvati in precedenza in una tabella Delta in un nuovo DataFrame in preparazione alla pulizia e al miglioramento di questi dati per ulteriori analisi.
Copiare e incollare il codice seguente nella nuova cella vuota del Notebook.
Python
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)Scala
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)Premere
Shift+Enterper eseguire la cella e quindi passare alla cella successiva.
Passaggio 4: pulire e migliorare i dati non elaborati e salvare
In questo passaggio si modifica il nome della colonna Year, si modificano i dati nella colonna First_Name con iniziale maiuscola e si aggiornano i valori per la colonna Sex in modo da distinguere il sesso e quindi salvare il DataFrame in una nuova tabella.
Copiare e incollare il codice seguente in una nuova cella vuota di codice del Notebook.
Python
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")Scala
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")R
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")Premere
Shift+Enterper eseguire la cella e quindi passare alla cella successiva.
Passaggio 5: raggruppare e visualizzare i dati
In questo passaggio si filtrano i dati solo per l'anno 2021, si raggruppano i dati in base al sesso e al nome, si aggregano per conteggio e si ordinano per conteggio. Salvare quindi il DataFrame in una tabella e quindi visualizzare i dati in un grafico a barre.
Copiare e incollare il codice seguente in una nuova cella vuota di codice del Notebook.
Python
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")Scala
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")R
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")Premere
Ctrl+Enterper eseguire la cella.-
- Accanto alla scheda Tabella, fare clic su + e quindi su Visualizzazione.
Nell'editor di visualizzazione fare clic su Tipo di visualizzazione e verificare che sia selezionata l'opzione Barra.
Nella colonna X, selezionare
First_Name.Fare clic su Aggiungi colonna in colonne Y e quindi selezionare Total_Count.
In Raggruppa per, selezionare Sesso.
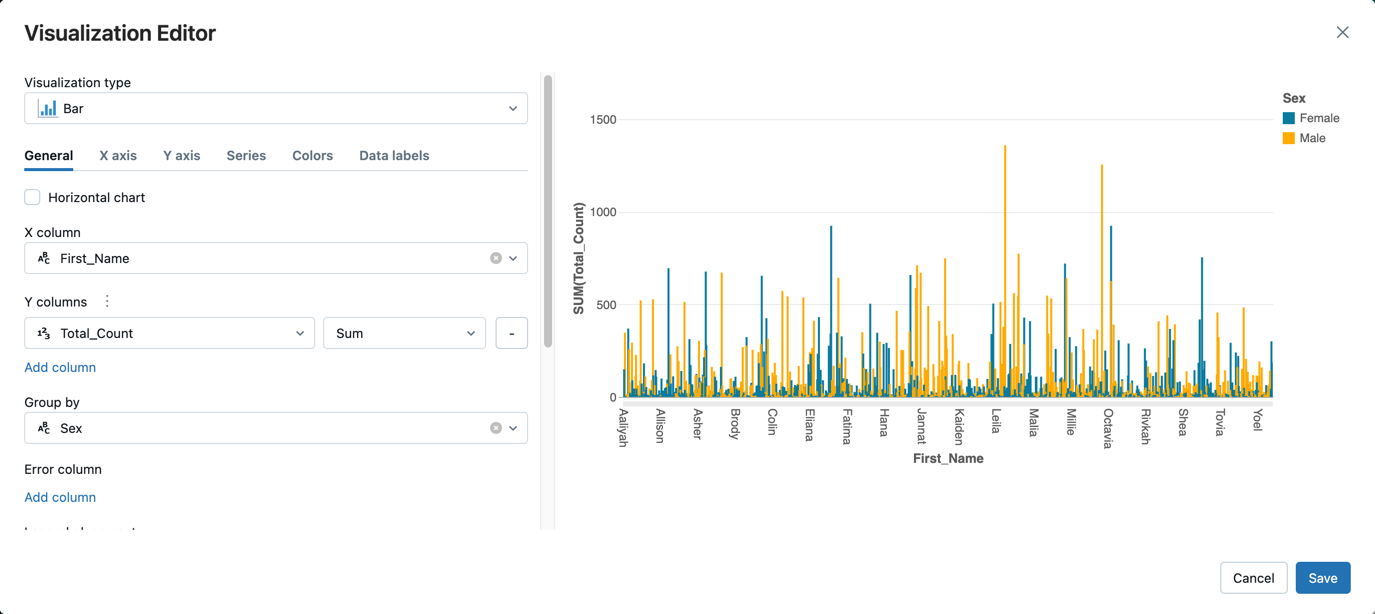
Fare clic su Salva.
Pulire e migliorare i Notebook di dati
Usare uno dei Notebook seguenti per eseguire la procedura descritta in questo articolo. Sostituire <catalog-name>, <schema-name> e <volume-name> con i nomi del catalogo, dello schema e del volume per un volume di Unity Catalog. Opzionalmente, sostituire il valore table_name con il nome desiderato per la tabella.