Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Databricks supporta l'uso di linguaggi di programmazione diversi per lo sviluppo e la progettazione dei dati. Questo articolo illustra le opzioni disponibili, dove è possibile usare tali lingue e le relative limitazioni.
Consigli
Databricks consiglia Python e SQL per i nuovi progetti:
- python è un linguaggio di programmazione per utilizzo generico molto diffuso. I DataFrame PySpark semplificano la creazione di trasformazioni modulari e testabili. L'ecosistema Python supporta anche un'ampia gamma di librerie che supporta un'ampia gamma di librerie per estendere la soluzione.
-
SQL è un linguaggio molto diffuso per la gestione e la modifica di set di dati relazionali eseguendo operazioni quali l'esecuzione di query, l'aggiornamento, l'inserimento e l'eliminazione di dati. SQL è una buona scelta se la tua esperienza riguarda principalmente i database o l'archiviazione dei dati. SQL può anche essere incorporato in Python usando
spark.sql.
I linguaggi seguenti hanno un supporto limitato, pertanto Databricks non li consiglia per i nuovi progetti di ingegneria dei dati:
- Scala è il linguaggio usato per lo sviluppo di Apache Spark™.
- R è supportato completamente solo nei notebook di Databricks.
Il supporto del linguaggio varia anche a seconda delle funzionalità usate per creare pipeline di dati e altre soluzioni. Ad esempio, le pipeline di Lakeflow supportano Python e SQL, mentre i flussi di lavoro consentono di creare pipeline di dati usando Python, SQL, Scala e Java.
Nota
È possibile usare altri linguaggi per interagire con Databricks per eseguire query sui dati o eseguire trasformazioni dei dati. Tuttavia, queste interazioni si trovano principalmente nel contesto delle integrazioni con sistemi esterni. In questi casi, uno sviluppatore può usare quasi qualsiasi linguaggio di programmazione per interagire con Databricks tramite l'API REST Databricks, driver ODBC/JDBC, linguaggi specifici con connettore SQL di Databricks supporto (Go, Python, Javascript/Node.js) o linguaggi con implementazioni di Spark Connect, ad esempio Go e Rust.
Sviluppo di aree di lavoro e sviluppo locale
È possibile sviluppare progetti di dati e pipeline usando l'area di lavoro Databricks o un ambiente di sviluppo integrato nel computer locale, ma è consigliabile avviare nuovi progetti nell'area di lavoro Databricks. L'area di lavoro è accessibile tramite un Web browser, consente di accedere facilmente ai dati in Unity Catalog e supporta potenti funzionalità di debug e funzionalità, ad esempio Genie Code.
Sviluppare codice nell'area di lavoro di Databricks usando i notebook di Databricks o l'editor SQL. I notebook di Databricks supportano più linguaggi di programmazione anche all'interno dello stesso notebook, in modo da poter sviluppare usando Python, SQL e Scala.
Lo sviluppo di codice direttamente nell'area di lavoro di Databricks offre diversi vantaggi:
- Il ciclo di feedback è più veloce. È possibile testare immediatamente il codice scritto sui dati reali.
- Il codice Genie in grado di supportare il contesto predefinito può velocizzare lo sviluppo e risolvere i problemi.
- È possibile pianificare facilmente notebook e query direttamente dall'area di lavoro di Databricks.
- Per lo sviluppo python, è possibile strutturare correttamente il codice Python usando i file come pacchetti Python in un'area di lavoro.
Tuttavia, lo sviluppo locale all'interno di un IDE offre i vantaggi seguenti:
- Gli IDE hanno strumenti migliori per l'uso di progetti software, ad esempio navigazione, refactoring del codice e analisi statica del codice.
- È possibile scegliere come controllare l'origine e, se si usa Git, sono disponibili funzionalità più avanzate in locale rispetto all'area di lavoro con le cartelle Git.
- Esiste una gamma più ampia di lingue supportate. Ad esempio, è possibile sviluppare codice usando Java e distribuirlo come attività JAR.
- È disponibile un supporto migliore per il debug del codice.
- È disponibile un supporto migliore per l'uso degli unit test.
Esempio di selezione della lingua
La selezione della lingua per la progettazione dei dati viene visualizzata usando l'albero delle decisioni seguente:
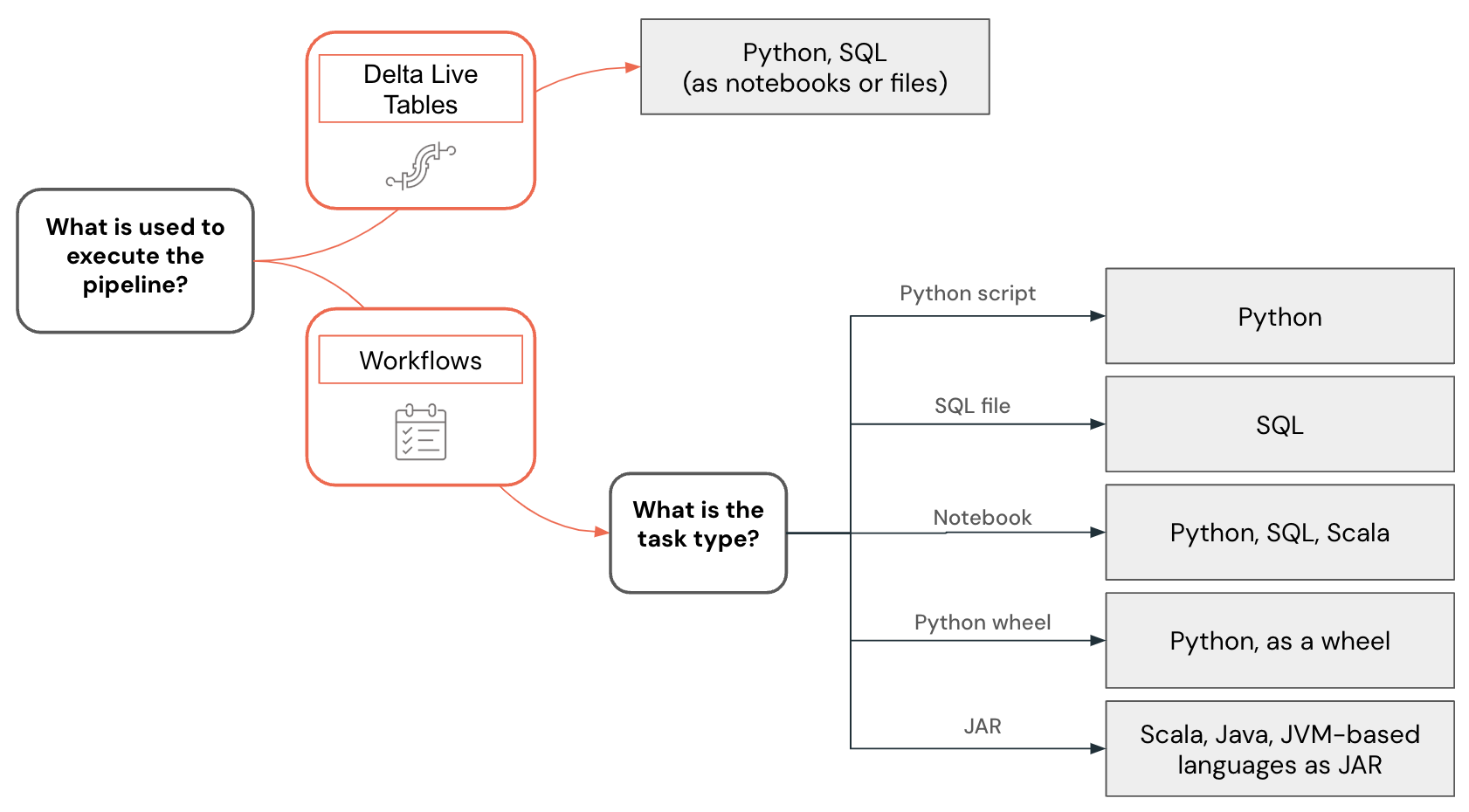
Sviluppo di codice Python
Il linguaggio Python include il supporto di prima classe in Databricks. È possibile usarlo nei notebook di Databricks, nelle pipeline e nei flussi di lavoro di Lakeflow, per sviluppare funzioni definite dall'utente e distribuirlo anche come script Python e come ruote.
Quando si sviluppano progetti Python nell'area di lavoro Databricks, sia come notebook che in file, Databricks fornisce strumenti come il completamento del codice, la navigazione, la convalida della sintassi, la generazione di codice usando Genie Code, il debug interattivo e altro ancora. Il codice sviluppato può essere eseguito in modo interattivo, distribuito come flusso di lavoro di Databricks o pipeline Lakeflow o anche come funzione nel catalogo unity. È possibile strutturare il codice suddividendolo in pacchetti Python separati che possono quindi essere usati in più pipeline o processi.
Databricks offre un'estensione per Visual Studio Code e JetBrains offre un plug-in per PyChar m che consente di sviluppare codice Python in un IDE, sincronizzare il codice in un'area di lavoro di Databricks, eseguirlo all'interno dell'area di lavoro ed eseguire il debug dettagliato usando Databricks Connect. Il codice sviluppato può quindi essere distribuito usando pacchetti di automazione dichiarativa come un job o una pipeline di Databricks.
Sviluppo di codice SQL
Il linguaggio SQL può essere usato nei notebook di Databricks o come query di Databricks usando l'editor SQL. In entrambi i casi, uno sviluppatore ottiene l'accesso a strumenti come il completamento del codice e il codice Genie compatibile con il contesto che può essere usato per la generazione del codice e la risoluzione dei problemi. Il codice sviluppato può essere distribuito come processo o pipeline.
I flussi di lavoro di Databricks consentono anche di eseguire codice SQL archiviato in un file. È possibile usare un IDE per creare questi file e caricarli nell'area di lavoro. Un altro uso comune di SQL è nelle pipeline di ingegneria dei dati sviluppate usando dbt (strumento di compilazione dei dati). I flussi di lavoro di Databricks supportano l'orchestrazione di progetti dbt.
Sviluppo di codice Scala
Scala è il linguaggio originale di Apache Spark™. È un linguaggio potente, ma ha una curva di apprendimento ripida. Anche se Scala è un linguaggio supportato nei notebook di Databricks, esistono alcune limitazioni relative alla creazione e alla gestione delle classi e degli oggetti Scala che possono rendere più difficile lo sviluppo di pipeline complesse. In genere gli IDE offrono un supporto migliore per lo sviluppo del codice Scala, che può quindi essere distribuito usando attività JAR nei flussi di lavoro di Databricks.
Risorse aggiuntive
- Sviluppare in Databricks è un punto di ingresso per la documentazione sulle diverse opzioni di sviluppo per Databricks.
- La pagina degli strumenti di sviluppo descrive diversi strumenti di sviluppo che possono essere usati per sviluppare localmente per Databricks, inclusi bundle di automazione dichiarativa e plug-in per gli IDE.
- Sviluppare codice nei notebook di Databricks descrive come sviluppare nell'area di lavoro Databricks usando i notebook di Databricks.
- Scrivere query ed esplorare i dati nell'editor SQL. Questo articolo descrive come usare l'editor SQL di Databricks per usare il codice SQL.
- Le pipeline Lakeflow descrive il processo di sviluppo delle pipeline Lakeflow.
- Databricks Connect consente di connettersi ai cluster Databricks ed eseguire codice dall'ambiente locale.
- Informazioni su come usare Genie Code per uno sviluppo più rapido e per risolvere i problemi di codice.